一,重启机制(手动重启)
1,不保留工作的RM重启
在Hadoop-2.4.0版本实现,当Client提交一个application给RM时,RM会将该application的相关信息存储起来,具体存储的位置是可以在配置文件中指定的,可以存储到本地文件系统上,也可以存储到HDFS或者是Zookeeper上,此外RM也会保存application的最终状态信息(failed,killed,finished),如果是在安全环境下运行,RM还会保存相关证书文件。
当RM被关闭后,NodeManager(以下简称NM)和Client由于发现连接不上RM,会不断的向RM发送消息,以便于能及时确认RM是否已经恢复正常,当RM重新启动后,它会发送一条re-sync(重新同步)的命令给所有的NM和ApplicationMaster(以下简称AM),NM收到重新同步的命令后会杀死所有的正在运行的containers并重新向RM注册,从RM的角度来看,每台重新注册的NM跟一台新加入到集群中NM是一样的。
AM收到重新同步的命令后会自行将自己杀掉。接下来,RM会将存储的关于application的相关信息读取出来,将在RM关闭之前最终状态为正在运行中的application重新提交运行。
2,保留工作的RM重启
从Hadoop-2.6.0开始增强了RM重启功能,与不保留工作不同的地方在于,RM会记录下container的整个生命周期的数据,包括application运行的相关数据,资源申请状况,队列资源使用状况等数据。
当RM重启之后,会读取之前存储的关于application的运行状态的数据,同时发送re-sync的命令,与第一种方式不同的是,NM在接受到重新同步的命令后并不会杀死正在运行的containers,而是继续运行containers中的任务,同时将containers的运行状态发送给RM。
之后,RM根据自己所掌握的数据重构container实例和相关的application运行状态,如此一来,就实现了在RM重启之后,紧接着RM关闭时任务的执行状态继续执行。
3,配置
# 作业信息保存在zookeeper
<property>
<name>hadoop.zk.address</name>
<value>node1.cn:2181,node2.cn:2181,node3.cn:2181</value>
</property>
# 启动重启机制
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
4,注意,RM挂了之后并不会自动重启,需要手动快速重启
二,高可用
ResourceManager(RM)负责管理群集中的资源和调度应用程序(如MR、Spark等)。
在Hadoop 2.4之前,YARN群集中的ResourceManager存在SPOF(Single Point of Failure,单点故障)。
为了解决ResourceManager的单点问题,YARN设计了一套Active/Standby模式的ResourceManager HA(High Availability,高可用)架构。
在运行期间有多个ResourceManager同时存在来增加冗余进而消除这个单点故障,并且只能有一个ResourceManager处于Active状态,其他的则处于Standby状态,当Active节点无法正常工作,其余Standby状态的几点则会通过竞争选举产生新的Active节点。
当有多个RM时,Clients和NMs通过读取yarn-site.xml配置找到所有ResourceManager。Clients、AM和NM会轮训所有的ResourceManager并进行连接,直到找着Active状态的RM。如果Active状态的RM也出现故障,它们就会继续查找,直到找着新的Active状态的RM。
1, 故障转移(主备切换原理)
YARN这个Active/Standby模式的RM HA架构在运行期间,会有多个RM同时存在,但只能有一个RM处于Active状态,其他的RM则处于Standby状态,当Active节点无法正常提供服务,其余Standby状态的RM则会通过竞争选举产生新的Active节点。以基于ZooKeeper这个自动故障切换为例,切换的步骤如下:
-
主备切换,RM使用基于ZooKeeper实现的ActiveStandbyElector组件来确定RM的状态是Active或Standby。
-
创建锁节点,在ZooKeeper上会创建一个叫做ActiveStandbyElectorLock的锁节点,所有的RM在启动的时候,都会去竞争写这个临时的Lock节点,而ZooKeeper能保证只有一个RM创建成功。创建成功的RM就切换为Active状态,并将信息同步存入到ActiveBreadCrumb这个永久节点,那些没有成功的RM则切换为Standby状态。
-
注册Watcher监听,所有Standby状态的RM都会向/yarn-leader-election/cluster1/ActiveStandbyElectorLock节点注册一个节点变更的Watcher监听,利用临时节点的特性,能够快速感知到Active状态的RM的运行情况。
