[paper]SwapNet: Image Based Garment Transfer(2018)
[code]SwapNet
文章阅读

摘要
SwapNet是一个能在图像上转移人的衣服的框架,人在图像中可以具有任意的身体姿势、形状和衣服。服装转移是一项具有挑战性的任务,它要求从人体姿势和形状中分离出服装的特征,在新的人体上真实的合成服装纹理。文中提出了一种神经网络结构,用两个特定于任务的自网络来处理这些子问题。由于获取不同身体上显示相同衣服的成对图像是困难的,提出了一种新的弱监督方法,通过数据增强从单个图像生成训练对。提出了在不受约束的图像中进行服装转移的全自动方法,不用解决困难的三维重建问题。展示了各种服装转换结果,强调了我们再传统图像到图像转换的优势和类比途径。
介绍
- 介绍了一种在图像空间中运行的方法,该方法可以在具有任意服装,身体姿势和形状的图像之间传输服装信息。避免了一方模板的3D重建或参数估计的需要。
- 由于缺乏理想的监督培训数据,引入了一种若监督学方法来完成此任务。

相关工作
- Human parsing and understanding(人物分析和理解)
- Generative adversarial networks(GANs)(生成对抗网络)
- Image-based garment synthesis(基于图像的服装合成)
- Visual analogies(视觉类比)
SwapNet
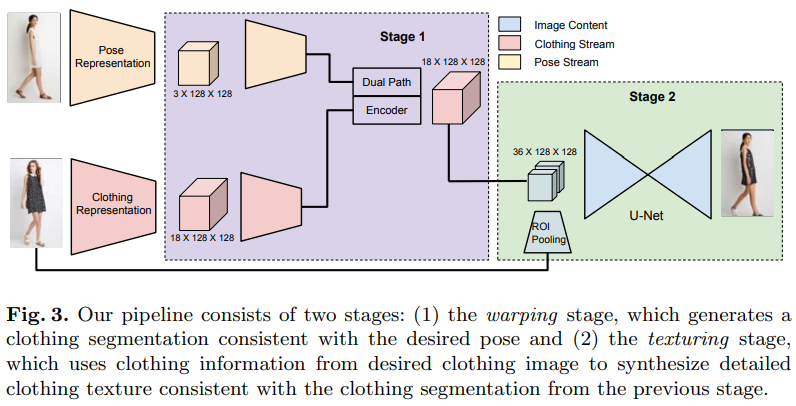
提供的服装转换系统,可以在保持姿势和身体形状的同时在一对图像之间交换服装,通过将服装的概念与身体形状和姿势的概念区分开来实现。以便于更改人或服装并根据需要重新组合它们。
给定一个图像
A
A
A和图像
B
B
B,图像
A
A
A中人穿着的衣服是要换装的衣服,图像
B
B
B中的人是保持身体形状和姿势,将衣服换成图像
A
A
A中衣服的待处理图像,生成的图像
B
′
B'
B′由
B
B
B图像中的人穿着
A
A
A图像中的衣服所组成。
A
A
A和
B
B
B可以描述不同体形、不同姿势、穿着任意衣服的人。
越来越流行的条件生成模型使用编码器-解码器类型的网络体现结构来转换输入图像以直接产生输出像素。例如pix2pix和Scribbler在图像转换任务上显示了高质量的结果,其中输出的结构和形状与输入的偏差不大。但是服装转换提出了更独特的挑战,成功的转换涉及对输入图像的重大结构更改。将所需服装的形状和纹理细节直接转换到目标身体会给网络带来太大的负担,从而导致转移质量较差。
提出了两阶段的方法来分别处理形状和纹理的合成。具体来说,服装和身体的分割为所需服装和目标身体提供了简洁和必要的表示。因此,首先进行分割操作以执行所需的形状更改,例如生成A中衣服图像的分割以图像B中目标身体的形状和姿势。假设图像A的衣服分割和图像B的身体分割是通过先前的工作给出或计算的,在第二阶段,纹理细化网将合成的服装分割和所需服装作为输入,生成最终的转换结果。
Warping Module
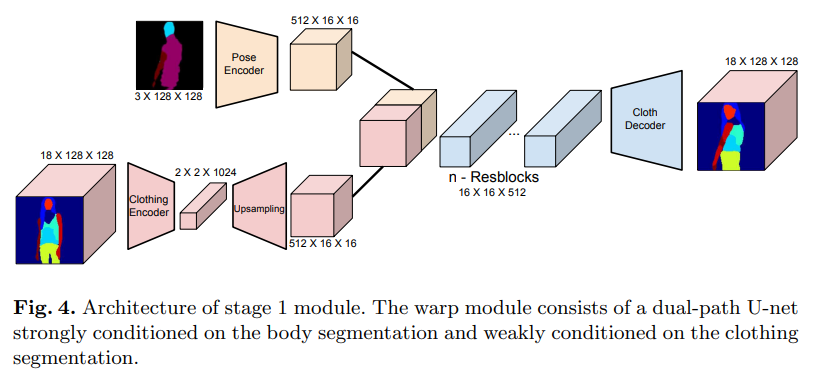
Warping Module主要是对
A
c
s
A_{cs}
Acs和
B
b
s
B_{bs}
Bbs进行操作,生成
B
c
s
′
B'_{cs}
Bcs′,
A
c
s
A_{cs}
Acs是对A图像进行衣服分割的结果,
B
b
s
B_{bs}
Bbs是对B图像进行人分割的结果,
B
c
s
′
B'_{cs}
Bcs′是图像B的衣服分割与A中分割的形状和标签一致,同时严格遵循B中的身体形状和姿势。这个问题为条件的生成过程,其中衣服应以
A
c
s
A_{cs}
Acs为条件,身体应以
B
b
s
B_{bs}
Bbs为条件。
使用双路径网络解决双条件问题。双路径网络由两个编码器流组成,一个编码器用于身体,一个编码器用于衣服,一个解码器将两个编码的隐藏表示组合在一起以生成最终输出。使用18通道分割蒙版表示服装,其中不包括皮带或眼镜之类的小配件。给定这个18通道分割图,其中每个通道包含一个衣服类别的概率图,衣服编码器将生成尺寸为512x16x16的特征图。给定颜色编码的3通道人体分割,人体编码器会类似的生成尺寸为512x16x16的特征图来表示目标人身体。这些编码的特征图被连接起来并通过4个残差块。然后对生成的特征图进行上采样,以生成所需的18通道的服装分割。
生成的图像以身体的分割为强条件,以衣服的分割为弱条件。这是在将其采样到所需大小的特征图之前,将衣服分割编码为2x2x1024较窄表示来说实现的。这种紧凑的表示形式,可以使网络提取高级信息,例如衣服的类型(上衣、下装、鞋子、皮肤等),从每个衣服的通道中提取整体的衣服形状,同时现在生成的分割,使其紧跟人体分割中的目标姿势和身体形状。
为了监督训练,理想的情况下,需要真实三元组
(
B
b
s
+
A
c
s
→
B
c
s
′
)
(B_{bs}+A_{cs} rightarrow B'_{cs})
(Bbs+Acs→Bcs′)。但是这样的数据集很难获得,并且对于服装的较大变化通常是不可扩展。所以,使用自我监督的方法来生成所需的三元组。具体的,给定单张图像B,可以考虑直接监督的三元组
(
B
b
s
+
B
c
s
→
B
c
s
′
)
(B_{bs}+B_{cs} rightarrow B'_{cs})
(Bbs+Bcs→Bcs′)。但是,使用这样的设置,会存在网络学习身份映射
B
c
s
=
B
c
s
′
B_{cs} = B'_{cs}
Bcs=Bcs′的危险。为了避免这种情况,使用增强的
B
c
s
B_{cs}
Bcs,执行随机仿射变换(包括随机裁剪和翻转)。这样网络就会丢弃来自
B
c
s
B_{cs}
Bcs的位置信息,只获取有关服装分割的类型和结构的高级信息。
衣服分割选用18通道的概率图,而不是3通道的颜色编码图,使模型有更大的灵活性来warp每个单独的分割。在训练的过程中,分割图像的每个通道经过不同的仿射变换,因此,网络应该学习每个通道和相应的身体分割之间的更高层次的关系推理。相比之下,对于身体分割使用3通道颜色编码图像,根据观察测试,身体分割的更细粒度编码不会提供更多信息,颜色编码的身体分割图像HIA提供了有关每个服装部分应该在何处对齐的指导,这总体上提供了有关身体形状和姿势的更强线索。此外,由于衣服部分跨越多个身体部分,保持整个身体图像的结构比将身体部分分成单独的通道更有利。


Texturing Module
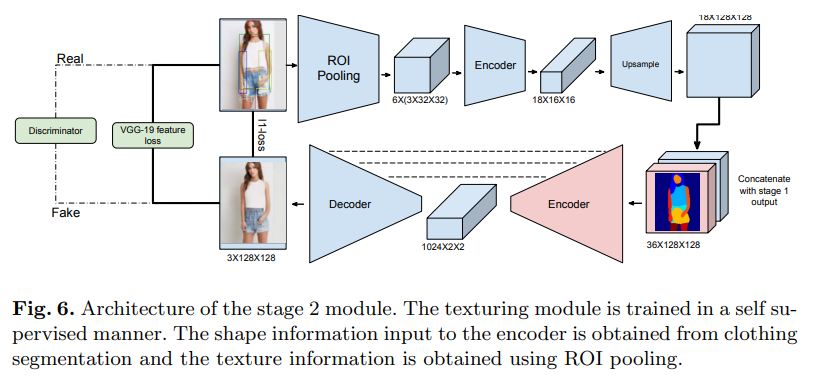
第二阶段的网络,纹理模块是一个U-Net架构,经过训练,可以根据所需的身体形状和姿势分割衣服,生成纹理细节。
与第一阶段类似,使用弱监督的方式训练纹理模块。给定输入图像B,我们认为输入为
(
B
c
s
+
e
m
b
e
d
d
i
n
g
o
f
t
h
e
c
l
o
t
h
i
n
g
i
n
B
→
B
)
(B_{cs}+embedding of the clothing in B rightarrow B)
(Bcs+embeddingoftheclothinginB→B)。为了避免学习身份映射,通过执行随机翻转和裁剪来从B的增强中计算苏旭服装的嵌入。我们使用L1重建损失,特征损失(VGG-19)和GAN损失以及DRAGAN梯度惩罚,这些已被证明可以改善结果的清晰度并稳定GAN的训练。第二阶段纹理模块的学习目标:
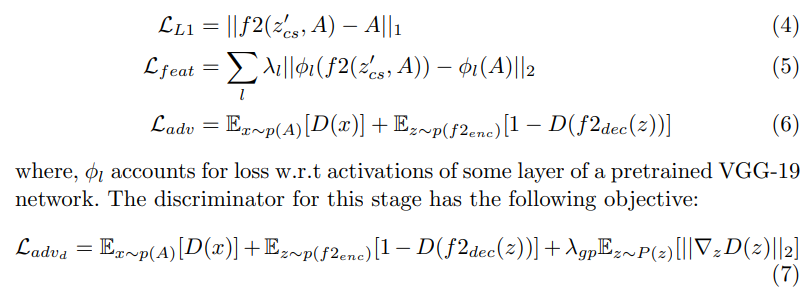
在测试阶段,使用前一阶段生成的服装细节。在通道之间执行argmax操作来展平18通道分段图。这样做主要是为了防止由于第一阶段的输出在特定像素位置有多个通道具有非零值造成的伪影。次步骤不可区分,因此不允许进行端到端的训练。但是,我可以跳过argmax步骤并采用softmax来对这些经过预训练的网络进行端到端的微调。我们的框架对于输入衣服和身体分割中的噪声是鲁棒的。第二阶段对第一阶段产生的包含噪声的衣服分割进行操作,并学会在填充纹理和颜色时忽略噪声。
网络框架的优势是,服装分割和身体分割不需要非常准确就可以使框架有效。我们的分割是通过最先进的人体分析和人体分析模型获得的,但是这些预测仍然具有噪声,并且经常会出现空洞。我们的网络框架能学会补偿对于这些中间表示中的噪声。包含噪声的衣服和身体分割提供了非常丰富和结构化的信号,与姿势关键点相反,但不像对pix2pix和Scribbler的输入那样严格,作为输入需要精确的草图和分割以生成合理的结果。
另外,我们再第一阶段的输入上执行一些后处理,以保留目标个体的身份,然后再将其输入第二阶段。特别是在生成的服装分割中
B
c
s
′
B'_{cs}
Bcs′,我们将人脸和头部分割替换为原始衣服分割
B
c
s
B_{cs}
Bcs。同样,在第二段结束时,我们将B的联合头发像素复制到结果中。如果没有这些步骤,整个框架类似于重新安置同一个人,而不是将衣服重新定位到另一个人。
实验
-
定性评估
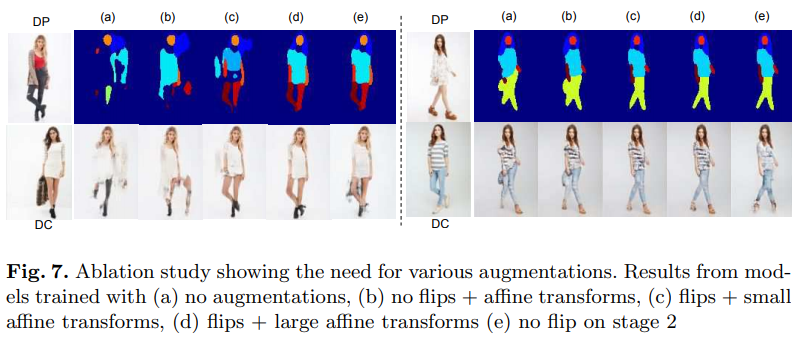



-
定量结果
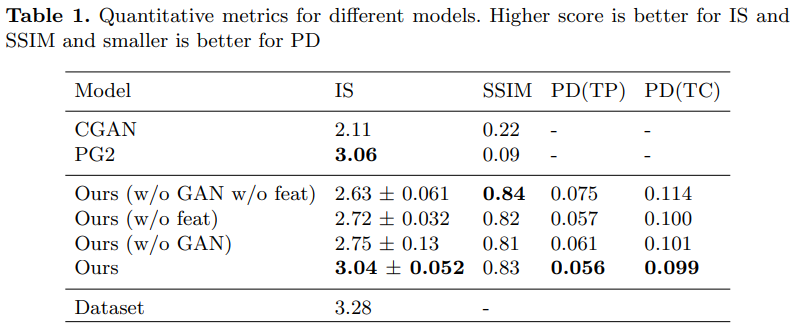
-
局限性

我们的框架难以处理原图像和目标图像之间的大姿势变化。如果其中一幅图像包含一个被截断的身体,而另一幅图像则包含一个完整的身体,我们的模型无法为缺失的下肢产生合适的细节。此外,我们的框架对帽子和太阳镜等类别的遮挡很敏感,可能会产生混合伪影。
结论
