→ zookeeper version 3.6.1
一、临时节点
相信我们对 zookeeper 的临时节点都不陌生,与持久节点的最大区别就是会随着会话的消失而删除,这种特性常被用来作注册中心分布式锁等,下面来分析下临时节点的实现:

单机模式下由三个 processor 构成了整个处理链路
PrepRequestProcessor 主要负责请求的反序列化,串行化处理和权限校验等
SyncRequestProcessor 主要负责数据的持久化
FinalRequestProcessor 主要负责对内存中数据的更新
这里主要看下第三个处理器是怎样处理临时节点的
org.apache.zookeeper.server.DataTree#createNode(java.lang.String, byte[], java.util.List<org.apache.zookeeper.data.ACL>, long, int, long, long, org.apache.zookeeper.data.Stat)
public void createNode(final String path, byte[] data, List<ACL> acl, long ephemeralOwner, int parentCVersion, long zxid, long time, Stat outputStat) throws KeeperException.NoNodeException, KeeperException.NodeExistsException {
// ... 省略部分代码
// 拿到当前节点的类型
EphemeralType ephemeralType = EphemeralType.get(ephemeralOwner);
// 是否是 container 节点
if (ephemeralType == EphemeralType.CONTAINER) {
containers.add(path);
// 是否是带过期时间的节点
} else if (ephemeralType == EphemeralType.TTL) {
ttls.add(path);
// 处理临时节点的逻辑
} else if (ephemeralOwner != 0) {
HashSet<String> list = ephemerals.get(ephemeralOwner);
if (list == null) {
list = new HashSet<String>();
ephemerals.put(ephemeralOwner, list);
}
synchronized (list) {
list.add(path);
}
}
// 省略部分代码
}
其实不难看懂,临时节点底层就是维护了一个 Map<Long, <Set<String>>>,key保存了 ephemeralOwner,value 则是临时节点的 path,现在只要看下 ephemeralOwner 是什么就好了,下面看下该方法调用方的入参
public ProcessTxnResult processTxn(TxnHeader header, Record txn, boolean isSubTxn) {
ProcessTxnResult rc = new ProcessTxnResult();
try {
//...省略部分代码
case OpCode.create:
CreateTxn createTxn = (CreateTxn) txn;
rc.path = createTxn.getPath();
createNode(
createTxn.getPath(),
createTxn.getData(),
createTxn.getAcl(),
// 判断是否是临时节点,是临时节点就传入 clientId
createTxn.getEphemeral() ? header.getClientId() : 0,
createTxn.getParentCVersion(),
header.getZxid(),
header.getTime(),
null);
break;
//...省略部分代码
}
} catch (KeeperException e) {
LOG.debug("Failed: {}:{}", header, txn, e);
