C51语言
C51语言与标准C语言间有许多相同地方,但也有自身特点。不同的嵌入式C语言编译系统之所以与标准C语言有不同的地方,主要是由于它们所针对的硬件系统不同。对于8051单片机,目前广泛使用的是C51语言。
C51语言基本语法与标准C相同,是在标准C的基础上进行适合8051内核单片机硬件的扩展,但与标准c又有不同之处:
- 库函数不同:
例如,在标准C中,库函数printf和scanf,常用于屏幕打印和接收字符,而在C51语言中,主要用于串行口数据的收发。 - 数据类型有一定区别:
例如,8051单片机包含位操作空间和丰富的位操作指令,因此,C51语言与标准C语言相比增加了位类型。 - C51语言变量存储模式与标准C语言中变量存储模式数据不同:
标准C最初是为通用计算机设计的,在通用计算机中只有一个程序和数据统一寻址的内存空间,而C51语言中变量的存储模式与8051单片机的各种存储器区紧密相关。 - 数据存储类型不同:
8051存储区可分为内部数据存储区、外部数据存储区以及程序存储区。 - 其他不同:
中断。标准C语言没有处理单片机中断的定义,而C51语言中有专门的中断函数。
头文件。C51语言头文件必须把8051单片机内部的外设硬件资源(如定时器、中断、I/O等)相应的特殊功能寄存器写入到头文件内,而标准C不用。
程序结构。由于8051单片机的硬件资源有限,它的编译系统不允许太多的程序嵌套。其次,标准C语言所具备的递归特性不被C51语言支持。
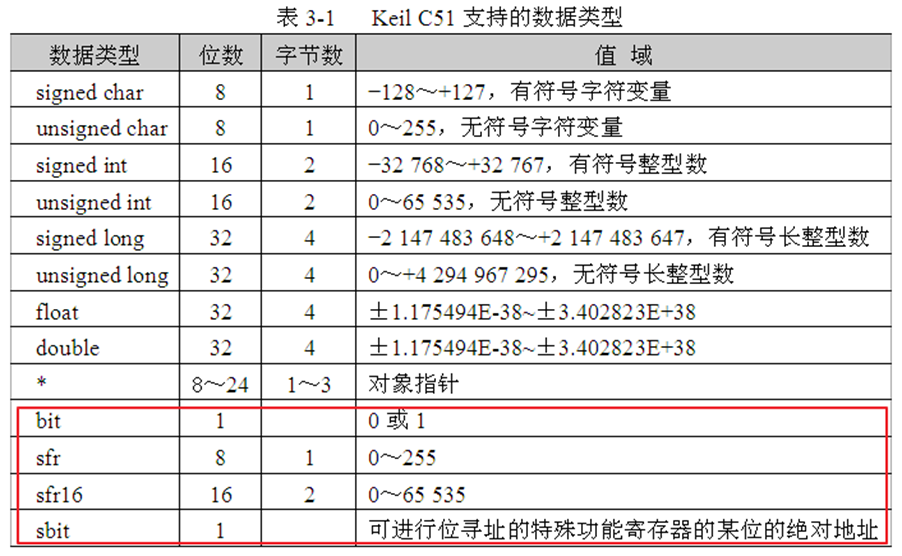
Keil C51支持的基本数据类型见下表
C51的注释写法有两种:
(1) //…… ,两个斜杠后面跟着的为注释语句,本写法只能注释一行,当换行时,必须在新行上重新写两个斜杠。
(2) /*……*/ ,一个斜杠与星号结合使用,本写法可注释任一行,即斜杠星号与星号斜杠之间的所有文字都作为注释,即注释有多行时,只需在注释的开始处,加斜杠星号,在注释的结尾处,加上星号斜杠即可。
加注释的目的是为了便于读懂程序,所有注释都不参与程序编译,编译器在编译过程中会自动删去注释。
C51语言允许通过使用关键字sfr、sbit或直接引用编译器提供的头文件来对特殊功能寄存器(SFR)进行访问,特殊功能寄存器分布在片内RAM高128字节中,只能采用直接寻址方式。
(1)使用关键字定义sfr。为能直接访问特殊功能寄存器SFR,C51提供了一种定义方法,即引入关键字sfr,语法如下:
sfr 特殊功能寄存器名字=特殊功能寄存器地址,例如:
sfr IE=0xA8; //中断允许寄存器IE地址A8H
sfr TCON=0x88; //定时器/计数器控制寄存器地址88H
在8051中,要访问16位SFR,要用关键字sfr16。16位SFR的低字节地址须作为“sfr16”的定义地址,例如:
sfr16 DPTR=0x82 //DPTR 的低8位地址为82H,高8位地址为83H。
(2)通过头文件访问SFR。各种衍生型的8051单片机的特殊功能寄存器的数量与类型有时是不相同的,对其访问可通过头文件访问来进行。为用户处理方便,C51把8051(或8052单片机)常用的特殊功能寄存器和其中的可寻址位进行了定义,放在一个reg51.h(或reg52.h)的头文件中。当用户要使用时,只需在使用之前用一条预处理命令#include<reg51.h>把这个头文件包含到程序中,就可使用特殊功能寄存器名和其中的可寻址位名称了。用户可对头文件进行增减。头文件引用举例如下:
#include<reg51.h> //包含8051单片机的头文件
void main(void)
{
TL0=0xf0; //给T0低字节TL0设置时间常数,已在reg51.h中定义
TH0=0x3f; //给T0高字节TH0设置时间常数,已在reg51.h中定义
TR0=1; //启动定时器0
……
}
(3)特殊功能寄存器中的位定义。对SFR中的可寻址位的访问,要使用关键字来定义可寻址位,共3种方法。
- sbit 位名=特殊功能寄存器^位置;例如:
sfr PSW=0xd0; //定义PSW 寄存器的字节地址0xd0
sbit CY=PSW^7; //定义CY位为PSW.7,地址为0xd0
sbit OV=PSW^2; //定义OV位为PSW.2,地址为0xd2
- sbit 位名=字节地址^位置; 例如:
sbit CY=0xd0^7; // CY位地址为0xd7
sbit OV=0xd0^2; // OV位地址为0xd2
- sbit 位名=位地址(将位的绝对地址赋给变量,位地址必须在0x80~0xff。)例如:
sbit CY=0xd7; // CY位地址为0xd7
sbit OV=0xd2; // OV位地址为0xd2
【例】AT89C51单片机片内P1口的各寻址位的定义如下:
sfr P1=0x90;
sbit P1_7= P1^7;
sbit P1_6= P1^6;
sbit P1_5= P1^5;
sbit P1_4= P1^4;
sbit P1_3= P1^3;
sbit P1_2= P1^2;
sbit P1_1= P1^1;
sbit P1_0= P1^0;
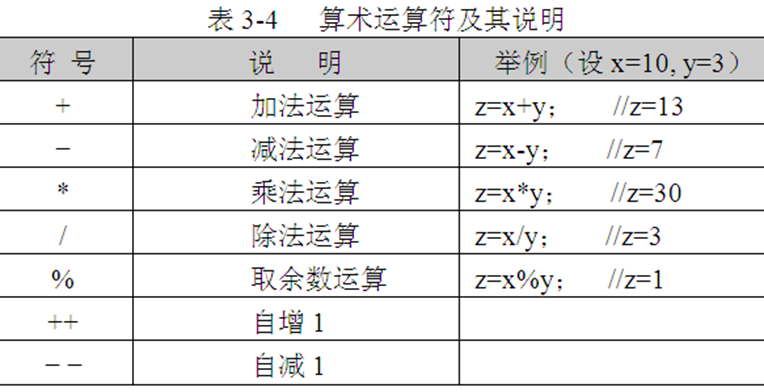
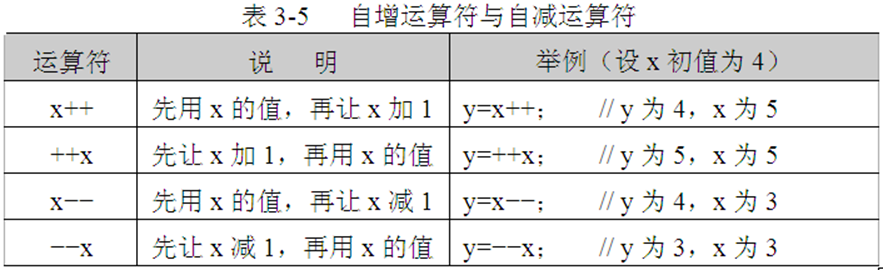
1.算术运算符
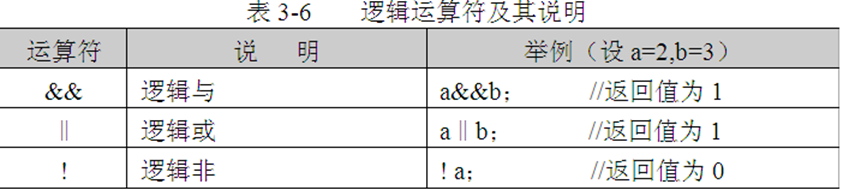
2.逻辑运算符
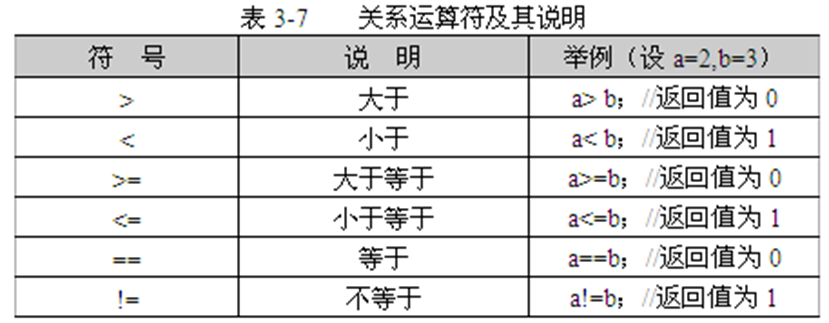
3.关系运算符
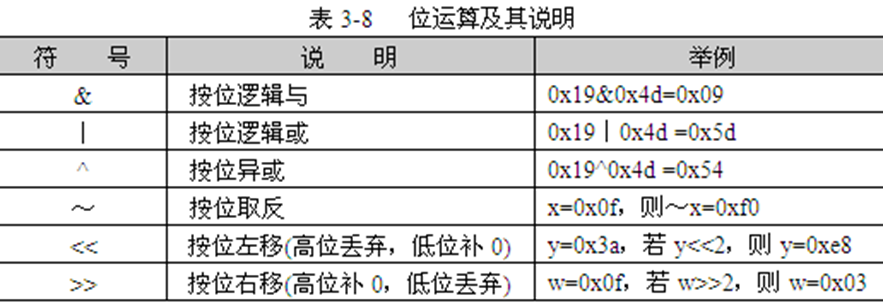
4.位运算
5.指针和取地址运算符
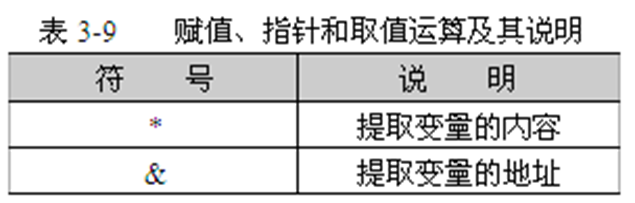
目标变量=*指针变量 //将指针变量所指的存储单元内容赋值给目标变量
指针变量=&目标变量 //将目标变量的地址赋值给指针变量
例如:
a=&b; //取b变量的地址送至变量a
c=*b; //把以指针变量b为地址的单元内容送至变量c
指针变量中只能存放地址(即指针型数据),不能将非指针类型的数据赋值给指针变量。
1.分支控制语句
(1)if语句用来判定所给定的条件是否满足,根据判定结果决定执行两种操作之一。
if语句的基本结构1如下:
if (表达式) {语句}
括号中的表达式成立时,程序执行大括号内的语句,否则程序跳过大括号中的语句部分,而直接执行下面的其他语句。例如:
if (x>y) {max=x; min=y;} //如果x>y,则x赋给max,y赋给min。如果x>y不成立,则不执行大括号中的赋值运算。
