【学习笔记】Pytorch深度学习-网络层之池化层、线性层、激活函数层
- 池化层(Pooling Layer)
- 线性层(Linear Layer)
- 激活函数层( Activation Layer)
池化层(Pooling Layer)
池化定义
池化运算是对信号进行“收集”并“总结”。由于池化操作类似蓄水池收集水资源,因此得名池化。
(1)收集
通过池化运算将信号由多变少,图像尺寸由大变小的过程;
(2)总结
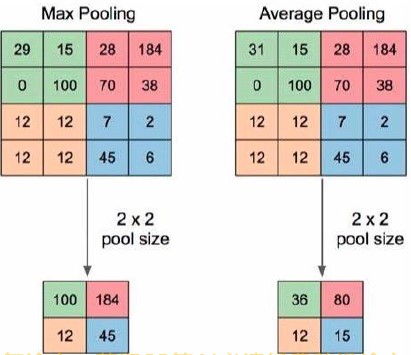
如图1中左图所示,1张
4
×
4
4 times 4
4×4 的输入图像经过
2
×
2
2 times 2
2×2 的池化窗口池化运算后,得到
2
×
2
2 times 2
2×2 的输出特征图。原本具有16个像素的图像变为4个像素进行表示,1个池化窗口内部用1个像素值来表示原本的4个像素值,这一过程就是总结。
在总结方法中,最常用的2种方法是最大值池化、平均值池化,如图1所示。
Pytorch中池化实现
1、二维最大值池化
1.1 理论
nn.MaxPool2d(kernel_size,stride=None,
padding=0,dilation=1,
return_indices=False,
ceil_mode=False)
功能:对二维信号(图像)进行最大值池化
主要参数:kernel_size:池化核尺寸
stride:步长
padding:填充个数
dilation:池化核间隔大小
ceil_mode:尺寸向上取整(Ture:向上;False:默认,向下)
return_indices:记录池化像素索引
解释:
(1)ceil_mode: 池化后,在计算输出特征图尺寸时,存在1个除法操作。如果除法不能整除时,可通过对ceil_mode进行设置选择尺寸向上或向下取整;设置ceil_mode=True时,输出特征图尺寸采用向上取整;ceil_mode=False时,此为默认设置,输出特征图尺寸采用向下取整。
卷积、池化输出特征图尺寸简化版公式:
I
n
s
i
z
e
−
k
e
r
n
e
l
s
i
z
e
+
2
p
a
d
d
i
n
g
s
t
r
i
d
e
+
1
=
o
u
t
s
i
z
e
.
frac{Insize-kernelsize+2padding}{stride}+1= outsize,.
strideInsize−kernelsize+2padding+1=outsize.
(2)return_indices: 记录下来的像素索引,通常会用于最大值反池化操作。早期自编码器、图像分割任务通常会利用最大值反池化来进行上采样, return_indices在反池化中则起着至关重要的作用。
举个例子:
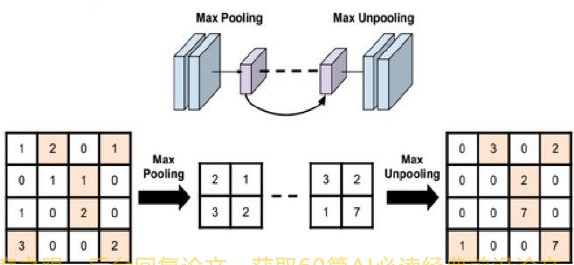
从图2、3的网络结构可以看出,红色线划分的前段是1个 正常的最大值池化下采样过程: 从
4
×
4
4 times 4
4×4 输入图像池化得到
2
×
2
2times 2
2×2的特征图,对于第1个池化窗口首先记录下最大像素值2的位置索引。该最大像素值经过中间一系列网络层运算后,变为了3而后进入反池化上采样环节,通过return_indices记录的2的索引值把3放到
4
×
4
4 times 4
4×4 图像中,完成反池化。
总而言之,记录最大值池化时像素点的索引值,反池化时,可通过该索引值将运算得来的新最大值放到相应的的位置。
1.2 实验
代码来自余老师
# ================ maxpool
# flag = 1
flag = 0
if flag:
//参数设置:
// kernel_size—2×2池化核、
// 步长—池化通常不重叠,步长与池化核参数相同;
// 其他均为默认设置
maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2)) # input:(i, o, size) weights:(o, i , h, w)
img_pool = maxpool_layer(img_tensor)
2、二维平均值池化
2.1 理论
nn.AvgPool2d(kernel_size, stride=None
padding=0,ceil_mode=False,
count_include_pad=True,
divisor_override=None)
功能:对二维信号(图像)进行平均值池化
主要参数:kernel_size:池化核尺寸
stride:步长
padding:填充个数
ceil_mode:尺寸向上取整
count_include_pad:填充值用于计算(True-用于计算,False-不用于计算)
divisor_override:除法因子
解释:
divisor_override除法因子:在进行平均值池化时,计算方法是:
池
化
窗
所
覆
盖
像
素
点
像
素
值
之
和
被
覆
盖
的
像
素
点
个
数
=
当
前
窗
口
平
均
值
.