-
准备切换,当Active状态的RM出现故障(如宕机或网络中断),其在ZooKeeper上创建的Lock节点随之被删除,这时其它各个Standby状态的RM都会受到ZooKeeper服务端的Watcher事件通知,然后开始竞争写Lock子节点,创建成功的变为Active状态,其他的则是Standby状态。
-
Fencing(隔离),在分布式环境中,机器经常出现假死的情况(常见的是GC耗时过长、网络中断或CPU负载过高)而导致无法正常对外进行及时响应。如果有一个处于Active状态的RM出现假死,其他的RM刚选举出来新的Active状态的RM,这时假死的RM又恢复正常,还认为自己是Active状态,这就是分布式系统的脑裂现象,即存在多个处于Active状态的RM,可以使用隔离机制来解决此类问题。
-
YARN的Fencing机制是借助ZooKeeper数据节点的ACL权限控制来实现不同RM之间的隔离。这个地方改进的一点是,创建的根ZNode必须携带ZooKeeper的ACL信息,目的是为了独占该节点,以防止其他RM对该ZNode进行更新。借助这个机制假死之后的RM会试图去更新ZooKeeper的相关信息,但发现没有权限去更新节点数据,就把自己切换为Standby状态
总结下:1,所有的RM去ZOOKEEPER注册竞争主节点地位,只有一个能够抢到lock节点的写权限,抢到的即为activie,抢不到的为standby;
2,active的rm宕机或者假死之后,zookeeper会删除lock节点,其他的RM再次竞争;
3,为了防止脑裂,zookeeper要求携带acl控制信息才能访问根节点,宕机或假死的active rm的act会被失效,假死之后复活的rm尝试作为active去和zookeeper交互,发现其act失效,会将自身置为standby。
2,配置
yarn-site.xml
<!-- 启用RM HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- RM HA集群标识ID -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!-- RM HA集群中各RM的逻辑标识 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- rm1运行主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1.itcast.cn</value>
</property>
<!-- rm2运行主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2.itcast.cn</value>
</property>
<!-- rm1 WebUI地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<!-- rm2 WebUI地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<!-- 开启自动故障转移 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- zk集群的地址 -->
<property>
<name>hadoop.zk.address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<!-- 开启rm状态恢复重启机制 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 使用zk集群存储RM状态数据 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
<!-- 开启yarn日志聚集功能,收集每个容器的日志集中存储在一个地方 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置为一天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
3,检查
yarn rmadmin -getAllServiceState
总结:
rm挂掉之后,lock节点被删除,standby状态的rm会来抢占创建lock节点,谁先创建lock节点,谁就是新的rm。
三,架构体系
构成:
- 组件:ResourceManager、NodeManager、ApplicationMaster
- 其他:client、container(资源的抽象与隔离,将物理节点分割为多个container)
核心交互:
- 作业提交 client------>RM
- 资源申请 container(am)--------->RM
- 作业状态汇报 container(MR task)------>container(AM)
- 节点状态汇报 NM------------->RM
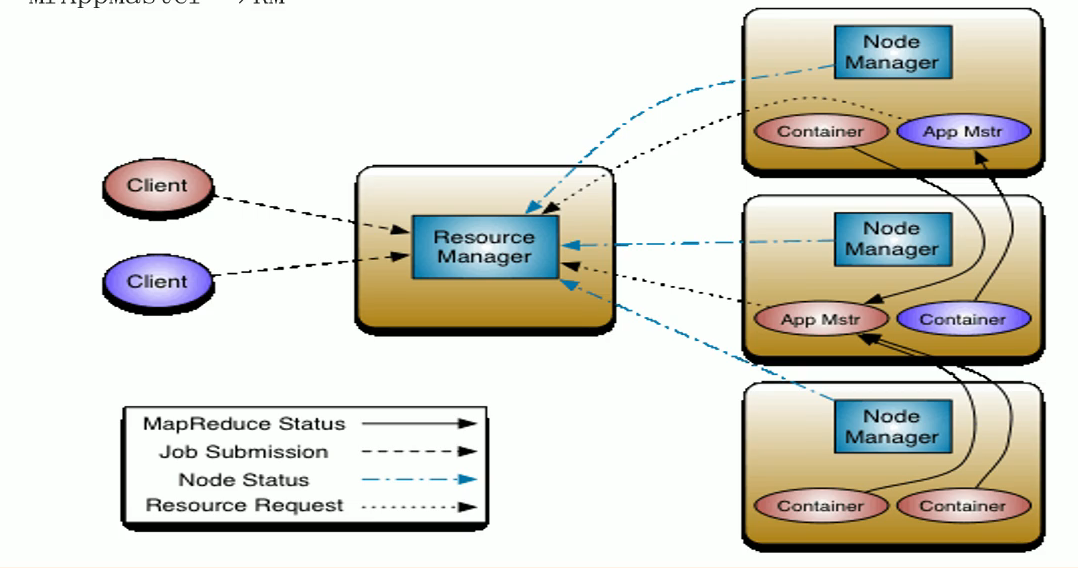
