1.goroutine简介
多进程、多线程已经提高了系统的并发能力,在高并发场景下,如果一个线程阻塞cpu,那就需要切换其他线程中去执行,为每个任务都创建一个线程成本比较高,因此又衍生出协程。我们知道一个线程分为“内核态“线程和”用户态“线程,goroutine是Go语言实现的用户态线程, 协程跟线程是有区别的,线程由CPU调度是抢占式的,协程由用户态调度是协作式的,一个协程让出CPU后,才执行下一个协程。
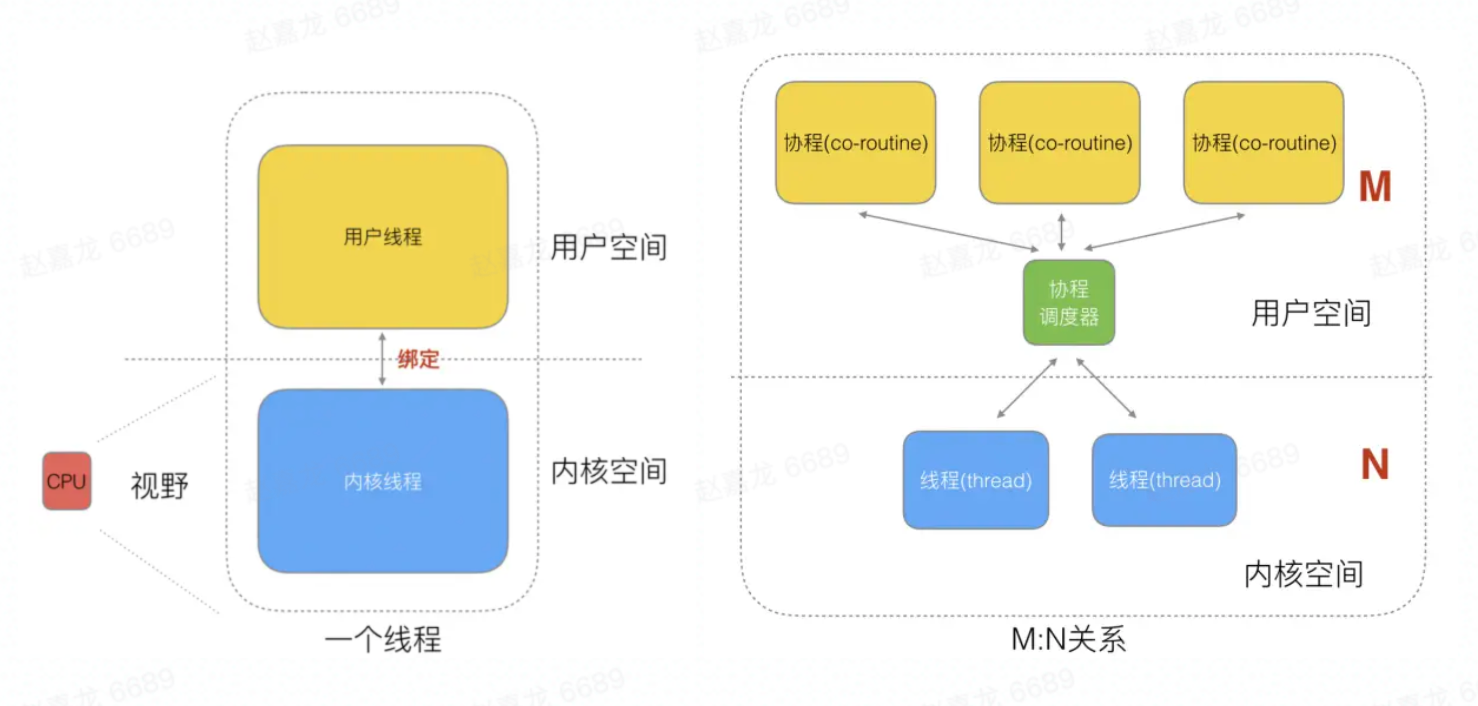
思考为什么协程和线程是M:N映射关系?
M个协程可以在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速,但是一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,无并发能力,因此需要N个线程
线程成本高主要表现在以下两个方面:
- 调度的高消耗CPU;操作系统线程的创建和切换都需要进入内核,都会占用很长时间,导致CPU有很大的一部分时间都被用来进行进程调度了
- 高内存占用;内核在创建操作系统线程时默认会为其分配一个较大的栈内存(进程虚拟内存会占用4GB[32位操作系统], 而线程也要大约4MB)
而相对的,用户态的goroutine则轻量得多:
- goroutine是用户态线程,创建和切换都在用户代码中完成而无需进入操作系统内核
- goroutine启动时默认栈大小只有2k,可自动调整容量
2.调度模型组成
1.被遗弃的GM模型
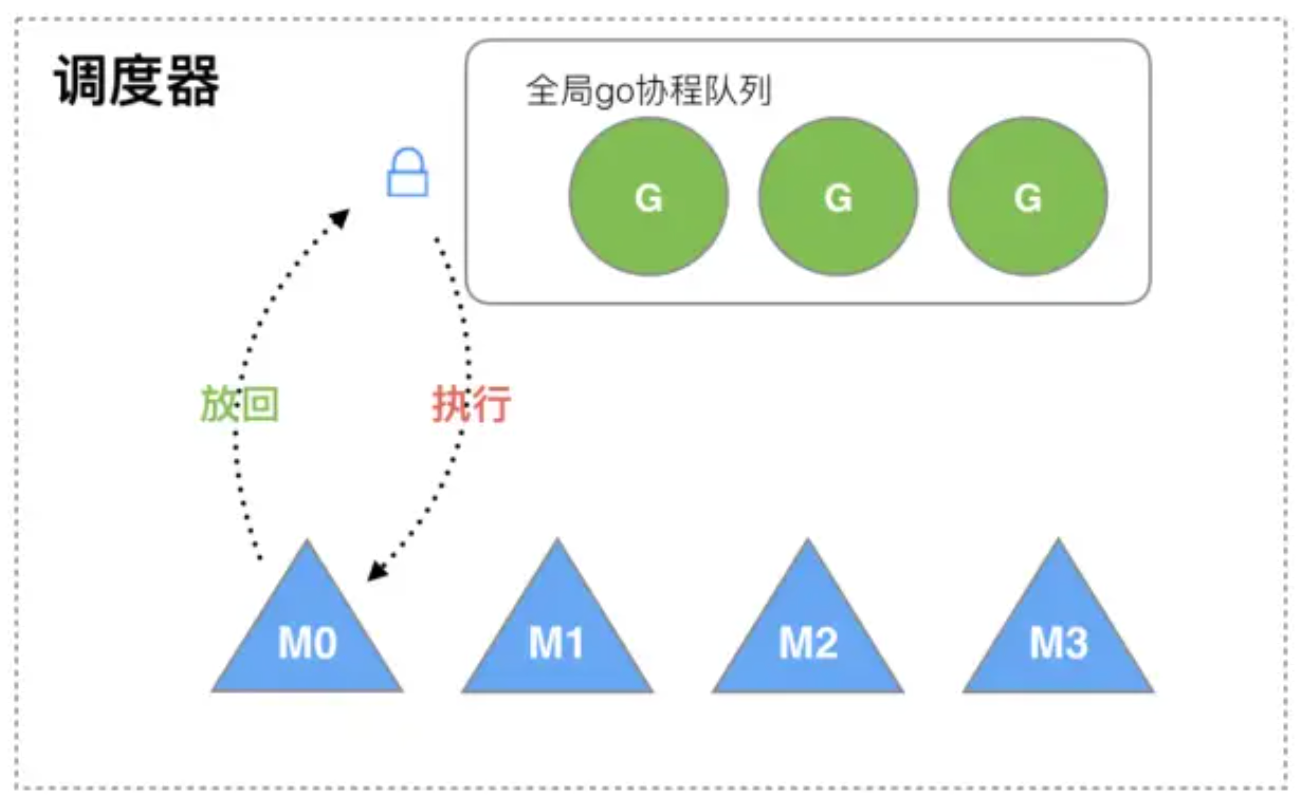
在12年的go1.1版本之前用的都是GM模型, G为Goroutine协程,M为Machine内核级线程, M想要执行、放回G都必须访问全局G队列,并且M有多个,即多线程访问同一资源需要加锁进行保证互斥/同步,所以全局G队列是有互斥锁进行保护的。
1.创建、销毁、调度G都需要每个M获取锁,这就形成了激烈的锁竞争
2.很差的局部性。比如当G中包含创建新协程的时候,M0创建了G1,因为将G1放入全局队列,,需要把G1交给M’执行,也造成了很差的局部性,因为G’和G是相关的,最好放在M上执行,而不是其他M
2.GPM模型组成
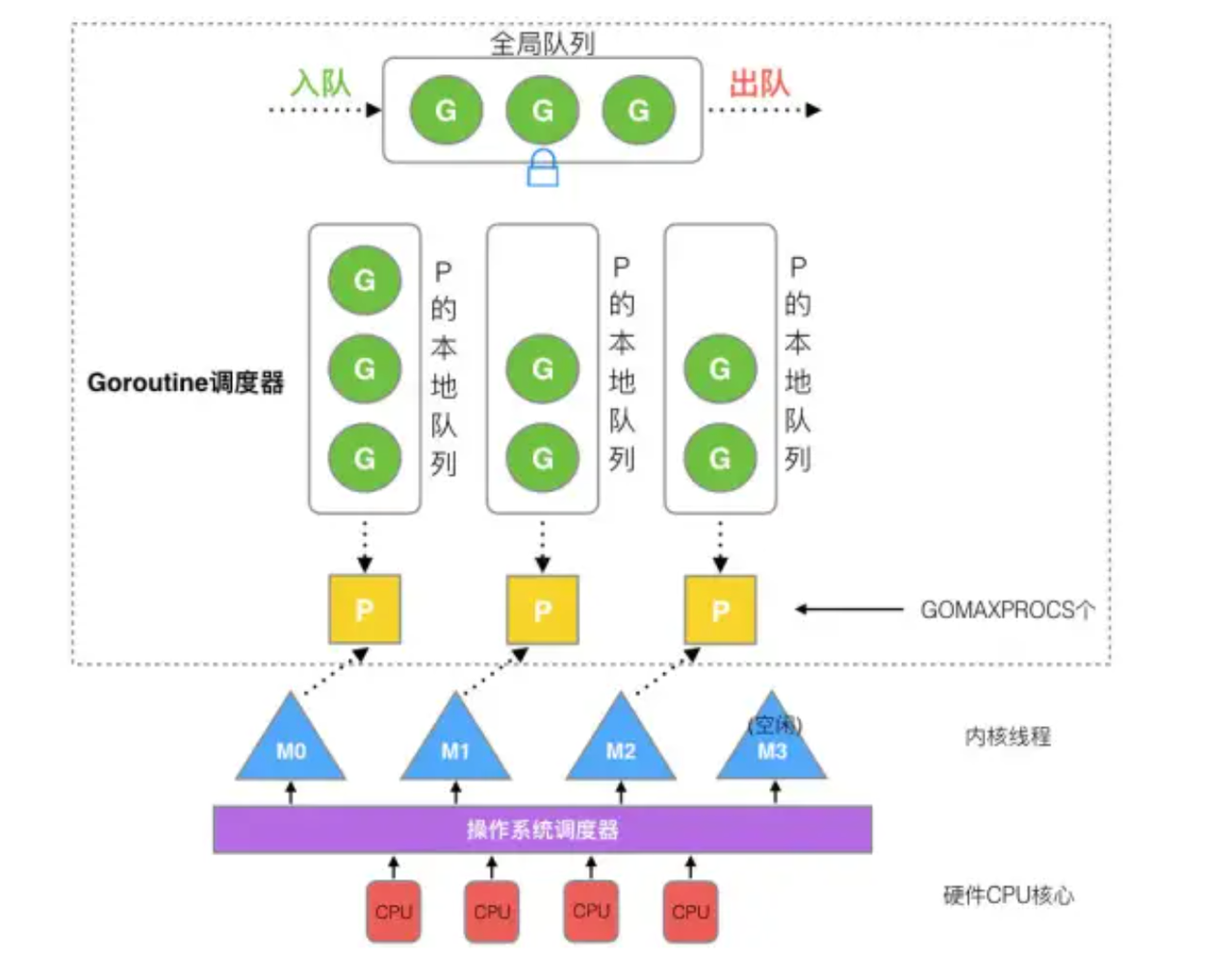
调度器主要由以下几部分组成:
schedt结构体:go调度器主体结构,保存调度器自身的状态信息,另外还有goroutine全局队列、空闲的工作线程M、空闲的p结构体对象等其他信息
// 重要的全局变量
var (
allgs []*g // 存储所有g的数组
allm *m // 存储所有m的链表,通过 m.alllink链向下一个m
allp []*p // len(allp) == gomaxprocs
gomaxprocs int32 // 最大可创建p的个数,默认为cpu个数,可通过环境变量设置
ncpu int32 // cpu个数