我们介绍了SwapNet,用于单张图像服装转换的框架。与传统的端到端的训练不同,我们激发了采用两阶段方法的需求,重点介绍了使用分通道分割作为中间阶段的服装转换。此外,在缺少针对不同姿势的相同服装的训练数据情况下,采用了一种新颖的弱监督训练程序来训练变形和纹理化模块。在未来,我们旨在利用有监督的子集,该子集可能使模型能够处理更大的姿态和比例变化。还可以利用变形之类的方法进一步改善生成的衣服中的细节。
代码解读
inference.py中,调用TestOptions()函数
if __name__ == '__main__':
config = TestOptions()
...
test_options.py的TestOptioins类的初始化函数中调用base_options.py中的BaseOptions类的初始化函数。
class TestOptions(BaseOptions):
def __init__(self, **defaults):
super().__init__()
...
BaseOptions类的初始化函数中
class BaseOptions:
def __init__(self):
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
conflict_handler="resolve",
)
# == EXPERIMENT SETUP ==
parser.add_argument(
"--config_file",
help="load arguments from a json file instead of command line",
)
parser.add_argument(
"--name",
default="my_experiment",
help="name of the experiment, determines where things are saved",
)
parser.add_argument(
"--comments",
default="",
help="additional comments to add to this experiment, saved in args.json",
)
parser.add_argument("--verbose", action="store_true")
parser.add_argument(
"--display_winsize",
type=int,
default=256,
help="display window size for both visdom and HTML",
)
# == MODEL INIT / LOADING / SAVING ==
parser.add_argument(
"--model", help="which model to run", choices=("warp", "texture", "pix2pix")
)
parser.add_argument(
"--checkpoints_dir", default="./checkpoints", help="Where to save models"
)
parser.add_argument(
"--load_epoch",
default="latest",
help="epoch to load (use with --continue_train or for inference, 'latest' "
"for latest ",
)
# == DATA / IMAGE LOADING ==
parser.add_argument(
"--dataroot",
required=True,
help="path to data, should contain 'cloth/', 'body/', 'texture/', "
"'rois.csv'",
)
parser.add_argument(
"--dataset", help="dataset class to use, if none then will use model name"
)
parser.add_argument(
"--dataset_mode",
default="image",
choices=("image", "video"),
help="how data is formatted. video mode allows additional source inputs"
"from other frames of the video",
)
# channels
parser.add_argument(
"--cloth_representation",
default="labels", # default according to SwapNet
choices=("rgb", "labels"),
help="which representation the cloth segmentations are in. 'labels' means "
"a 2D tensor where each value is the cloth label. 'rgb' ",
)
parser.add_argument(
"--body_representation",
default="rgb", # default according to SwapNet
choices=("rgb", "labels"),
help="which representation the body segmentations are in",
)
parser.add_argument(
"--cloth_channels",
default=19,
type=int,
help="only used if --cloth_representation == 'labels'. cloth segmentation "
"number of channels",
)
parser.add_argument(
"--body_channels",
default=12,
type=int,
help="only used if --body_representation == 'labels'. body segmentation "
"number of channels. Use 12 for neural body fitting output",
)
parser.add_argument(
"--texture_channels",
default=3,
type=int,
help="RGB textured image number of channels",
)
# image dimension / editing
parser.add_argument(
"--pad", action="store_true", help="add a padding to make image square"
)
parser.add_argument(
"--load_size",
default=128,
type=int,
help="scale images (after padding) to this size",
)
parser.add_argument(
"--crop_size", type=int, default=128, help="then crop to this size"
)
parser.add_argument(
"--crop_bounds",
help="DO NOT USE WITH --crop_size. crop images to a region: ((xmin, ymin), (xmax, ymax))",
)
# == ITERATION PROPERTIES ==
parser.add_argument(
"--max_dataset_size", type=int, default=float("inf"), help="cap on data"
)
parser.add_argument(
"--batch_size", type=int, default=8, help="batch size to load data"
)
parser.add_argument(
"--shuffle_data",
default=True,
type=bool,
help="whether to shuffle dataset (default is True)",
)
parser.add_argument(
"--num_workers",
default=4,
type=int,
help="number of CPU threads for data loading",
)
parser.add_argument(
"--gpu_id", default=0, type=int, help="gpu id to use. -1 for cpu"
)
parser.add_argument(
"--no_confirm", action="store_true", help="do not prompt for confirmations"
)
self._parser = parser
self.is_train = None

- 返回
test_options.py的TestOptioins类的初始化函数中。
class TestOptions(BaseOptions):
def __init__(self, **defaults):
...