多个作业由多个AM,RM和NM是从集群的角度来说的,AM是从任务的角度来说的。
RM
包括scheduler和Applications Manager
- scheduler:根据容量、队列等限制条件,分配资源给正在运行的应用
- Applications Manager:管理所有的应用程序:应用程序提交、与scheduler交互获取资源启动AM,监控AM,重启AM
NM
负责节点的资源管理
- 汇报NM的资源使用情况
- 和AM沟通启动container
AM
- 根据作业需求向RM请求资源
- 与NM交互启动container
- 监控任务运行状态,任务失败是重新申请资源重启任务
- AM是一个抽象,不同的任务需要自己实现AM,yarn自带MapReduce的实现。其他需要使用yarn做资源管理的框架需要实现AM,如果spark要实现spark版本的AM,flink要实现flink版本的AM
- 是计算框架和资源的接口,计算框架通过AM向资源管理器申请资源
container
实现对资源的封装以资源隔离
通信-RPC
四,yarn提交任务流程
-
1,客户端向RM申请运行一个Application,RM收到请求后,生成ApplicationId和资源提交路径并返回给client;client将Application运行需要的资源提交到hdfs,默认是
/tmp/hadoop-yarn/staging/root/.staging -
2,客户端提交资源后,申请运行AppMaster,RM将其初始化为一个task,放入队列中等待调度执行。客户端的工作就完成了
-
3,当NM有空闲资源时,scheduler调度器向NM发送指令,NM领取任务创建容器、启动ApplicationMaster。
-
4,AM启动后,向RM注册并保持联系,从hdfs中获取资源、解析资源,获取任务信息并计算所需要的资源,根据计算结果向RM申请资源
-
5,RM收到AM的请求后,将其放入scheduler的队列中等待调度
-
6,NM有空闲资源时,RM向NM发送指令创建Container,领取任务,创建容器
-
7,NM容器创建完成后,AM将程序发送给NM的容器,容器启动YarnChild进程运行Map任务
-
8,AM监控任务运行情况
-
9,Map任务完成后,AM向RM申请资源运行reducetask
-
10,所有任务完成后,AM向RM申请注销自己,释放资源。。
五,yarn ui
- yarn ui的问题,只能查看运行中的日志,无法查看已经完成的任务的日志
- yarn重启后,连完成的任务都找不到了
JobHistoryServer可以解决历史任务详细信息看不到的问题
六,JobHistoryServer
配置:
1,mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/mr-history/intermediate</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/mr-history/done</value>
</property>
2,开启日志聚合
MapReduce 是在各个机器上运行的, 在运行过程中产生的日志存在于各个机器上,为了能够统一查看各个机器的运行日志,将日志集中存放在 HDFS 上, 这个过程就是日志聚集。
yarn-site.xml
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/app-logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
3,启动
[root@node1 ~]# mr-jobhistory-daemon.sh start historyserver
## 或者如下命令:
[root@node1 ~]# mapred --daemon start historyserver
4,访问
http://node1:19888/jobhistory
六,timelineserver
JobHistoryServer只能查看mr任务的信息,不能查看spark、flink的信息,针对这个问题,spark、flink都要提供自己的server,为了统一,yarn提供了timelineserver,Jobhistoryserver可以看作是timelineserver的一部分,timelineserver是jobhistoryserver的升级版。
配置:
yarn-site.xml
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>node2</value>
<description>设置YARN Timeline服务地址</description>
</property>
<property>
<name>yarn.timeline-service.address</name>
<value>node2:10200</value>
<description>设置YARN Timeline服务启动RPC服务器的地址,默认端口10200</description>
