本文代码请见:https://github.com/Ryuk17/SpeechAlgorithms
博客地址(转载请指明出处):https://www.cnblogs.com/LXP-Never/p/14142108.html
如果你觉得写得还不错,点赞????,关注是对我最大的支持,谢谢????
传统的语音增强方法基于一些设定好的先验假设,但是这些先验假设存在一定的不合理之处。此外传统语音增强依赖于参数的设定,人工经验等。随着深度学习的发展,越来越多的人开始注意使用深度学习来解决语音增强问题。由于单通道使用场景较多,本文就以单通道语音增强为例。
目前基于DNN单通道大致可以分为两种方法,
- 第一种寻求噪声语音谱与纯净语音谱的映射
- 第二种基于mask的方法
基于映射的语音增强
基于映射的语音增强方法通过训练神经网络模型将噪声谱与纯净谱之间的映射关系,其流程如下图所示,很多博客和文章也有讲这个方法但是我觉得不详细,让初学者一脸懵逼,下面详细介绍。
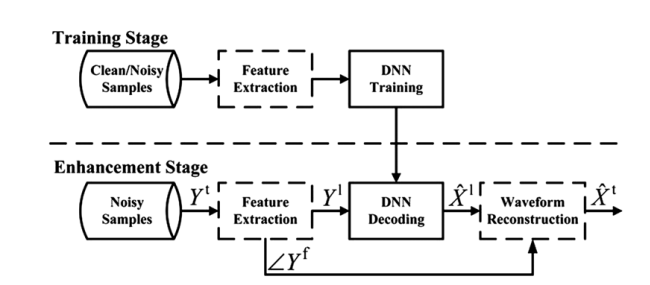
训练阶段
输入:这里采用较为简单地特征,即带噪声语音信号的幅度谱,也可以采用其他的特征。值得一提的是,如果你的输入是一帧,对应输出也是一帧的话效果一般不会很好。因此一般采用扩帧的技术,如下图所示,即每次输入除了当前帧外还需要输入当前帧的前几帧和后几帧。这是因为语音具有短时相关性,对输入几帧是为了更好的学习这种相关性
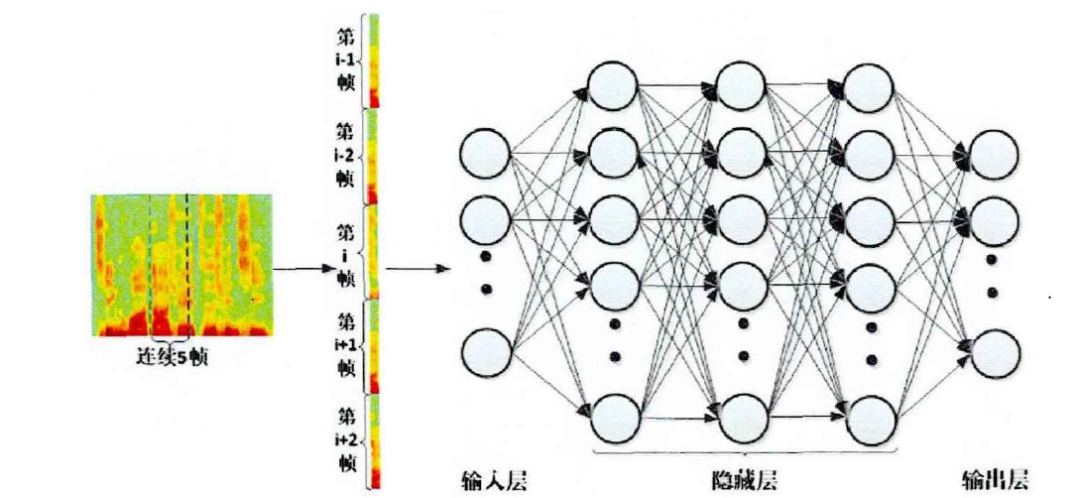
- Label:数据的label为纯净语音信号的幅度谱,这里只需要一帧就够了。
- 损失函数:学习噪声幅度谱与纯净语音信号的幅度谱类似于一个回归问题,因此损失函数采用回归常用的损失函数,如均方误差(MSE)、均方根误差(RMSE)或平均绝对值误差(MAE)等....
