一、设计思想
1.1、设计做简化
技术简化能减就减、模块解耦,不涉及业务的校验、算法等抽象独立出去,网关不关心不处理任何业务消息。
1.2、功能做简化
网关不对业务做任何干预,只做自己应该做的 核心功能、控制功能、统计功能。
核心功能:通道认证、心跳维活、消息传递、机器灰度、流量整形、通道超时剔除
控制功能:灰度机器设置、节点权重调整
二、使用技术
工程构建主要基于 netty 4.1.68.final 、redis、spring cloud 2.5.4、sentinel技术构建。
2.1、Netty相关技术
2.1.1、版本选择
netty 4.1.68.final版本是当前在维护比较新的netty版本,目前各类中间件已经使用其构建项目,作为此版本的可靠性背书。
2.1.2、boss、worker线程池自适应
使用netty提供的默认线程池管理类DefaultThreadFactory实现对boss、worker线程池管理。好处线程池中线程数由netty自己管理比我们自己决定更科学、线程名称、线程组统一管理在排异常更友好。
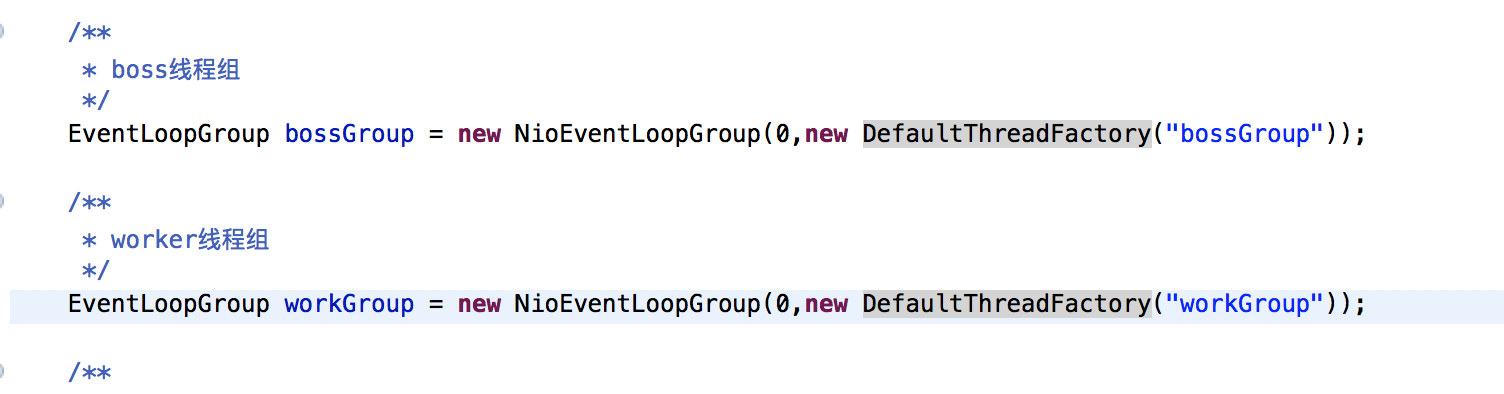
2.1.3、握手认证、心跳、业务消息解耦
自贩机心跳、握手、业务消息走一个入口,代码没有做到各司其职相互不干扰。本次构建在nett框架级别抽象出心跳、握手认证、业务消息三个模块。平时业务只关心业务通道的代码,其他对业务透明。构建利用netty handler注册机制顺序为 握手认证、心跳、业务消息的顺序。
心跳代码对比:
心跳与业务代码接收堵通道独立出来,利用netty注册链使用ctx.fireChannelRead做消息传递,使心跳与业务消息通道解耦。
| 自贩机代码-心跳 | 新网关代码-心跳 |
|
|
|
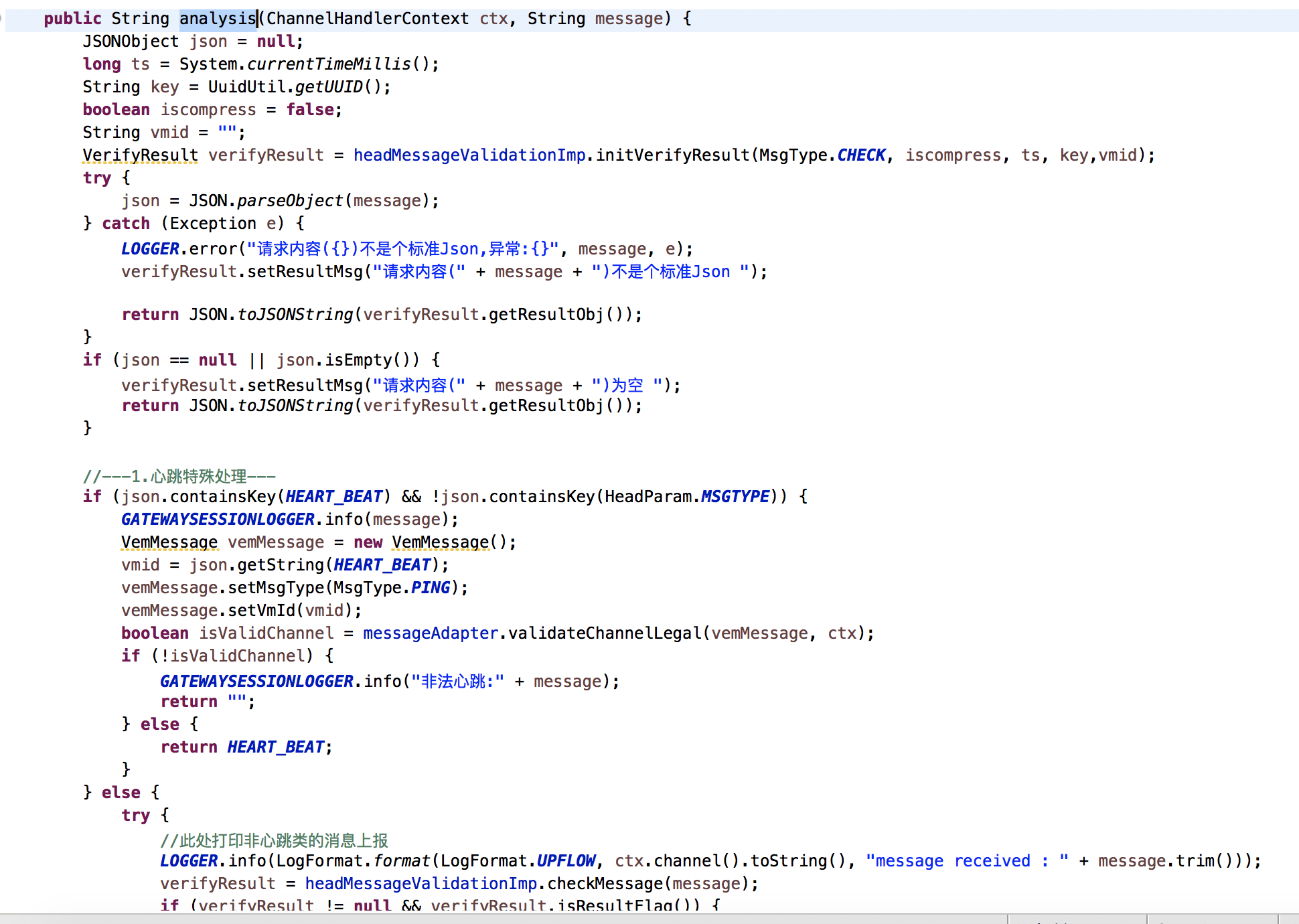

握手代码对比:
自贩机握手校验是每次发送一个消息都校验消息是否合法,验证的方法是读redis的认证缓存token,但是netty有更优雅的方式解决。netty在第一次通讯的时候会拦截该消息,如果验证通过netty会删除验证消息的handler具体代码:ctx.pipeline().remove(this),后续这个通道的消息不需要再次验证。