</property>
<property>
<name>yarn.timeline-service.webapp.address</name>
<value>node2:8188</value>
<description>设置YARN Timeline服务WebUI地址</description>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
<description>设置RM是否发布信息到Timeline服务器</description>
</property>
<property>
<name>yarn.timeline-service.generic-application-history.enabled</name>
<value>true</value>
<description>设置是否Timelinehistory-servic中获取常规信息,如果为否,则是通过RM获取</description>
</property>
重启YARN服务:
stop-yarn.sh
start-yarn.sh
启动命令如下:
注意要在node1上启动
yarn --daemon start timelineserver
## 或
yarn-daemon.sh start timelineserver
查看:
http://node1:8188/applicationhistory
七,资源隔离
yarn实现了对内存和CPU的隔离
八,资源调度
调度策略
- FIFO
- Capacity Scheduler,apache版本的默认调度策略
- Fari Scheduler
队列:
- Scheduler最重要的工作就是按照一定的策略为队列中的task分配执行所需的资源。
FIFO调度器
- 先提交的应用先运行,遇到大任务时,会阻塞后面的小任务的执行。
Capacity Scheduler
- 开启:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
- 资源队列划分:
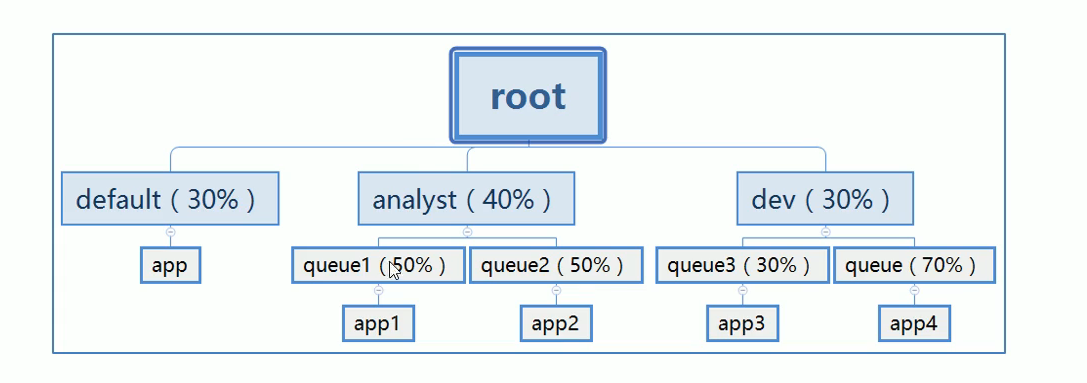
举例:容量调度如何平衡大小任务的资源占用问题
- 对于Capacity调度器,通常配置一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。
配置:
capacity-scheduler.xml
<configuration>
<!-- root下分为两个队列,分别为prod和dev -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<!-- dev继续分为两个队列,分别为eng和science -->
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>eng,science</value>
</property>
<!-- 设置prod队列40% -->
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<!-- 设置dev队列60% -->
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<!-- 设置dev队列可使用的资源上限为75% -->
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<!-- 设置eng队列50% -->
<property>
<name>yarn.scheduler.capacity.root.dev.eng.capacity</name>
<value>50</value>
</property>
<!-- 设置science队列50% -->
<property>
<name>yarn.scheduler.capacity.root.dev.science.capacity</name>
<value>50</value>
</property>
</configuration>
生效:
- 修改配置后执行如下命令,让配置生效
yarn rmadmin -refreshQueues
使用:
- 在代码中指定queue名称
conf.set("mapreduce.job.queuename", "prod");
- 提交job时命令行指定
yarn jar /export/data/jar/hadooptes.jar com.lcy.wordcount.mr.WordCountMr -Dmapreduce.job.queuename=prod
Fair Scheduler(公平调度器)
FairScheduler是Hadoop可插拔的调度程序,提供了YARN应用程序公平地共享大型集群中资源的另一种方式。
FairScheduler是一个将资源公平的分配给应用程序的方法,使所有应用在平均情况下随着时间的流逝可以获得相等的资源份额。