self.is_train = False
parser = self._parser
parser.set_defaults(max_dataset_size=50, shuffle_data=False)
parser.add_argument(
"--interval",
metavar="N",
default=1,
type=int,
help="only run every n images",
)
parser.add_argument(
"--warp_checkpoint",
help="Use this to run the warp stage. Specifies the checkpoint file of "
"warp stage model, containing args.json file in same dir",
)
parser.add_argument(
"--texture_checkpoint",
help="Use this to run the texture stage. Specifies the checkpoint dir of "
"texture stage containing args.json file",
)
parser.add_argument(
"--checkpoint",
help="Shorthand for both warp and texture checkpoint to use the 'latest' "
"generator file (or specify using --load_epoch). This should be the "
"root dir containing warp/ and texture/ checkpoint folders.",
)
parser.add_argument(
"--body_dir",
help="Directory to use as target bodys for where the cloth will be placed "
"on. If same directory as --cloth_root, use --shuffle_data to achieve "
"clothing transfer. If not provided, will uses --dataroot/body",
)
parser.add_argument(
"--cloth_dir",
help="Directory to use for the clothing source. If same directory as "
"--body_root, use --shuffle_data to achieve clothing transfer. If not "
"provided, will use --dataroot/cloth",
)
parser.add_argument(
"--texture_dir",
help="Directory to use for the clothing source. If same directory as "
"--body_root, use --shuffle_data to achieve clothing transfer. If not "
"provided, will use --dataroot/texture",
)
parser.add_argument(
"--results_dir",
default="results",
help="folder to output intermediate and final results",
)
parser.add_argument(
"--skip_intermediates",
action="store_true",
help="choose not to save intermediate cloth visuals as images for warp "
"stage (instead, just save .npz files)",
)
parser.add_argument(
"--dataroot",
required=False,
help="path to dataroot if cloth, body, and texture not individually specified",
)
# remove arguments
parser.add_argument(
"--model", help=argparse.SUPPRESS
) # remove model as we restore from checkpoint
parser.add_argument("--name", default="", help=argparse.SUPPRESS)
parser.set_defaults(**defaults)

- 返回
inference.py中,调用config.parse()函数。
if __name__ == '__main__':
config = TestOptions()
config.parse()
- 进入
base_options.py中的parse(self, print_options=True, store_options=True, user_overrides=True)函数中。调用gather_options()函数
def parse(self, print_options=True, store_options=True, user_overrides=True):
"""
Args:
print_options: print the options to screen when parsed
store_options: save the arguments to file: "{opt.checkpoints_dir}/{opt.name}/args.json"
Returns:
"""
opt = self.gather_options()
- 进入
gather_options()函数
"""
Gathers options from all modifieable thingies.
:return:
"""
parser = self._parser
# basic options
opt, _ = parser.parse_known_args()
parser.set_defaults(dataset=opt.model)
opt.batch_size
# modify options for each arg that can do so
modifiers = ["model", "dataset"]
if self.is_train:
modifiers.append("optimizer_D")
for arg in modifiers:
# becomes model(s), dataset(s), optimizer(s)
import_source = eval(arg.split("_")[0] + "s")
# becomes e.g. opt.model, opt.dataset, opt.optimizer
name = getattr(opt, arg)
print(arg, name)
if name is not None:
options_modifier = import_source.get_options_modifier(name)
parser = options_modifier(parser, self.is_train)
opt, _ = parser.parse_known_args()
# hacky, add optimizer G params if different from opt_D
if arg is "optimizer_D" and opt.optimizer_D != opt.optimizer_G:
modifiers.append("optimizer_G")
self._parser = parser
final_opt = self._parser.parse_args()
return final_opt
getattr(object, name, default)Python内置函数,作用是返回object的名称为name的属性的属性值,如果name存在,则直接返回其属性值;如果属性name不存在,则出发AttributeError异常或当可选参数default定义时返回default值。
- 返回
base_options.py中的parse(self, print_options=True, store_options=True, user_overrides=True)函数中。调用静态函数BaseOptions._validate(opt)。
def parse(self, print_options=True, store_options=True, user_overrides=True):
...
opt.is_train = self.is_train
# perform assertions on arguments
BaseOptions._validate(opt)
- 进入
BaseOptions._validate(opt)函数中。
@staticmethod
def _validate(opt):
"""
Validate that options are correct
:return:
"""
assert (
opt.crop_size <= opt.load_size
), "Crop size must be less than or equal to load size "
- 返回
base_options.py中的parse(self, print_options=True, store_options=True, user_overrides=True)函数中。调用print()函数。
def parse(self, print_options=True, store_options=True, user_overrides=True):
...
if opt.gpu_id > 0:
torch.cuda.set_device(opt.gpu_id)
torch.backends.cudnn.benchmark = True
self.opt = opt
# Load options from config file if present
if opt.config_file:
self.load(opt.config_file, user_overrides)
if print_options: # print what we parsed
self.print()
- 进入
print()函数中。
def print(self):
"""
prints the options nicely
:return:
"""
d = vars(self.opt)
print("=====OPTIONS======")
for k, v in d.items():
print(k, ":", v)
print("==================")
vars([object])Python内置函数,返回对象object的属性和属性值的字典对象。
- 返回
base_options.py中的parse(self, print_options=True, store_options=True, user_overrides=True)函数中,调用save()函数。
def parse(self, print_options=True, store_options=True, user_overrides=True):
...
root = opt.checkpoints_dir if self.is_train else opt.results_dir
self.save_file = os.path.join(root, opt.name, "args.json")
if store_options: # store options to file
self.save()
- 进入
save()函数。
def save(self):
"""
Saves to a .json file
:return:
"""
d = vars(self.opt)
PromptOnce.makedirs(os.path.dirname(self.save_file), not self.opt.no_confirm)
with open(self.save_file, "w") as f:
f.write(json.dumps(d, indent=4))
- 调用
util.util.py中的PromptOnce类中的makedirs()静态函数。
class PromptOnce:
"""
Prompts the user if a path already exists. However, it will only prompt once during
the whole run of the program.
"""
already_asked = False
@staticmethod
def makedirs(path, prompt=True):
try:
os.makedirs(path)
PromptOnce.already_asked = True
except FileExistsError as e:
if prompt and len(os.listdir(path)) != 0 and not PromptOnce.already_asked:
print("The experiment directory '{0}' already exists.".format(path))
print(" Here are its contents:")
print("t", os.listdir(path))
a = input(
"n Existing data will be overwritten!n"
" Are you sure you want to continue? (y/N): "
)
if a.lower().strip() != "y":
print(" Did not receive confirmation to overwrite. Exiting...")
quit()
print()
PromptOnce.already_asked = True
- 返回
base_options.py中的parse(self, print_options=True, store_options=True, user_overrides=True)函数中,返回opt值。
def parse(self, print_options=True, store_options=True, user_overrides=True):
...
return opt
- 返回
inference.py中,调用_run_warp()函数。
...