m0 m // 代表进程的主线程
g0 g // m0的g0,也就是m0.g0 = &g0
sched schedt
)
type schedt struct {
// 空闲状态的m
midle muintptr // idle m's waiting for work
// 空闲状态的m个数
nmidle int32 // number of idle m's waiting for work
// m允许的最大个数
maxmcount int32 // maximum number of m's allowed (or die)
nmsys int32 // number of system m's not counted for deadlock
nmfreed int64 // cumulative number of freed m's
// 系统中goroutine的数目,会自动更新
ngsys uint32 // number of system goroutines; updated atomically
// 空闲的p列表
pidle puintptr // idle p's
// 有多少个状态为空闲的p
npidle uint32
// 有多少个m自旋
nmspinning uint32 // m处于自旋状态时,是当前m没有g可运行,正在寻找可运行的g
// Global runnable queue.
// 全局的可运行的g队列
runqhead guintptr
runqtail guintptr
// 全局队列的大小
runqsize int32
// freem is the list of m's waiting to be freed when their
// m.exited is set. Linked through m.freelink.
freem *m
}
g的结构体: 它保存了goroutine的所有信息, 如保存调度信息
type g struct {
// 简单数据结构,lo 和 hi 成员描述了栈的下界和上界内存地址
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
// 当前的m
m *m // current m; offset known to arm liblink
// goroutine切换时,用于保存g的上下文,包括栈顶、栈低、pc等寄存器
sched gobuf
// 唯一的goroutine的ID
goid int64
// 标记是否可抢占
preempt bool
}
m结构体: Machine内核级线程, 每个工作线程都有唯一一个m结构体的实例对象与之对应,线程通过 ThreadLocal 存储各自的m对象;m结构体对象主要记录着工作线程的诸如栈的起止位置、当前正在执行的goroutine以及是否空闲等等状态信息之外,还通过指针维持着与p结构体的实例对象之间的绑定关系。
type m struct {
