
3.4.4 性能分析
我们使用上面的两种方法采集到运行的golang程序的性能数据样本后,下面就可以用我们第一步,安装的pprof工具来查看性能数据了, pprof可视化分析工具,主要是对样本数据文件进行解析,提供解析后的性能数据给我查看。
现在我们通过一个实例来详细的介绍一下性能分析的过程。 通过pprof的来查看笔者的一款基于fasthttp服务的性能数据
由于是一个非http底层的服务,fasthttp本身有兼容pprof的实现方式,但是笔者简单的还是通过另其一个单独的http服务来实现;仅仅只是为了演示而已;在真实的场景里,还是应该在成本可控的范围内,仅可能不要过多的启用冗余的底层服务和端口,
解释
对于云原生或者容器开发而言,多一个底层服务可能就需要至少publish出一个服务端口,这对于云原生或者容器开发而言,都是不必要的资源浪费,而且还带来了维护和管理上的不必要的管理内容
Pprof代码,简单的引入包和启动默认Mux
import _ "net/http/pprof"go http.ListenAndServe("0.0.0.0:8889", nil)查看pprof的性能数据
http://localhost:8999/debug/pprof/
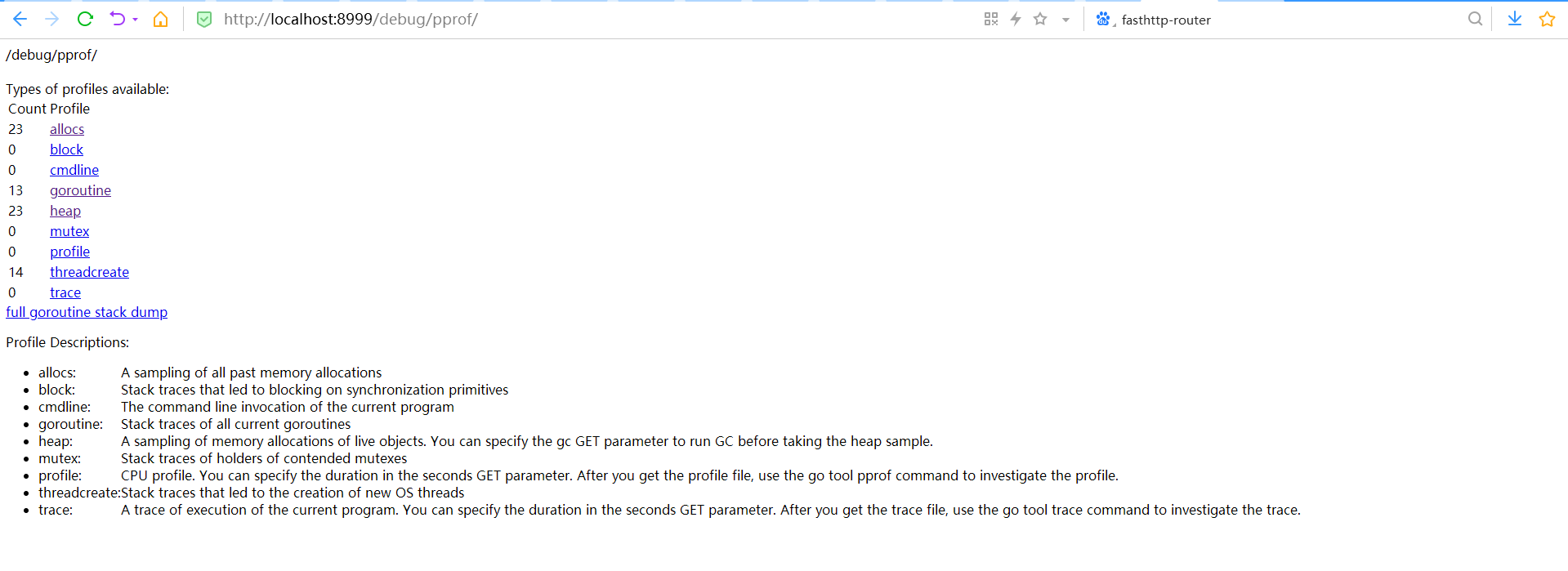
在PProf的性能采样报告里,包含以下方面的数据样本提供pprof工具进行可视化分析
profile CPU占用情况的采样信息 allocs 内存分配情况的采样信息 blocks 阻塞操作情况的采样信息 cmdline 显示程序启动命令及参数 goroutine 当前所有协程的堆栈信息 heap 堆上内存使用情况的采样信息 mutex 锁争用情况的采样信息 threadcreate 系统线程创建情况的采样信息 trace 程序运行跟踪信息
提示
这里演示的是后台服务类型的程序,通过http的方式提供性能数据样本来源, 如果是Run over once运行程序, 可以将样本数据通过pprof提供的API保存到文件里,然后通过pprof工具进行可视化查看和分析
使用go tool pprof分析数据命令: go tool pprof pprof_file|pprof_url 进入命令行交互模式后,可以使用help查看所有子命令,使用help <cmd|option>查看子命令使用方法。