# override checkpoint options
if opt.checkpoint:
if not opt.warp_checkpoint:
opt.warp_checkpoint = os.path.join(
opt.checkpoint, "warp", "{0}_net_generator.pth".format(opt.load_epoch)
)
print("Set warp_checkpoint to", opt.warp_checkpoint)
if not opt.texture_checkpoint:
opt.texture_checkpoint = os.path.join(
opt.checkpoint, "texture", "{0}_net_generator.pth".format(opt.load_epoch)
)
print("Set texture_checkpoint to", opt.texture_checkpoint)
# use dataroot if not individually provided
for subdir in ("body", "cloth", "texture"):
attribute = "{0}_dir".format(subdir)
if not getattr(opt, attribute):
setattr(opt, attribute, os.path.join(opt.dataroot, subdir))
# Run warp stage
if opt.warp_checkpoint:
print("Running warp inference...")
_run_warp()
- 进入
_run_warp()函数,调用_setup(WARP_SUBDIR, create_webpage=not opt.skip_intermediates)函数。
def _run_warp():
"""
Runs the warp stage
"""
warp_out, webpage = _setup(WARP_SUBDIR, create_webpage=not opt.skip_intermediates)
- 进入
_setup(subfolder_name, create_webpage=True)函数,调用get_out_dir(subfolder_name)函数。
def _setup(subfolder_name, create_webpage=True):
"""
Setup outdir, create a webpage
Args:
subfolder_name: name of the outdir and where the webpage files should go
Returns:
"""
out_dir = get_out_dir(subfolder_name)
- 进入
get_out_dir(subfolder_name)函数。
def get_out_dir(subfolder_name):
return os.path.join(opt.results_dir, subfolder_name)
- 返回
_setup(subfolder_name, create_webpage=True)函数,调用html.HTML(out_dir, "Experiment = {0}, Phase = {1} inference, " "Loaded Epoch = {2}".format(opt.name, subfolder_name, opt.load_epoch)函数。
def _setup(subfolder_name, create_webpage=True):
"""
Setup outdir, create a webpage
Args:
subfolder_name: name of the outdir and where the webpage files should go
Returns:
"""
...
PromptOnce.makedirs(out_dir, not opt.no_confirm)
webpage = None
if create_webpage:
webpage = html.HTML(
out_dir,
"Experiment = {0}, Phase = {1} inference, "
"Loaded Epoch = {2}".format(opt.name, subfolder_name, opt.load_epoch),
)
return out_dir, webpage
- 进入
util/html.py中的HTML类中的初始化函数中。
class HTML:
"""This HTML class allows us to save images and write texts into a single HTML file.
It consists of functions such as <add_header> (add a text header to the HTML file),
<add_images> (add a row of images to the HTML file), and <save> (save the HTML to the disk).
It is based on Python library 'dominate', a Python library for creating and manipulating HTML documents using a DOM API.
"""
def __init__(self, web_dir, title, refresh=0):
"""Initialize the HTML classes
Parameters:
web_dir (str) -- a directory that stores the webpage. HTML file will be created at <web_dir>/index.html; images will be saved at <web_dir/images/
title (str) -- the webpage name
refresh (int) -- how often the website refresh itself; if 0; no refreshing
"""
self.title = title
self.web_dir = web_dir
self.img_dir = os.path.join(self.web_dir, 'images')
if not os.path.exists(self.web_dir):
os.makedirs(self.web_dir)
if not os.path.exists(self.img_dir):
os.makedirs(self.img_dir)
self.doc = dominate.document(title=title)
if refresh > 0:
with self.doc.head:
meta(http_equiv="refresh", content=str(refresh))
Pythonzhon 中的dominate库是用来生成HTML的一个方便的工具,而不是模板系统,平时测试开发直接使用即可,上线Web网站的话,先变字符串,再从字符串上存成一个HTML。生成一个html页面:
- 返回
_setup(subfolder_name, create_webpage=True)函数,返回_run_warp()函数,调用_rebuild_from_checkpoint(opt.warp_checkpoint, cloth_dir=opt.cloth_dir, body_dir=opt.body_dir)函数。
def _run_warp():
"""
Runs the warp stage
"""
...
print("Rebuilding warp from {0}".format(opt.warp_checkpoint))
warp_model, warp_dataset = _rebuild_from_checkpoint(
opt.warp_checkpoint, cloth_dir=opt.cloth_dir, body_dir=opt.body_dir
)
- 进入函数
_rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs),调用base_options.py中的load()函数。
def _rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs):
"""
Loads a model and dataset based on the config in a particular dir.
Args:
checkpoint_file: dir containing args.json and model checkpoints
**ds_kwargs: override kwargs for dataset
Returns: loaded model, initialized dataset
"""
checkpoint_dir = os.path.dirname(checkpoint_file)
# read the config file so we can load in the model
loaded_opt = load(copy.deepcopy(opt), os.path.join(checkpoint_dir, "args.json"))
- 进入
base_options.py中的load(opt, json_file, user_overrides=True)函数。
def load(opt, json_file, user_overrides=True):
"""
Args:
opt: Namespace that will get modified
json_file:
user_overrides: whether user command line arguments should override anything being loaded from the config file
"""
opt = copy.deepcopy(opt)
with open(json_file, "r") as f:
args = json.load(f)
# if the user specifies arguments on the command line, don't override these
if user_overrides:
user_args = filter(lambda a: a.startswith("--"), sys.argv[1:])
user_args = set(
[a.lstrip("-") for a in user_args]
) # get rid of left dashes
print("Not overriding:", user_args)
# override default options with values in config file
for k, v in args.items():
# only override if not specified on the cmdline
if not user_overrides or (user_overrides and k not in user_args):
setattr(opt, k, v)
# but make sure the config file matches up
opt.config_file = json_file
return opt
Python lstrip()方法用于截掉字符串左边的空格或指定字符。

- 返回函数
_rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs),调用
override_namespace()函数。
def _rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs):
...
# force certain attributes in the loaded cfg
override_namespace(
loaded_opt,
is_train=False,
batch_size=1,
shuffle_data=opt.shuffle_data, # let inference opt take precedence
)
- 进入
override_namespace()函数。
def override_namespace(namespace, **kwargs):
"""
Simply overrides the attributes in the object with the specified keyword arguments
Args:
namespace: argparse.Namespace object
**kwargs: keyword/value pairs to use as override
"""
assert isinstance(namespace, argparse.Namespace)
for k, v in kwargs.items():
setattr(namespace, k, v)
- 返回函数
_rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs),调用create_model(loaded_opt)函数。
def _rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs):
...
if same_crop_load_size: # need to override this if we're using intermediates
loaded_opt.load_size = loaded_opt.crop_size
model = create_model(loaded_opt)
- 进入
models/__init__.py中的create_model(opt)函数,调用find_model_using_name(opt.model)。
def create_model(opt):
"""Create a model given the option.
This function warps the class CappedDataLoader.
This is the main interface between this package and 'train.py'/'test.py'
Example:
>>> from models import create_model
>>> model = create_model(opt)
"""
model = find_model_using_name(opt.model)
- 进入
find_model_using_name(model_name)。
def find_model_using_name(model_name):
"""Import the module "models/[model_name]_model.py".
In the file, the class called DatasetNameModel() will
be instantiated. It has to be a subclass of BaseModel,
and it is case-insensitive.
"""
model_filename = "models." + model_name + "_model"
modellib = importlib.import_module(model_filename)
model = None
target_model_name = model_name.replace('_', '') + 'model'
for name, cls in modellib.__dict__.items():
if name.lower() == target_model_name.lower()
and issubclass(cls, BaseModel):
model = cls
if model is None:
print("In %s.py, there should be a subclass of BaseModel with class name that matches %s in lowercase." % (model_filename, target_model_name))
exit(0)
return model
modellib = importlib.import_module(model_filename)动态的导入脚本文件。
modellib.__dict__.items()Python类提供了__dict__属性,方便用户查看类中包含哪些属性。该属性可以用类名或者类的实例对象来调用,用类名直接调用__dict__,会输出由该类中所有类属性组成的字典;而是用类的实例对象调用__dict__,会输出由该类中所有实例属性组成的字典。
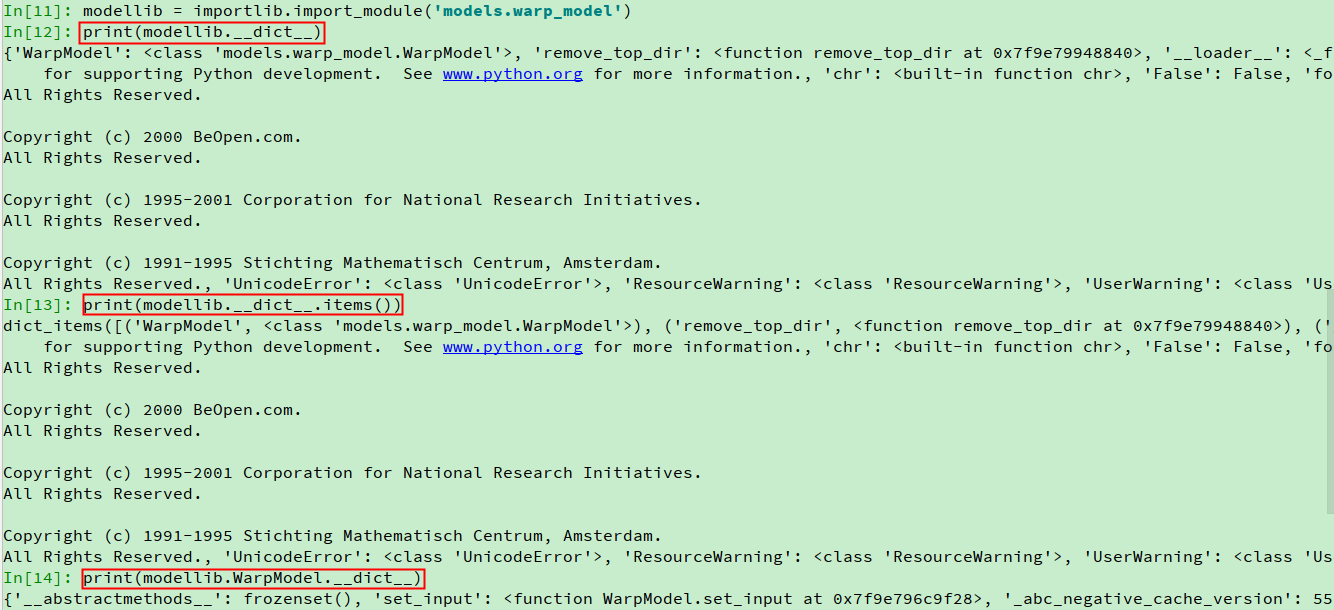
- 进入
models/__init__.py中的create_model(opt)函数,调用model(opt)。
def create_model(opt):
...
