前几天,华为发布了最新的AI芯片,号称目前全球最强,算力吊打谷歌TPU3和英伟达Tesla V100。
这么震撼人心,必须挺一波!!
华为牛逼!!
(这句5毛)
下面来具体分析一下。
一、昇腾910的整体结构
我去华为官网查了一下,然后就得到这么一点信息:
(之后截图补上,这是地址:https://e.huawei.com/cn/products/cloud-computing-dc/atlas/ascend-910)
看得我一脸蒙蔽。
信息太少了!
从其他新闻媒体公开的信息,总结一下:
昇腾910,采用达芬奇架构,7nm工艺,功耗350W,FP16算力为256T,INT8算力为512T。
有媒体说是32核。(没有官方石锤,不确定)
然后,没了。
这怎么猜?
呵呵,这有何难!!
来,咱们发散思维,细细研究一下,推测一下具体架构。
首先,FP16的算力是256T,这个是石锤的。这个数据后面有用。
然后,不是采用的达芬奇架构么?记得这不是华为的第一款达芬奇架构芯片。第一款达芬奇架构芯片是之前的昇腾310。还记得么?(这是我之前分析昇腾310的博客:https://blog.csdn.net/evolone/article/details/90317637)
那不妨回忆一下昇腾310的参数。
下面是我之前的分析:
从海报中能够看出,AI core 采用的是二维平面阵列结构,应该是类似谷歌TPU的脉动阵列结构。
从海报中可知,单个AI Core每周期可完成4096次MAC运算,那么4096=64X64,所以猜测MAC阵列的尺寸是64X64的。
支持8T半精度浮点计算和16T整型int8计算。
从公布的算力来看:
8T= 4K(4096 MAC) X 2(双核) X 1G(频率1GHz)
整体架构类似谷歌的TPU2,都是双核的。
当然,如果华为认为一次MAC运算包含的一个乘法,一个加法,如果各算一次,就是两次。
那么,算力的计算就是下面这种了:
8T= 2(一次MAC=一次乘法+一个加法) X 4K(4096 MAC) X 1(单核) X 1G(频率1GHz)
这么一结合,就能推算出昇腾910的架构了。
可能的算力计算方法如下:
以256T的FP16为例。
256T = 32(大核,每个8T算力)X 2(一次MAC=一次乘法+一个加法)X 4K(4096 MAC) X 1(单核,小核) X 1G(频率1GHz)
或者
256T = 32(大核,每个8T算力)X 4K(4096 MAC) X 2(双核,小核) X 1G(频率1GHz)
这么一看,推算方法还是有几分像模像样的,哈哈。
昇腾910与310的关系,有点像寒武纪DianNao与DaDianNao的关系。
单核与多核的区别。
二、达芬奇架构的AI Core内部结构分析
从机器之心的一篇文章中看到的关于达芬奇架构的结构图。
不知真假,姑且用来分析学习一下。
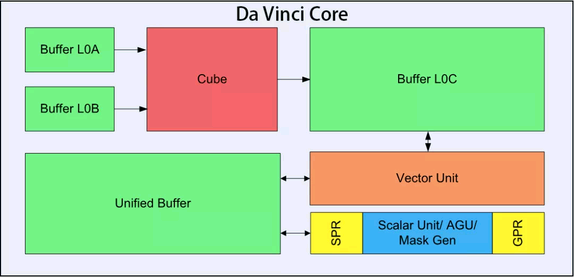
(这是地址:https://www.jiqizhixin.com/articles/2019-08-23-7)
由上图可知,整个达芬奇Core和谷歌的TPU比较像。
整体来看,两个bufferL0A和L0B作为输入,应该是其中一个暂存的是activition,另一个暂存的是权重。
红色的Cube模块,应该是类似谷歌TPU脉动阵列的结构,猜测是一个乘累加阵列,计算结果输出存放在另外一个buffer L0C。
Vector Unit,类似一个DSP,从buffer L0C中取得乘累加计算结果,然后进行pooling/padding,BN,激活,加法等处理。如果还没得到最终结果,就暂时返回存储在buffer L0C,如果得到了最终结果,就传递给Unified Buffer。
Scalar Unit应该是用来控制调度的,类似一个MCU,可以是ARM的,也可以是RISC-V的。
华为的达芬奇 AI core与谷歌TPU非常像。
但是,达芬奇做出了更多的优化设计。
最大的优化设计是引入了Vector Unit,这个可以看作功能强大的DSP。
以Vector Unit替换原来的BN/ADD/激活/POOLING/PADDING等模块,在不显著增加运算逻辑的前提下,尽可能增加芯片的灵活性。
原因:
(纯粹是我的个人分析,做不得准,我不负责任的啊。)
因为现在的深度学习算法还不成熟稳定,一直都有新颖的计算方法层出不穷,这就导致计算的需求一直在变。
但是,芯片逻辑是实际的物理电路,一旦设计好,那么就固定了,谁都变不了。而且芯片的研发设计需要少则几月多则几年的时间,所以,按照当下最新的算法需求设计的芯片,可能真正上市时,算法又变了。
那么芯片可能就废了。
或者,效率不高。
细细分析一下,常用的卷积,需要大量的乘累加,这个需求一直不变。所以,这一部分可以保留。
但是之后的BN/激活等模块,就灵活多变了,比如激活模块,可能出现了新的激活函数,那么原来的设计就不满足需求了。
所以,除开卷积等比较稳定的计算类型外,其他的计算就需要灵活处理了。
那么,这个时候,需要灵活处理的模块,使用固定逻辑就不满足客观现实了,改用通用性更高且可灵活编程配置的DSP就是自然而然的选择。
当然,因为根据实际算法需求而进行灵活的编程控制,DSP自身并不具备这样的功能,那么就需要一个类似MCU的模块了。也就自然引入了Scalar模块。
所以,目前来看,华为的达芬奇架构的Core,已经做了很多优秀的优化设计,属于世界领先水平了。
看到这里,内心澎湃,忍不住多说一句:
华为真牛逼!!
最后
以上就是傲娇小蘑菇最近收集整理的关于AI芯片:华为Ascend(昇腾)910结构分析的全部内容,更多相关AI芯片内容请搜索靠谱客的其他文章。








发表评论 取消回复