// 用来执行调度指令的 goroutine
g0 *g // goroutine with scheduling stack
morebuf gobuf // gobuf arg to morestack
// thread-local storage
tls [6]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
// 当前运行的goroutine
curg *g // current running goroutine
// 关联p和执行的go代码
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
id int64
// 用于标识睡眠还是唤醒
park note
// 是否自旋,自旋就表示M正在找G来运行
spinning bool // m is out of work and is actively looking for work
// m是否被阻塞
blocked bool // m is blocked on a note
// 用于链接allm
alllink *m // on allm
schedlink muintptr
//...
}
p结构体: P全称为Processor,所有的P都在程序启动时创建,每一个m都会与一个p结构体的实例对象关联在一起, p主要维护一份局部goroutine运行队列
type p struct {
// id也是allp的数组下标
id int32
status uint32 // one of pidle/prunning/...
// 单向链表,指向下一个P的地址
link puintptr
// 每调度一次加1
schedtick uint32 // incremented on every scheduler call
// 回链到关联的m
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
// 可运行的goroutine的队列
runqhead uint32
runqtail uint32
runq [256]guintptr
// 下一个运行的g,优先级最高
runnext guintptr
}
3.浅析调度策略
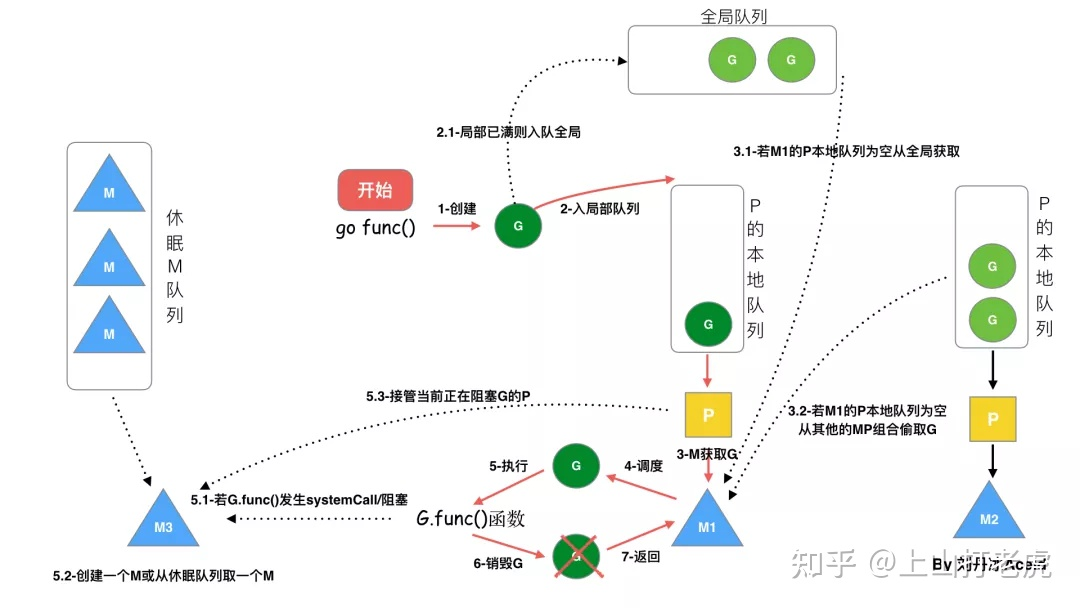
- 我们通过 go func()来创建一个goroutine
- 有两个存储G的队列,一个是局部调度器P的本地队列、一个是全局G队列。新创建的G会先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局的队列中
- G只能运行在M中,一个M必须持有一个P,M与P是1:1的关系。M会从P的本地队列弹出一个可执行状态的G来执行,如果P的本地队列为空,就会向其他的MP组合偷取一个可执行的G来执行
- 一个M调度G执行的过程是一个循环机制,如下伪代码所示
// 程序启动时的初始化代码
......