- 最后一层的激活函数:由于是回归问题,最后一层采用线性激活函数
- 其他:输入的幅度谱进行归一化可以加速学习过程和更好的收敛。如果不采用幅度谱可以采用功率谱,要注意的是功率谱如果采用的单位是dB,需要对数据进行预处理,因为log的定义域不能为0,简单的方法就是在取对数前给等于0的功率谱加上一个非常小的数
增强阶段
- 输入:输入为噪声信号的幅度谱,这里同样需要扩帧。对输入数据进行处理可以在语音信号加上值为0的语音帧,或者舍弃首尾的几帧。如果训练过程对输入进行了归一化,那么这里同样需要进行归一化
- 输出:输入为估计的纯净语音幅度谱
- 重构波形:在计算输入信号幅度谱的时候需要保存每一帧的相位信息,然后用保存好的相位信息和模型输出的幅度谱重构语音波形,代码如下所示。
spectrum = magnitude * np.exp(1.0j * phase)
基于Mask的语音增强
Mask这个单词有的地方翻译成掩蔽有的地方翻译成掩膜,我个人倾向于翻译成“掩蔽”,本文就用掩蔽作为Mask的翻译。
时频掩蔽
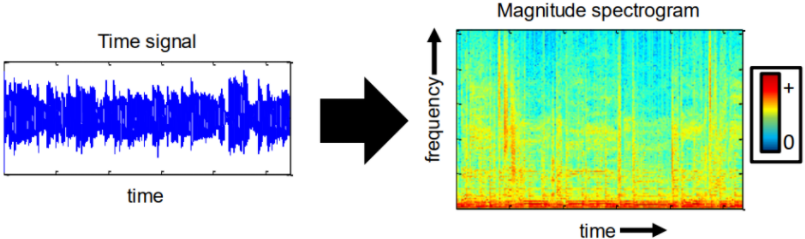
我们都知道语音信号可以通过时域波形或者频域的各种频谱表示,此外语谱图可以同时展示时域和频域的信息,因此被广泛应用,如下图所示。
现在我们假设有两段语音信号,一段是音乐信号,另一段是噪声,他们混合在一起了,时域波形和对应的语谱图分别如下图所示:

如果我们想将音乐信号从混合信号中抽离(这个过程叫做语音分离)在时域方面是容易做到的。现在我们从频域角度入手去解决语音分离问题。首先我们提出两个假设:
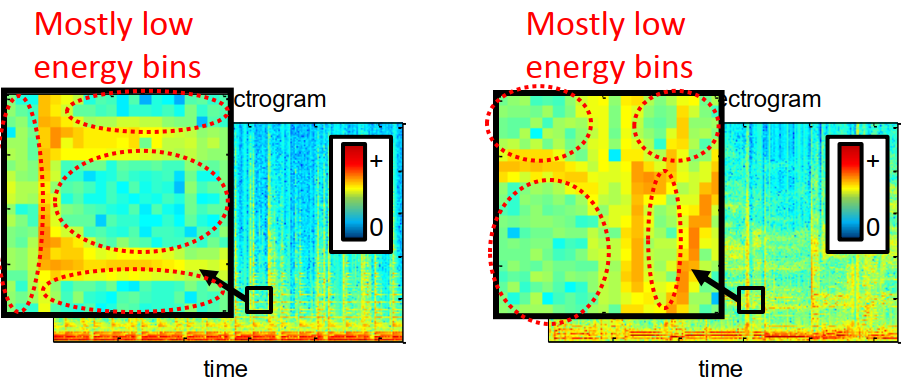
1、我们假设信号能量稀疏的,即对于大多数时频区域它的能量为0,如下图所示,我们可以看到大多数区域的值,即频域能量为0。
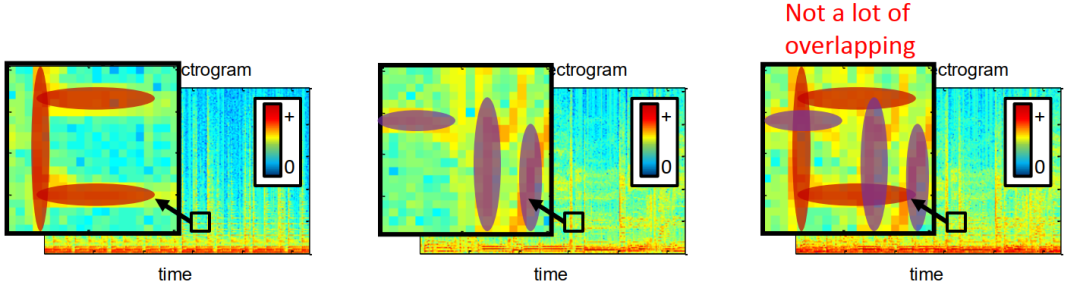
2、我们假设信号能量不相交的,即它们的时频区域不重叠或者重叠较少,如下图所示,我们可以看到时频区域不为0的地方不重叠或者有较少部分的重叠。
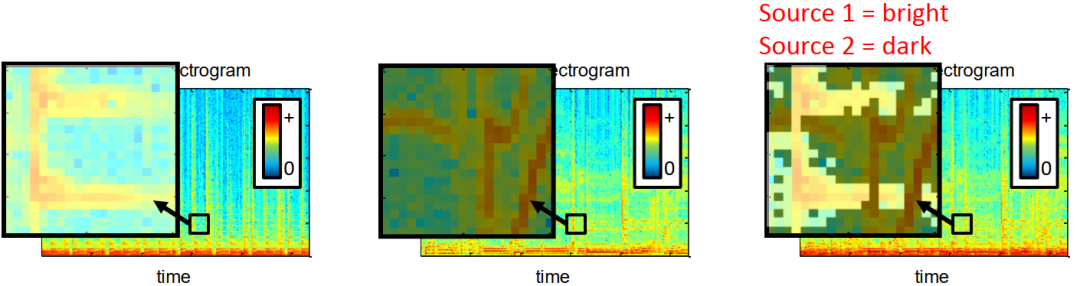
基于以上两点假设,我们就可以分离我们想要的信号和噪声信号。给可能属于一个信号源的区域分配掩码为1,其余的分配掩码0,如下图所示。
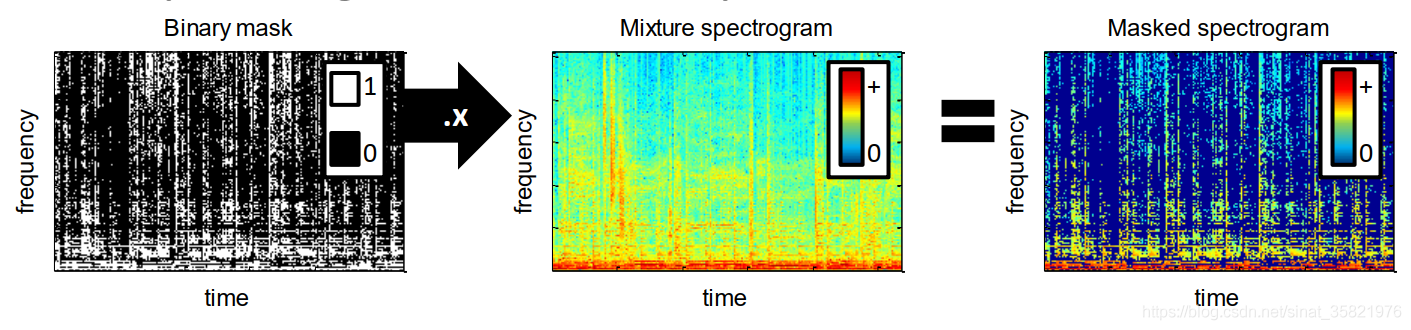
我们通过0和1的二值掩码然后乘以混合信号的语谱图就可以得到我们想要喜好的语谱图了,如下图所示。
但是,这里存在一个问题,我们无法从语谱图中还原语音信号。为了解决这一问题,我们首先还原所有的频率分量,即对二值掩码做个镜像后拼接。假设我们计算语谱图时使用的是512点SFTF,我们一般去前257点进行分析和处理,在这里我们将前257点的后255做镜像,然后拼接在一起得到512点频率分量,如下图所示。
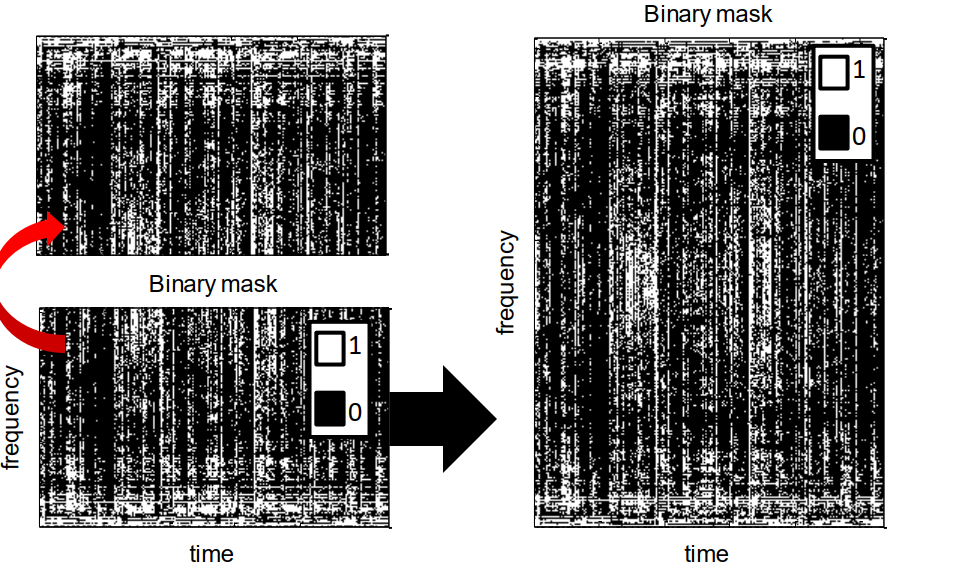
