一、什么是IDF文本语料库
在jieba的TF-IDF模型里面,当调用获取关键词的函数
jieba.analyse.extract_tags()
的时候,该函数会调用默认的IDF语料库。IDF语料库就是jieba官方在大量文本的基础上,通过
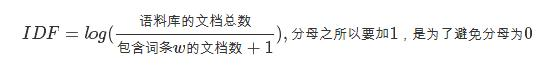
计算得到的一个idf字典,其key为分词之后的每个词,其value为 每个词的IDF数值。
二、计算自定义的IDF文本语料库
程序流程如下:
1、读取文本文件,分词,去停用词,得到all_dict 字典,字典的键是word,字典的值是包含word 的文档的个数。
# 获取每个目录下所有的文件
for mydir in catelist:
class_path = corpus_path+mydir+"/" # 拼出分类子目录的路径
#print(class_path)
seg_dir = seg_path+mydir+"/" # 拼出分词后语料分类目录
if not os.path.exists(seg_dir): # 是否存在目录,如果没有创建
os.makedirs(seg_dir)
#print(seg_dir)
file_list = os.listdir(class_path) # 获取class_path下的所有文件
for file_path in file_list: # 遍历类别目录下文件
fullname = class_path + file_path # 拼出文件名全路径
#print(fullname)
content = readfile(fullname).strip() # 读取文件内容
content = content.replace("rn".encode(encoding="utf-8"),"".encode(encoding="utf-8")) # 删除换行和多余的空格
content = content.replace(" ".encode(encoding="utf-8"),"".encode(encoding="utf-8"))
content_seg = jieba.cut(content.strip()) # 为文件内容分词
stopwords = stopwordslist('./stopwords1.txt')
outstr = []
for word in content_seg:
if word not in stopwords:
if word != 't' and word != 'n':
#outstr.append(word)
outstr.append(word)
for word in outstr:
if ' ' in outstr:
outstr.remove(' ')
temp_dict = {}
total += 1
for word in outstr:
#print(word)
temp_dict[word] = 1
# print(temp_dict)
for key in temp_dict:
num = all_dict.get(key, 0)
all_dict[key] = num + 1
#savefile(seg_dir+file_path,"".join(outstr)) # 将处理后的文件保存到分词后语料目录2、计算IDF值并保存到txt中 idf_dict 字典的键是word ,值是对应的IDF数值。
# idf_dict字典就是生成的IDF语料库
idf_dict = {}
for key in all_dict:
# print(all_dict[key])
w = key
p = '%.10f' % (math.log10(total/(all_dict[key]+1)))
if w > u'u4e00' and w<=u'u9fa5':
idf_dict[w] = p
print('IDF字典构造结束')
fw = open('wdic.txt', 'w',encoding='utf-8')
for k in idf_dict:
if k != 'n':
print(k)
fw.write(k + ' ' + idf_dict[k] + 'n')
fw.close()三、程序中的一些问题记录
1、readfile函数的返回值是文本内容对应的字符串。replace()函数内要使用'utf-8'编码。
content = readfile(fullname).strip() # 读取文件内容
content = content.replace("rn".encode(encoding="utf-8"),"".encode(encoding="utf-8")) # 删除换行和多余的空格2、停用词stopwords 是读取停用词文本之后转换生成的列表。通过for循环和if 判断,去掉停用词,生成outstr 最终的分词列表。
for word in content_seg:
if word not in stopwords:
if word != 't' and word != 'n':
#outstr.append(word)
outstr.append(word)3、word-idf 字典建立。 这里的key 和p都是字符串。通过if判断语句,保证字典的key 都是汉字。
idf_dict = {}
for key in all_dict:
# print('ok')
# print(all_dict[key])
w = key
p = '%.10f' % (math.log10(total/(all_dict[key]+1)))
if w > u'u4e00' and w<=u'u9fa5':
idf_dict[w] = p
#print(idf_dict)
#del idf_dict['']
#del idf_dict[' ']
print('IDF字典构造结束')4、保存为txt,这里必须要‘utf-8’编码,不然jieba不识别。 fw.wirte()一行行把字典写入txt。
fw = open('wdic.txt', 'w',encoding='utf-8')
for k in idf_dict:
if k != 'n':
print(k)
fw.write(k + ' ' + idf_dict[k] + 'n')
fw.close()四、jieba中替换为自定义的IDF语料库
jieba.analyse.set_idf_path(idf_file_name)
keywords = jieba.analyse.extract_tags(sentence, topK=20, withWeight=True, allowPOS=('n', 'nr', 'ns'))
最后
以上就是震动电话最近收集整理的关于如何生成自定义的逆向文件频率(IDF)文本语料库(二)的全部内容,更多相关如何生成自定义内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复