| 自贩机-握手 | 新网关-握手 |
|
|
|
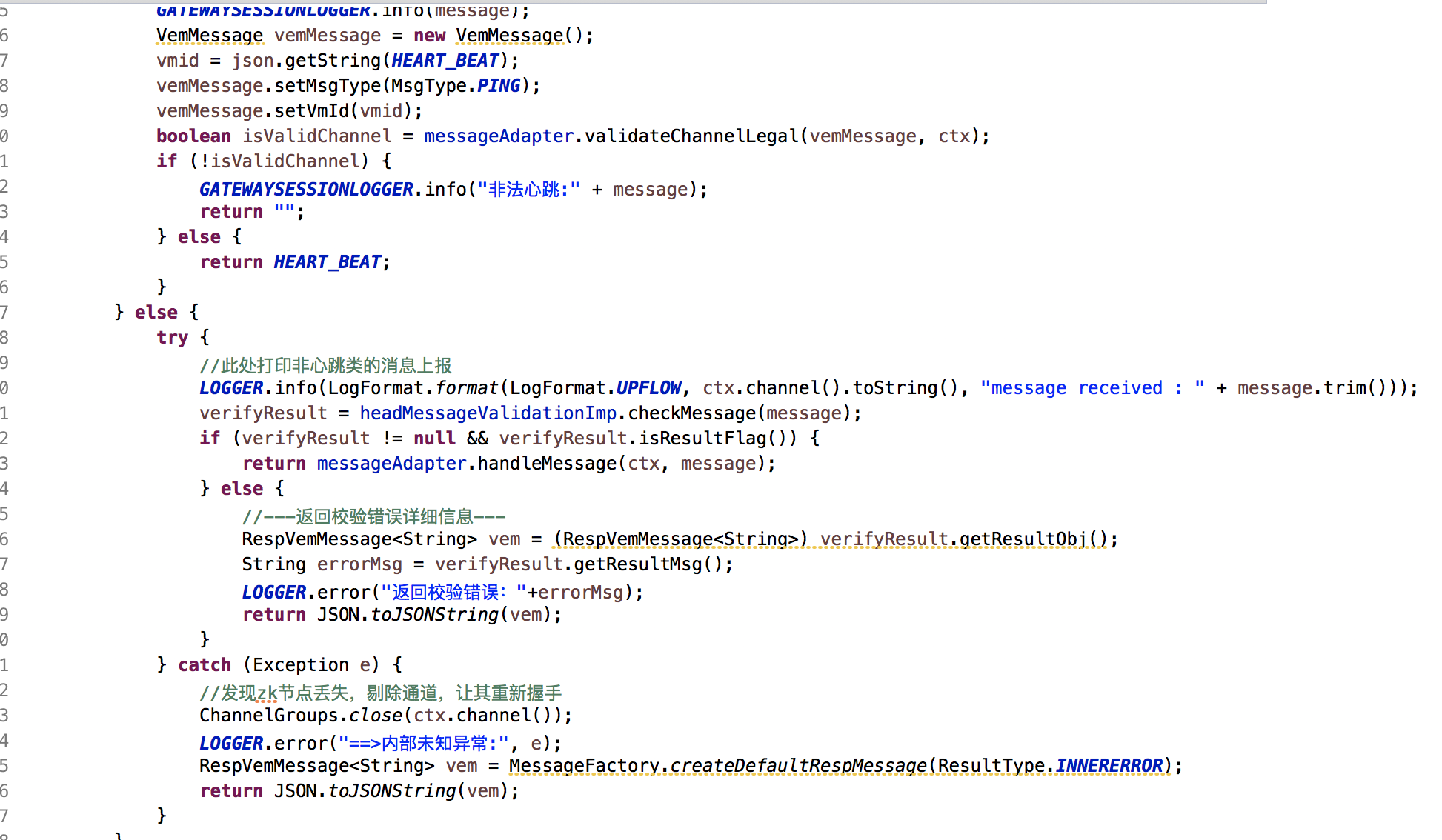
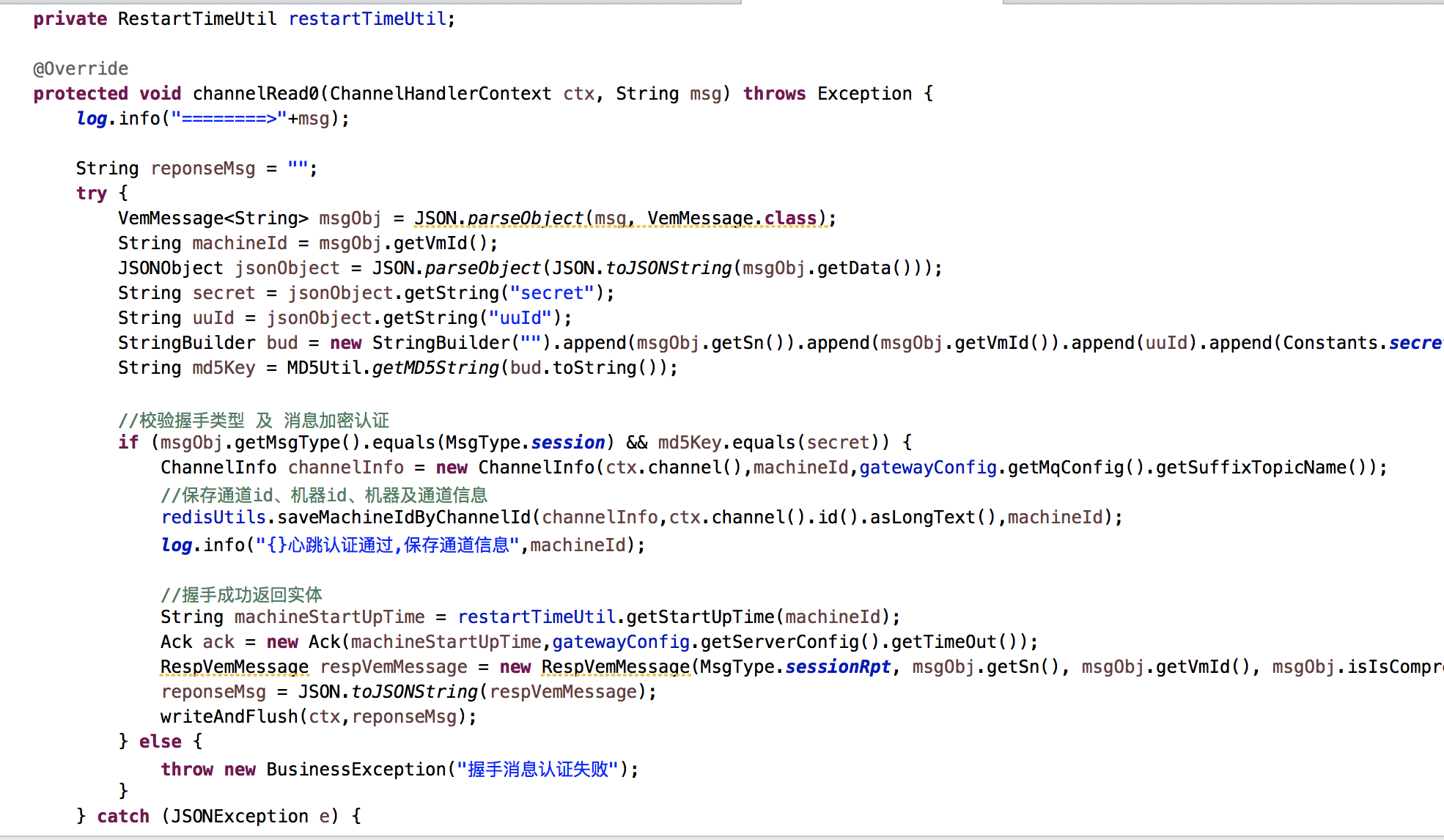
业务处理代码对比:
自贩机代码握手、心跳、业务消息都糅合在一起,新的框架都一个上行消息发送操作。
| 自贩机-业务处理 | 新网关-业务处理 |
|
|
|


2.1.4、字符串帧长度及分割符号
为什么分隔符:tcp协议其实就是一个流,自然存在半包和粘包问题。netty基于tcp自然也存在这个问题,netty通过流分隔符解决半包和粘包问题。
为什么字符串帧需要控制长度:合理的串长度是netty自我保护的手段,防止消息过大导致OOM。

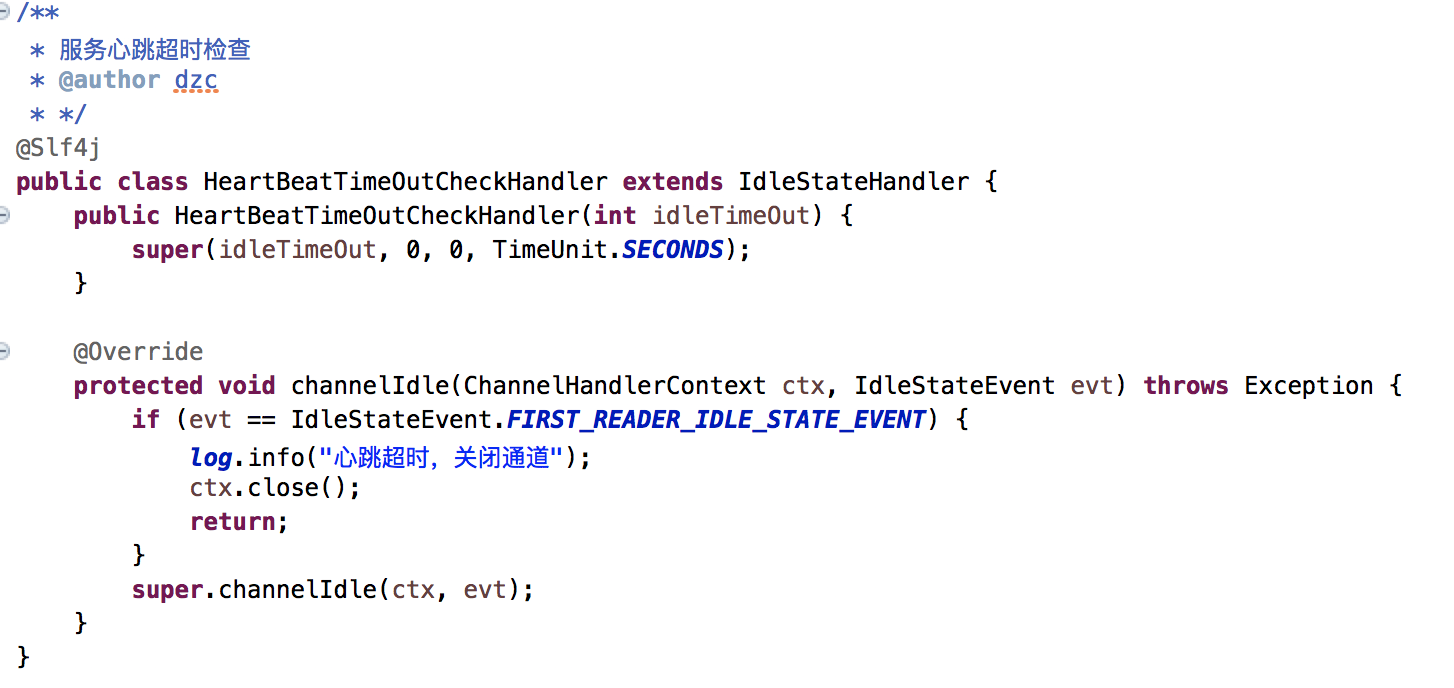
2.1.5、通道超时及超时拦截拦截剔除
netty通道通过心跳维持其活跃,如果超过其设置的最大读写超时时间即触发通道超时。如果通道超时可以被netty捕获到,然后触发通道被剔除。
2.1.6、流量整形
本次工程按照处理几十万机器链接的要求构建的,需要对流量做控制。netty提供通道级别流量整形、及全局流量整形的流量控制支持,我司选择全局的流量负载。问过我司运维单机最大流量负载是读写各100M。故netty全局流量负载读写设置为100M。自贩机目前单机读写流量负载为11M左右,也就是说单机要20倍自贩机规模才能触发此设置。

2.1.7、在线机器总数统计的精确性
在线总数统计:统计在线机器数量,目前是通过运维对Linux 4201端口的长链接数统计的。
单个机器在线情况判定:目前自贩机是通过数据库状态判断机器是否在线的。由于接口延时等原因无法精确判断出工控的在线情况。新工程设计的是机器在线情况判断通过绑定的nett 通道key去网关查询通道,如果通道存在且活跃表明工控是在线的。