然后根据这个还原语音信号。这里指的一提的是,在进行STFT后的相位信息要保存,用于还原语音信号。
接下来介绍如何计算掩蔽值,掩蔽值计算方法有许多,但一般来说有两种常用的计算方法,分别为理想二值掩蔽(Ideal Binary Mask, IBM)和理想比值掩蔽(Ideal Ratio Mask, IRM)。IBM的计算公式如下:
$$公式1:I B M(t, f)=left{begin{array}{l}
1, operatorname{SNR}(t, f)>L C \
0, text { else }
end{array}right.$$
其中LC为阈值,一般取0,SNR计算公式为:
$$公式2:operatorname{SNR}(t, f)=10 * log 10left(frac{|S(t, f)|^{2}}{|N(t, f)|^{2}}right)$$
IRM为一个[0-1]的值,计算公式为:
$$公式3:operatorname{IRM}(t, f)=left(frac{S^{2}(t, f)}{S^{2}(t, f)+N^{2}(t, f)}right)^{beta}=left(frac{operatorname{SNR}(t, f)}{operatorname{SNR}(t, f)+1}right)^{beta}$$
其中$beta$为可调节尺度因子,一般取0.5。
基于mask方法的语音增强一般基于这种假设,在带噪语音谱中即存噪声信号又存在语音信号,因此将噪声信号掩蔽掉剩下的就是语音信号。目前常用的两种掩蔽方法:理想二值掩蔽、理想比值掩蔽
- 理想二值掩蔽(Ideal Binary Mask,IBM),将分离任务变成了一个二分类问题。这类方法根据听觉感知特性,把音频信号分成不同的子带,根据每个时频单元上的信噪比,在噪声占主导情况下,把对应的时频单元的能量设为0,在目标语音占主导的情况下,保持原样。
- 理想比值掩蔽(Ideal Ratio Mask,IRM),它同样对每个时频单元进行计算,但不同于IBM的“非零即一”,IRM中会计算语音信号和噪音之间的能量比,得到介于0到1之间的一个数,然后据此改变时频单元的能量大小。IRM是对IBM的演进,反映了各个时频单元上对噪声的抑制程度,可以进一步提高分离后语音的质量和可懂度。
基于掩蔽的语音增强和基于映射的语音增强模型训练和增强过程类似,这里只提几个重要的地方,其余地方参考上面内容。
- Label:数据的label为根据信噪比计算的IBM或者IRM,这里只需要一帧就够了
- 损失函数:IBM的损失函数可以用交叉熵,IRM的损失函数还是用均方差
- 最后一层的激活函数:IBM只有0和1两个值,IRM范围为[0,1],因此采用sigmoid激活函数就可以了
- 重构波形:首先用噪声幅度谱与计算的Mask值对应位置相乘,代码如下,然后根据相位信息重构语音波形。
enhance_magnitude = np.multiply(magnitude, mask)