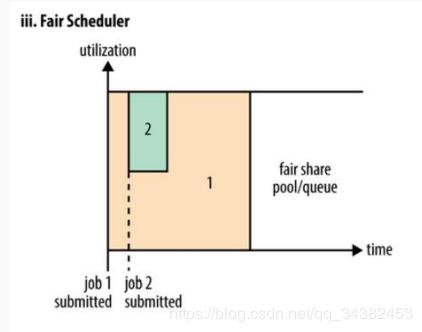
公平调度可以在多个队列:
- 当A启动一个job而B没有任务时,A会获得全部集群资源;
- 当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。
- 如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会各自使用四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享
- 在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。如下图所示,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
- 需要注意的是,在图中Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。
案例:多租户(多用户)资源隔离
启用:yarn-site.xml
配置官方参考文档
<configuration>
<!-- yarn之前的配置属性不需要修改 -->
<!-- 指定使用fairScheduler的调度方式 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- 指定fair资源分配配置文件路径 -->
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/export/server/hadoop-2.7.5/etc/hadoop/fair-scheduler.xml</value>
</property>
<!-- 是否启用资源抢占,如果启用,那么当该队列资源使用
yarn.scheduler.fair.preemption.cluster-utilization-threshold 这么多比例的时候,就从其他空闲队列抢占资源
-->
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name>
<value>0.8f</value>
</property>
<!-- 设置成true,当任务中未指定队列的时候,将以用户名作为队列名。
这个配置就实现了根据用户名自动分配队列。 -->
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
</property>
<!-- 是否允许创建未定义的队列。
如果设置成true,yarn将会自动创建任务中指定的未定义过的队列。
设置成false之后,任务中指定的未定义的队列将无效,该任务会被分配到default资源池中。
如果在分配文件中给出了队列放置策略queuePlacementPolicy ,则将忽略此属性。 -->
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
</property>
</configuration>
fair-scheduler.xml
<?xml version="1.0"?>
<allocations>
<!-- 设置每个用户提交运行应用的最大数量为30 -->
<userMaxAppsDefault>30</userMaxAppsDefault>
<!-- 定义队列,所有队列都是root的子队列 -->
<queue name="root">
<aclSubmitApps> </aclSubmitApps>
<aclAdministerApps> </aclAdministerApps>
<queue name="hadoop">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>2.0</weight>
<!-- 可以将应用程序提交到队列的用户和/或组的列表。 -->
<!-- 格式为:用户名 用户组 -->
<!-- 多个用户时:user1,user2 group1,group2 -->
<aclSubmitApps>hadoop hadoop</aclSubmitApps>
<!-- 允许管理任务的用户名和组,格式同上 -->
<aclAdministerApps>hadoop hadoop</aclAdministerApps>
</queue>
<queue name="spark">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<!-- 抢夺资源时依据weight划分优先级 -->
<weight>1.0</weight>
<aclSubmitApps>spark spark</aclSubmitApps>
<aclAdministerApps>spark spark</aclAdministerApps>
</queue>
<queue name="develop">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fifo</schedulingMode>