instance = model(opt)
print("model [%s] was created" % type(instance).__name__)
return instance
- 进入
warp_model.py中的WarpModel类的初始化函数中,调用base_gan.py中BaseGAN类的初始化函数。
class WarpModel(BaseGAN):
def __init__(self, opt):
"""
Initialize the WarpModel. Either in GAN mode or plain Cross Entropy mode.
Args:
opt:
"""
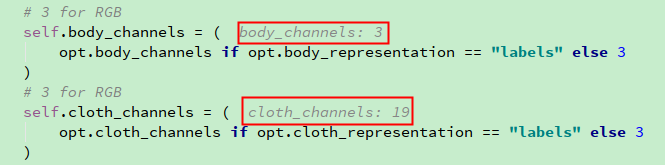
# 3 for RGB
self.body_channels = (
opt.body_channels if opt.body_representation == "labels" else 3
)
# 3 for RGB
self.cloth_channels = (
opt.cloth_channels if opt.cloth_representation == "labels" else 3
)
BaseGAN.__init__(self, opt)
- 进入
base_gan.py中BaseGAN类的初始化函数,调用base_model.py中BaseModel类的初始化函数。
class BaseGAN(BaseModel, ABC):
def __init__(self, opt):
"""
Sets the generator, discriminator, and optimizers.
Sets self.net_generator to the return value of self.define_G()
Args:
opt:
"""
super().__init__(opt)
Python中并没有提供抽象类与抽象方法,但是提供了内置模块
abc(abstract base class)来模拟实现抽象类。
主要类或函数:
abc.ABCMeta这是用来生成抽象基础类的元类。由它生成的类可以被直接继承。abc.ABC辅助类,可以不用关心元类概念,直接继承它,就有了abc.ABCMeta元类。使用时注意元类冲突。@abc.abstractmethod定义抽象方法,处理这个装饰器,其余装饰器都被deprecated了。
- 进入
base_model.py中BaseModel类中的初始化函数中。
"""This class is an abstract base class (ABC) for models.
To create a subclass, you need to implement the following five functions:
-- <__init__>: initialize the class; first call BaseModel.__init__(self, opt).
-- <set_input>: unpack data from dataset and apply preprocessing.
-- <forward>: produce intermediate results.
-- <optimize_parameters>: calculate losses, gradients, and update network weights.
-- <modify_commandline_options>: (optionally) add model-specific options and set default options.
"""
def __init__(self, opt):
"""Initialize the BaseModel class.
Parameters:
opt (Option class)-- stores all the experiment flags; needs to be a subclass of BaseOptions
When creating your custom class, you need to implement your own initialization.
In this fucntion, you should first call <BaseModel.__init__(self, opt)>
Then, you need to define four lists:
-- self.loss_names (str list): specify the training losses that you want to plot and save.
-- self.model_names (str list): specify the images that you want to display and save.
-- self.visual_names (str list): define networks used in our training.
-- self.optimizers (optimizer list): define and initialize optimizers. You can define one optimizer for each network. If two networks are updated at the same time, you can use itertools.chain to group them. See cycle_gan_model.py for an example.
"""
self.opt = opt
self.gpu_id = opt.gpu_id
self.is_train = opt.is_train
# get device name: CPU or GPU
self.device = (
torch.device("cuda:{}".format(self.gpu_id))
if self.gpu_id is not None
else torch.device("cpu")
)
# save all the checkpoints to save_dir
self.save_dir = os.path.join(opt.checkpoints_dir, opt.name)
if self.is_train:
PromptOnce.makedirs(self.save_dir, not opt.no_confirm)
self.loss_names = []
self.model_names = []
self.visual_names = []
self.optimizer_names = []
# self.optimizers = []
self.image_paths = []
self.metric = 0 # used for learning rate policy 'plateau'
- 返回
base_gan.py中BaseGAN类的初始化函数,调用warp_model.py中的define_G()函数。
class BaseGAN(BaseModel, ABC):
def __init__(self, opt):
...
self.net_generator = self.define_G().to(self.device)
- 进入
warp_model.py中的define_G()函数,调用swapnet_modules.py中WarpModule类初始化函数。
class WarpModel(BaseGAN):
def generate_G(self):
"""
The generator is the Warp Module.
"""
return WarpModule(
body_channels=self.body_channels, cloth_channels=self.cloth_channels
)
swapnet_modules.py中WarpModule类初始化函数,调用layers.py中的UNetDown类初始化函数。
class WarpModule(nn.Module):
"""
The warping module takes a body segmentation to represent the "pose",
and an input clothing segmentation to transform to match the pose.
"""
def __init__(self, body_channels=3, cloth_channels=19, dropout=0.5):
super(WarpModule, self).__init__()
######################
# Body pre-encoding # (top left of SwapNet diagram)
######################
self.body_down1 = UNetDown(body_channels, 64, normalize=False)
- 进入
layers.py中的UNetDown类初始化函数。
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias=False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size))
layers.append(nn.LeakyReLU(0.2))
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
功能:对由多个输入平面组成的输入信号进行二维卷积。
参数说明:
- in_channels:输入维度,输入信号的形式为(N, C_{in}, H, W)
- N:表示batch size(批处理参数)
- C_{in}:表示channel个数
- H,W:分别表示特征图的高和宽
- out_channels:输出维度
- kernel_size: 卷积核的宽度和长度,单个整数或由两个整数构成的list/tuple。如果为单个整数,则表示在各个空间维度的相同长度。
- stride:步长,默认为1,可以设为1个int型数或者一个(int,int)型的tuple。
- padding:补0,控制zero-padding的数目,padding是在卷积之前补0.
- dilation:扩张,控制kernel点(卷积核点)的间距
- groups(int, optional):从输入通道到输出通道的阻塞连接数,通常来说,卷积个数唯一,但是对某些情况,可以设置范围在1-in_channels中数目的卷积核。
经过卷积后输出特征图尺寸计算公式:
W o u t = W i n − K + 2 P S + 1 W_{out} = frac {W_{in} - K + 2P}{S} + 1 Wout=SWin−K+2P+1
swapnet_modules.py中WarpModule类初始化函数,调用layers.py中的UNetUp类初始化函数。
class WarpModule(nn.Module):
...
def __init__(self, body_channels=3, cloth_channels=19, dropout=0.5):
self.body_down2 = UNetDown(64, 128)
self.body_down3 = UNetDown(128, 256)
self.body_down4 = UNetDown(256, 512, dropout=dropout)
######################
# Cloth pre-encoding # (bottom left of SwapNet diagram)
######################
self.cloth_down1 = UNetDown(cloth_channels, 64, normalize=False)
self.cloth_down2 = UNetDown(64, 128)
self.cloth_down3 = UNetDown(128, 256)
self.cloth_down4 = UNetDown(256, 512)
self.cloth_down5 = UNetDown(512, 1024, dropout=dropout)
self.cloth_down6 = UNetDown(1024, 1024, normalize=False, dropout=dropout)
# the two UNetUp's below will be used WITHOUT concatenation.
# hence the input size will not double
self.cloth_up1 = UNetUp(1024, 1024)
- 进入
layers.py中的UNetUp类初始化函数,。
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True),
]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1)
功能:进行反卷积
参数说明:
- in_channels(int):输入信号的通道数
- out_channels(int):卷积产生的通道数
- kernel_size(int or tuple):卷积核的大小
- stride(int or tuple, optional):卷积步长,即要将输入扩大的倍数。
- padding(int or tuple, optional):输入的每一条边补充0的层数,高宽都增加2*padding
- output_padding(int or tuple, optional):鼠标边补充0的层数,高宽都增加padding
- groups(int, optional):从输入通道到输出通道的阻塞连接数
- bias(bool, optional):如果bias=True,添加偏置
- dilation(int or tuple,optional):卷积核元素之间的间距
输出图像尺寸计算公式:
W o u t = ( W i n t − 1 ) ∗ S + P o u t − 2 ∗ P i n + K W_{out} = (W_{int} - 1) * S + P_{out} - 2*P_{in} + K Wout=(Wint−1)∗S+Pout−2∗Pin+K
- 返回
swapnet_modules.py中WarpModule类初始化函数,调用ResidualBlock(1024, dropout=dropout)函数。
class WarpModule(nn.Module):
...