Duration: 30s, Total samples = 20ms (0.067%) Entering interactive mode (type "help" for commands, "o" for options) (pprof) help Commands: callgrind Outputs a graph in callgrind format comments Output all profile comments disasm Output assembly listings annotated with samples dot Outputs a graph in DOT format eog Visualize graph through eog evince Visualize graph through evince gif Outputs a graph image in GIF format gv Visualize graph through gv kcachegrind Visualize report in KCachegrind list Output annotated source for functions matching regexp pdf Outputs a graph in PDF format
CPU Profiling
运行命令
go tool pprof http://localhost:8999/debug/pprof/profile
采样持续时间30s, 使用top命令,查看最耗时的地方
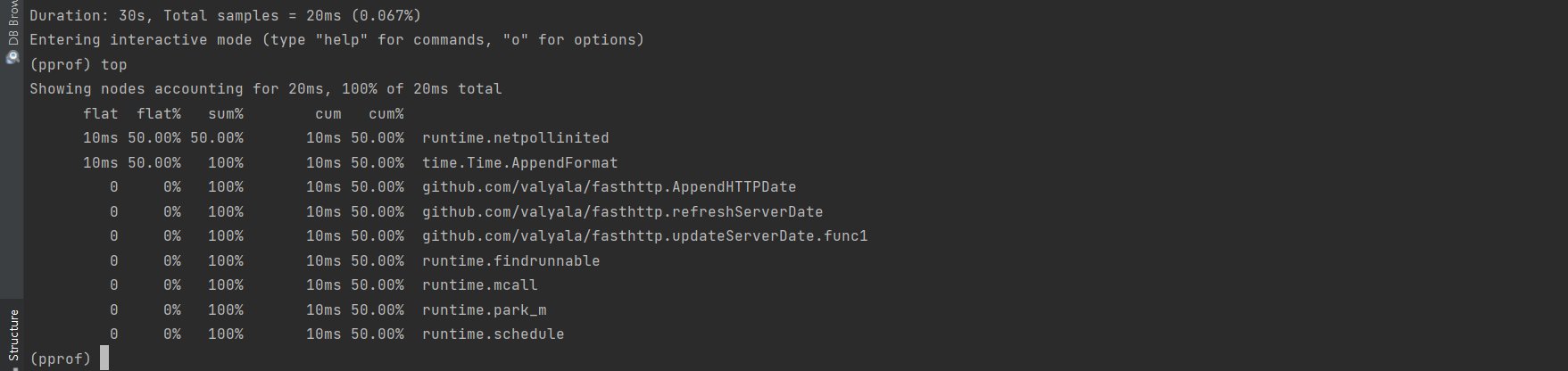
Top命令的结果,列表出了在采样的持续时间30s内,发生的程序中各种函数调用过程中最耗时的前n条信息;
其中每一行都表示一个采用到的函数调用,
每类都对应着采集到的数据分析; 列的参照如下
flat:函数在 CPU 上运行的时间
flat%:函数在CPU上运行时间的百分比
sum%:所有函数累加使用 CPU 的比例,即所有flat%的总和
cum: 函数以及子函数运行所占用的时间,应该大于等于flat
cum%: 函数以及子函数运行所占用的比例,应该大于等于flat%
函数的名字