机器超时在线误差与容错:本判断方案的误差取决2个点。1、netty 通道idleTimeOut设置大小,当前程序设置通道超时是200秒 2、Linux操作系统的2MSL(2*Linux 处理TCP通道残留数据处理等待时间),目前我司参数是1秒。那么在线统计精确统计时间误差就是:200+1=201秒。
#TCP 连接断开相关设置
命令:cat /etc/sysctl.conf
net.ipv4.tcp_max_tw_buckets = 10000
#表示系统同时保持TIME_WAIT套接字的最大数量
net.ipv4.tcp_timestamps = 0
#关闭TCP时间戳
#以一种比重发超时更精确的方法(请参阅 RFC 1323)来启用对 RTT 的计算;为了实现更好的性能应该启用这个选项
net.ipv4.tcp_tw_recycle = 1
#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_tw_reuse = 1
#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_retries2 = 1
#活动TCP连接重传次数,超过次数视为掉线,放弃连接。缺省值:15,建议设为 2或者3.
net.ipv4.tcp_fin_timeout = 1
#FIN_WAIT状态的TCP连接的超时时间2.1.8、channel通道标记
netty 通道识别是通过ChannelId识别的。Channeld支持两类asShortText(可能重复)、asLongText(全局唯一)两类。我们设备就是映射为唯一的一个ChannelId。但是ChannelId不好管理没有对应的业务标记,所以我们要利用Channel的AttributeKey属性绑定业务工控机vemId。这个api比较特殊文档描述不是很清楚一般刚入门netty的人不会发现这个特性。

2.1.9、序列化问题解决
在使用redis保存ChannelId时候发现保存redis前和保存redis后的值不一致,一步步调试发现redis选择序列化的规则不支持对ChannelId的序列化。发现只有JdkSerializationRedisSerializer支持netty ChannelId序列化。但是缓冲不能被其他项目引用,不能序列化,建议ChannelId存储使用本项目hashmap。
