txt文档转dataframe写入excel
文本格式:市名-区名-街道名

# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
df = pd.read_table('no_street.txt')
list=[]
for i in df.values:
print(i[0])
li = i[0].split("-")
# print(li)
list.append(li)
data = pd.DataFrame(list)
data.to_excel('street.xls')
对excel进行分组统计
street_areas市区重新写入excel
tj_street_areas统计区域和街道个数
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
df = pd.read_excel('street.xls')
print(df.head())
print(df.groupby(0).groups)
print(df.loc[74])
for i in df.groupby(0).groups:
# print(i)
pass
listm = []
li = []
for name, group in df.groupby(0):
# print(name) # 市名称
# print(group)
column = ['rowid','city','area','street']
group.columns=column
# print(group.values)
cnum = group['area'].nunique()
snum = group['street'].nunique()
print(name)
# print(group['area'])
for s in group.values:
print(s)
li.append(s)
print("区域:")
print(group.drop_duplicates(['area'])['area'].values)
print("街道:")
print(group.drop_duplicates(['street'])['street'].values)
# print(cnum)
# print(snum)
streets = str(group.drop_duplicates(['street'])['street'].values)
# s = "市:{}-有{}区-新增街道数:{}个".format(name,cnum,snum)
areas = str(group.drop_duplicates(['area'])['area'].values)
s = [name, cnum, snum, areas, streets]
listm.append(s)
# print(df.groupby(0).get_group('三亚'))#选择某一组数据
# print(df.groupby(0).get_group('三亚')[1].nunique())
# f = open('1.txt', 'w',encoding='utf8')
# f.write(str(listm))
# f.close()
# data = pd.DataFrame(listm)
# data.to_excel('tj_street_areas.xls')
data = pd.DataFrame(li)
data.to_excel('street_areas.xls')
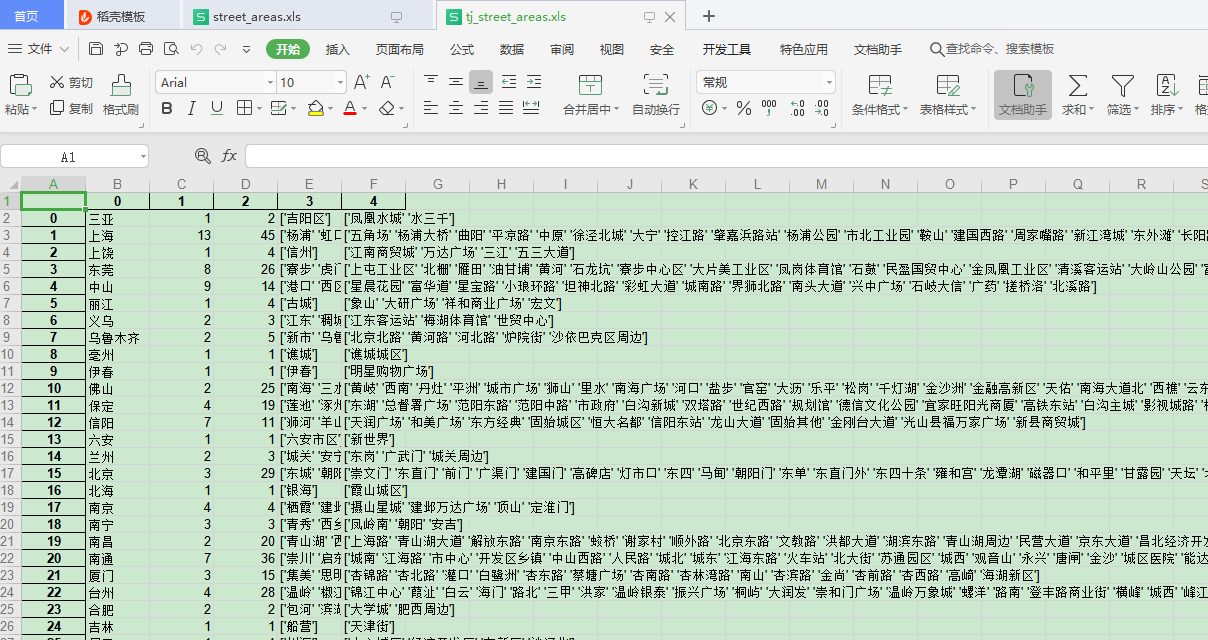
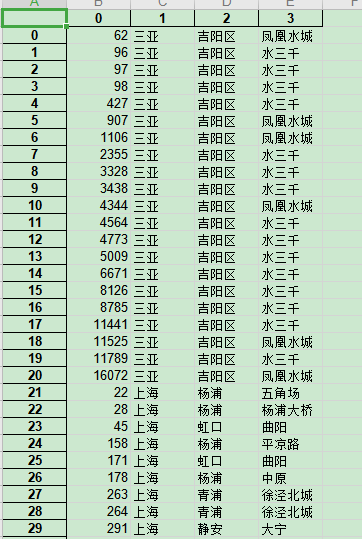
最后
以上就是无心热狗最近收集整理的关于python对TXT文本数据分组统计的全部内容,更多相关python对TXT文本数据分组统计内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复