rc.err = e.code().intValue();
} catch (IOException e) {
LOG.debug("Failed: {}:{}", header, txn, e);
}
}上述代码能发现入参是 clientId,可能这个 id 还是不太明确,接下来去找下构造 TxnHeader 的地方,也就是第一个 processor
org.apache.zookeeper.server.PrepRequestProcessor#pRequest2Txn
protected void pRequest2Txn(int type, long zxid, Request request, Record record, boolean deserialize) throws KeeperException, IOException, RequestProcessorException {
if (request.getHdr() == null) {
// cxid 是客户端生成的 xid,zxid 是服务端生成的
request.setHdr(new TxnHeader(request.sessionId, request.cxid, zxid,
Time.currentWallTime(), type));
}
//...省略部分代码
}clientId 就是 TxnHeader 的第一个构造参数,也就是 sessionId,其实也不难想象,要想达到这种效果需要跟会话产生关系
二、单机 Session
这里就简单过一下不会讲的很细,主要回顾下与临时节点有关的特性
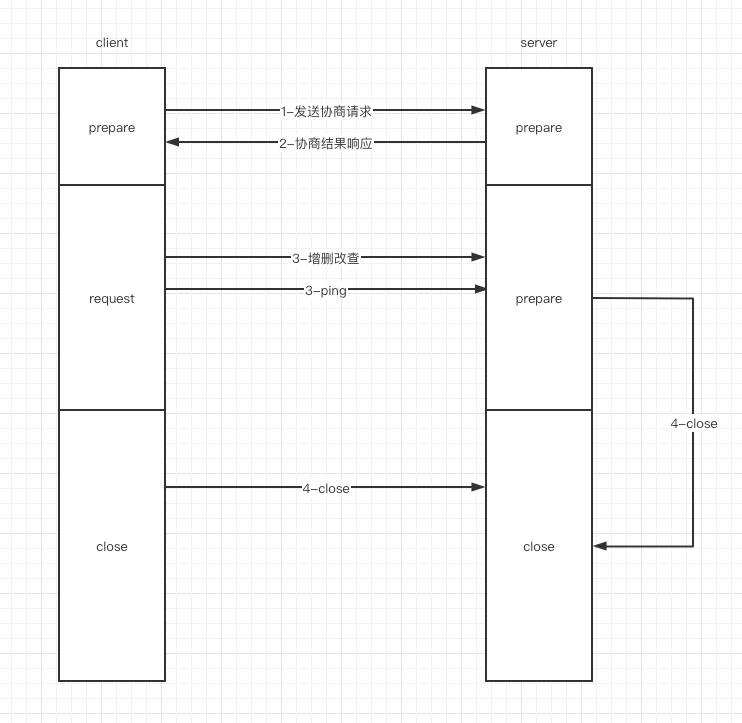
1、发送协商请求:这部分主要是对 session 创建以及过期时间的协商,为什么叫协商是因为这两边的任何一方都不能擅自决定这两个参数
session 的创建:如果请求方发送协商请求的时候 sessionId = 0 ,那么服务端会生成一个 sessionId 返回给请求端,正常情况下初始化都为 0 ,只有当进行重连的时候才会携带上次请求的 sessionId
过期时间:请求方协商请求的时候也会携带过期时间,服务端启动也会初始化过期时间,如果两端不一致服务端会返回较小的时间作为过期时间
2、协商结果响应
主要就是返回协商过后的过期时间与 sessionId
3、增删改查 与 ping
其实这里做的主要的就是对 session 的续期,每请求一次都会给 session 续期,每次增删改查都会,期间没有增删改查请求端会记录上次请求的时间,如果发现 session 快过期则会发送 ping 请求
4、session 的关闭:session 关闭主要可能来自两方面
zk server 内部线程轮询发现有过期的 session 于是构造 session 过期的请求发送到上面介绍的 3个 处理器中
请求端发送关闭 session 的请求
看了以上的逻辑那我们来聊下当 processor 接收到 close 请求的时候会做些什么处理呢
org.apache.zookeeper.server.PrepRequestProcessor#pRequest2Txn
protected void pRequest2Txn(int type, long zxid, Request request, Record record, boolean deserialize) throws KeeperException, IOException, RequestProcessorException {
// ... 省略部分代码
case OpCode.closeSession:
long startTime = Time.currentElapsedTime();
synchronized (zks.outstandingChanges) {
// 拿到 session 对应的临时节点
Set<String> es = zks.getZKDatabase().getEphemerals(request.sessionId);
for (ChangeRecord c : zks.outstandingChanges) {
if (c.stat == null) {
// Doing a delete
es.remove(c.path);