#目前redis支持下面4类序列化方式
GenericToStringSerializer
Jackson2JsonRedisSerializer
JdkSerializationRedisSerializer
OxmSerializer
StringRedisSerialize2.1.10、代码结构与功能
netty各类模块在ChannelPipeline中注册结构图。

2.2、网关灰度发布
2.2.1、灰度网关设计方式
2.2.1.1、灰度网关打标
为后续工控上线是否选择灰度网关做辨识标记
2.2.1.2、节点权重打标
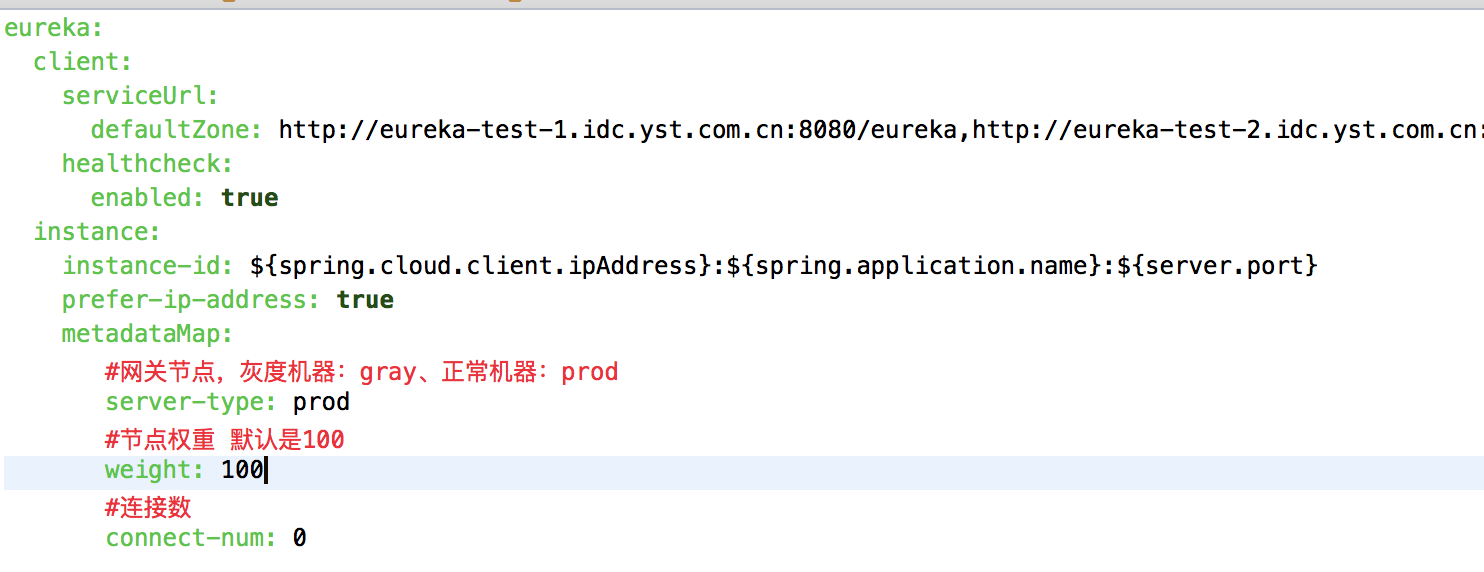
为后续机器上线流量按照权重分配做标记,比如一权重为80的节点,比权重为60的节点,要多出20%流量。
2.2.1.3、长连接数写入元数据
长连接数写入元数据,方便后续做最小连接数上线算法,也可以获取机器在线的工控数量,让我们知道每台机器的负载情况。元数据写入要60秒才能生效(元数据写入本地缓存60秒刷新一次),故读写元数据用redis兜底,做到立刻生效。
2.2.2、机器是如何获取灰度网关
1、基于spring cloud 元数据实现灰度版本控制,对网关进行灰度打标。
2、基于spring cloud服务发现发现当前可用的网关节点。
3、如果是灰度工控机器访问网关,返回的是灰度的机器。
4、如果正常网关访问返回正常机器。最后正常机器兜底。

2.3、网关负载与削峰
网关负载:在自贩机经常发现机器节点上工控机数量不平均。特别是停机发布第一台启动的机器数要比最后一台启动的机器数多好几倍且一天流量也不会均匀导致流量监控告警。故我们需要一套上线算法让流量波动均匀点。算法采用责任链的设计模式设计,RR算法兜底保证算法可靠性。
网关削峰:由于工控很多设计和定时有关,必然定时器时间到点了会产生很大的流量,因此我们需要对流量削峰处理。流量削峰应用在,机器定时重启、机器定时任务定时参数的一个基准。
2.3.1、网关削峰算法设计
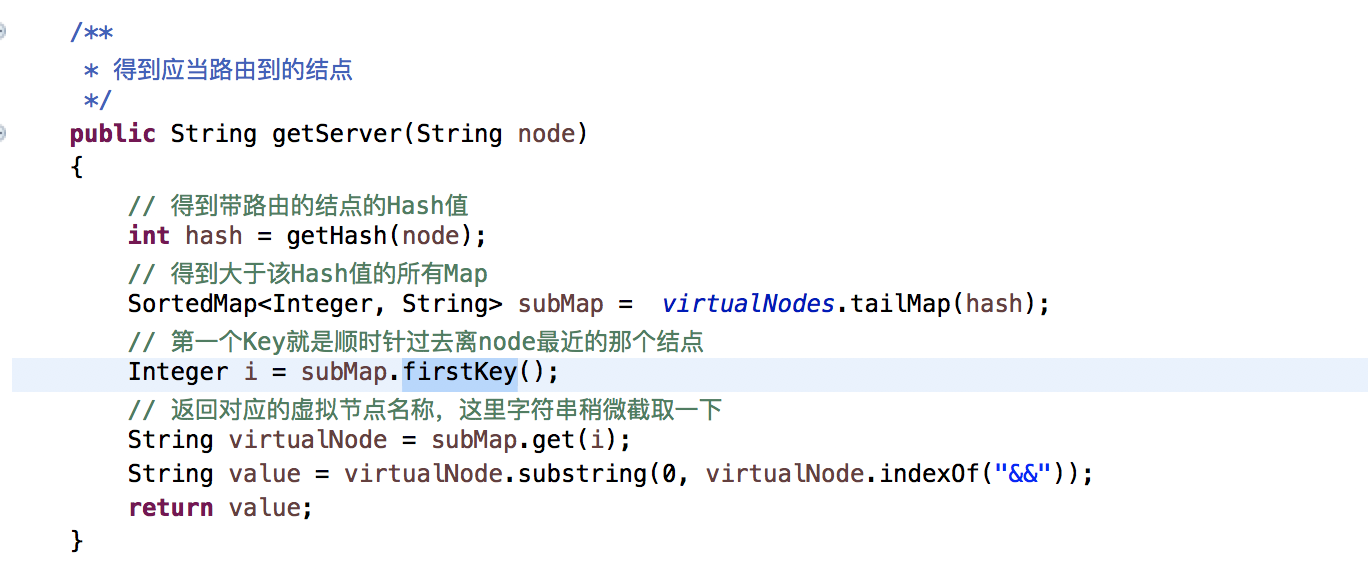