<weight>1.5</weight>
<aclSubmitApps>hadoop,develop,spark</aclSubmitApps>
<aclAdministerApps>hadoop,develop,spark</aclAdministerApps>
</queue>
<!-- 所有的任务如果不指定任务队列,都提交到default队列里面来 -->
<queue name="default">
<minResources>512mb,4vcores</minResources>
<maxResources>30720mb,30vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.0</weight>
<aclSubmitApps>*</aclSubmitApps>
</queue>
</queue>
</allocations>
九,核心参数配置
RM:
-
设置YARN使用调度器,默认值:(不同版本YARN,值不一样)
yarn.resourcemanager.scheduler.class -
Apache 版本 YARN ,默认值为容量调度器;
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler -
CDH 版本 YARN ,默认值为公平调度器;
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler -
ResourceManager处理调度器请求的线程数量,默认50,如果YARN运行任务Job比较多,可以将值调整大一下。
yarn.resourcemanager.scheduler.client.thread-count
NM 核心参数:
NodeManager运行在每台机器上,负责具体的资源管理
- 参数一:yarn.nodemanager.resource.detect-hardware-capabilities
是否让yarn自己检测硬件进行配置,默认false,如果设置为true,那么就会自动探测NodeManager所在主机的内存和CPU。 - 参数二:yarn.nodemanager.resource.count-logical-processors-as-cores
是否将虚拟核数当作CPU核数,默认false。 - 参数三:yarn.nodemanager.resource.pcores-vcores-multiplier
虚拟核数和物理核数乘数,例如:4核8线程,该参数就应设为2,默认1.0。 - 参数四:yarn.nodemanager.resource.memory-mb
NodeManager使用内存,默认8G - 参数五:yarn.nodemanager.resource.system-reserved-memory-mb
此参数,仅仅当上述参数一为true和参数四为-1时,设置才生效;
默认值:20% of (system memory - 2*HADOOP_HEAPSIZE) - 参数六:yarn.nodemanager.resource.cpu-vcores
NodeManager使用CPU核数,默认8个。 - 参数七:其他参数,使用默认值即可
- 参数:yarn.nodemanager.pmem-check-enabled,是否开启物理内存检查限制container,默认打开;
- 参数:yarn.nodemanager.vmem-check-enabled,是否开启虚拟内存检查限制container,默认打开;
- 参数:yarn.nodemanager.vmem-pmem-ratio,虚拟内存物理内存比例,默认2.1;
Contanier 核心参数:
当应用程序提交运行至YARN上时,无论是AppMaster运行,还是Task(MapReduce框架)或Executor(Spark框架)或TaskManager(Flink框架)运行,NodeManager将资源封装在Contanier容器中,以便管理和监控,核心配置参数如下所示:
-
参数一:yarn.scheduler.minimum-allocation-mb
单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。 -
参数二:yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。 -
参数三:yarn.scheduler.minimum-allocation-vcores
单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。 -
参数四:yarn.scheduler.maximum-allocation-vcores
单个任务可申请的最多虚拟CPU个数,默认是4。
最后
以上就是魁梧宝贝最近收集整理的关于yarn学习笔记的全部内容,更多相关yarn学习笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复