} else if (c.stat.getEphemeralOwner() == request.sessionId) {
es.add(c.path);
}
}
// 针对每个临时节点构建删除请求
for (String path2Delete : es) {
if (digestEnabled) {
parentPath = getParentPathAndValidate(path2Delete);
parentRecord = getRecordForPath(parentPath);
parentRecord = parentRecord.duplicate(request.getHdr().getZxid());
parentRecord.stat.setPzxid(request.getHdr().getZxid());
parentRecord.precalculatedDigest = precalculateDigest(
DigestOpCode.UPDATE, parentPath, parentRecord.data, parentRecord.stat);
addChangeRecord(parentRecord);
}
nodeRecord = new ChangeRecord(
request.getHdr().getZxid(), path2Delete, null, 0, null);
nodeRecord.precalculatedDigest = precalculateDigest(
DigestOpCode.REMOVE, path2Delete);
addChangeRecord(nodeRecord);
}
if (ZooKeeperServer.isCloseSessionTxnEnabled()) {
request.setTxn(new CloseSessionTxn(new ArrayList<String>(es)));
}
zks.sessionTracker.setSessionClosing(request.sessionId);
}
// ... 省略部分代码
}其实有很多操作是跟请求串行化有关的,这些暂时可以不用考虑,主要就是构建版本id变化的请求比如 zxid 之类的的请求,下面就是真正的在 finalRequestProcessor 中处理删除临时节点的逻辑了
org.apache.zookeeper.server.DataTree#processTxn(org.apache.zookeeper.txn.TxnHeader, org.apache.jute.Record, boolean)
public ProcessTxnResult processTxn(TxnHeader header, Record txn, boolean isSubTxn) {
// ... 省略部分代码
case OpCode.closeSession:
long sessionId = header.getClientId();
if (txn != null) {
killSession(sessionId, header.getZxid(),
ephemerals.remove(sessionId),
((CloseSessionTxn) txn).getPaths2Delete());
} else {
killSession(sessionId, header.getZxid());
}
break;
// ... 省略部分代码
}其实逻辑也很简单,从数据结构中移除
那么现在我问个问题,如果说意外情况下客户端丢失了连接会不会导致临时节点丢失呢?相信你已经有了答案,答案是在 session 过期时间内重连是不会的
那么来个升级版问题,如果说服务端重启了会不会导致临时节点丢失呢?我先说答案,答案是不会的,下面我们来看下代码
org.apache.zookeeper.server.ZooKeeperServer#takeSnapshot(boolean)
public void takeSnapshot(boolean syncSnap) {
long start = Time.currentElapsedTime();
try {
txnLogFactory.save(zkDb.getDataTree(), zkDb.getSessionWithTimeOuts(), syncSnap);