通过上面的报告,我们可以看到,在采样的30s的时间内, 程序基本上没有发生调用。 而且根据所有相关程序调用的信息,这两个10ms耗时的调用,还是和pprof采样有关的,不过对性能的开销基本上可以忽略不计(10ms/30s);
结合着压力工具,对服务进行加压, 这时候就可以看到加压过程中的各种耗时函数调用的情况了, 在笔者演示的这个项目里,在前台有个定时刷新的任务,打开这个任务没5s刷新; 同时采样的持续时间改成60s, 然后查看采样数据的变化
采用持续时间改成60s
E:WORKPROJECTgitgogolang-sampleDemo> go tool pprof http://localhost:8999/debug/pprof/profile?seconds=60

查看前20条耗时最长的调用
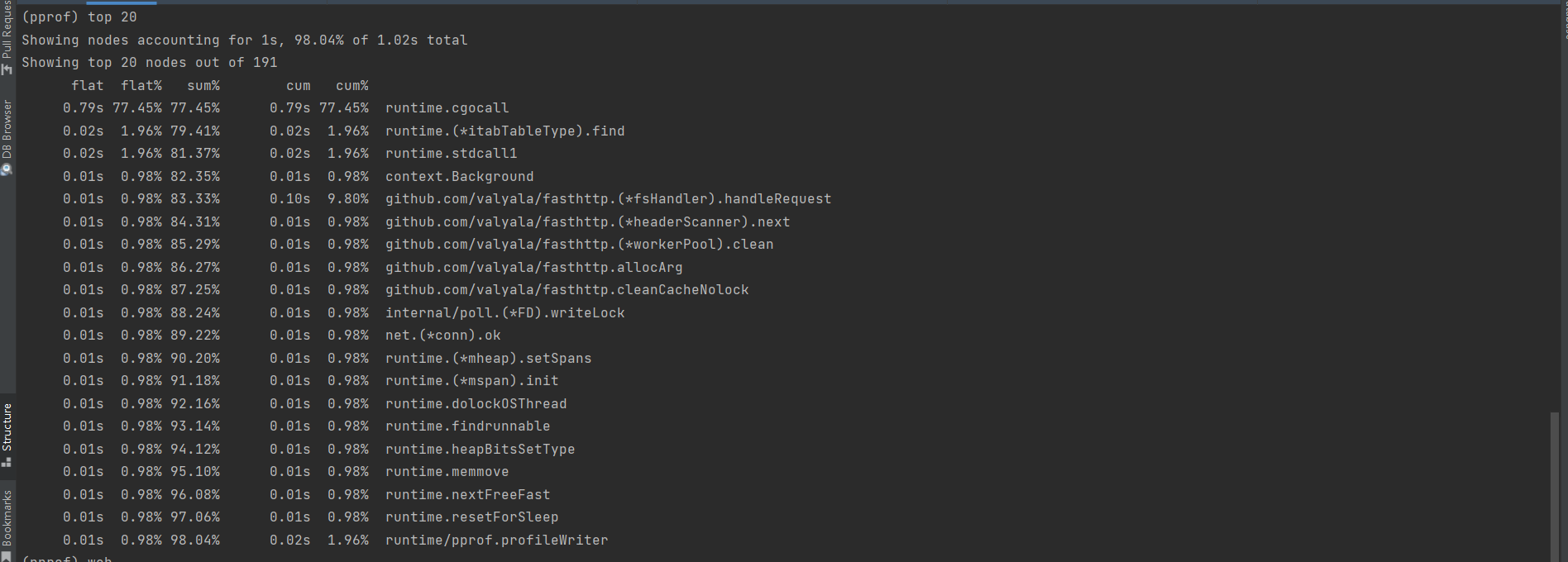
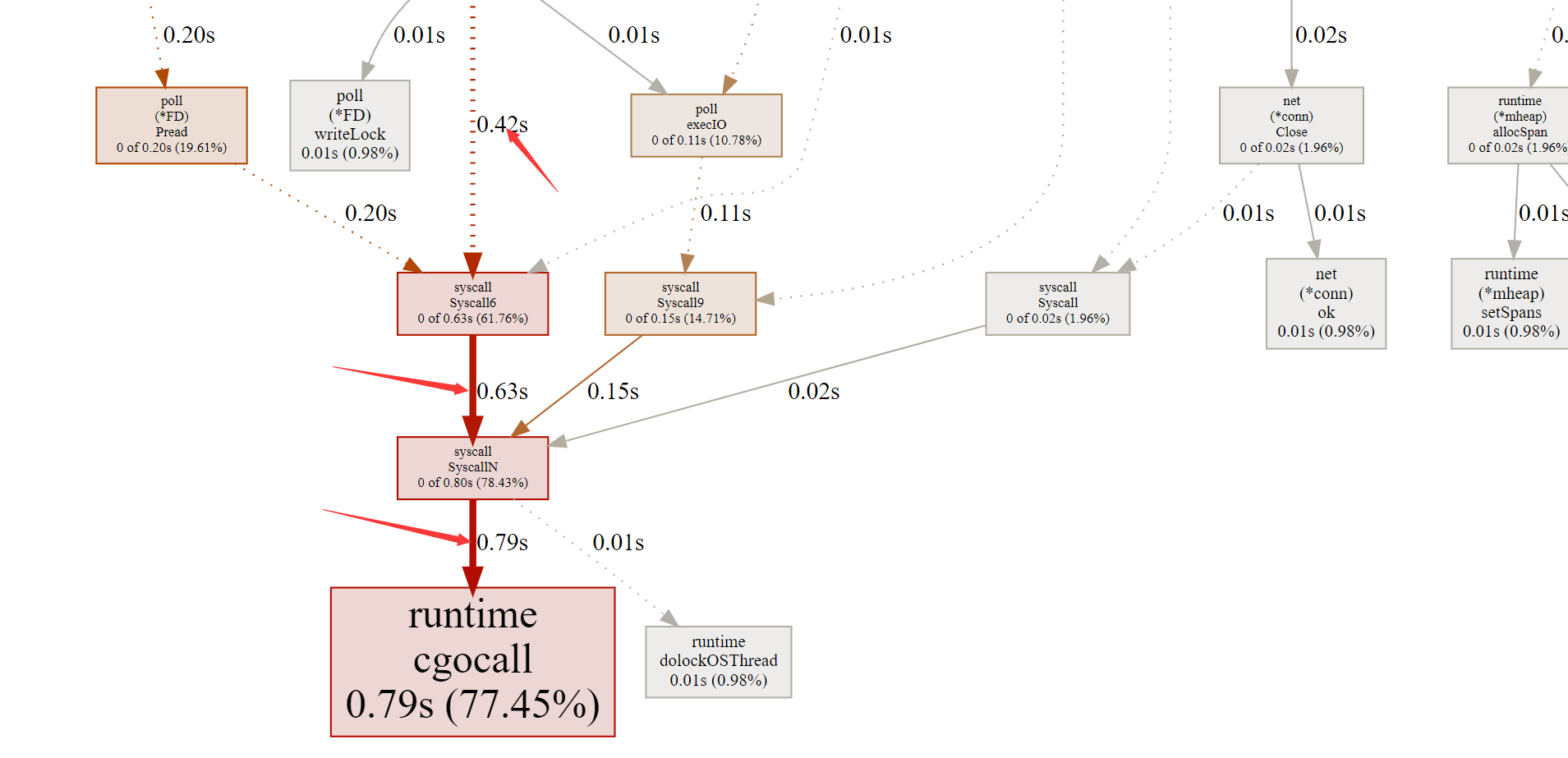
这里可以看到调用现在最长的耗时0.79s,runtime.cgocall, 然后就可以通过提供的这些函数名来对自己的程序进行分析和研判了
使用子命令:list 函数名。 可以用pprof分析函数中的哪一行导致的耗时
(pprof) list runtime.cgocall
Total: 1.02s
ROUTINE ======================== runtime.cgocall in E:WORKSOFTgo1.18.windows-amd64gosrcruntimecgocall.go
790ms 790ms (flat, cum) 77.45% of Total
. . 152: //
. . 153: // fn may call back into Go code, in which case we'll exit the
. . 154: // "system call", run the Go code (which may grow the stack),
. . 155: // and then re-enter the "system call" reusing the PC and SP
. . 156: // saved by entersyscall here.