frac{池化窗所覆盖像素点像素值之和}{被覆盖的像素点个数}= 当前窗口平均值,.
被覆盖的像素点个数池化窗所覆盖像素点像素值之和=当前窗口平均值.
有了除法因子,就不再除以 被覆盖的像素点个数,而是可以通过任意赋值(见实验2.2)。
2.2 实验
代码来自余老师
#==================AvgPool
flag = 1
# flag = 0
if flag:
img_tensor = torch.ones((1, 1, 4, 4)) //创建张量
avgpool_layer = nn.AvgPool2d((2, 2), stride=(2, 2), divisor_override=3) //设置平均值池化中除法因子为3
img_pool = avgpool_layer(img_tensor)
print("raw_img:n{}npooling_img:n{}".format(img_tensor, img_pool))
实验意味着,原本
4
×
4
4 times 4
4×4的输入图像经过池化下采样得到
2
×
2
2times 2
2×2的特征图。1个
2
×
2
2times 2
2×2池化窗口内,像素值计算变为:
像
素
值
之
和
:
1
+
1
+
1
+
1
除
法
因
子
3
=
当
前
窗
口
平
均
值
1.3333...
.
frac{像素值之和:1+1+1+1}{除法因子3}= 当前窗口平均值1.3333...,.
除法因子3像素值之和:1+1+1+1=当前窗口平均值1.3333....

3、二维最大值反池化
3.1、理论
nn.MaxUnpool2d(kernel_size,stride=None,
padding=0)
功能:对二维信号(图像)进行最大值反池化(池化上采样)
主要参数:kernel_size:池化核尺寸
stride:步长
padding:填充个数
forward(self,input,indices,output_size=None)
解释:
后段进入【反池化层】,从
2
×
2
2times 2
2×2输入图像上采样到
4
×
4
4times 4
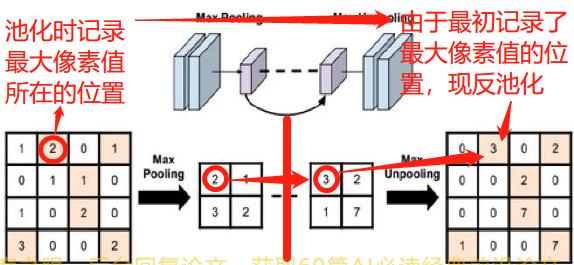