网关削峰设计基于一致性hash算法。算法思想:将工控关机时间【2:00-4:00】共计7200秒,加上500倍的虚拟节点,分布在0-2的32次方范围的hash环上的数据结构。当工控握手的时候获取工控机的vemId的hashcode,在hash环上获取一个hash段,然后获取hash段的firstKey作为目标的key,取value就是工控重启的时间点。
2.4.2、网关负载算法设计
权重算法场景:手动按照比例分配流量的场景。比如:1、流量按照1:9的比例分配,2、解决最小链接数场景的水位不差距调优。
最少链接数算法场景:设置阈值当触发阈值流量都流向链接数最小的节点
RR算法场景:流量平均分配
2.4.1.1、权重算法
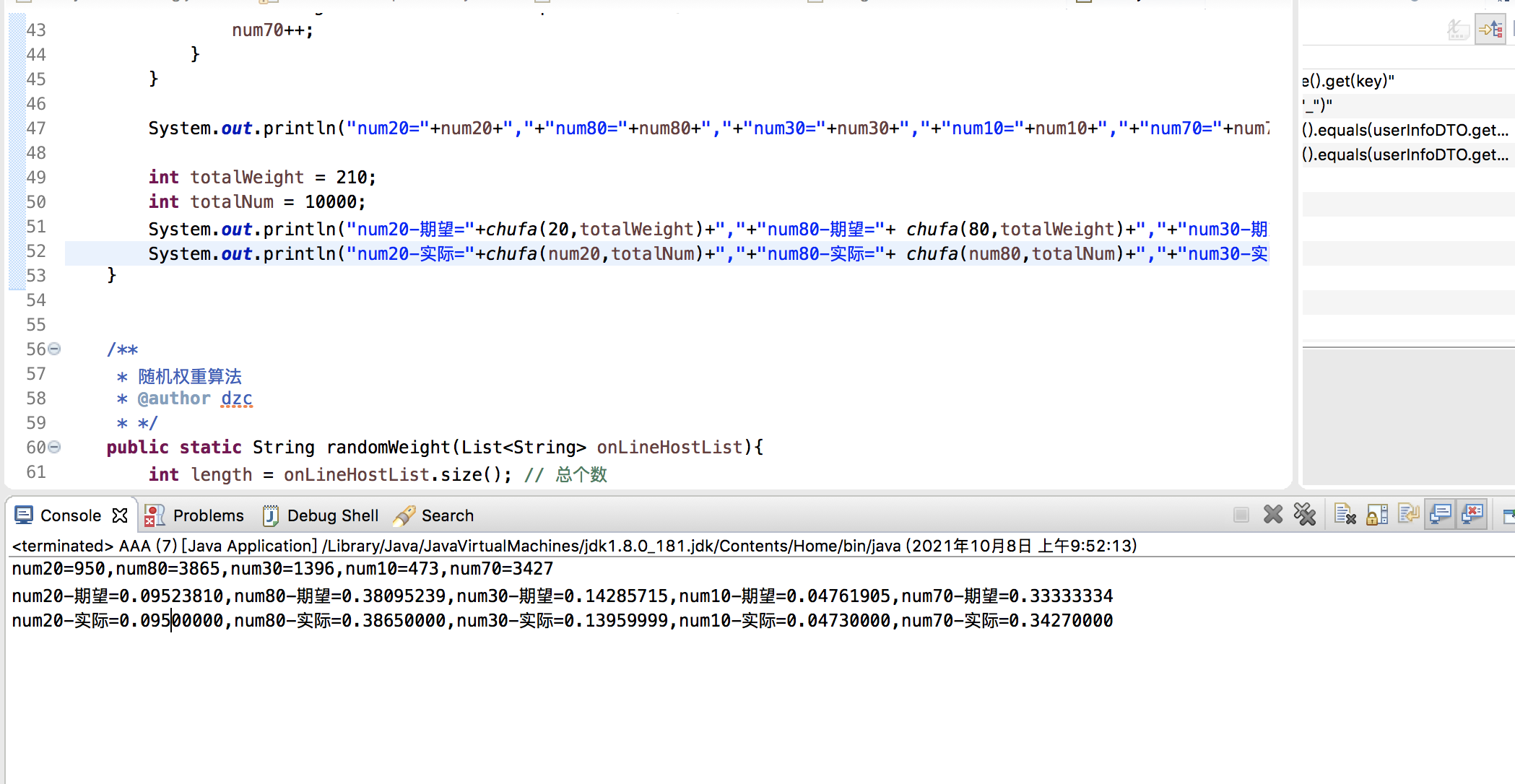
权重算法使用的是随机权重算法。权重算法触发条件是,集群节点权重值不一致。ps:随机权重算法有一定的误差,误差范围我测试是千分之一左右。为什么不做到精确?因为要保证算法的性能,如果做到精确就要加锁。
算法思想:
1、累加节点的所有权重值totalWeight
2、在totalWeight范围内进行随机得到随机权重offsetWeight
3、随机权重和每个节点的权重对比,如果权重落在第一个符合条件的节点权重范围内,就代表此节点被选中。

权重算法误差测试:
2.4.1.2、最少链接算法
通过获取在线的服务节点上的长链接数,如果链接最多的节点的链接数比最少的多20%则触发控制。链接全部给最少的节点,等节点链接数在水位内,自动关闭链接最少算法,路由走RR算法。

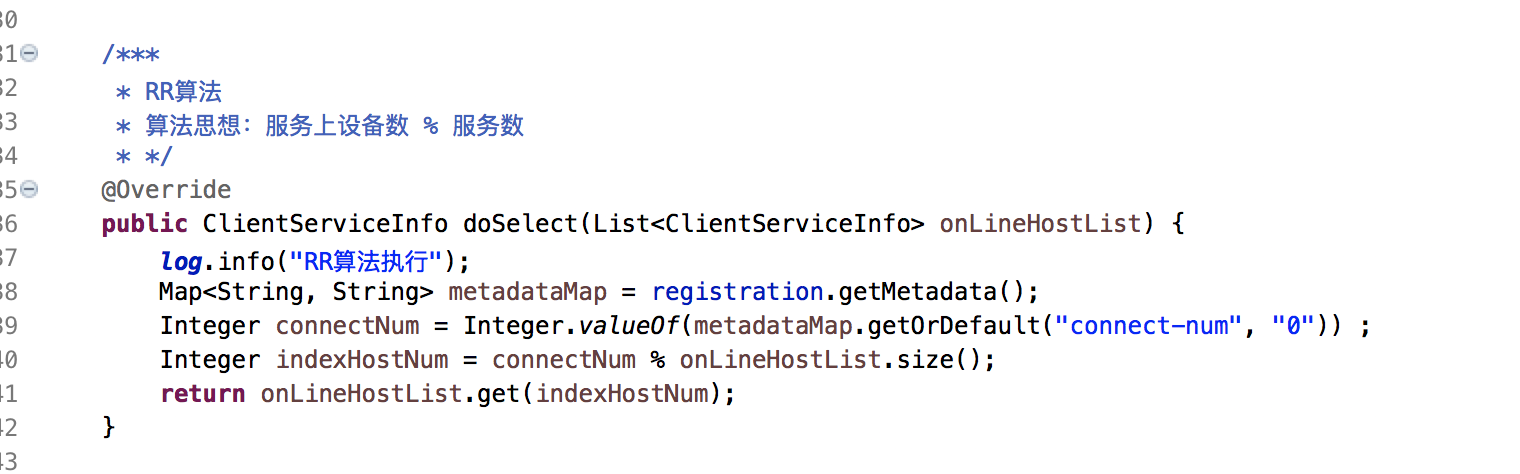
2.4.1.3、RR算法
RR算法是最后的兜底算法,链接平均的给集群中的每台机器。
2.5、缓存与限流
目前限流基于Sentinel限流方案。备选方案Guava、Sentinel、HyStrix、redis,压测过redis和Sentinel限流,差异不大。
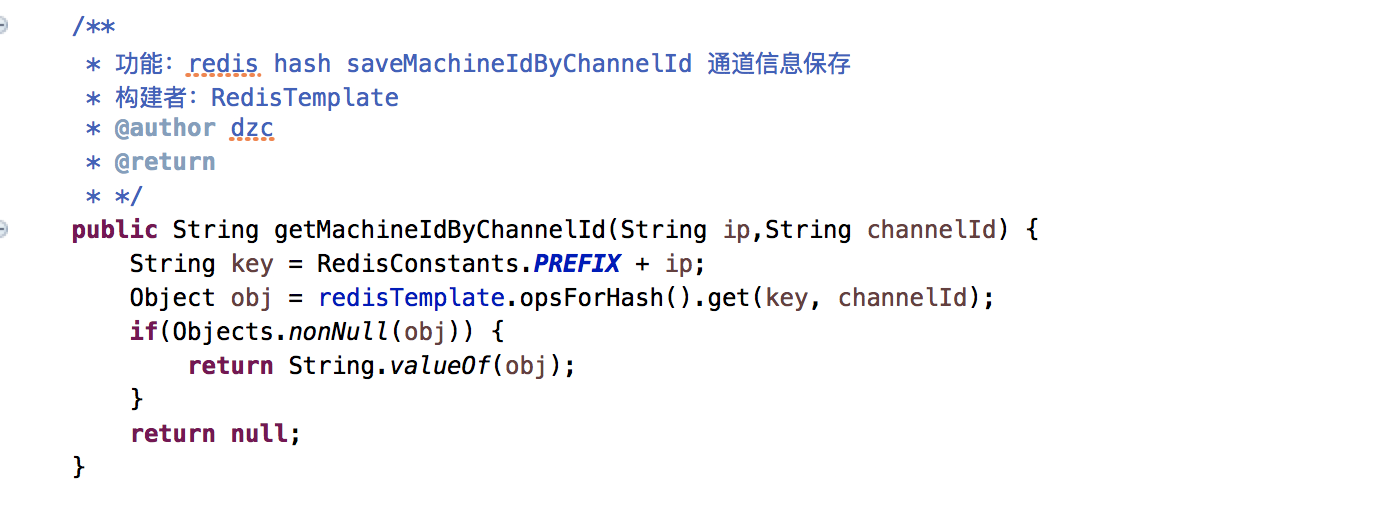
2.5.1、redis客户端
项目集成redis客户端主要保存通道机器信息。