790ms 790ms 157: entersyscall()
. . 158:
. . 159: // Tell asynchronous preemption that we're entering external
. . 160: // code. We do this after entersyscall because this may block
. . 161: // and cause an async preemption to fail, but at this point a
. . 162: // sync preemption will succeed (though this is not a matter通过这个命令,可以直接追击到源代码的行数,从而进行仔细的调用过程分析
这里我们根据分析看到的,打开cgocall.go源文件,一探究竟
技巧
在Idea里,使用快捷键 Ctrl + Shift + R ; 然后在搜索框里,输入 cgocall.go,就可以快速的定位到cgocall.go文件
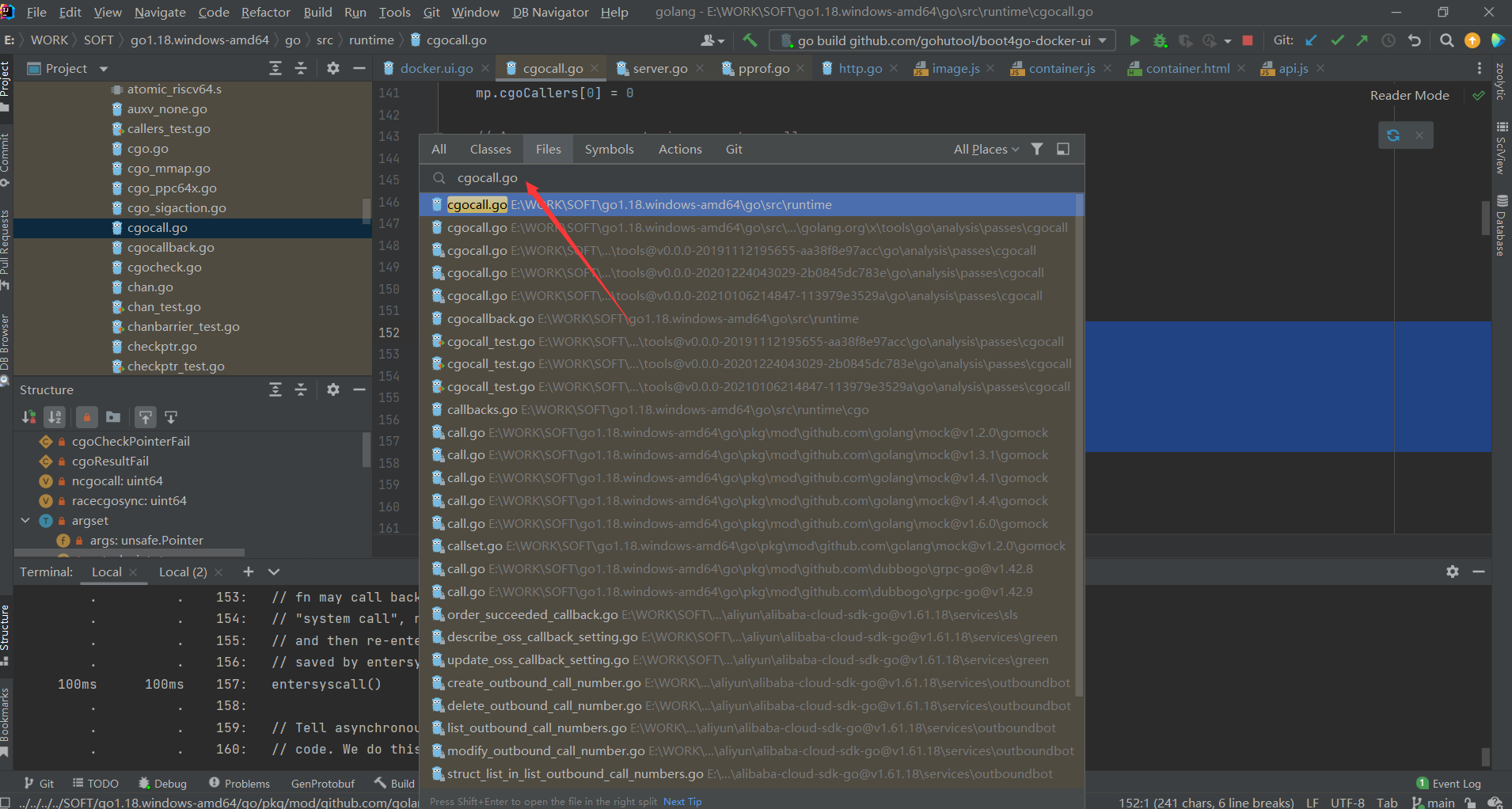
//
// fn may call back into Go code, in which case we'll exit the
// "system call", run the Go code (which may grow the stack),
// and then re-enter the "system call" reusing the PC and SP
// saved by entersyscall here.