4×4输出特征图,涉及到像素点放在哪里的问题。这一步就可依靠【最大值池化层】中的return_indices来记录索引,【最大值池化层】中最大像素值的索引传入到【反池化层】中,如反池化层中红色标注的各个像素点,将当前
2
×
2
2times 2
2×2输入图像中的像素点放在对应的位置上。因此,【最大反池化】参数与【最大值池化】参数类似,只是在forward时需要多传入indices索引参数。
3.2、实验
# ================ max unpool
flag = 1
# flag = 0
if flag:
# pooling【最大值池化】
img_tensor = torch.randint(high=5, size=(1, 1, 4, 4), dtype=torch.float) //随机初始化1个尺寸为4*4的图像
maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2), return_indices=True) //设置最大值池化参数,记录索引
img_pool, indices = maxpool_layer(img_tensor)
# unpooling【最大值反池化】
img_reconstruct = torch.randn_like(img_pool, dtype=torch.float)
//这一步形如图5中第3层,其参数应与第二层输出特征图一样,
//因此用randn_like(img_pool)进行初始化
maxunpool_layer = nn.MaxUnpool2d((2, 2), stride=(2, 2))
img_unpool = maxunpool_layer(img_reconstruct, indices)
print("raw_img:n{}nimg_pool:n{}".format(img_tensor, img_pool))
print("img_reconstruct:n{}nimg_unpool:n{}".format(img_reconstruct, img_unpool))
结果:


线性层(Linear Layer)
线性层定义
线性层又称为全连接层,其每个神经元与上一层所有神经元相连,实现对前一层的线性组合,线性变换。
线性层功能