for i := 0; i < N; i++ { // 创建N个操作系统线程执行schedule函数
create_os_thread(schedule) // 创建一个操作系统线程执行schedule函数
}
// 定义一个线程私有全局变量,注意它是一个指向m结构体对象的指针
// ThreadLocal用来定义线程私有全局变量
ThreadLocal self *m
//schedule函数实现调度逻辑
func schedule() {
// 创建和初始化m结构体对象,并赋值给私有全局变量self
self = initm()
for { //调度循环
if (self.p.runqueue is empty) {
// 根据某种算法从全局运行队列中找出一个需要运行的goroutine
g := find_a_runnable_goroutine_from_global_runqueue()
} else {
// 根据某种算法从私有的局部运行队列中找出一个需要运行的goroutine
g := find_a_runnable_goroutine_from_local_runqueue()
}
run_g(g) // CPU运行该goroutine,直到需要调度其它goroutine才返回
save_status_of_g(g) // 保存goroutine的状态,主要是寄存器的值
}
}
- 当M执行某一个G时候如果发生了syscall或则其余阻塞操作,M会阻塞,如果当前有一些G在执行,runtime会把这个线程M从P中摘除(detach),然后再创建一个新的操作系统的线程(如果有空闲的线程可用就复用空闲线程)来服务于这个P
- 当M系统调用结束时候,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列。如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中,然后这个G会被放入全局队列中
3.深入调度策略
M0 : 是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量runtime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个G, 在之后M0就和其他的M一样了。
G0: 是每次启动一个M都会第一个创建的gourtine,G0仅用于负责调度的G,G0不指向任何可执行的函数, 每个M都会有一个自己的G0。在调度或系统调用时会使用G0的栈空间, 全局变量的G0是M0的G0。
1.goroutine调度器初始化
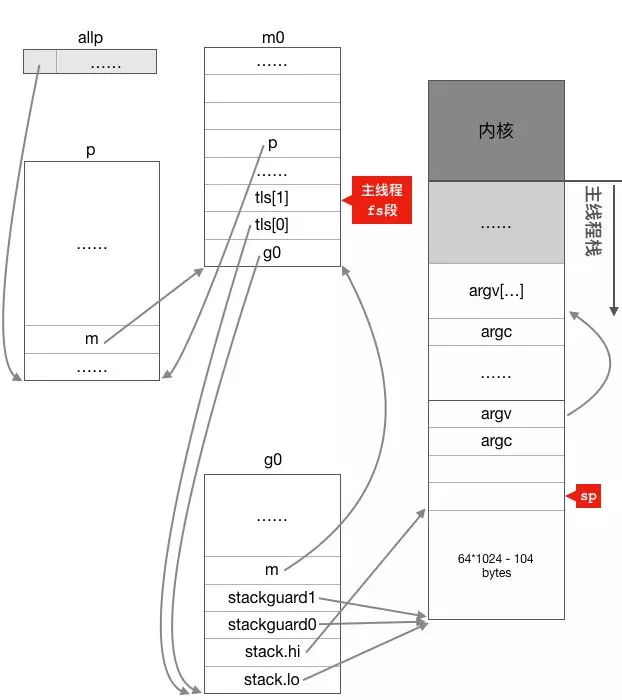
- go程序的入口点是runtime.rt0_go,go程序启动后,主线程执行时rt0_go汇编代码时,首先调用schedinit初始化
- 初始化sched对象的初始化
- 创建并初始化g0,g0是从主线程栈上空分出一部分当作g0的栈
- 创建并初始化m0,首先主线程初始化自己的线程地存储(TLS),将g0挂在到主线程的tls[0]上,m0挂在到g0的m结构上,这样m0就与主线程关联起来了,主线程通过tls 就可以间接的获取m0