entersyscall()
至这个地方,可以看到的是go底层的syscall的系统调用; 虽然现在的问题耗时点最长的是他,但是目前的调用他并不算太多,采样时长是60s, 目前他的耗时是0.79s(790ms 77.45); 我们还是继续看看是否是我们的主要业务代码导致的;
Graphviz图形化,查看调用关系
如果安装了graphviz工具, 还可以通过图形化的方式, 来查看每个函数的调用关系图, 在pprof的交互模式里输入web命令
(pprof) help web
Visualize graph through web browser
Usage:
web [n] [focus_regex]* [-ignore_regex]*
Include up to n samples
Include samples matching focus_regex, and exclude ignore_regex.执行命令后,pprof会根据样本数据产生一个svg的图像文件,并自动启动浏览器打开该文件,显示出各个函数的调用关系
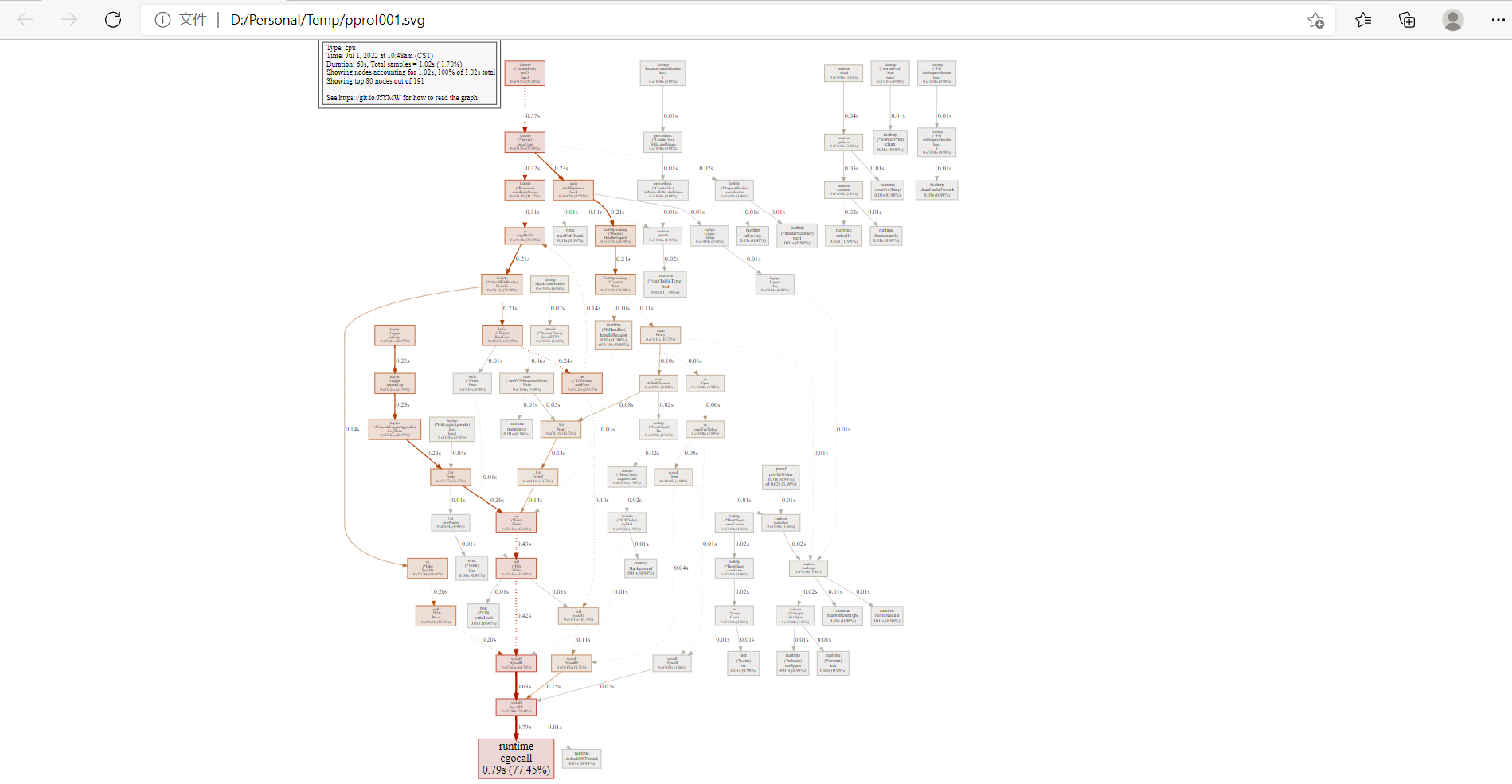
每个方形格子就是一个函数调用, 格子越大,耗时就越长,可以放大图片,看到每个格子的具体的调用数据
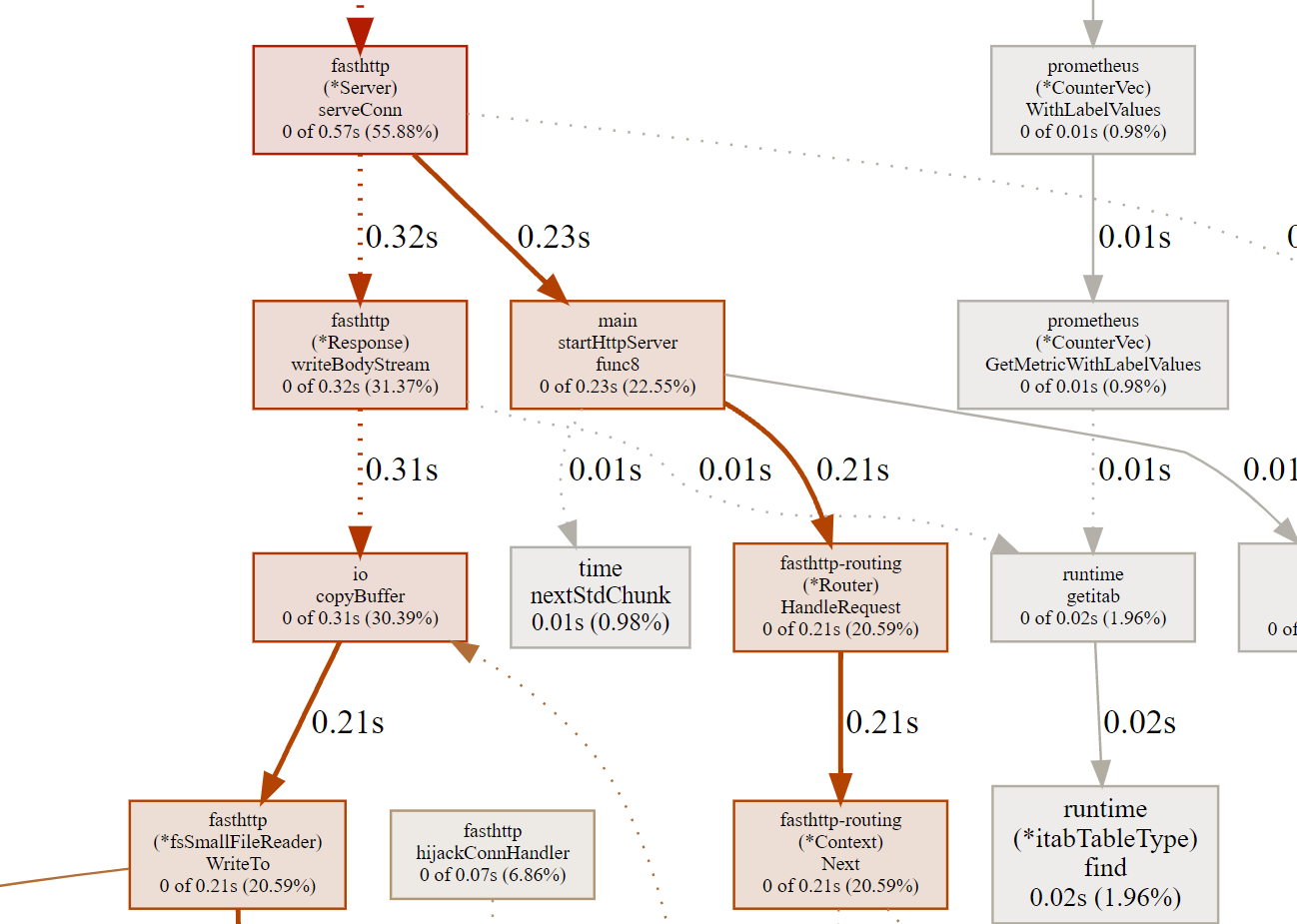
查看runtime.cgocall的调用链, 可以看到耗时最长的这个调用链,是0.42s,如下图
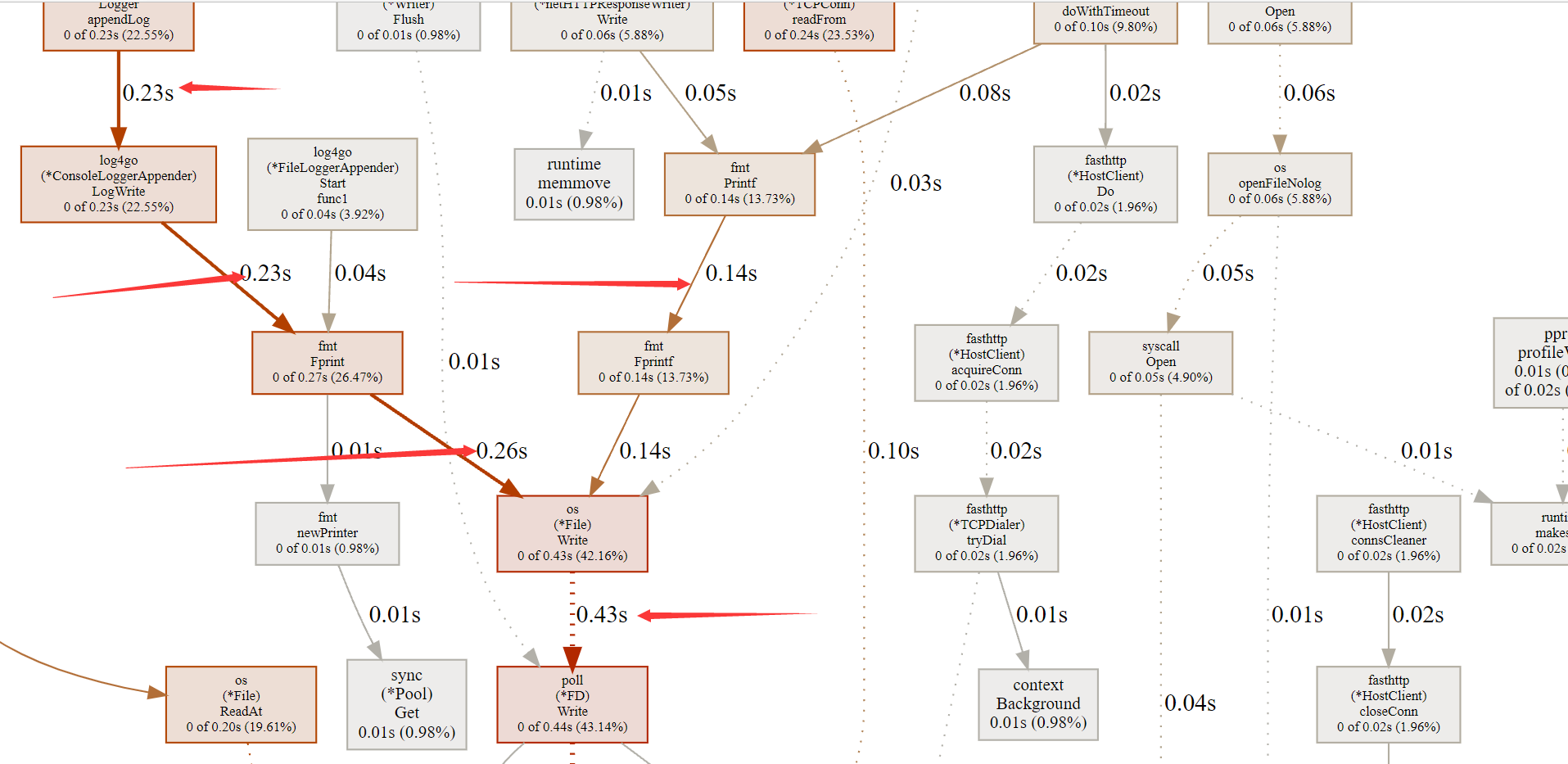
继续往这条链上溯源下去,发现0.43的主要分支0.26S,0.14S, 0.03S, 可以分别在图里找到其调用的起源,