在卷积神经网络进行分类时,输出分类结果前,通常采用全连接层对特征进行处理。Pytorch中全连接层又称为Linear线性层,因为如果不考虑激活函数的非线性性质,那么全连接层就是对输入数据进行线性组合,因此而得名"线性层"。
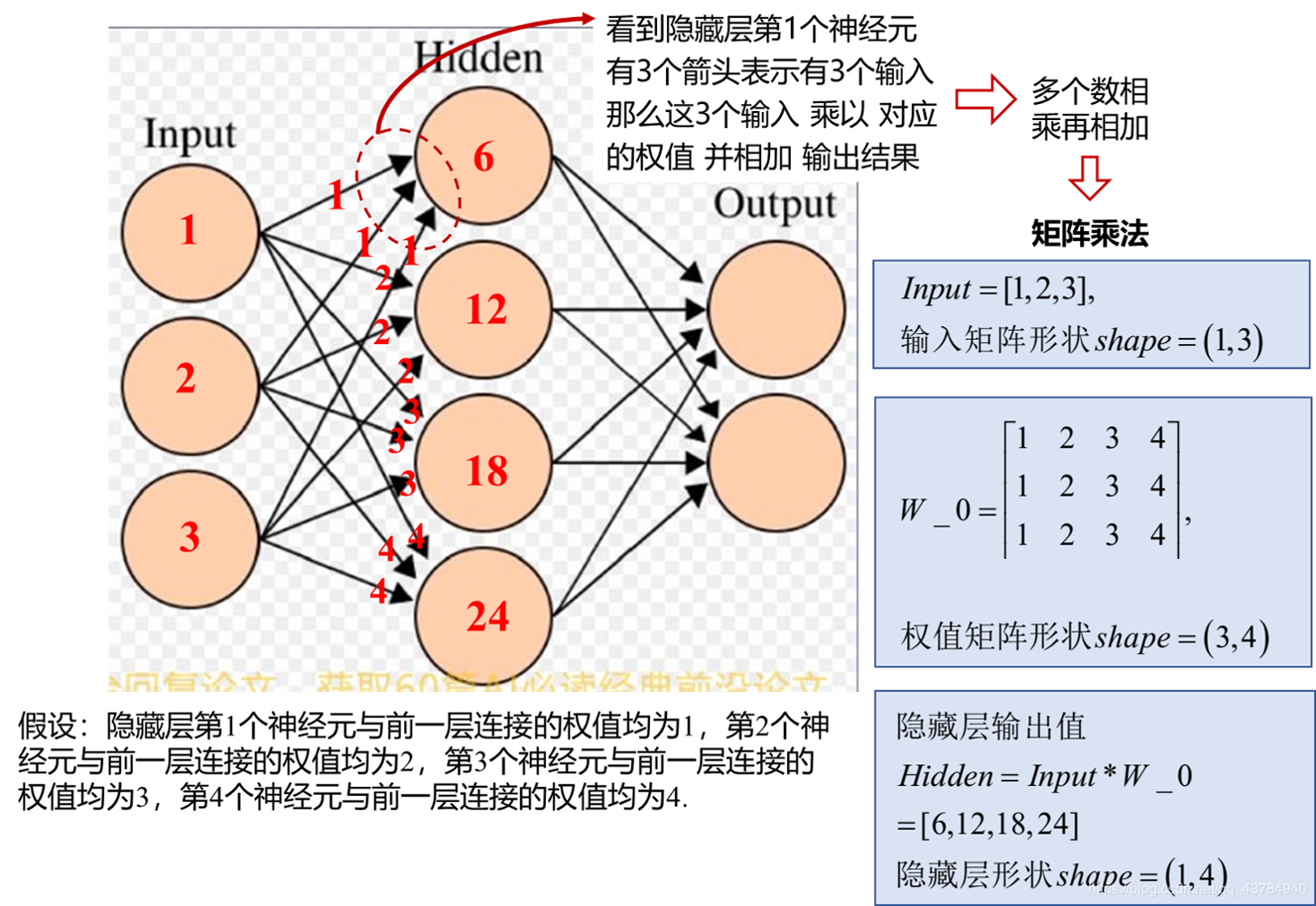
以图8为例,观察2层全连接网络:
(1)连接方式:每个神经元与上一层所有神经元相连
(2)运算方式:每个神经元的输出结果是对上一层输入值的加权求和,即采用前一层的输入乘以权值、相加然后输出。
例如,图8中看到隐藏层第1个神经元有3个箭头指向它,说明有3个输入。这3个输入 乘以对应权值并求和得到该神经元的输出结果:
1
×
1
+
2
×
1
+
3
×
1
=
6
1times 1 +2 times 1+3 times 1= 6,
1×1+2×1+3×1=6
以此类推,通过矩阵乘法得到隐藏层的全部输出值。
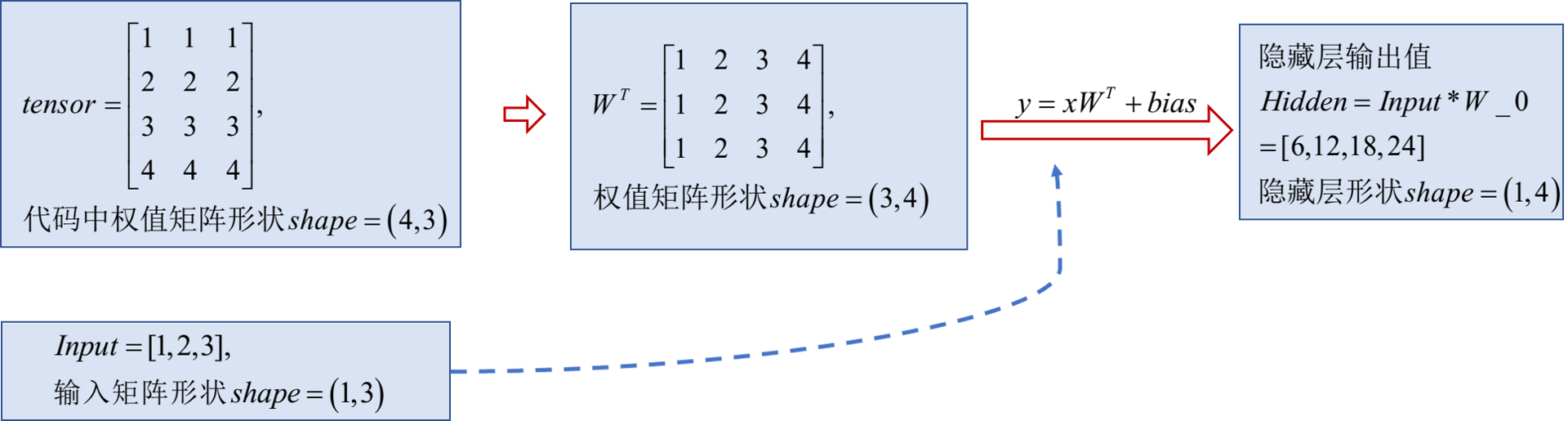
Pytorch中线性层实现-nn.Linear
nn.Linear(in_features,out_features,bias=True)
功能:对一维信号(向量)进行线性组合
主要参数:in_features:输入结点数
out_features:输出结点数
bias:是否需要偏置
nn.Linear计算公式
y
=
X
W
T
+
b
i
a
s
y=Xmathbf{W}^mathrm{T}+bias
y=XWT+bias
注意:由于计算过程中,会自动将权值矩阵
W
W
W进行转置
W
T
mathbf{W}^mathrm{T}
WT,因此输入的权值矩阵应当注意形状和数值(见实验)
nn.Linear实验
# ================ linear
# flag = 1
flag = 0
if flag:
inputs = torch.tensor([[1., 2, 3]])
linear_layer = nn.Linear(3, 4)
linear_layer.weight.data = torch.tensor([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.],
[4., 4., 4.]])