def __init__(self, body_channels=3, cloth_channels=19, dropout=0.5):
....
self.cloth_up2 = UNetUp(1024, 512)
######################
# Resblocks # (middle of SwapNet diagram)
######################
self.resblocks = nn.Sequential(
# I don't really know if dropout should go here. I'm just guessing
ResidualBlock(1024, dropout=dropout),
ResidualBlock(1024, dropout=dropout),
ResidualBlock(1024, dropout=dropout),
ResidualBlock(1024, dropout=dropout),
)
- 进入
layers.py中ResidualBlock类中的初始化函数。
class ResidualBlock(nn.Module):
def __init__(self, in_features, dropout=0.0):
super(ResidualBlock, self).__init__()
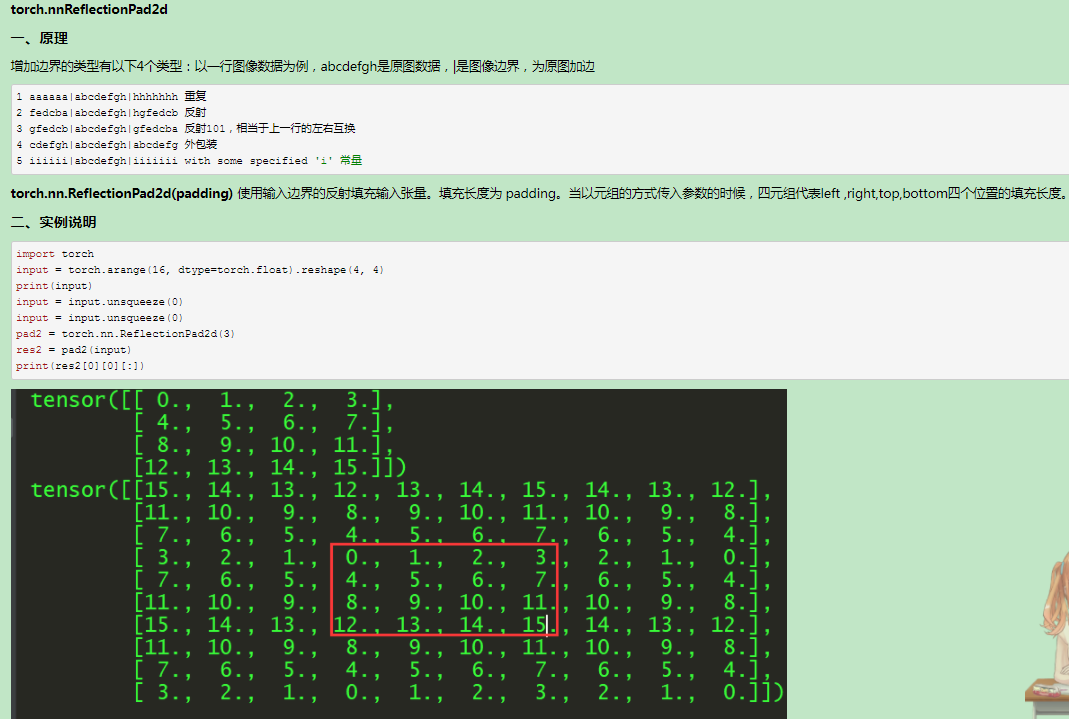
conv_block = [
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
nn.ReLU(inplace=True),
nn.Dropout(dropout), # added by AJ
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
]
self.conv_block = nn.Sequential(*conv_block)

- 返回
swapnet_modules.py中WarpModule类初始化函数,调用layers.py中DualUNetUp()函数。
class WarpModule(nn.Module):
...
def __init__(self, body_channels=3, cloth_channels=19, dropout=0.5):
....
######################
# Dual Decoding # (right of SwapNet diagram, maybe)
######################
# The SwapNet diagram just says "cloth" decoder, so I don't know if they're
# actually doing dual decoding like I've done here.
# Still, I think it's cool and it makes more sense to me.
# Found from "Multi-view Image Generation from a Single-View".
# ---------------------
# input encoded (512) & cat body_d4 (512) cloth_d4 (512)
self.dual_up1 = DualUNetUp(1024, 256)
- 进入
layers.py中DualUNetUp()类的初始化函数,调用UNetUp类的初始化函数。
class DualUNetUp(UNetUp):
"""
My guess of how dual u-net works, according to the paper
"Multi-View Image Generation from a Single-View"
@author Andrew
"""
def __init__(self, in_size, out_size, dropout=0.0):
super(DualUNetUp, self).__init__(in_size, out_size, dropout)
- 进入
UNetUp类的初始化函数。
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True),
]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
- 返回
DualUNetUp()类的初始化函数,返回WarpModule类初始化函数。
class WarpModule(nn.Module):
...
def __init__(self, body_channels=3, cloth_channels=19, dropout=0.5):
....
# input dual_up1 (256) & cat body_d3 (256) cloth_d3 (256)
self.dual_up2 = DualUNetUp(3 * 256, 128)
# input dual_up2 (128) & cat body_d2 (128) cloth_d2 (128)
self.dual_up3 = DualUNetUp(3 * 128, 64)
# TBH I don't really know what the below code does.
# like why don't we dualnetup with down1?
# maybe specific to pix2pix? hm, if so maybe we should replicate.
# ------
# update: OHHH I get it now. it's because U-Net only outputs half the size as
# the original image, hence we need to upsample.
self.upsample_and_pad = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(3 * 64, cloth_channels, 4, padding=1),
nn.Tanh(),
)

- 返回
warp_model.py中的define_G()函数,返回base_gan.py中BaseGAN类的初始化函数,调用models/__init__.py中的init_weights(self.net_generator, opt.init_type, opt.init_gain)函数。
class BaseGAN(BaseModel, ABC):
def __init__(self, opt):
...
modules.init_weights(self.net_generator, opt.init_type, opt.init_gain)
- 进入
models/__init__.py中的init_weights(net, init_type="normal", init_gain=0.02)函数。
def init_weights(net, init_type="normal", init_gain=0.02):
"""Initialize network weights.
Parameters:
net (network) -- network to be initialized
init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
We use 'normal' in the original pix2pix and CycleGAN paper. But xavier and kaiming might
work better for some applications. Feel free to try yourself.
"""
def init_func(m): # define the initialization function
classname = m.__class__.__name__
if hasattr(m, "weight") and (
classname.find("Conv") != -1 or classname.find("Linear") != -1
):
if init_type == "normal":
init.normal_(m.weight.data, 0.0, init_gain)
elif init_type == "xavier":
init.xavier_normal_(m.weight.data, gain=init_gain)
elif init_type == "kaiming":
init.kaiming_normal_(m.weight.data, a=0, mode="fan_in")
elif init_type == "orthogonal":
init.orthogonal_(m.weight.data, gain=init_gain)
else:
raise NotImplementedError(
"initialization method [%s] is not implemented" % init_type
)
if hasattr(m, "bias") and m.bias is not None:
init.constant_(m.bias.data, 0.0)
elif (
classname.find("BatchNorm2d") != -1
): # BatchNorm Layer's weight is not a matrix; only normal distribution applies.
init.normal_(m.weight.data, 1.0, init_gain)
init.constant_(m.bias.data, 0.0)
print("initialize network with %s" % init_type)
net.apply(init_func) # apply the initialization function <init_func>
- 返回
base_gan.py中BaseGAN类的初始化函数,直到执行完。
class BaseGAN(BaseModel, ABC):
def __init__(self, opt):
...
self.model_names = ["generator"]
if self.is_train:
# setup discriminator
self.net_discriminator = discriminators.define_D(
self.get_D_inchannels(), 64, opt.discriminator, opt.n_layers_D, opt.norm
).to(self.device)
modules.init_weights(self.net_discriminator, opt.init_type, opt.init_gain)
# load discriminator only at train time
self.model_names.append("discriminator")
# setup GAN loss
use_smooth = True if opt.gan_label_mode == "smooth" else False
self.criterion_GAN = modules.loss.GANLoss(
opt.gan_mode, smooth_labels=use_smooth
).to(self.device)
if opt.lambda_discriminator:
self.loss_names = ["D", "D_real", "D_fake"]
if any(gp_mode in opt.gan_mode for gp_mode in ["gp", "lp"]):
self.loss_names += ["D_gp"]
self.loss_names += ["G"]
if opt.lambda_gan:
self.loss_names += ["G_gan"]
# Define optimizers
self.optimizer_G = optimizers.define_optimizer(
self.net_generator.parameters(), opt, "G"
)
self.optimizer_D = optimizers.define_optimizer(
self.net_discriminator.parameters(), opt, "D"
)
self.optimizer_names = ("G", "D")
swapnet_model.py中WarpModel类初始化函数,直到执行完。
class WarpModel(BaseGAN):
def __init__(self, opt):
...