} catch (IOException e) {
LOG.error("Severe unrecoverable error, exiting", e);
// This is a severe error that we cannot recover from,
// so we need to exit
ServiceUtils.requestSystemExit(ExitCode.TXNLOG_ERROR_TAKING_SNAPSHOT.getValue());
}
long elapsed = Time.currentElapsedTime() - start;
LOG.info("Snapshot taken in {} ms", elapsed);
ServerMetrics.getMetrics().SNAPSHOT_TIME.add(elapsed);
}这块入口代码在第二个处理器中,每达到指定的条件,zk 后台线程会将内存数据打成快照进行持久化处理,同时打成快照的还有 session 和过期时间,这个时间不是某一时刻的具体时间,而是一段时间间隔,也就是只要 zk 不启动就永远不会丢失
zk集群状态下是怎么维护 session 的呢?下面我们聊聊集群状态下的 globalSession 与 localSession
三、zk 集群
1、角色
zk 中按不同的场景有两种角色的定义方式
第一种按照选举
Leader:主要负责数据的更新同步查询
Follower:主要向 Leader 提交数据的更新,提供查询,具有选举权和被选举权
Observer:主要提供查询,没有选举权和被选举权
第二种按照数据同步进行划分
Leader:主要负责更新数据跟同步数据
Learner:主要接受数据的同步
2、zk集群如何处理一次写提交
由于本次主要介绍 session 跟 临时节点的关系,zk 间的数据同步不会讲的很细,只会体现为逻辑上的 processor 的数据同步,LearnHandler FollowerServer 的等真实处理数据同步组件不会出现
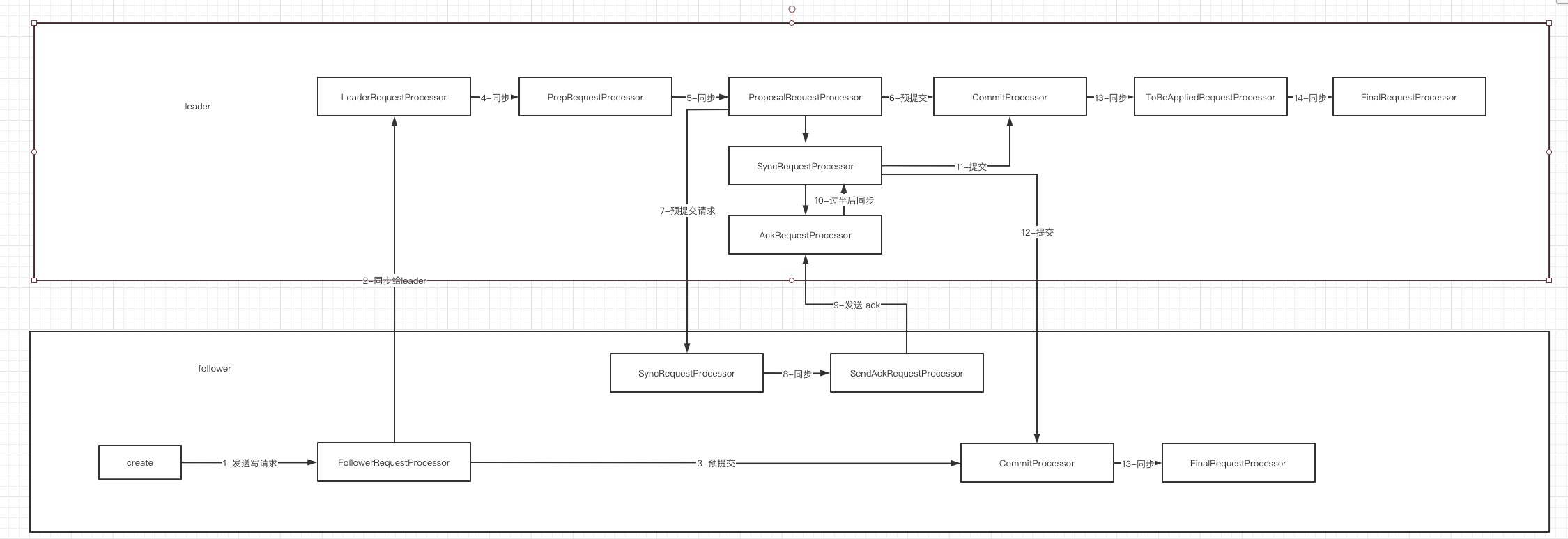
1、如果当前请求的节点为 follower 节点
2、如果当前请求为写请求那么会将该请求转发到 leader 节点
3、转发给 leader 节点后提交给 committProcessor,此时不会立即更新内存中的数据,而是会放到处理中的队列中
4、包含了 session 的升级下面会提到
5、提交给预提交处理器
6、提交给 committProcessor,此时不会立即更新内存中的数据,而是会放到处理中的队列中
7、之后会向 follower 节点发送一阶段提交请求
8、follower 节点收到后会写入 log 并转发给 下一个处理器
9、接下来给 leader 节点发送 ack 请求代表收到这个一阶段提交的请求并且处理成功
10、如果 leader 请求收到过半则 leader 节点进行持久化写 log
11、持久化后 commitProcessor 会进行真正的提交
12、将提交请求转发给 follower 进行真正的提交流程
13-14、修改内存完成提交
四、zk 集群中的临时节点
在开始之前想先聊下几个配置
localSessionsEnabled:是否开启 localSession
localSessionsUpgradingEnabled:是否允许 lcoalSession 升级为 globalSession
在了解什么是 localSession 与 globalSession 前不妨先考虑这样一个问题:session 在集群中应该由谁来维护?
由 Leader 节点维护:我们想一下 Learner 节点存在的意义是什么,是为了分担主节点的读压力,其实整个读操作根本不需要经过 Leader 节点,仅仅是查询当前节点的数据就够,那么我们来看看创建更改节点的操作,整个交互仅仅是 Follower 跟 Leader 节点间的通讯,根本与客户端没有关系,仅仅是增加了 session 的维护成本
由 Follower 节点维护:如果由 Follower 节点进行维护,那么来考虑下怎样维护临时节点。
正常情况:创建临时节点的时候按照如上流程进行创建,当 session 过期或者销毁的时候通知主节点删除临时节点,一切看起来很正常
异常情况:如果从节点发生了重启主从间的连接断开,那么是否要销毁临时节点呢?