Demo效果以及代码
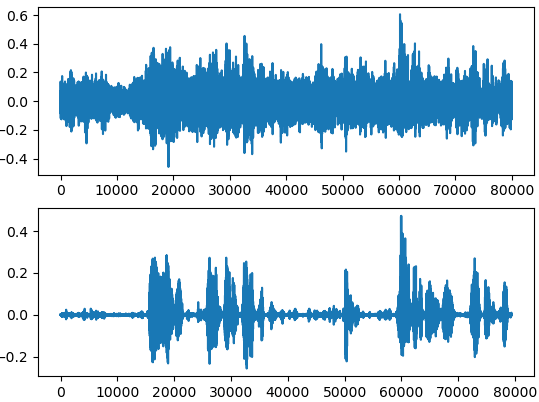
首先看下实验效果,首先是基于映射语音增强的结果:
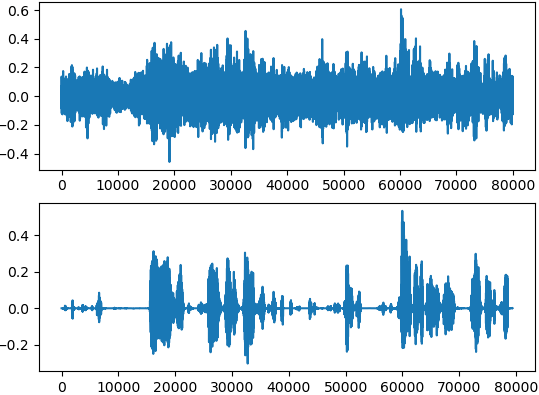
基于IBM语音增强的结果:
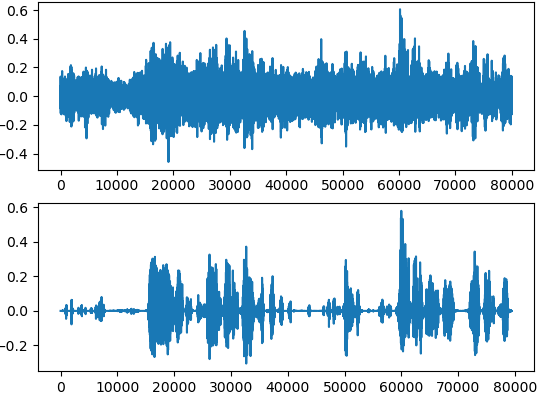
基于IRM语音增强的结果:
训练代码:
"""
@FileName: IBM.py
@Description: Implement IBM
@Author: Ryuk
@CreateDate: 2020/05/08
@LastEditTime: 2020/05/08
@LastEditors: Please set LastEditors
@Version: v0.1
"""
import numpy as np
import librosa
from sklearn.preprocessing import StandardScaler
from keras.layers import *
from keras.models import Sequential
def generateDataset():
mix, sr = librosa.load("./mix.wav", sr=8000)
clean,sr = librosa.load("./clean.wav", sr=8000)
win_length = 256
hop_length = 128
nfft = 512
mix_spectrum = librosa.stft(mix, win_length=win_length, hop_length=hop_length, n_fft=nfft)
clean_spectrum = librosa.stft(clean, win_length=win_length, hop_length=hop_length, n_fft=nfft)
mix_mag = np.abs(mix_spectrum).T
clean_mag = np.abs(clean_spectrum).T
frame_num = mix_mag.shape[0] - 4
feature = np.zeros([frame_num, 257*5])
k = 0
for i in range(frame_num - 4):
frame = mix_mag[k:k+5]
feature[i] = np.reshape(frame, 257*5)
k += 1
snr = np.divide(clean_mag, mix_mag)
mask = np.around(snr, 0)
mask[np.isnan(mask)] = 1
mask[mask > 1] = 1
label = mask[2:-2]
ss = StandardScaler()