# TODO: decode visuals for cloth
self.visual_names = ["inputs_decoded", "bodys_unnormalized", "fakes_decoded"]
if self.is_train:
self.visual_names.append(
"targets_decoded"
) # only show targets during training
# we use cross entropy loss in both
self.criterion_CE = nn.CrossEntropyLoss()
if opt.warp_mode != "gan":
# remove discriminator related things if no GAN
self.model_names = ["generator"]
self.loss_names = "G"
del self.net_discriminator
del self.optimizer_D
self.optimizer_names = ["G"]
else:
self.loss_names += ["G_ce"]
- 返回到
models/__init__.py中的create_model(opt)函数中,直到执行完。
def create_mdoel(opt):
...
print("model [%s] was created" % type(instance).__name__)
return instance
- 返回到
_rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs)函数中,调用base_model.py中的load_model_weights("generator", checkpoint_file)函数。
def _rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs):
...
# loads the checkpoint
model.load_model_weights("generator", checkpoint_file).eval()
- 进入
base_model.py中的load_model_weights(self, model_name, weights_file)函数,直到执行完成。
class BaseModel(ABC):
def load_model_weights(self, model_name, weights_file):
""" Loads the weights for a single model
Args:
model_name: name of the model to load parameters into
weights_file: path to weights file
"""
net = getattr(self, "net_{}".format(model_name))
print("loading the model {0} from {1}".format(model_name, weights_file))
state_dict = torch.load(weights_file, map_location=self.device)
if hasattr(state_dict, "_metadata"):
del state_dict._metadata
net.load_state_dict(state_dict)
return self
- 返回到
_rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs)函数中,调用base_model.py中的eval()函数。
class BaseModel(ABC):
def eval(self):
"""Make models eval mode during test time"""
for name in self.model_names:
if isinstance(name, str):
net = getattr(self, "net_" + name)
net.eval()
return self
- 返回到
_rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs)函数中,调用print_networks(opt.verbose)函数。
def _rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs):
...
model.print_networks(opt.verbose)
dataset = create_dataset(loaded_opt, **ds_kwargs)
return model, dataset
- 进入
base_model.py中的print_networks(self, verbose)函数中。
class BaseModel(ABC):
def print_networks(self, verbose):
"""Print the total number of parameters in the network and (if verbose) network architecture
Parameters:
verbose (bool) -- if verbose: print the network architecture
"""
print("---------- Networks initialized -------------")
for name in self.model_names:
if isinstance(name, str):
net = getattr(self, "net_" + name)
num_params = 0
for param in net.parameters():
num_params += param.numel()
if verbose:
print(net)
print(
"[Network %s] Total number of parameters : %.3f M"
% (name, num_params / 1e6)
)
print("-----------------------------------------------")
- 返回到
_rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs)函数中,调用create_dataset(loaded_opt, **ds_kwargs)函数。
def _rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs):
...
dataset = create_dataset(loaded_opt, **ds_kwargs)
- 进入
datasets/__init__.py中的create_dataset(opt, **ds_kwargs)函数中,调用CappedDataLoader类的初始化函数。
def create_dataset(opt, **ds_kwargs):
"""Create a dataset given the option.
This function wraps the class CappedDataLoader.
This is the main interface between this package and 'train.py'/'test.py'
Example:
>>> from datasets import create_dataset
>>> dataset = create_dataset(opt)
"""
data_loader = CappedDataLoader(opt, **ds_kwargs)
return data_loader
- 进入
CappedDataLoader类的初始化函数中,调用find_dataset_using_name(dname)。
class CappedDataLoader:
"""Wrapper class of Dataset class that caps the data limit at the specified
max_dataset_size """
def __init__(self, opt, **ds_kwargs):
"""Initialize this class
Step 1: create a dataset instance given the name [dataset_mode]
Step 2: create a multi-threaded data loader.
"""
self.opt = opt
dname = opt.dataset if opt.dataset else opt.model
print("Creating dataset {0}...".format(dname), end=" ")
dataset_class = find_dataset_using_name(dname)
- 进入
find_dataset_using_name(dataset_name)函数中。
def find_dataset_using_name(dataset_name):
"""Import the module "data/[dataset_name]_dataset.py".
In the file, the class called DatasetNameDataset() will
be instantiated. It has to be a subclass of BaseDataset,
and it is case-insensitive.
"""
dataset_filename = "datasets." + dataset_name + "_dataset"
datasetlib = importlib.import_module(dataset_filename)
dataset = None
target_dataset_name = dataset_name.replace("_", "") + "dataset"
for name, cls in datasetlib.__dict__.items():
if name.lower() == target_dataset_name.lower() and issubclass(cls, BaseDataset):
dataset = cls
if dataset is None:
raise NotImplementedError(
"In {0}.py, there should be a subclass of BaseDataset "
"with class name that matches {1} in lowercase.".format(dataset_filename, target_dataset_name)
)
return dataset
- 返回
CappedDataLoader类的初始化函数中,调用warp_dataset.py中WarpDataset类中的初始化函数。
class CappedDataLoader:
def __init__(self, opt, **ds_kwargs):
...
self.dataset = daaset_class(opt, **ds_kwargs)
- 进入
warp_dataset.py中WarpDataset类中的初始化函数,调用base_dataset.py中BaseDataset类中的初始化函数。
class WarpDataset(BaseDataset):
""" Warp dataset for the warp module of SwapNet """
@staticmethod
def modify_commandline_options(parser, is_train):
parser.add_argument(
"--input_transforms",
nargs="+",
default="none",
choices=("none", "hflip", "vflip", "affine", "perspective", "all"),
help="what random transforms to perform on the input ('all' for all transforms)",
)
if is_train:
parser.set_defaults(
input_transforms=("hflip", "vflip", "affine", "perspective")
)
parser.add_argument(
"--per_channel_transform",
action="store_true",
default=True, # TODO: make this a toggle based on if data is RGB or labels
help="Perform the transform for each label instead of on the image as a "
"whole. --cloth_representation must be 'labels'.",
)
return parser
def __init__(self, opt, cloth_dir=None, body_dir=None):
"""
Args:
opt:
cloth_dir: (optional) path to cloth dir, if provided
body_dir: (optional) path to body dir, if provided
"""
super().__init__(opt)
- 进入
base_dataset.py中BaseDataset类中的初始化函数。
class BaseDataset(data.Dataset, ABC):
"""This class is an abstract base class (ABC) for datasets.
To create a subclass, you need to implement the following four functions:
-- <__init__>: initialize the class, first call BaseDataset.__init__(self, opt).
-- <__len__>: return the size of dataset.
-- <__getitem__>: get a data point.
-- <modify_commandline_options>: (optionally) add dataset-specific options and set default options.
"""
def __init__(self, opt):
"""Initialize the class; save the options in the class
Parameters:
opt (Option class)-- stores all the experiment flags; needs to be a subclass of BaseOptions
"""
self.opt = opt
self.root = opt.dataroot
self.crop_bounds = self.parse_crop_bounds()
self.is_train = opt.is_train
- 返回
warp_dataset.py中WarpDataset类中的初始化函数,调用data_utils.py中的find_valid_files(self.cloth_dir, extensions)。
class WarpDataset(BaseDataset):
def __init__(self, opt, cloth_dir=None, body_dir=None):
...
self.cloth_dir = cloth_dir if cloth_dir else os.path.join(opt.dataroot, "cloth")
print("cloth dir", self.cloth_dir)
extensions = [".npz"] if self.opt.cloth_representation == "labels" else None
print("Extensions:", extensions)
self.cloth_files = find_valid_files(self.cloth_dir, extensions)
- 进入
data_utils.py中的find_valid_files(dir, extensions=None, max_dataset_size=float("inf")),调用in_extensions(fname, extensions if extensions else IMG_EXTENSIONS)。
def find_valid_files(dir, extensions=None, max_dataset_size=float("inf")):
"""
Get all the images recursively under a dir.