//形状变为4×3的权值矩阵
linear_layer.bias.data.fill_(0.5)
output = linear_layer(inputs)
print(inputs, inputs.shape)
print(linear_layer.weight.data, linear_layer.weight.data.shape)
print(output, output.shape)
可以看到代码中,权值矩阵 W W W变为 4 × 3 4times 3 4×3的,这是因为计算过程中会自动将其转置为 3 × 4 3times 4 3×4再运算。
激活函数层( Activation Layer)
激活函数层功能
激活函数对特征进行非线性变换,赋予多层神经网络具有深度的意义。
神经网络中通常会采用全连接层进行叠加,例如Lenet输出分类结果时,采用了3个全连接层进行叠加;同时在每个全连接层输出时添加1个非线性激活函数层,它赋予了多层神经网络具有深度的意义。
分析
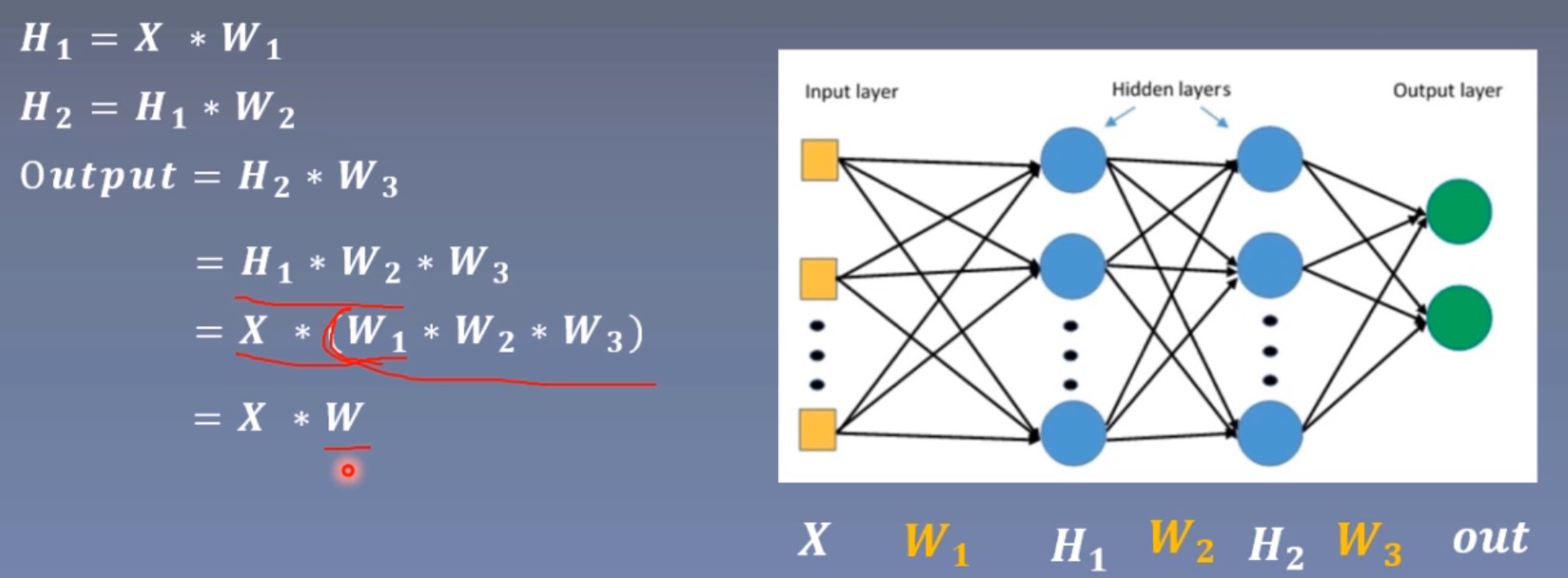
o
u
t
p
u
t
=
X
×
W
等
价
于
H
1
=
X
×
W
1
output=Xtimes W 等价于 H_1=Xtimes W_1 ,
output=X×W等价于H1=X×W1由图可以看出,多层神经网络由于矩阵乘法的结合性退化成了单层。 如果加入了非线性激活函数,那么多个矩阵相乘的公式就不成立了:
W
≠
W
1
∗
W
2
∗
W
3
W ne W_1*W_2*W_3,