不销毁:如果不销毁的情况下从节点不进行重连,那么临时节点将永久存在,在配置多个节点(A,B,C)的情况下,在 A 节点上创建了 临时节点,A 节点发生宕机,此时如果路由到 B 节点,在 A 不重启让临时节点过期的情况下那么临时节点将永久存在
销毁:销毁在客户端的视角下会发生莫名其妙丢失节点,配置多个节点(A,B,C)的情况下,在 A 节点上创建了 临时节点,A 节点发生宕机,此时如果路由到 B 节点,那么会发现临时节点已经丢了,并且不会触发回调
因此为避免上述问题,对应临时节点的 session 也要在 leader 节点维护一份
考虑到在 Leader 节点维护开销大的问题同时也兼顾节点一致的问题下诞生了上面两个配置
接下来我们看下之前第二小节留下的问题:为什么集群状态下重启会发生临时节点的丢失,而单机状态下不会
0、创建 session
下面是我的配置文件,我是两个选项都是打开的,创建连接的时候 server 端会进行判断,是否允许开启 localSession,如果允许的话则创建 localSession,不允许则创建 globalSession
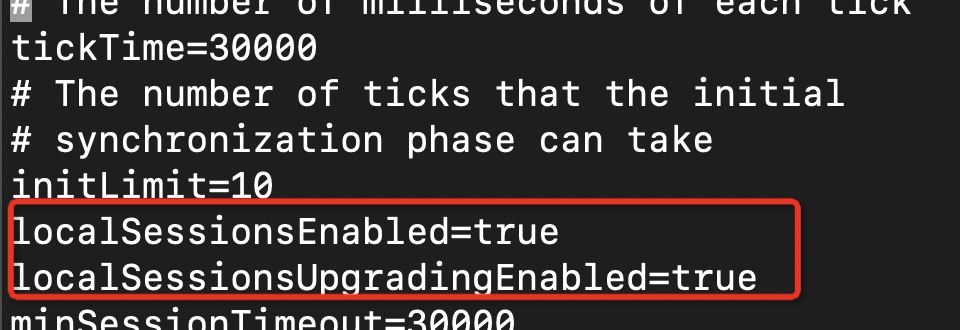
具体代码如下
// org.apache.zookeeper.server.ZooKeeperServer#processConnectRequest
long createSession(ServerCnxn cnxn, byte[] passwd, int timeout) {
if (passwd == null) {
// Possible since it's just deserialized from a packet on the wire.
passwd = new byte[0];
}
// 获取自增 id 并将维护 sessionId - SessionImpl 和 SessionImpl - expiryTime 的映射
long sessionId = sessionTracker.createSession(timeout);
Random r = new Random(sessionId ^ superSecret);
r.nextBytes(passwd);
ByteBuffer to = ByteBuffer.allocate(4);
to.putInt(timeout);
cnxn.setSessionId(sessionId);
// 将客户端的请求包装成 Request
Request si = new Request(cnxn, sessionId, 0, OpCode.createSession, to, null);
submitRequest(si);
return sessionId;
}
// org.apache.zookeeper.server.quorum.LearnerSessionTracker#createSession
public long createSession(int sessionTimeout) {
if (localSessionsEnabled) {
return localSessionTracker.createSession(sessionTimeout);
}
return nextSessionId.getAndIncrement();
}
// org.apache.zookeeper.server.SessionTrackerImpl#trackSession
public synchronized boolean trackSession(long id, int sessionTimeout) {
boolean added = false;
SessionImpl session = sessionsById.get(id);
if (session == null) {
session = new SessionImpl(id, sessionTimeout);
}
SessionImpl existedSession = sessionsById.putIfAbsent(id, session);
// ...省略部分代码
}
上述代码就是创建 localSession 的流程,其实最重要的代码就在后面,查看 sessionById 这个 Map 中有没有 id,有的话就不创建,没有的话就创建
1、发送写请求 create -e /test
按照 zk 集群中的流程首先经过的是 FollowerRequestProcessor ,这里会对 session 的类型进行校验,如果当前是 localSession 并且写的是临时节点会对 session 进行升级,但是发现如果没有配置 localSessionsUpgradingEnabled=true 的话会抛出异常,下面看下代码
// org.apache.zookeeper.server.quorum.QuorumZooKeeperServer#checkUpgradeSession
public Request checkUpgradeSession(Request request) throws IOException, KeeperException {
// ... 省略部分代码
CreateRequest createRequest = new CreateRequest();
request.request.rewind();
ByteBufferInputStream.byteBuffer2Record(request.request, createRequest);
request.request.rewind();
CreateMode createMode = CreateMode.fromFlag(createRequest.getFlags());
// 如果不是临时节点则直接返回
if (!createMode.isEphemeral()) {
return null;
// 如果没有开启 localSessionsUpgradingEnabled 会抛异常
if (!self.isLocalSessionsUpgradingEnabled()) {
throw new KeeperException.EphemeralOnLocalSessionException();
}
// session 升级
return makeUpgradeRequest(request.sessionId);
}
// org.apache.zookeeper.server.quorum.QuorumZooKeeperServer#makeUpgradeRequest
private Request makeUpgradeRequest(long sessionId) {
synchronized (upgradeableSessionTracker) {
// 判断当前是否是 localSession 其实就是判断 sessionId 这个 map 中有没有对应的 sessionId
if (upgradeableSessionTracker.isLocalSession(sessionId)) {
// session 升级
int timeout = upgradeableSessionTracker.upgradeSession(sessionId);