if语句的基本结构2如下:
if (表达式) {语句1;} else {语句2;}
括号中的表达式成立时,程序执行大括号内的语句1,否则程序跳过大括号中的语句1部分,而直接执行else部分大括号内的语句2。例如:
if (x>y){max=x; } //如果x>y,则max赋值为x
else {max=y;} //否则max赋值为y
if语句的基本结构3如下:
if (表达式1) {语句1;}
else if (表达式2) {语句2;}
else if (表达式3) {语句3;}
……
else {语句n;}
if 和 else if 本质上是互斥的,当if(表达式1) {语句1;}执行后直接跳过else if(表达式) {语句;},若执行else if (表达式2) {语句2;}时,表示if(表达式1)为假,语句1没有被执行。例如:
if (x>100) {y=1;} //若x>100,则y=1
else if (x>50) {y=2;} //若100>x>50,则y=2
else if (x>30) {y=3;} //若50>x>30,则y=3
else if (x>10) {y=4;} //若30>x>10,则y=4
else {y=5;} //若x<10,则y=5
(2)switch语句。if语句只有两个分支可选择,而switch语句是多分支选择语句。switch语句的一般形式如下:
switch (表达式1)
{
case 常量表达式1:{语句1;}break;
case 常量表达式2:{语句2;}break;
……
case 常量表达式n:{语句n;}break;
default:{语句n+1;}
}
switch语句说明:
- 每一case常量表达式须互不相同,否则将混乱。
- 各个case和default出现次序,不影响程序执行的结果。
- switch括号内表达式的值与某case后面的常量表达式的值相同时,就执行它后面的语句,遇到break语句则退出switch语句。
- 若所有的case中的常量表达式的值都没有与switch语句表达式的值相匹配时,就执行default后面的语句。
- 如果在case语句中遗忘了break语句,则程序执行了本行之后,不会按规定退出switch语句,而是将执行后续的case语句。
- switch语句的最后一个分支可以不加break语句,结束后直接退出switch结构。
【例】在单片机程序设计中,常用switch语句作为键盘中按键按下的判别,并根据按下键的键号跳向各自的分支处理程序。
input: keynum=keyscan( ) //keyscan( )是另行编写的一个键盘扫描函数,如有键按下,该函数就会得到按下键的键值,将键值赋予变量keynum
switch(keynum)
{
case 1: key1( ); break; //如果按下键为1键,则执行函数key1( )
case 2: key2( ); break; //如果按下键为2键,则执行函数key2( )
case 3: key3( ); break; //如果按下键为3键,则执行函数key3( )
……
case n: keyn( ); break; //如果按下键为n键,则执行函数keyn( )
default:goto input
}
2.循环控制语句