W=W1∗W2∗W3多层神经网络也就不会退化。
1、激活函数sigmoid()—nn.sigmoid
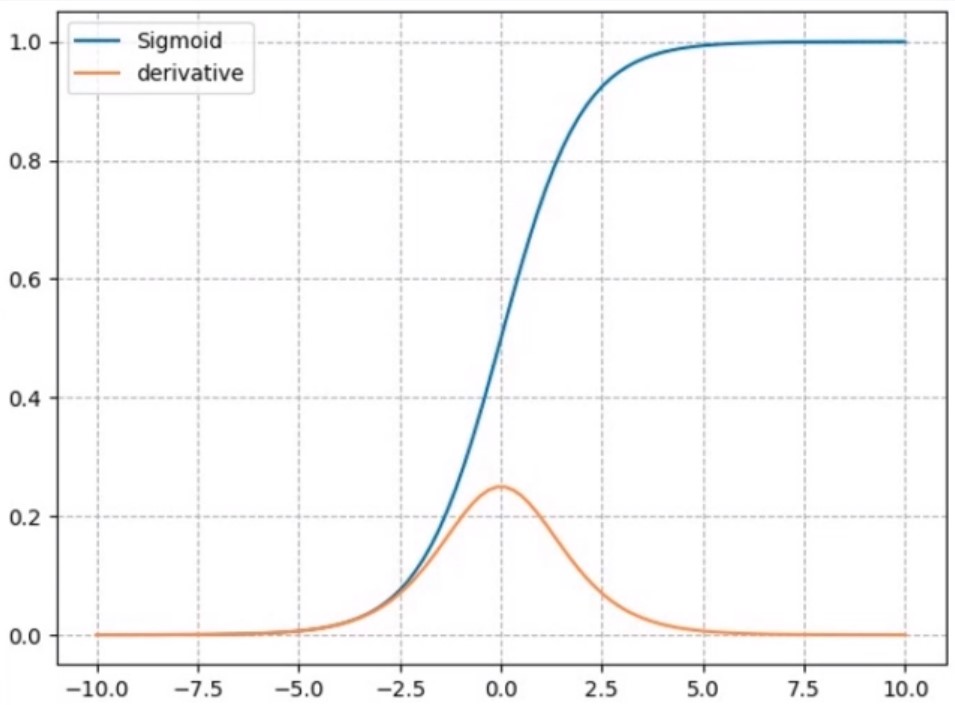
| 计算公式 | y = 1 1 + e − x y= frac{1}{1+e^{-x} quad} y=1+e−x1 |
|---|---|
| 梯度公式 | y ′ = y ∗ ( 1 − y ) y^{'}= y*(1-y) y′=y∗(1−y) |
| 特性 | 1、输出值在(0,1),符合概率 2、导数范围是[0,0.25],易导致梯度消失 3、输出为非0均值,破坏数据分布 |
| 分析 | |
| 由图11可知, | |
| (1)符合概率:蓝色曲线为sigmoid函数值。其函数值在(0,1),符合概率值的区间,sigmoid()因此也常用作二分类输出的激活函数;在循环神经网络RNN中,也作为各种门控单元的激活函数用来控制信息的流动。 | |
| (2)梯度消失:黄色曲线为导函数。导函数有2个饱和区,易导致梯度消失, 若神经元落入到饱和区,梯度几乎为0,就无法反向传播梯度、更新权重了。 | |
| (3)破坏数据分布:由曲线图可以看出,sigmoid函数值都是大于0的,形成非0均值的数据分布。 |
2、双曲正切函数Tanh()—nn.Tanh
| 计算公式 | y = s i n x c o s x = e x − e − x e x + e − x = 2 1 + e − 2 x − 1 y=frac{sinx}{cosx}= frac{e^x-e^{-x}quad }{e^x+e^{-x}quad}=frac {2}{1+e^{-2x}quad}-1 y=cosxsinx=ex+e−xex−e−x=1+e−2x2−1 |