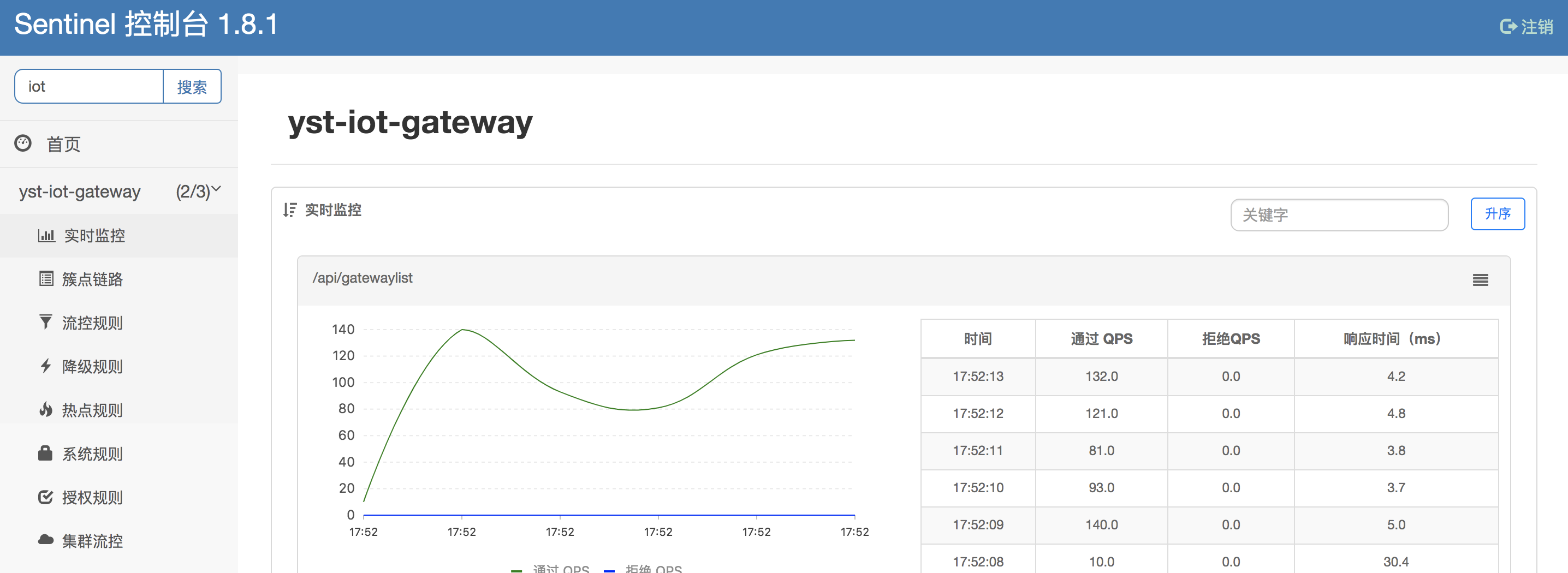
2.5.2、Sentinel限流方案
由于我司未提供Sentinel starter 基于spring cloud2.5.4,这里直接使用spring-cloud-starter-alibaba-sentinel官方版本。
2.6、消费中间件支持
项目支持kafka、rocketMq。如果切换只需要改一个注解及链接配置。

2.6.1、消息堵塞处理 - 小规模消息堵塞,自动消费方式治理消费堵塞
2.6.2、消息堵塞处理 - 大规模消息堵塞,通过调节偏移量处理消息堵塞
2.6.3、消息定向 - 工控切换后消息是否发到当前连接的工控topic上面去(后续实现)
2.6.4、网关自动消费 - 和handler对接,提供AIP动态通知handler在线的网关数,做到动态增减网关handler自动消费,建议handler本地做缓存定时刷新。
2.6.5、handler消息去重复 - 建议handler使用redisson布隆过滤器实现去重消息,注意布隆过滤器扩容和概率碰撞,合理设置碰撞概率可以做到亿分之一。
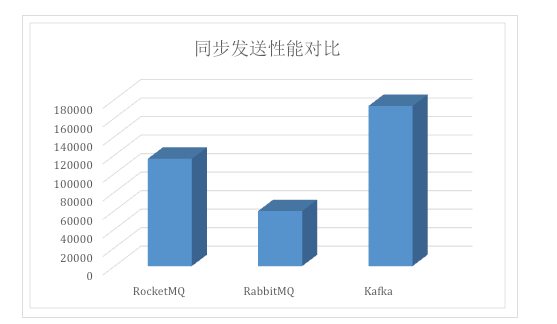
2.6.6、kafka vs rocketMq选型
在我使用感受看来区别不大,rockeMq宣传可以实现的功能kafka也能实现,kafak也能实现。kafka适合大数据、流式计算、对性能要求高的场景消息,rockeMq适合对性能要求不高运维方便的业务场景。
监控运维平台区别:
1、历史消息查看 - rockeMq比kafka好用的在于监控平台可以查询历史消息比较方便,kafak查询历史消息比较费劲要通过命令去查询。
2、重置消费位点 - rockeMq自己实现重置消费位点、堆积位点,kafka需要自己实现。
3、消息重复发送 - rockeMq可以重复发现消息再次消费,kafka需要自己实现。
性能区别:
1、传说是kafka比rocketMq性能高,关于性能测试报告,在官网没有发现测试文档,这点我没有测试,因为测试环境硬件限制可能无法发挥其能力。(阿里云测试结果)