ByteBuffer to = ByteBuffer.allocate(4);
to.putInt(timeout);
// 同步给 leader
return new Request(null, sessionId, 0, OpCode.createSession, to, null);
}
}
return null;
}上面代码就是判断下当前是否是 localSession,如果是的话并且需要升级那么会进行如下三步:移除 localSession,将 session 加入到待升级队列,同步给 leader
2、同步给 Leader
经过 LeaderRequestProcessor 其实处理逻辑跟经过 FollowerRequestProcessor 差不多,但此时同步给 LeaderRequestProcessor 后请求类型已经发生改变 由 OpCode.create 变更为 OpCode.createSession 因此不再会进行上述处理
3、预提交给 CommitProcessor
这里面逻辑很复杂,就不细看代码了,其实可以理解为有两个队列 一个为 pending 队列,一个为 commit 队列,本次请求会保存到 pending 队列但是不会处理,直到 commit 队列也收到对应的响应之后才会处理,这里跟 zk 的二阶段提交有关系
4、同步给 PrepRequestProcessor
这里做的事情也很简单就是根据 follower 提交的 sessionId 创建 session
org.apache.zookeeper.server.PrepRequestProcessor#pRequest2Txn
protected void pRequest2Txn(int type, long zxid, Request request, Record record, boolean deserialize) throws KeeperException, IOException, RequestProcessorException {
// ...省略部分代码
case OpCode.createSession:
request.request.rewind();
int to = request.request.getInt();
request.setTxn(new CreateSessionTxn(to));
request.request.rewind();
// 创建 session
zks.sessionTracker.trackSession(request.sessionId, to);
zks.setOwner(request.sessionId, request.getOwner());
break;
// ...省略部分代码5、同步给 ProposalRequestProcessor
这个 processor 会对其他 follower 节点发送一阶段提交请求
org.apache.zookeeper.server.quorum.ProposalRequestProcessor#processRequest
public void processRequest(Request request) throws RequestProcessorException {
if (request instanceof LearnerSyncRequest) {
zks.getLeader().processSync((LearnerSyncRequest) request);
} else {
nextProcessor.processRequest(request);
if (request.getHdr() != null) {
// We need to sync and get consensus on any transactions
try {
// leader 节点给所有 follower 发送一阶段提交请求
zks.getLeader().propose(request);
} catch (XidRolloverException e) {
throw new RequestProcessorException(e.getMessage(), e);
}
// 同步成功后异步持久化
syncProcessor.processRequest(request);
}
}
}
6、预提交给 CommitProcessor
这里处理逻辑跟 #3 是一样的
7、预提交请求
这里 Leader 节点会发送 Leader.PROPOSAL 请求最终会被 org.apache.zookeeper.server.quorum.Learner 监听到处理
处理方式其实就是交给 SyncRequestProcessor 已经持久化处理
这时候你可能会有问题,follower 节点进行了持久化但是如果 leader 节点没同步成功怎么办,这不久数据不一致了?其实不会的,因为数据没有真正写到内存并且 zk 重启前会同步 leader 节点的数据,所以不会产生数据不一致
这时候你可能还会有问题,如果 leader 节点挂了并且数据当前节点选为 leader 节点了呢,那么当前节点的数据会同步给其他 follower 最后还是一致的
// org.apache.zookeeper.server.quorum.Learner#syncWithLeader
protected void syncWithLeader(long newLeaderZxid) throws Exception {
// ... 省略部分代码
case Leader.PROPOSAL:
PacketInFlight pif = new PacketInFlight();
logEntry = SerializeUtils.deserializeTxn(qp.getData());
pif.hdr = logEntry.getHeader();
pif.rec = logEntry.getTxn();
pif.digest = logEntry.getDigest();
if (pif.hdr.getZxid() != lastQueued + 1) {
LOG.warn(
"Got zxid 0x{} expected 0x{}",
Long.toHexString(pif.hdr.getZxid()),
Long.toHexString(lastQueued + 1));
}
lastQueued = pif.hdr.getZxid();
if (pif.hdr.getType() == OpCode.reconfig) {
SetDataTxn setDataTxn = (SetDataTxn) pif.rec;
QuorumVerifier qv = self.configFromString(new String(setDataTxn.getData()));
self.setLastSeenQuorumVerifier(qv, true);
}
packetsNotCommitted.add(pif);
break;
// ... 省略部分代码
if (zk instanceof FollowerZooKeeperServer) {
FollowerZooKeeperServer fzk = (FollowerZooKeeperServer) zk;
for (PacketInFlight p : packetsNotCommitted) {