m0.g0 = &g0
g0.m = &m0
- 调用procresize函数创建和初始化p结构体对象,在这个函数里面会创建指定个数(根据cpu核数或环境变量确定)的p结构体对象放在全变量allp里, 并把m0和allp[0]绑定在一起,这样第一个GPM就构建好了,然后把除了allp[0]之外的所有p放入到全局变量sched.pidle空闲队列之中
m0.p = allp[0]
allp[0].m = &m0
注:线程的TLS是通过fs段寄存器实现的,不同的线程都有一组fs段寄存器,每个线程可以通过访问自己的fs段基地址,这样看似同一个全局变量但在不同线程中却拥有不同的内存地址,获取到私有的全局变量; 主线程把m0.tls[1]的地址设置成了fs段的段基址,m0.tls[0]的地址设置成g0的地址, 主线程中通过get_tls可以获取到g0了,通过g0的m成员又可以找到m0,于是这里就实现了m0和g0与主线程之间的关联
2. main goroutine调度
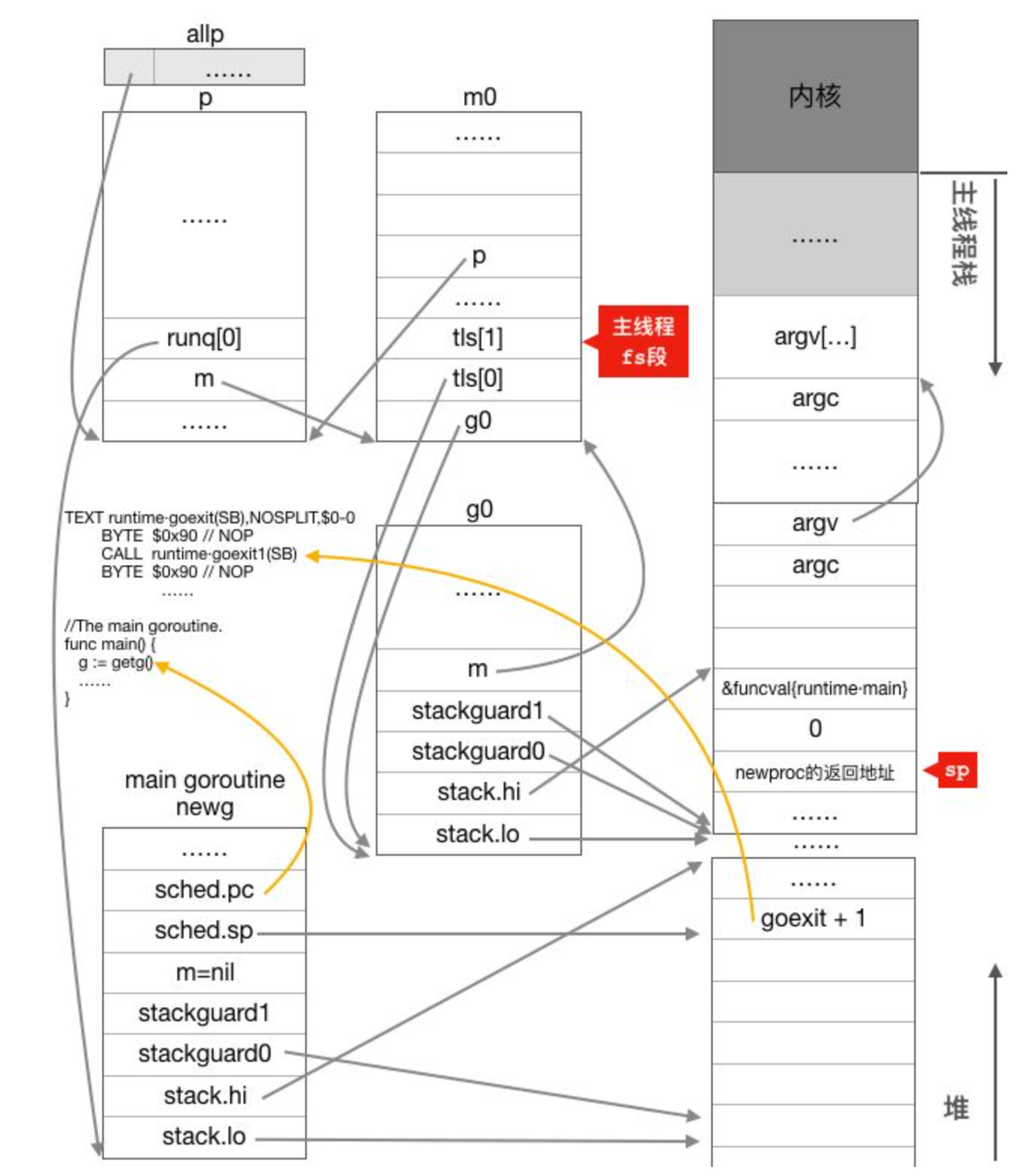
main goroutine 函数初始化过程:
- 完成调度器初始化后,又回到runtime.rt0_go函数,继续往下执行,紧接着会调用newproc()创建一个新的goroutine, 指向的是runtime.main
- newproc这个函数在创建普通的goroutine时也会使用,因此newproc首先会切换到g0栈(main goroutine是初始化时创建,当前就在g0栈,不用切换),然后调用newproc1进行下一步处理
为什么需要切换到g0栈创建初始化goroutine?
因为g0存储着一些调度器相关的栈空间,例如在调度循环中,schedule函数每新一轮调度都会重用上一轮调度的g0栈空间,因为schedule是调用自己完成循环调度的,每一轮调度结束都要切换到g0栈时都是切换到g0.sched.sp所指的固定位置,进行下一轮调度
- 首先从g0.m.p的本地队列中获取空闲的g, 本地列获取不到去全局队列获取,都没有获取到,则创建一个新newg, 在状态设置成_Gdead, 并放入全局变量allgs
- 对新创建newg进行初始化,从堆上分配一个g结构体对象并为这个newg分配一个大小为2k的栈,并设置好newg的stack成员
- 调用gostartcall函数调整栈空间和设置newg执行函数地址
- 调整newg的栈空间,把goexit函数的第二条指令的地址入栈,伪造成goexit函数调用了fn,从而使fn执行完成后执行ret指令时返回到goexit继续执行完成最后的清理工作;
- 重新设置newg.buf.pc 为需要执行的函数的地址,我们这个场景为runtime.main函数的地址。
- 设置newg的状态为_Grunnable,表示这个newg代表的goroutine可以运行了
- 把newg放入当前主线程绑定的p结构体对象的本地运行队列,这算是第一个真正意义上的goroutine,初始化的时候一定是p的本地运行队列,其它时候可能因为本地队列满了而放入全局队列
为什么要将newg的返回地址设置成goexit函数,直接在newg逻辑执行完之后 再调用goexit1完成最后的清理工作不行吗?
