这篇文章是ACL2020上的文章,来德国研究中心的Christoph Alt。
文章主要研究的是Tacred的数据集合中的Dev和Test集的标注错误,并且做了标注错误类型的分组,做了对比试验验证这些不同的错误原因对四个对比模型的影响,得出了 per:loc 和 same nertag&positive两个group的样例容易被分类错误的结论,并且认为将instance难度考虑到评估过程是有必要的。
这篇文章看到当前在Tacred上的SOTA模型仍然还有30%错误率,于是提出了问题,当前的Tacred的上的分类模型是否已经到达的了天花板;以及什么对于数据集和模型来讲是重要的。
作者从该任务最基本的组成部分——数据集本身出发,探究数据集中是否存在一些错误,导致模型无法正确分类。
那么由于Tacred数据集本身数据量还是比较大,因此需要筛选出一批最有可能出问题的样本。筛选方法是用49个模型对数据集分别在dev和test上测试,从dev和test集合中选出了最难分类的5000个样本。然后分成了Challenging(被一半模型分错)和Control(每个类别最多20个样本,至少被39个模型分类正确)两个集合。
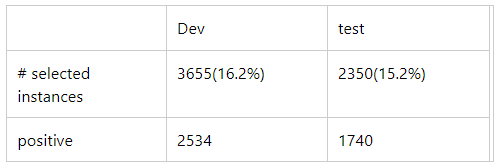
然后通过人工校验这5000个数据点,这些校验人员都是经过明确的guidance和训练,校验标记后的结果如表2。
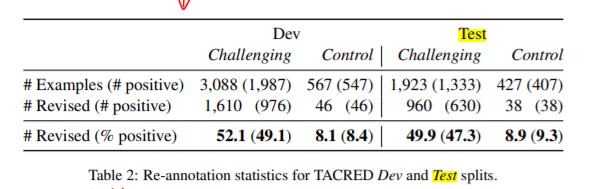
从这个表中可以看出对于Dev和Test中Challenging部分的数据,原数据集中错误标记占比还是比较高的,达到了50%;而在Control集合中,错误标记比较少,不到10%。【模型会因为50%的dev错误标注被带偏】。
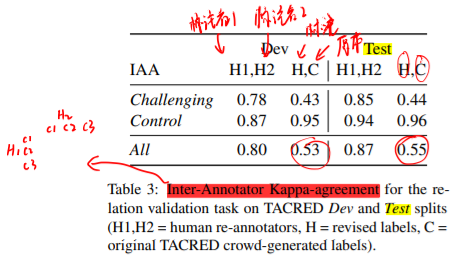
从这个不同标记来源的一致性检验【附加的PDF中有例子】中可以看到,经过本文指导的标注者H1和H2的标注一致性比较高。而本文的标注结果H和原数据集C中的标注结果一致性仅有0.54左右。
作者在修改后的test集合上进行49个模型的验证,F1值从62.1%涨到了70.1%。作者认为这是Tacred上影响模型准确率的主要因素。本文还对比了Riedel et al. (2010) 远程监督数据集的错误率大概在31%,低于本文的监督数据集Tacred。但是,作者并不反对训练集中出现的错误,本文作者认为测试集应该是准确的。
接下来作者开始研究来自模型的误差是怎么来的,也就是什么样子,具有什么能力的模型更有效果。
第一步:
之前获得到的revisited 数据集继续使用,用两个标注人员为每个错误标记的样本指定“错误类型”。作者通过不同的错误类型,来验证模型具有哪些处理错误的能力,不具有哪些能力。从而得出模型的误差来源。
通过人工标记,共得出了9种错误类型:

这1017个re-annotated样本是49个模型中预测错误的最多的。错误大致分两个类别Argument error和context error。
第二步:
进行自动误差分析,首先定义了四组误差来源:
1.
Surface structure – Groups for argument distance (argdist=1, argdist>10) and sentence length (sentlen>30) •
2.
Arguments – Head and tail mention NER type (same nertag, per:, org:, per:loc), and pronominal head/tail (has coref) •
3.
Context – Existence of distracting entities (has distractor) •
4.
Ground Truth – Groups conditioned on the ground truth (positive, negative, same nertag&positive)
一共是13种具体情形。
第三步:
选取模型进行实验,CNN+masked,TRE,SpanBERT,KnowBERT四个模型。
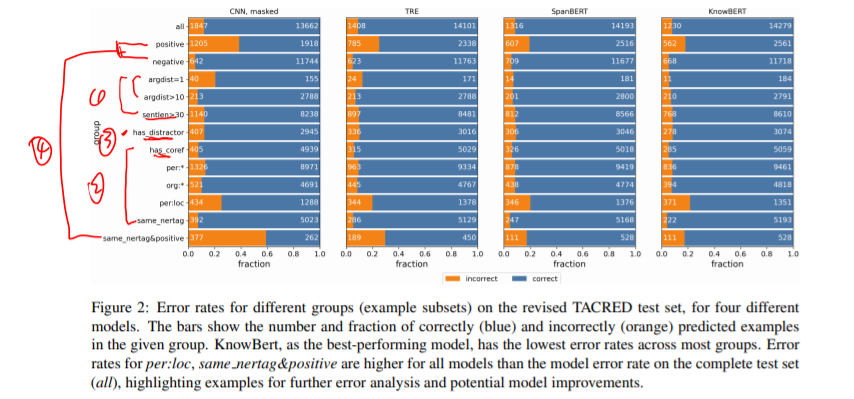
图上的1234对应四组误差。以其中一个模型为例说明,CNN_masked,对于positive这个误差类别和sam_nertag&positive容易分错。而1 2 3组的样本容易分正确。而这两个容易分错的样本对模型的影响都比较大,即容易被模型误分类。
作者单独做了实验验证context对模型的影响。
对于一个句子,remove outside意思是移除两个实体外面的词;remove inside意思是移除两个实体中间的词。
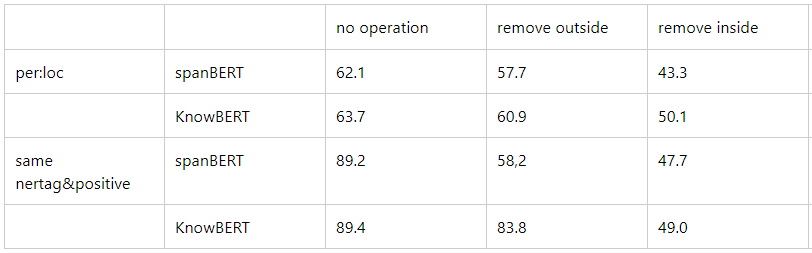
表明,在same nertag&positive上,SpanBERT更关注entity masking和context,因此它deF1值会降低比较多;Knowbert更关注实体本身的语义,因此下降不懂【将Knowbert和spanbert融合】
作者单独做实验验证了如果对实例难度进行加权后再验证,该权重来自49个模型,如果都被预测正确,权重为0,如果都被预测错误权重为1.使得模型更关注难分类的样本。
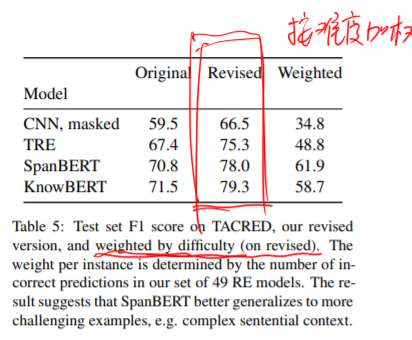
从表中可以看出,数据集合还是有很多容易分类的样本。
自己思考:
- 首先他的revisited的数据集没有给出。
- 其次这个最后加权仅仅是在评估的时候加上权重,总而更能校验模型对复杂样本的分类能力,但是没给出他们的re-annotated验证数据集,说屁呢?
- 尝试进行Spanbert和Knowbert优势融合。
最后
以上就是孝顺帅哥最近收集整理的关于【论文精读】TACRED Revisited: A Thorough Evaluation of the TACRED Relation Extraction Task的全部内容,更多相关【论文精读】TACRED内容请搜索靠谱客的其他文章。

Abstract(摘要)1.Introduction参考文献](https://www.shuijiaxian.com/files_image/reation/bcimg24.png)






发表评论 取消回复