fzk.logRequest(p.hdr, p.rec, p.digest);
}
for (Long zxid : packetsCommitted) {
fzk.commit(zxid);
}
}
}
// org.apache.zookeeper.server.quorum.FollowerZooKeeperServer#logRequest
public void logRequest(TxnHeader hdr, Record txn, TxnDigest digest) {
Request request = new Request(hdr.getClientId(), hdr.getCxid(), hdr.getType(), hdr, txn, hdr.getZxid());
request.setTxnDigest(digest);
if ((request.zxid & 0xffffffffL) != 0) {
pendingTxns.add(request);
}
syncProcessor.processRequest(request);
}8、同步给 SendAckRequestProcessor
这里逻辑其实很简单,就是给 leader 节点发送类型为 Leader.ACK 的请求
org.apache.zookeeper.server.quorum.SendAckRequestProcessor#processRequest
public void processRequest(Request si) {
if(si.type != OpCode.sync){
QuorumPacket qp = new QuorumPacket(Leader.ACK, si.hdr.getZxid(), null,
null);
try {
learner.writePacket(qp, false);
} catch (IOException e) {
LOG.warn("Closing connection to leader, exception during packet send", e);
try {
if (!learner.sock.isClosed()) {
learner.sock.close();
}
} catch (IOException e1) {
// Nothing to do, we are shutting things down, so an exception here is irrelevant
LOG.debug("Ignoring error closing the connection", e1);
}
}
}
}9、发送 ack
10、过半后同步
AckRequestProcessor 会有过半监测机制,如果没有过半 hasCommitted 会返回 false 不会进行后续处理
// org.apache.zookeeper.server.quorum.Leader#processAck
public synchronized void processAck(long sid, long zxid, SocketAddress followerAddr) {
// ... 省略部分代码
p.addAck(sid);
boolean hasCommitted = tryToCommit(p, zxid, followerAddr);
if (hasCommitted && p.request != null && p.request.getHdr().getType() == OpCode.reconfig) {
long curZxid = zxid;
while (allowedToCommit && hasCommitted && p != null) {
curZxid++;
p = outstandingProposals.get(curZxid);
if (p != null) {
hasCommitted = tryToCommit(p, curZxid, null);
}
}
}
}
// org.apache.zookeeper.server.quorum.Leader#tryToCommit
public synchronized boolean tryToCommit(Proposal p, long zxid, SocketAddress followerAddr) {
// ... 省略部分代码
if (!p.hasAllQuorums()) {
return false;
}
// ... 省略部分代码
return true;
}
// org.apache.zookeeper.server.quorum.SyncedLearnerTracker#hasAllQuorums
public boolean hasAllQuorums() {
for (QuorumVerifierAcksetPair qvAckset : qvAcksetPairs) {
if (!qvAckset.getQuorumVerifier().containsQuorum(qvAckset.getAckset())) {
return false;
}
}
return true;
}
// org.apache.zookeeper.server.quorum.flexible.QuorumMaj#containsQuorum
public boolean containsQuorum(Set<Long> ackSet) {
return (ackSet.size() > half);
}
11、提交
如果收到的 ack 过半之后会将请求放到 commit 队列中,之后 commitRequestProcessor 会进行后续处理,也就是提交到 commit 队列
// org.apache.zookeeper.server.quorum.Leader#tryToCommit
public synchronized boolean tryToCommit(Proposal p, long zxid, SocketAddress followerAddr) {
// ... 省略部分代码
zk.commitProcessor.commit(p.request);
if (pendingSyncs.containsKey(zxid)) {
for (LearnerSyncRequest r : pendingSyncs.remove(zxid)) {
sendSync(r);
}
}
return true;
}
// org.apache.zookeeper.server.quorum.CommitProcessor#commit
public void commit(Request request) {
if (stopped || request == null) {
return;
}
LOG.debug("Committing request:: {}", request);
request.commitRecvTime = Time.currentElapsedTime();
ServerMetrics.getMetrics().COMMITS_QUEUED.add(1);
committedRequests.add(request);
wakeup();