- 0.26s的调用来源于Log4go的日志功能,在图中可以看到log4go在这里分别有两中调用,一种来自于ConsoleLoggerAppender,其直接使用fmt进行打印控制操作,这个调用链可以看到fmt的性能真的是不好,所有的耗时0.23全部在这个函数里面, 在log4go里考虑到fmt糟糕的性能,都是使用的异步输出,所有这里我们看到的耗时是0.23,但是程序的表现上,是异步的,还是没有太多的视觉上的差异, log4go这里还有另一个FileLoggerAppender,日志输出至文件的,整个调用链耗时0.04s, 比fm优秀太多
- 0.14s的调用来源,也全部都是fmt调用链占用的, 调用来源于两处, 0.08s和0.05s, 并不是差了0.01s,是报告显示的时候,使用了2位小数的四舍五入,所以有这个差异
- 0.03的调用来源,图中没有展示全, 来之于业务底层框架上的调用,这个可以进一步追击下去了,和业务相关,今天笔者就不在这里进行深入下去了。
如果没有安装好graphviz工具,而不能使用web命令打开如上面这样的图形页面时; 可以使用pprof的tree命令; tree命令,也可以查看到整个调用过程中函数的调用关系的结构图,只是没有graphviz这么直观而已
(pprof) tree
Showing nodes accounting for 160ms, 100% of 160ms total
----------------------------------------------------------+-------------
flat flat% sum% cum cum% calls calls% + context
----------------------------------------------------------+-------------
100ms 100% | syscall.SyscallN
100ms 62.50% 62.50% 100ms 62.50% | runtime.cgocall