实现循环结构的语句有以下3种:while语句、do-while语句和for语句。
(1)while语句。语法形式为:
while(表达式)
{
循环体语句;
}
先判断表达式是否为真,如果表达式为真,就重复执行循环体语句;反之,则终止循环体内的语句。
(2)do-while语句。语法形式为:
do
{
循环体语句;
}
while(表达式);
先执行循环体语句,然后判断表达式是否为真,如果表达式为真,就重复执行循环体语句;反之,则终止循环体内的语句。
(3)for语句。for语句不仅可用于循环次数已知的情况,也可用于循环次数不确定而只给出循环条件情况。语法形式为:
for(表达式1;表达式2;表达式3)
{
循环体语句;
}
表达式可为空,但;不能省略,若for(;;),小括号内只有两分号,无表达式,这意味着没有设初值,无判断条件,循环变量为增值,它的作用相当于while(1),为无限循环。若for语句的3个表达式中,表达式1缺省,即不对i设初值(可在循环之前设置初值)。或表达式2缺省,即不判断循环条件。或表达式3缺省,即每次循环后变量i不变化,那么判断条件2会一直为真(或一直为假,不执行循环。表达式2变量可在循环语句中手动添加),则认为表达式始终为真,循环将无休止地进行下去,相当于while(1),为无限循环。
- 表达式1是进入第一次for循环之前运行了,并且只会执行一次
- 表示式2是for循环的执行条件,满足这个条件后才能进知入循环里面的语句
- 表达式3是在执行一次循环后执行的语句
若for循环没有循环体,则为软件延时,即循环执行指令,消磨一段已知的时间。如果使用12MHz晶振,则12个时钟周期花费的时间为1µs。
(1)break语句
循环结构中,可使用break语句跳出本层循环体,马上结束本层循环。
(2)continue语句
循环结构中,可使用continue语句跳出本层循环体,停止当前这一层循环,然后直接尝试下一层循环。
(3)goto语句
无条件转移语句,当执行goto语句时,将程序指针跳转到goto给出的下一条代码。
3.数组
(1)一维数组
类型说明符 数组名[元素个数];
可对数组进行整体初始化,即对数组中每个元素都进行赋值(可以不定义元素个数);也可定义元素个数,对其中一些元素进行赋值,未赋值的默认为0。可以在定义时进行整体初始化,也可在定义后单个地进行赋值。
例:int a[3]={2,4,6};
(2)多维数组
类型说明符 数组名[元素行数][元素列数];
可对数组进行整体初始化,即对数组中每个元素都进行赋值(可以不定义元素行数列数);也可定义元素行数列数,对其中一些元素进行赋值,未赋值的默认为0。可以在定义时进行整体初始化,也可在定义后单个地进行赋值。
例:int a[3][4]={1,2,3,4},{5,6,7,8},{9,10,11,12};
(3)字符数组
若一个数组的元素是字符型的,则该数组就是一个字符数组。
例:char a[7]= {‘B’,‘E’,‘I’,‘J’,‘I’,‘N’,‘G’};
还允许用字符串直接给字符数组置初值,数组的元素数目一定要比字符多一个,以便C51编译器自动在其后面加入结束符‘�’。
例:char a[10]= {“BEI JING”};
最后
以上就是妩媚凉面最近收集整理的关于C51语言的全部内容,更多相关C51语言内容请搜索靠谱客的其他文章。








发表评论 取消回复