}12、提交
提交也就是同步给 follower 节点告诉他们可以将请求提交到 commit 队列了
// org.apache.zookeeper.server.quorum.Leader#tryToCommit
public synchronized boolean tryToCommit(Proposal p, long zxid, SocketAddress followerAddr) {
// ... 省略部分代码
zk.commitProcessor.commit(p.request);
if (pendingSyncs.containsKey(zxid)) {
for (LearnerSyncRequest r : pendingSyncs.remove(zxid)) {
sendSync(r);
}
}
return true;
}
// org.apache.zookeeper.server.quorum.Leader#sendSync
public void sendSync(LearnerSyncRequest r) {
QuorumPacket qp = new QuorumPacket(Leader.SYNC, 0, null, null);
r.fh.queuePacket(qp);
}
// org.apache.zookeeper.server.quorum.FollowerZooKeeperServer#sync
public synchronized void sync() {
if (pendingSyncs.size() == 0) {
LOG.warn("Not expecting a sync.");
return;
}
Request r = pendingSyncs.remove();
if (r instanceof LearnerSyncRequest) {
LearnerSyncRequest lsr = (LearnerSyncRequest) r;
lsr.fh.queuePacket(new QuorumPacket(Leader.SYNC, 0, null, null));
}
commitProcessor.commit(r);
}13-14、同步
13 14 的同步其实逻辑都一样,只不过 leader 多了个 toBeApplyRequestProcessor 这里面干的事情不多,之前接受到 ack 请求同时会将一阶段提交队列中的请求放到 toBeApply 队列中,这个 processor 的功能就是从 toBeApply 队列中移除,最终 Leader 还是提交给 finalRequestProcessor
// org.apache.zookeeper.server.ZooKeeperServer#processTxnForSessionEvents
private void processTxnForSessionEvents(Request request, TxnHeader hdr, Record txn) {
int opCode = (request == null) ? hdr.getType() : request.type;
long sessionId = (request == null) ? hdr.getClientId() : request.sessionId;
if (opCode == OpCode.createSession) {
if (hdr != null && txn instanceof CreateSessionTxn) {
CreateSessionTxn cst = (CreateSessionTxn) txn;
sessionTracker.commitSession(sessionId, cst.getTimeOut());
} else if (request == null || !request.isLocalSession()) {
LOG.warn("*****>>>>> Got {} {}", txn.getClass(), txn.toString());
}
} else if (opCode == OpCode.closeSession) {
sessionTracker.removeSession(sessionId);
}
}
// Follower 的 commitSession 处理
// org.apache.zookeeper.server.quorum.LearnerSessionTracker#commitSession
public synchronized boolean commitSession(long sessionId, int sessionTimeout) {
boolean added = globalSessionsWithTimeouts.put(sessionId, sessionTimeout) == null;
if (localSessionsEnabled) {
removeLocalSession(sessionId);
finishedUpgrading(sessionId);
}
touchTable.get().put(sessionId, sessionTimeout);
return added;
}
// Leader 的 commitSession 处理
// org.apache.zookeeper.server.quorum.LeaderSessionTracker#commitSession
public synchronized boolean commitSession(
long sessionId, int sessionTimeout) {
boolean added = globalSessionTracker.commitSession(sessionId, sessionTimeout);
if (localSessionsEnabled) {
removeLocalSession(sessionId);
finishedUpgrading(sessionId);
}
return added;
}这个阶段其实就是维护 session 跟过期时间,并且将 session 从 localSession 的数据结构中移除,还记得我们之前创建 session 添加的升级中的 session map 数据结构吗,升级完成后也会移除
最终 leader 维护在 sessionsWithTimeout 这个map 中,follower 维护在 globalSessionsWithTimeouts 这个 map 中
----------------------
整个 session我们就分析完了,其实临时节点的创建跟 session 差不多,最终跟但节点一样,会将 session 跟临时节点绑定,最终每个节点都会维护一个 session(比如 A B C集群,在 A 上创建 globalSession 会同时在 B C 都创建 session 节点)也就是即使重启后连接另外的节点也不会导致 session 和 临时节点丢失
最后
以上就是威武航空最近收集整理的关于浅谈 Zookeeper 中的 Session 与 临时节点一、临时节点三、zk 集群四、zk 集群中的临时节点的全部内容,更多相关浅谈内容请搜索靠谱客的其他文章。








发表评论 取消回复