设置goexit其实是为非main goroutine准备的,非main goroutine执行完成后就会返回到goexit继续执行,结束goroutine ,而main goroutine执行完成后直接调用exit()整个进程就结束了,这是main goroutine与其它goroutine的一个区别。
启动m0进行循环调度,执行main goroutine的流程:
- 程序主线程创建main goroutine 后又回到runtime.rt0_go继续往下执行,调用mstart函数启动m0
- mstart会调用mstart1,mstart1首先调用下面save(getcallerpc(), getcallersp())函数保存g0的调度信息,主要是保存mstart调用mstart1时被call指令压栈的返回地址,调用mstart1函数之前mstart函数的栈顶地址
func mstart1() {
_g_ := getg() //启动过程时 _g_ = m0的g0
if _g_ != _g_.m.g0 {
throw("bad runtime·mstart")
}
//getcallerpc()获取mstart1执行完的返回地址
//getcallersp()获取调用mstart1时的栈顶地址
save(getcallerpc(), getcallersp())
asminit() //在AMD64 Linux平台中,这个函数什么也没做,是个空函数
minit() //与信号相关的初始化,目前不需要关心
if _g_.m == &m0 { //启动时_g_.m是m0,所以会执行下面的mstartm0函数
mstartm0() //也是信号相关的初始化,现在我们不关注
}
if fn := _g_.m.mstartfn; fn != nil { //初始化过程中fn == nil
fn()
}
if _g_.m != &m0 {// m0已经绑定了allp[0],不是m0的话还没有p,所以需要获取一个p
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}
//schedule函数永远不会返回
schedule()
}
- 调用schedule函数寻找需要运行的goroutine,我们这个场景找到的是main goroutine;
- 为了保证调度的公平性,每进行61次调度就需要优先从全局运行队列中获取goroutine
- 从与m关联的p的本地运行队列中获取goroutine
- 如果从本地运行队列和全局运行队列都没有找到需要运行的goroutine,则调用findrunnable函数从其它工作线程的运行队列中偷取,如果偷取不到,则当前工作线程进入睡眠
func schedule() {
_g_ := getg() //_g_ = 每个工作线程m对应的g0,初始化时是m0的g0
//......
var gp *g
//......
if gp == nil {
//为了保证调度的公平性,每进行61次调度就需要优先从全局运行队列中获取goroutine,
//因为如果只调度本地队列中的g,那么全局运行队列中的goroutine将得不到运行
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock) //所有工作线程都能访问全局运行队列,所以需要加锁
gp = globrunqget(_g_.m.p.ptr(), 1) //从全局运行队列中获取1个goroutine
unlock(&sched.lock)
}
}
if gp == nil {
//从与m关联的p的本地运行队列中获取goroutine
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
if gp == nil {
//如果从本地运行队列和全局运行队列都没有找到需要运行的goroutine,
//则调用findrunnable函数从其它工作线程的运行队列中偷取,如果偷取不到,则当前工作线程进入睡眠,
//直到获取到需要运行的goroutine之后findrunnable函数才会返回。
gp, inheritTime = findrunnable() // blocks until work is available
}
//跟启动无关的代码.....
//当前运行的是runtime的代码,函数调用栈使用的是g0的栈空间
//调用execte切换到gp的代码和栈空间去运行
execute(gp, inheritTime)
}
- 调用execute完成goroutine启动准备工作,这里首先把gp的状态从_Grunnable修改为_Grunning,然后把gp和当前m关联起来
- 调用gogo函数首先从g0栈切换到main goroutine的栈,进行CPU执行权的转让以及栈的切换, 从main goroutine的g结构体对象之中取出sched.pc的值并使用JMP指令跳转到该地址去执行;
func execute(gp *g, inheritTime bool) {
_g_ := getg() //g0
//设置待运行g的状态为_Grunning
casgstatus(gp, _Grunnable, _Grunning)
//......
//把g和m关联起来
_g_.m.curg = gp
gp.m = _g_.m
//......
//gogo完成从g0到gp真正的切换
//1.把gp.sched的成员恢复到CPU的对应寄存器完成状态以及栈的切换;
//2.跳转到gp.sched.pc所指的指令地址(runtime.main)处执行
gogo(&gp.sched)
}
- main goroutine执行完毕直接调用exit系统调用退出进程。
3.非main goroutine的退出及调度循环
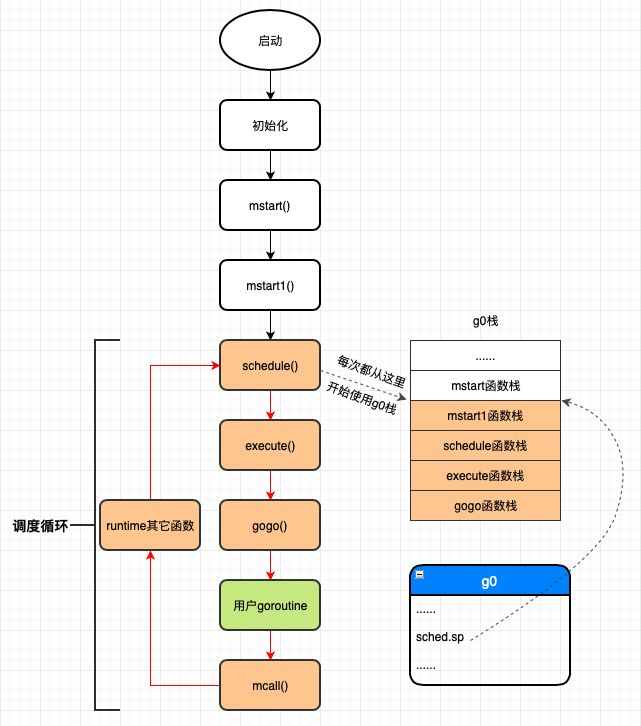
非main goroutine执行完成后就会返回到goexit继续执行,而main goroutine执行完成后整个进程就结束了,这是main goroutine与其它goroutine的一个区别
执行过程:
- 初始化,调用mstart函数,做一些g0边界检查之类的事情,然后调用mstart1函数
- 在mstart1函数中调用save函数保存mstart1函数结束后的地址等调度信息到g0.sched中
- 依次调用schedule->execute->gogo函数执行调度;
- 运行用户的goroutine代码;
- 用户goroutine代码调用结束会返回到会goexit1函数,然后这些函数调用mcall,将当前工作线程的从g2切换到g0,此时g0的栈是前面save保存schedule执行完饭回到mstart1之后的栈
mcall函数主要有两个功能:
- 首先从当前运行的g(我们这个场景是g2)切换到g0,这一步包括保存当前g的调度信息,把g0设置到tls中,修改CPU的rsp寄存器使其指向g0的栈;
- 以当前运行的g(我们这个场景是g2)为参数调用fn函数(此处为goexit0)。
// 当goroutine结束后,会调用这个函数
func goexit1() {
if raceenabled {
racegoend()
}
// goroutine trace 结束记录
if trace.enabled {
traceGoEnd()
}
// 切换到g0执行goexit0
mcall(goexit0)
}
从g2栈切换到g0栈之后,下面开始在g0栈执行goexit0函数,该函数完成最后的清理工作:
- 把g的状态从_Grunning变更为_Gdead;
- 然后把g的一些字段清空成0值;
- 调用dropg函数解除g和m之间的关系,其实就是设置g->m = nil, m->currg = nil;
- 把g放入p的freeg队列缓存起来供下次创建g时快速获取而不用从内存分配。freeg就是g的一个对象池;
- 调用schedule函数再次进行调度;
- 再次调用schedule函数进入新一轮调度,之后工作线程一直循环执行着3~5这一调度循环直到进程退出为止
问题:
m0是主线程初始化时创建,并主动调用mstart()进行循环调度, 那此时只有一个主线程,那其他m1、m2是什么时机被创建并进入各自的schedule循环调度呢?