----------------------------------------------------------+-------------
10ms 100% | github.com/valyala/fasthttp.(*RequestHeader).parseHeaders
10ms 6.25% 68.75% 10ms 6.25% | bytes.IndexByte
----------------------------------------------------------+-------------
10ms 100% | github.com/valyala/fasthttp.(*RequestHeader).parseHeaders
10ms 6.25% 75.00% 10ms 6.25% | github.com/valyala/fasthttp.caseInsensitiveCompare
----------------------------------------------------------+-------------
10ms 100% | runtime.mallocgc
10ms 6.25% 81.25% 10ms 6.25% | runtime.memclrNoHeapPointers
----------------------------------------------------------+-------------
10ms 100% | time.Time.AppendFormat
10ms 6.25% 87.50% 10ms 6.25% | runtime.memmove
----------------------------------------------------------+-------------
20ms 100% | runtime.resettimer
10ms 6.25% 93.75% 20ms 12.50% | runtime.modtimer
10ms 50.00% | runtime.wakeNetPoller
----------------------------------------------------------+-------------
10ms 100% | runtime.semawakeup
10ms 6.25% 100% 10ms 6.25% | runtime.stdcall1
----------------------------------------------------------+-------------
40ms 100% | github.com/gohutool/log4go.(*FileLoggerAppender).Start.func1
0 0% 100% 40ms 25.00% | fmt.Fprint
40ms 100% | os.(*File).Write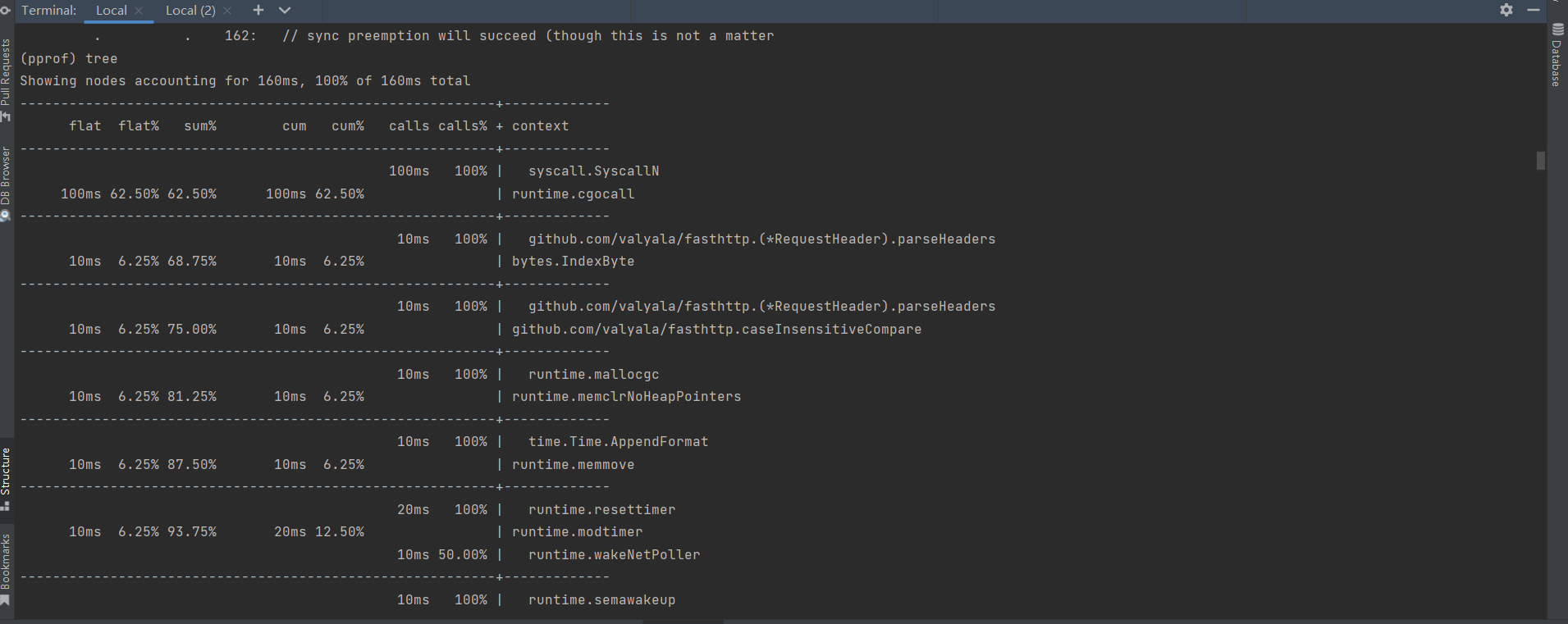
技巧
top n 返回前n条信息
采样的持续时间,可以在执行go tool pprof url地址后面加上查询参数 ?seconds=n, 例如 go tool pprof http://localhost:8999/debug/pprof/profile?seconds=10

最后
以上就是虚幻手套最近收集整理的关于爱上开源之golang入门至实战第三章-性能分析-分析数据3.4.4 性能分析CPU Profiling的全部内容,更多相关爱上开源之golang入门至实战第三章-性能分析-分析数据3.4.4内容请搜索靠谱客的其他文章。








发表评论 取消回复