Args:
dir:
extensions: specific extensions to look for. else will use IMG_EXTENSIONS
max_dataset_size:
Returns: found files, where each item is a tuple (id, ext)
"""
if isinstance(extensions, str):
extensions = [extensions]
images = []
assert os.path.isdir(dir), "%s is not a valid directory" % dir
for root, _, fnames in sorted(os.walk(dir, followlinks=True)):
for fname in fnames:
if in_extensions(fname, extensions if extensions else IMG_EXTENSIONS):
- 进入
in_extensions(filename, extensions)中。
def in_extensions(filename, extensions):
return any(filename.endswith(extension) for extension in extensions)
- 返回
data_utils.py中的find_valid_files(dir, extensions=None, max_dataset_size=float("inf")),直到执行完成。
def find_valid_files(dir, extensions=None, max_dataset_size=float("inf")):
...
for root, _, fnames in sorted(os.walk(dir, followlinks=True)):
for fname in fnames:
if in_extensions(fname, extensions if extensions else IMG_EXTENSIONS):
path = os.path.join(root, fname)
images.append(path)
return images[: min(max_dataset_size, len(images))]
- 返回
warp_dataset.py中WarpDataset类中的初始化函数,调用data_utils.py中的get_norm_stats(os.path.dirname(self.body_dir), "body")函数。
class WarpDataset(BaseDataset):
def __init__(self, opt, cloth_dir=None, body_dir=None):
...
self.cloth_files = find_valid_files(self.cloth_dir, extensions)
if not opt.shuffle_data:
self.cloth_files.sort()
self.body_dir = body_dir if body_dir else os.path.join(opt.dataroot, "body")
if not self.is_train: # only load these during inference
self.body_files = find_valid_files(self.body_dir)
if not opt.shuffle_data:
self.body_files.sort()
print("body dir", self.body_dir)
self.body_norm_stats = get_norm_stats(os.path.dirname(self.body_dir), "body")
- 进入
data_utils.py中的get_norm_stats(dataroot, key)函数。
def get_norm_stats(dataroot, key):
try:
df = pd.read_json(
os.path.join(dataroot, "normalization_stats.json"), lines=True
).set_index("path")
except ValueError:
raise ValueError("Could not find 'normalization_stats.json' for {0}".format(dataroot))
series = df.loc[key]
return series["means"], series["stds"]
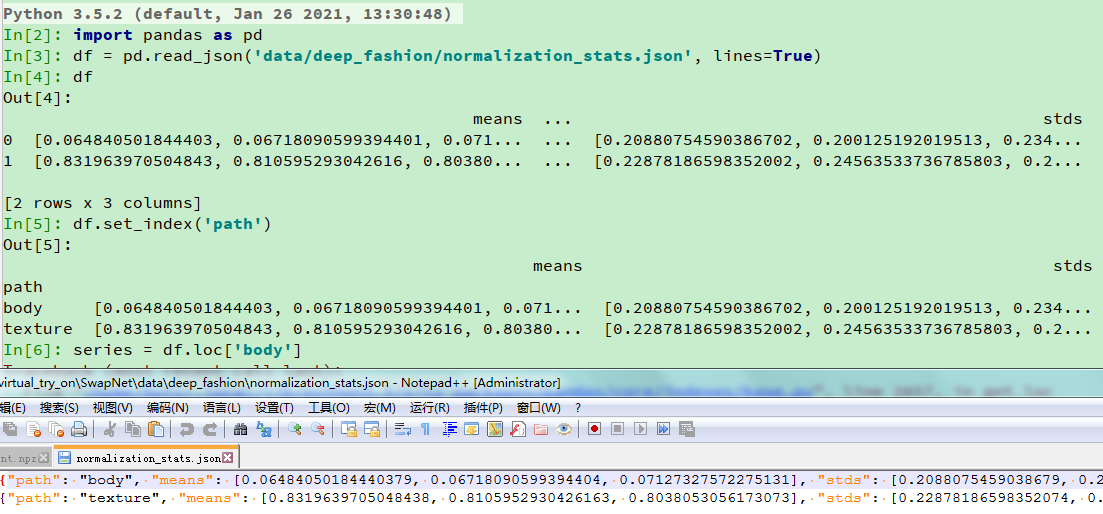
- 返回
warp_dataset.py中WarpDataset类中的初始化函数,调用datasets/__init__.py中get_transforms(opt)函数。
class WarpDataset(BaseDataset):
def __init__(self, opt, cloth_dir=None, body_dir=None):
...
self.body_norm_stats = get_norm_stats(os.path.dirname(self.body_dir), "body")
opt.body_norm_stats = self.body_norm_stats
self._normalize_body = transforms.Normalize(*self.body_norm_stats)
self.cloth_transform = get_transforms(opt)
- 进入
datasets/__init__.py中get_transforms(opt)函数。
def get_transforms(opt):
"""
Return Composed torchvision transforms based on specified arguments.
"""
transforms_list = []
if "none" in opt.input_transforms:
return
every = "all" in opt.input_transforms
if every or "vflip" in opt.input_transforms:
transforms_list.append(transforms.RandomVerticalFlip())
if every or "hflip" in opt.input_transforms:
transforms_list.append(transforms.RandomHorizontalFlip())
if every or "affine" in opt.input_transforms:
transforms_list.append(
transforms.RandomAffine(
degrees=10, translate=(0.1, 0.1), scale=(0.8, 1.2), shear=20
)
)
if every or "perspective" in opt.input_transforms:
transforms_list.append(transforms.RandomPerspective())
return transforms.RandomOrder(transforms_list)
- 返回
warp_dataset.py中WarpDataset类中的初始化函数,返回CappedDataLoader类的初始化函数中。
class CappedDataLoader:
def __init__(self, opt, **ds_kwargs):
...
self.dataset = dataset_class(opt, **ds_kwargs)
print("dataset [{0}] was created".format(type(self.dataset).__name__))
self.dataloader = torch.utils.data.DataLoader(
self.dataset,
batch_size=opt.batch_size,
shuffle=opt.shuffle_data,
num_workers=opt.num_workers,
)
- 返回
datasets/__init__.py中的create_dataset(opt, **ds_kwargs)函数中。
def create_dataset(opt, **ds_kwargs):
"""Create a dataset given the option.
This function wraps the class CappedDataLoader.
This is the main interface between this package and 'train.py'/'test.py'
Example:
>>> from datasets import create_dataset
>>> dataset = create_dataset(opt)
"""
data_loader = CappedDataLoader(opt, **ds_kwargs)
return data_loader
- 返回到
_rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs)函数中,
def _rebuild_from_checkpoint(checkpoint_file, same_crop_load_size=False, **ds_kwargs):
...
dataset = create_dataset(loaded_opt, **ds_kwargs)
return model, dataset
- 返回到
_run_warp()函数中,调用_run_test_loop(warp_model, warp_dataset, webpage, iteration_post_hook=save_cloths_npz)函数。
def _run_warp():
...
warp_model, warp_dataset = _rebuild_from_checkpoint(
opt.warp_checkpoint, cloth_dir=opt.cloth_dir, body_dir=opt.body_dir
)
def save_cloths_npz(local):
"""
We must store the intermediate cloths as .npz files
"""
name = "_to_".join(
[remove_extension(os.path.basename(p)) for p in local["image_paths"][0]]
)
out_name = os.path.join(warp_out, name)
# save the warped cloths
compress_and_save_cloth(local["model"].fakes[0], out_name)
print("Warping cloth to match body segmentations in {0}...".format(opt.body_dir))
try:
_run_test_loop(
warp_model, warp_dataset, webpage, iteration_post_hook=save_cloths_npz
)
- 进入
_run_test_loop(model, dataset, webpage=None, iteration_post_hook: Callable = None)函数。
def _run_test_loop(model, dataset, webpage=None, iteration_post_hook: Callable = None):
"""
Args:
model: object that extends BaseModel
dataset: object that extends BaseDataset
webpage: webpage object for saving
iteration_post_hook: a function to call at the end of every iteration
Returns:
"""
total = min(len(dataset), opt.max_dataset_size)
with tqdm(total=total, unit="img") as pbar:
for i, data in enumerate(dataset):
if i >= total:
break
model.set_input(data) # set input
model.test() # forward pass
image_paths = model.get_image_paths() # ids of the loaded images
if webpage:
visuals = model.get_current_visuals()
save_images(webpage, visuals, image_paths, width=opt.display_winsize)
if iteration_post_hook:
iteration_post_hook(local=locals())
pbar.update()
if webpage:
webpage.save()
参考资料
[paper]SwapNet: Image Based Garment Transfer(2018)
[code]SwapNet
[dataset]DeepFashion: In-shop Clothes Retrieval
Python学习笔记(9):dominate库基础使用
Python lstrip()方法
Python 动态导入对象,importlib.import_module()使用
Python模块文档学习之抽象基类abc模块
nn.Conv2d和nn.ConvTranspose2d参数说明及区别
PyTorch中 nn.Conv2d与nn.ConvTranspose2d函数的用法
pytorch中的ReflectionPad2d
nn.ConvTranspose2d和nn.Upsample的区别
Python any() 函数
最后
以上就是热心百合最近收集整理的关于基于图像的虚拟试衣:SwapNet: Image Based Garment Transfer(2018)文章阅读代码解读的全部内容,更多相关基于图像的虚拟试衣:SwapNet:内容请搜索靠谱客的其他文章。








发表评论 取消回复