feature = ss.fit_transform(feature)
return feature, label
def getModel():
model = Sequential()
model.add(Dense(2048, input_dim=1285))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.1))
model.add(Dropout(0.1))
model.add(Dense(2048))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.1))
model.add(Dropout(0.1))
model.add(Dense(2048))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.1))
model.add(Dropout(0.1))
model.add(Dense(257))
model.add(BatchNormalization())
model.add(Activation('sigmoid'))
return model
def train(feature, label, model):
model.compile(optimizer='adam',
loss='mse',
metrics=['mse'])
model.fit(feature, label, batch_size=128, epochs=20, validation_split=0.1)
model.save("./model.h5")
def main():
feature, label = generateDataset()
model = getModel()
train(feature, label, model)
if __name__ == "__main__":
main()
增强代码:
"""
@FileName: Inference.py
@Description: Implement Inference
@Author: Ryuk
@CreateDate: 2020/05/08
@LastEditTime: 2020/05/08
@LastEditors: Please set LastEditors
@Version: v0.1
"""
import librosa
import numpy as np
from basic_functions import *
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from keras.models import load_model
def show(data, s):
plt.figure(1)
ax1 = plt.subplot(2, 1, 1)
ax2 = plt.subplot(2, 1, 2)
plt.sca(ax1)
plt.plot(data)
plt.sca(ax2)
plt.plot(s)
plt.show()
model = load_model("./model.h5")
data, fs = librosa.load("./test.wav", sr=8000)
win_length = 256
hop_length = 128
nfft = 512
spectrum = librosa.stft(data, win_length=win_length, hop_length=hop_length, n_fft=nfft)
magnitude = np.abs(spectrum).T
phase = np.angle(spectrum).T
frame_num = magnitude.shape[0] - 4
feature = np.zeros([frame_num, 257 * 5])
k = 0
for i in range(frame_num - 4):
frame = magnitude[k:k + 5]
feature[i] = np.reshape(frame, 257 * 5)
k += 1
ss = StandardScaler()
feature = ss.fit_transform(feature)
mask = model.predict(feature)
mask[mask > 0.5] = 1
mask[mask <= 0.5] = 0
fig = plt.figure()
plt.imshow(mask, cmap='Greys', interpolation='none')
plt.show()
plt.close(fig)
magnitude = magnitude[2:-2]
en_magnitude = np.multiply(magnitude, mask)
phase = phase[2:-2]
en_spectrum = en_magnitude.T * np.exp(1.0j * phase.T)
frame = librosa.istft(en_spectrum, win_length=win_length, hop_length=hop_length)
show(data, frame)
librosa.output.write_wav("./output.wav",frame, sr=8000)
参考文献
DNN单通道语音增强(附Demo代码)(大量抄袭于它)
基于Mask的语音分离
补充一下:https://blog.csdn.net/shichaog/article/details/105890125
最后
以上就是爱听歌大地最近收集整理的关于基于深度学习的单通道语音增强基于映射的语音增强基于Mask的语音增强Demo效果以及代码参考文献的全部内容,更多相关基于深度学习内容请搜索靠谱客的其他文章。








发表评论 取消回复