2、kafka为性能而生的,为了性能其舍弃很多好用的功能,比如上面的监控功能。其客户端也是合并发送机制,提高并发。
参数调优:
1、kafka参数调优比较灵活,其有上百个调优参数(kafka调优参数)
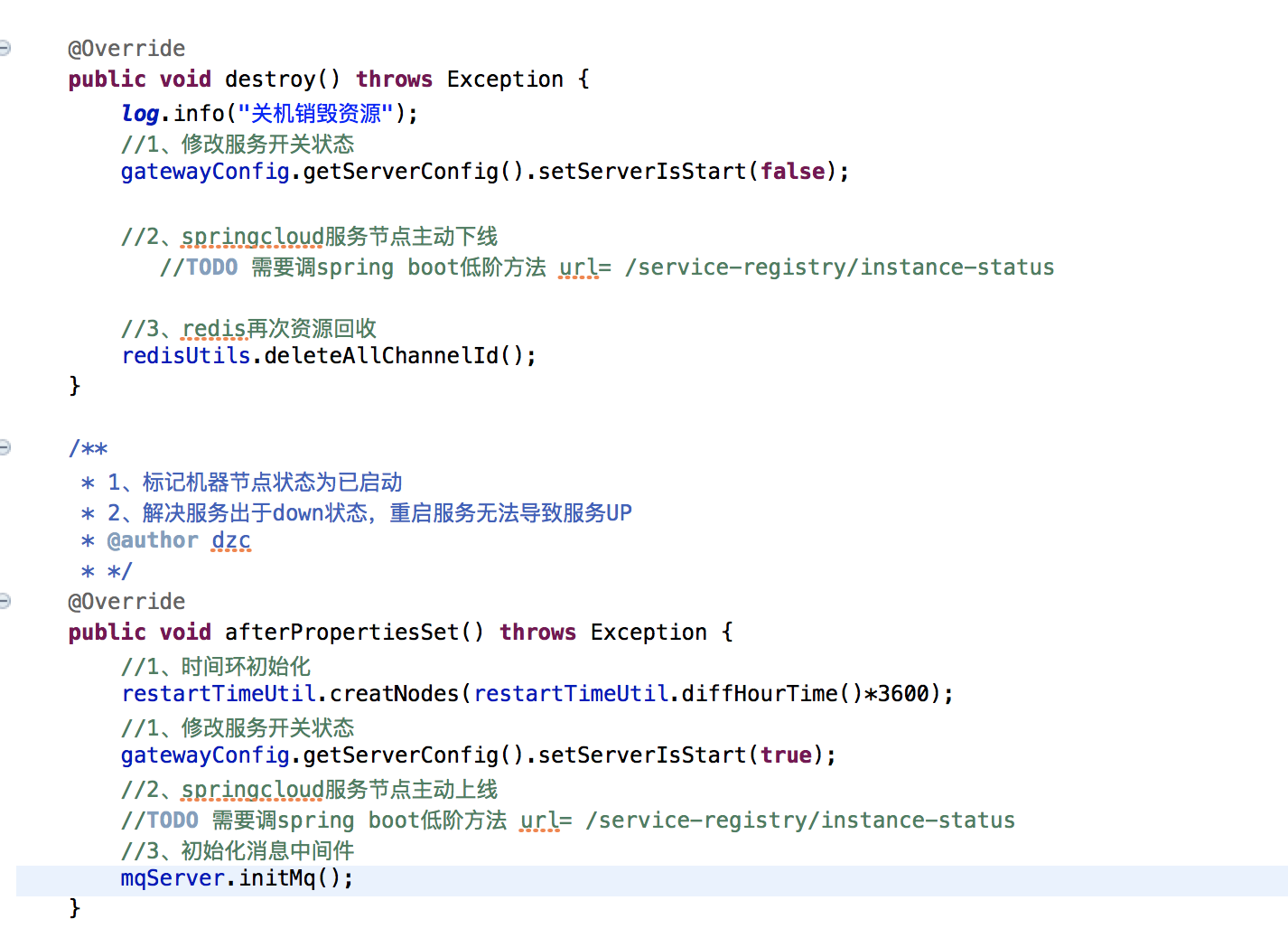
2.7、优雅开关机
优雅关机利用spring 钩子做关机资源回收。为什么不用jvm钩子,应为项目是spring环境构建的,jvm钩子适合非spring构建的程序。
2.7.1、优雅开机
时间hash环初始化:工控每天要一个重启开关机的时间窗口,自贩机这个时间点是2点-4点。算法的思想是在2的32次方的范围将7200秒均匀分配在环上,当工控握手的时候会在环上获取一个时间点作为自己重启的时间点。也作为工控定时请求后端的基础时间点,这样做的目的是让流量分配均匀。
springcloud服务上线up操作:测试和生产发现有springcloud服务出于down状态,重启项目服务依然是down状态。原因是因为服务处于down状态,重启后运维脚本没有up。咨询运维后发现是邱小泉这边决定的规则。这边为了规避这个问题自己UP自己上线。
初始化消息中间件:初始化rockMq或者kafka中间件
2.7.2、优雅关机
机器主动下线down:让机器不在产业流量分配
netty资源回收:netty boss、worker线程池回收
redis资源回收:相关的通道缓存删除
三、后端管理
1、灰度机器管理、节点权重调整、手动下线设备控制、在线机器数展示等
2、机器在线信息查询,机器流量大小、机器消息数大小等等业务关心的参数
3、消息中间件消息偏移管理开发
4、机器统计大屏统计功能
5、工控远程运维模块开发
7、app升级 [机器、全量]
8、此模块待开发
四、性能测试
上线性能测试、吞吐量测试、各种指标准确性测试
4.1、大批量上线性能测试
4.1.1、网关关机发布场景
网关停机发布,此时全量的网关会同时打向第一台开机网关,观察网关的运行情况。
测试点:
1、网关是否能抗住负载
2、网关上线并发情况
3、网关资源使用情况
测试步骤:
1、用jemter模拟出20000个工控等线程初始化就绪一次性访问网关,为什么不更多?jemter集群资源性能不够。
2、观察网关的各项指标,评估网关负载能力。
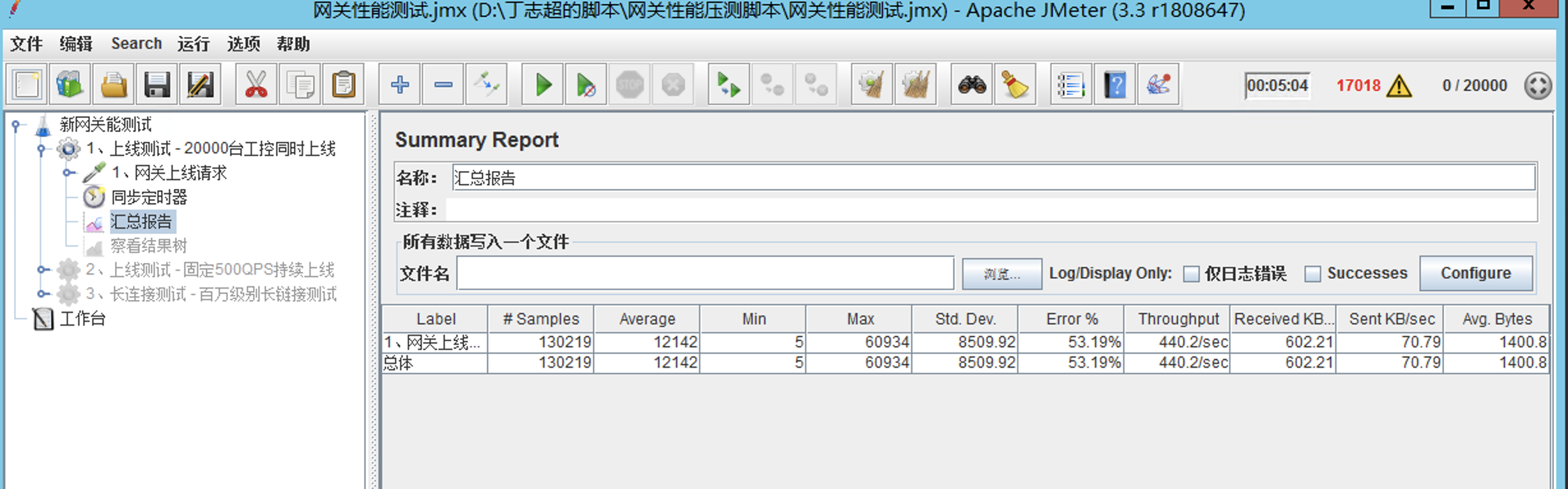
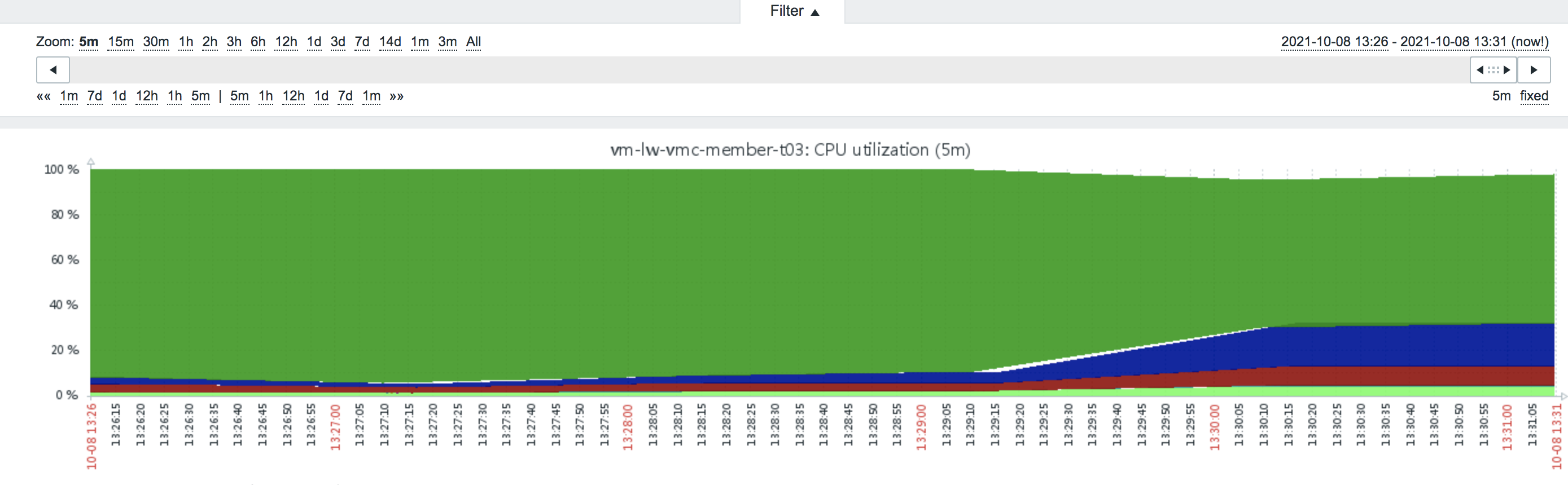
测试结果分析:
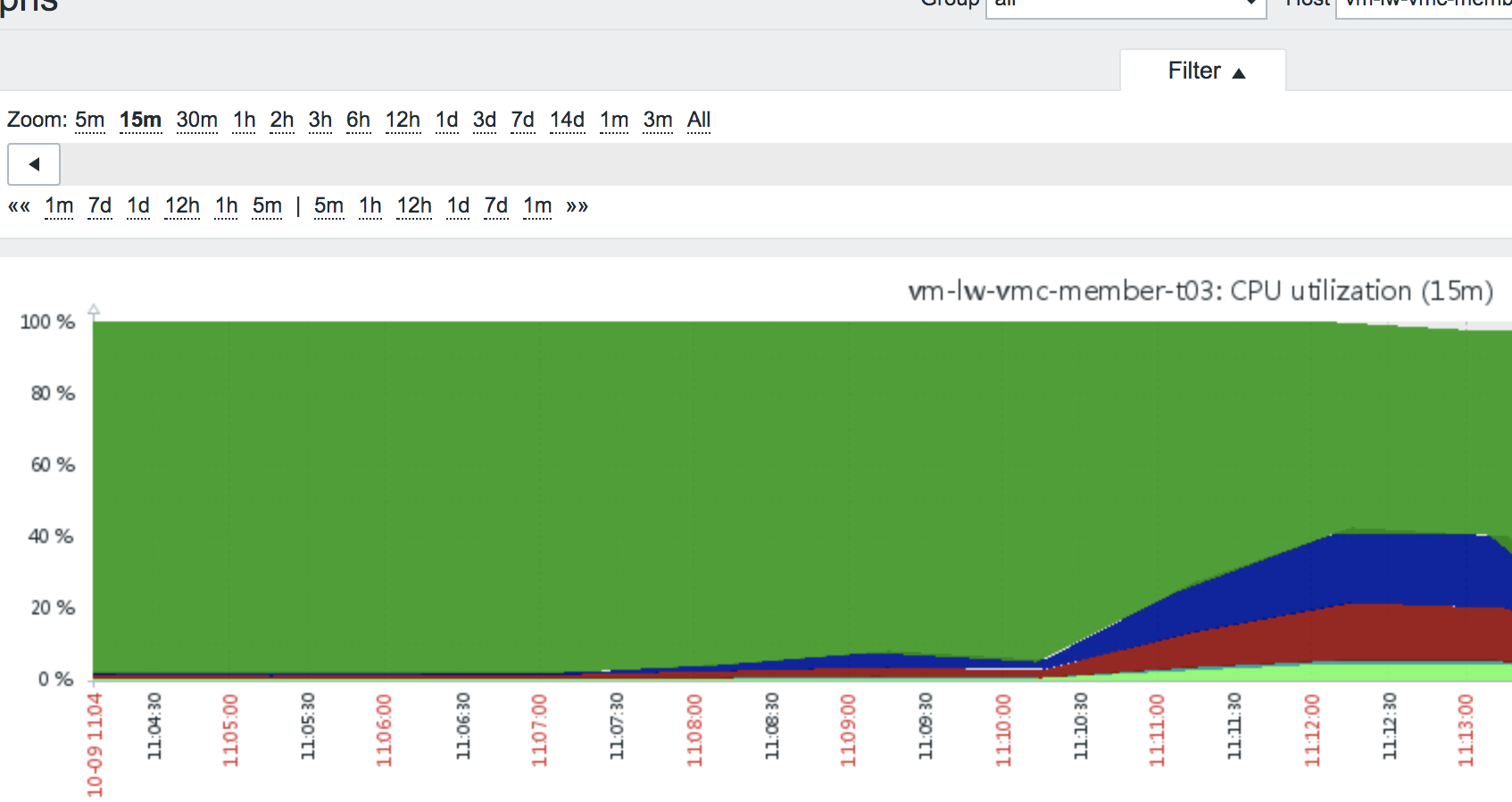
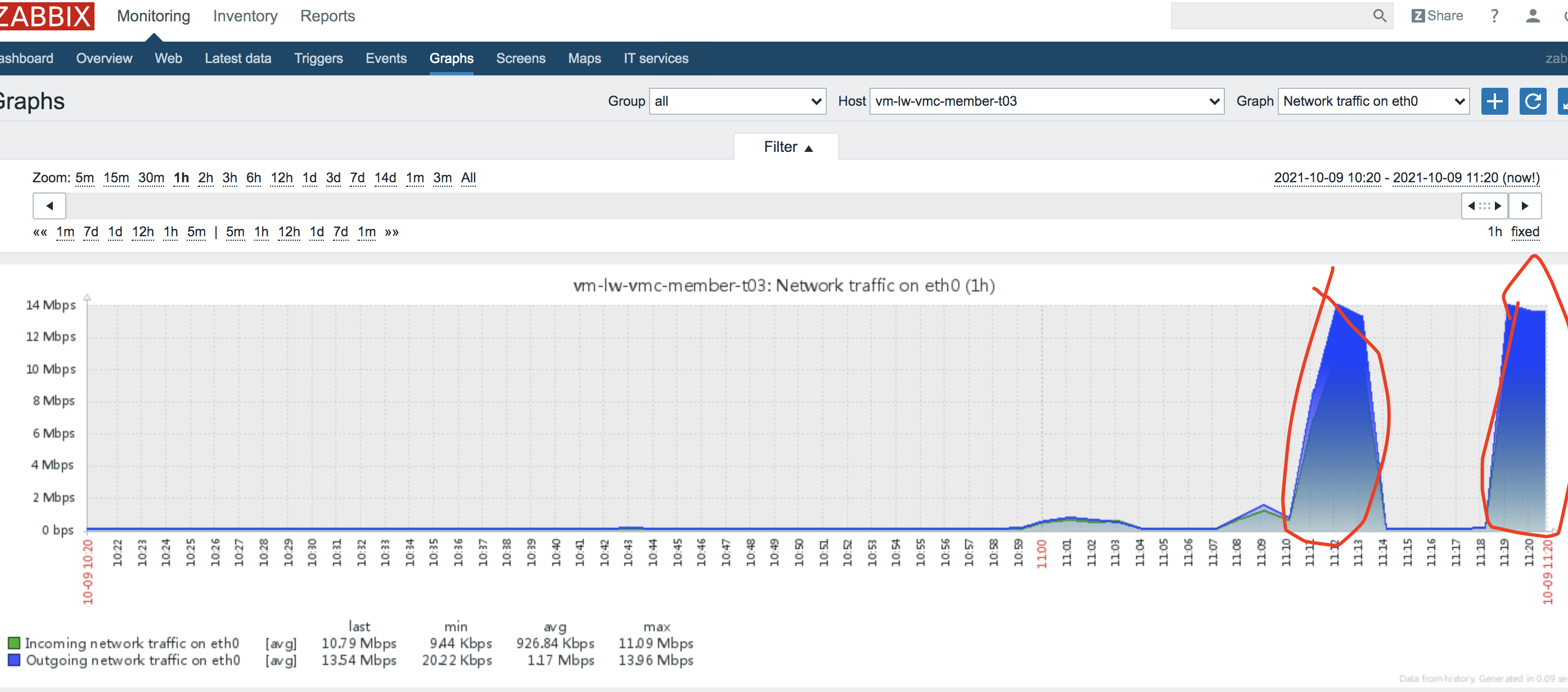
1、20000个请求同时打向网关系统资源使用40%左右。
2、由于Sentinel限流保护此时系统并没有挂。
3、由于Sentinel限流保护为500qps,压测一段时间后,QPS在420上下。
| 2万台工控同时上线 | 网关QPS | CPU资源 | 内存资源 |
|
|
|
|
|

4.2、网关负载测试
测试网关在最大连接数下工作,网关的负载情况。由于jemter tcp测试当前线程会被阻塞,无法利用当前通道发送心跳,所以测试方式是上线后发送所有的业务命令,测试满负载的系统情况。
4.2.1、测试网关最大负载场景
1、用jemter模拟出50000个工控,上线后发送业务协议,然后观察网关系统负载。
测试点:
1、用jemter模拟工控,然后慢慢上线发送握手上线,在发送业务协议。
2、然后不断增加线程数,观察网关负载。
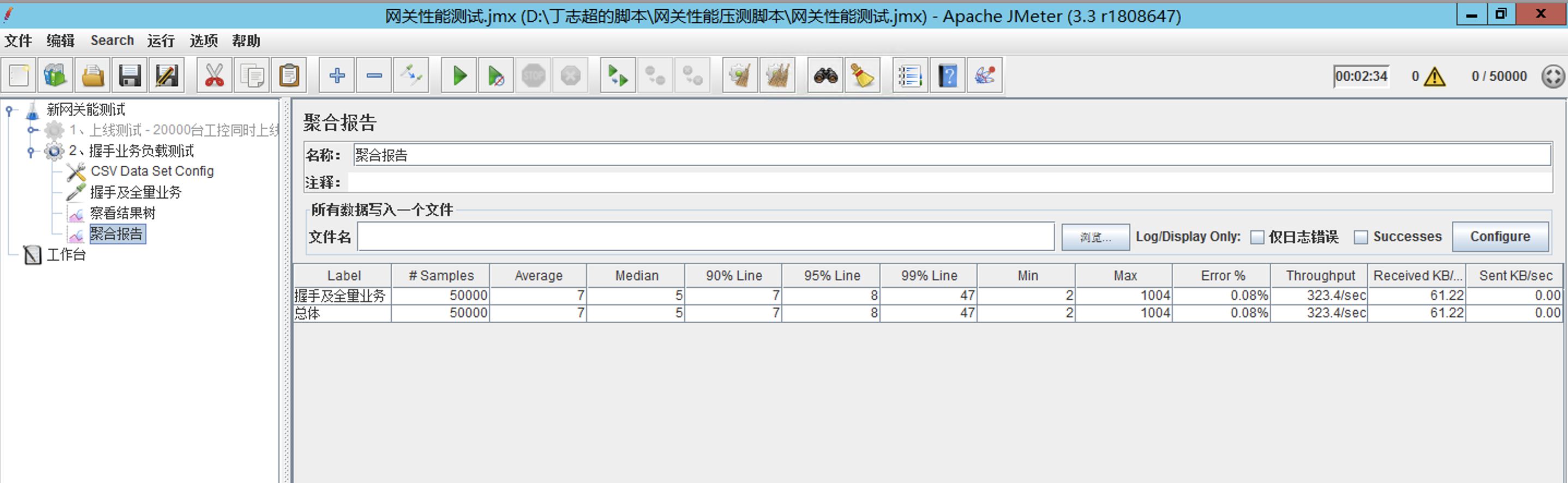
测试结果分析:
1、在不考虑带宽的前提下,系统资源消耗40%,支持qps=324全量并发。
2、根据冰柜通讯协议,1台冰柜一天会同步366次通讯。
3、推算1台网关的冰柜负载量=324*6*24*3600/366 = 458911台冰柜。
| 全量业务网关QPS | cup | 内存 | 网络资源 |
|
|
|
|
|

最后
以上就是苗条翅膀最近收集整理的关于100、网关详细设计文档一、设计思想二、使用技术三、后端管理四、性能测试的全部内容,更多相关100、网关详细设计文档一、设计思想二、使用技术三、后端管理四、性能测试内容请搜索靠谱客的其他文章。








发表评论 取消回复