4.协作与抢占
1.主动调度
Goroutine的主动调度是指当前正在运行的goroutine通过直接调用runtime.Gosched()函数暂时放弃运行而发生的调度。
func Gosched() {
checkTimeouts() //amd64 linux平台空函数
//切换到当前m的g0栈执行gosched_m函数,并保存g2的sched.sp和sched.bp这几个寄存器代表了g2的调度现场信息
mcall(gosched_m)
//再次被调度起来则从这里开始继续运行
}
// gosched_m 调用 goschedImpl
func goschedImpl(gp *g) {
......
casgstatus(gp, _Grunning, _Grunnable)
dropg() //设置当前m.curg = nil, gp.m = nil,把gp关联的m去掉
lock(&sched.lock)
globrunqput(gp) //把gp放入sched的全局运行队列runq
unlock(&sched.lock)
schedule() //进入新一轮调度
}
2.被动调度
举个例子:goroutine因操作channel被阻塞而发生的被动调度,其实发生被动调度的情况还比较多,比如因读写网络连接而阻塞、加锁被阻塞或select操作阻塞等等都会发生被动调度
package main
func start(c chan int) {
c <- 100
}
func main() {
c := make(chan int)
go start(c)
<-c
}
- 假设main创建好g2后首先阻塞在了对channel的读操作上
- 阻塞后main goroutine会被挂入channel的读取队列之中并调用mcall从当前main goroutine切换到g0去执行park_m函数
func park_m(gp *g) {
_g_ := getg()
if trace.enabled {
traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip)
}
casgstatus(gp, _Grunning, _Gwaiting)
dropg() //解除g和m之间的关系
......
schedule()
}
- park_m首先把当前goroutine的状态设置为_Gwaiting(因为它正在等待其它goroutine往channel里面写数据),然后调用dropg函数解除g和m之间的关系,然后通过调用schedule函数进入调度循环进行下一轮调度
- 假设只有一个工作线程在进行调度,那此时g2还在运行队列里,所以在这里schedule会把g2调度起来运行
- g2写操作执行完之后,会调用goready函数切换到g0栈并唤醒读取队列中对应的goroutine,即正在等待读channel的main goroutine,唤醒只指把goroutine的状态设置为_Grunnable,然后把其放入运行队列之中等待调度器的调度。这个唤醒main goroutine就属于 被动调度。
3.抢占式调度
go1.14以前是基于函数调用扩栈监测进行响应抢占,go1.14以后支持基于信号抢占,信号强占实时性更高,下面主要讲解基于函数调用扩栈监测进行响应抢占的版本
func main() {
var x int
threads := runtime.GOMAXPROCS(0)
for i := 0 ; i < threads; i++ {
go func() {
for {
x++
}
}()
}
time.sleep(time.second)
fmt.Println("x=",x)
}
_____________________
g1.14输出: 0
g1.13输出: 卡死
对于运行时间过长的goroutine,系统监控线程首先会提出抢占请求,然后工作线程在适当的时候会去响应这个请求并暂停被抢占goroutine的运行,最后工作线程再调用schedule函数继续去调度其它goroutine;
设置抢占标识:
sysmon系统监控线程一直轮询的执行retake函数,遍历所有p,对运行中p判断goroutine连续运行超过了10毫秒,则会调用preemptone函数向该goroutine发出抢占请求。
sysmons是系统后台监控线程,而且这个函数不符合GPM模型,该函数直接占用一个M,且不需要P,没有任何上下文切换,用不着P
const forcePreemptNS = 10 * 1000 * 1000 // 10ms
func retake(now int64) uint32 {
......
for i := 0; i < len(allp); i++ { //遍历所有的P
_p_ := allp[i]
if _p_ == nil {
continue
}
//_p_.sysmontick用于sysmon线程记录被监控p的系统调用时间和运行时间
pd := &_p_.sysmontick
s := _p_.status
if s == _Prunning { //P处于运行状态,需要检查其是否运行得太久了
// Preempt G if it's running for too long.
//_p_.schedtick:每发生一次调度,调度器++该值
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
//监控线程监控到一次新的调度,所以重置跟sysmon相关的schedtick和schedwhen变量
pd.schedtick = uint32(t)
pd.schedwhen = now
continue
}
//pd.schedtick == t说明(pd.schedwhen ~ now)这段时间未发生过调度,
//所以这段时间是同一个goroutine一直在运行,下面检查一直运行是否超过了10毫秒
if pd.schedwhen+forcePreemptNS > now {
//从某goroutine第一次被sysmon线程监控到正在运行一直运行到现在还未超过10毫秒
continue
}
//连续运行超过10毫秒了,设置抢占请求
preemptone(_p_)
}
}
return 0
}
func preemptone(_p_ *p) bool {
mp := _p_.m.ptr()
if mp == nil || mp == getg().m {
return false
}
//gp是被抢占的goroutine
gp := mp.curg
if gp == nil || gp == mp.g0 {
return false
}
gp.preempt = true //设置抢占标志
// Every call in a go routine checks for stack overflow by
// comparing the current stack pointer to gp->stackguard0.
// Setting gp->stackguard0 to StackPreempt folds
// preemption into the normal stack overflow check.
//stackPreempt是一个常量0xfffffffffffffade,是非常大的一个数
gp.stackguard0 = stackPreempt //设置stackguard0使被抢占的goroutine去处理抢占请求
return true
}
响应抢占请求:
注意上面抢占处理时设置stackguard0是非常大的一个数, 每个函数执行入口都会执行newstack(),检查是否需要扩栈的操作,然后被抢占的goroutine在函数的的入口处检查g的stackguard0成员是一个非常大的数,已经栈溢出,并且preempt为true就会执行响应抢占的操作
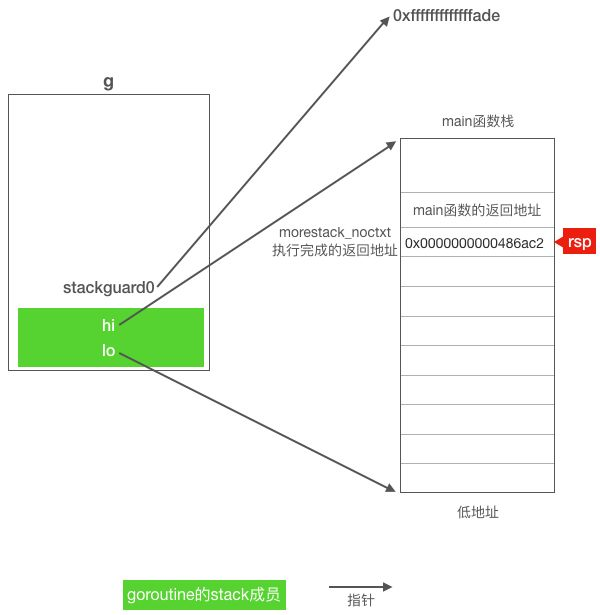
func newstack() {
thisg := getg() // thisg = g0
......
// 这行代码获取g0.m.curg,也就是需要扩栈或响应抢占的goroutine
// 对于我们这个例子gp = main goroutine
gp := thisg.m.curg
......
//检查g.stackguard0是否被设置为stackPreempt
preempt := atomic.Loaduintptr(&gp.stackguard0) == stackPreempt
if preempt {
if gp == thisg.m.g0 {
throw("runtime: preempt g0")
}
if thisg.m.p == 0 && thisg.m.locks == 0 {
throw("runtime: g is running but p is not")
}
......
//下面开始响应抢占请求
// Act like goroutine called runtime.Gosched.
//设置gp的状态,省略的代码在处理gc时把gp的状态修改成了_Gwaiting
casgstatus(gp, _Gwaiting, _Grunning)
//调用gopreempt_m把gp切换出去
gopreempt_m(gp) // never return
}
......
}
// gopreempt_m 调用 goschedImpl
func gopreempt_m(gp *g) {
if trace.enabled {
traceGoPreempt()
}
// 该函数首先把gp的状态从_Grunning设置成_Grunnable,并通过dropg函数解除当前工作线程m和gp之间的关系,然后把gp放入全局队列等待被调度器调度,最后调用schedule()函数进入新一轮调度。
goschedImpl(gp)
}
对正在系统调用中g进行抢占:
对于系统调用执行时间过长的goroutine,调度器并没有暂停其执行,只是剥夺了正在执行系统调用的工作线程所绑定的p,要等到工作线程从系统调用返回之后绑定p失败的情况下该goroutine才会真正被暂停运行。
- p的运行队列里面有等待运行的goroutine。
这用来保证当前p的本地运行队列中的goroutine得到及时的调度,因为该p对应的工作线程正处于系统调用之中,无法调度队列中goroutine,所以需要寻找另外一个工作线程来接管这个p从而达到调度这些goroutine的目的; - 没有空闲的p。
表示其它所有的p都已经与工作线程绑定且正忙于执行go代码,这说明系统比较繁忙,所以需要抢占当前正处于系统调用之中而实际上系统调用并不需要的这个p并把它分配给其它工作线程去调度其它goroutine。 - 从上一次监控线程观察到p对应的m处于系统调用之中到现在已经超过10了毫秒。
这表示只要系统调用超时,就对其抢占,而不管是否真的有goroutine需要调度,这样保证sysmon线程不至于觉得无事可做(sysmon线程会判断retake函数的返回值,如果为0,表示retake并未做任何抢占,所以会觉得没啥事情做)而休眠太长时间最终会降低sysmon监控的实时性。至于如何计算某一次系统调用时长可以参考上面代码及注释。
参考资料
https://github.com/zboya/golang_runtime_reading
http://mp.weixin.qq.com/mp/homepage?__biz=MzU1OTg5NDkzOA==&hid=1&sn=8fc2b63f53559bc0cee292ce629c4788&scene=18#wechat_redirect
https://mp.weixin.qq.com/s/SEPP56sr16bep4C_S0TLgA
https://www.bilibili.com/video/BV19r4y1w7Nx?from=search&seid=14477206065715896522
最后
以上就是清新楼房最近收集整理的关于Golang深入理解GPM模型的全部内容,更多相关Golang深入理解GPM模型内容请搜索靠谱客的其他文章。








发表评论 取消回复