|---|---|
| 梯度公式 | y ′ = 1 − y 2 y^{'}= 1-y^{2} y′=1−y2 |
| 特性 | 1、输出值在(-1,1),数据分布符合0均值 2、导数范围是(0,1),易导致梯度消失 |
y = s i n x c o s x = e x − e − x e x + e − x = 1 − e − 2 x 1 + e − 2 x = 2 − ( 1 + e − 2 x ) 1 + e − 2 x = 2 1 + e − 2 x − 1 y=frac{sinx}{cosx}= frac{e^x-e^{-x}quad }{e^x+e^{-x}quad}=frac {1-e^{-2x}}{1+e^{-2x}}=frac{2-(1+e^{-2x})}{1+e^{-2x}}=frac {2}{1+e^{-2x}quad}-1 y=cosxsinx=ex+e−xex−e−x=1+e−2x1−e−2x=1+e−2x2−(1+e−2x)=1+e−2x2−1
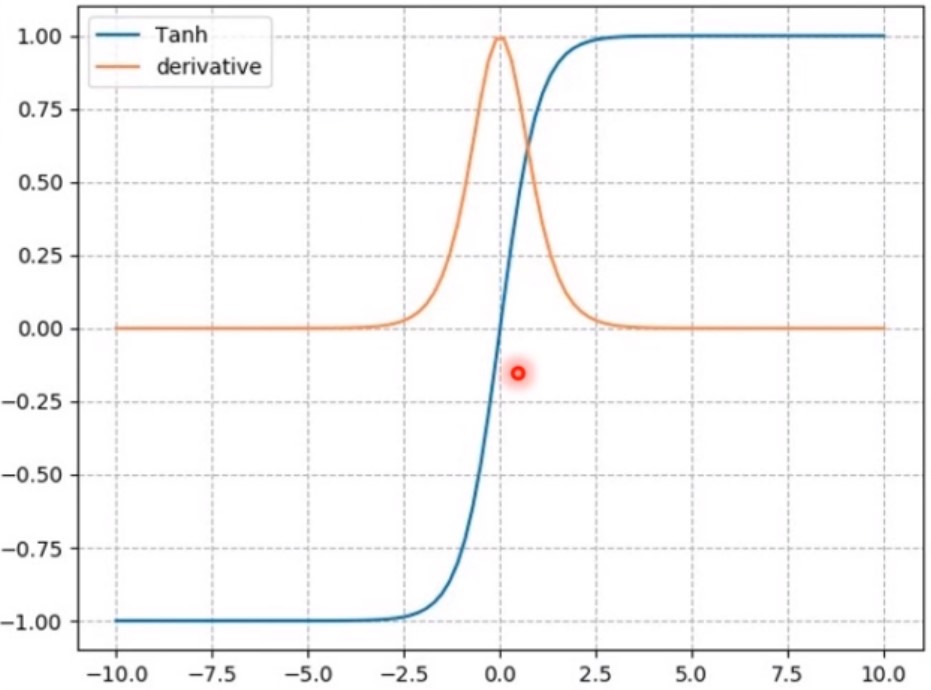
分析
由图12可知,
(1)破坏数据分布现象有所"减缓":蓝色曲线为输出函数,其范围为(-1,1),均值控制在0均值。
(2)梯度消失:黄色曲线为导函数,范围为()导函数仍有2个饱和区,虽然数值有所增大,但仍易导致梯度消失。
为什么上述两种激活函数都会导致梯度消失?
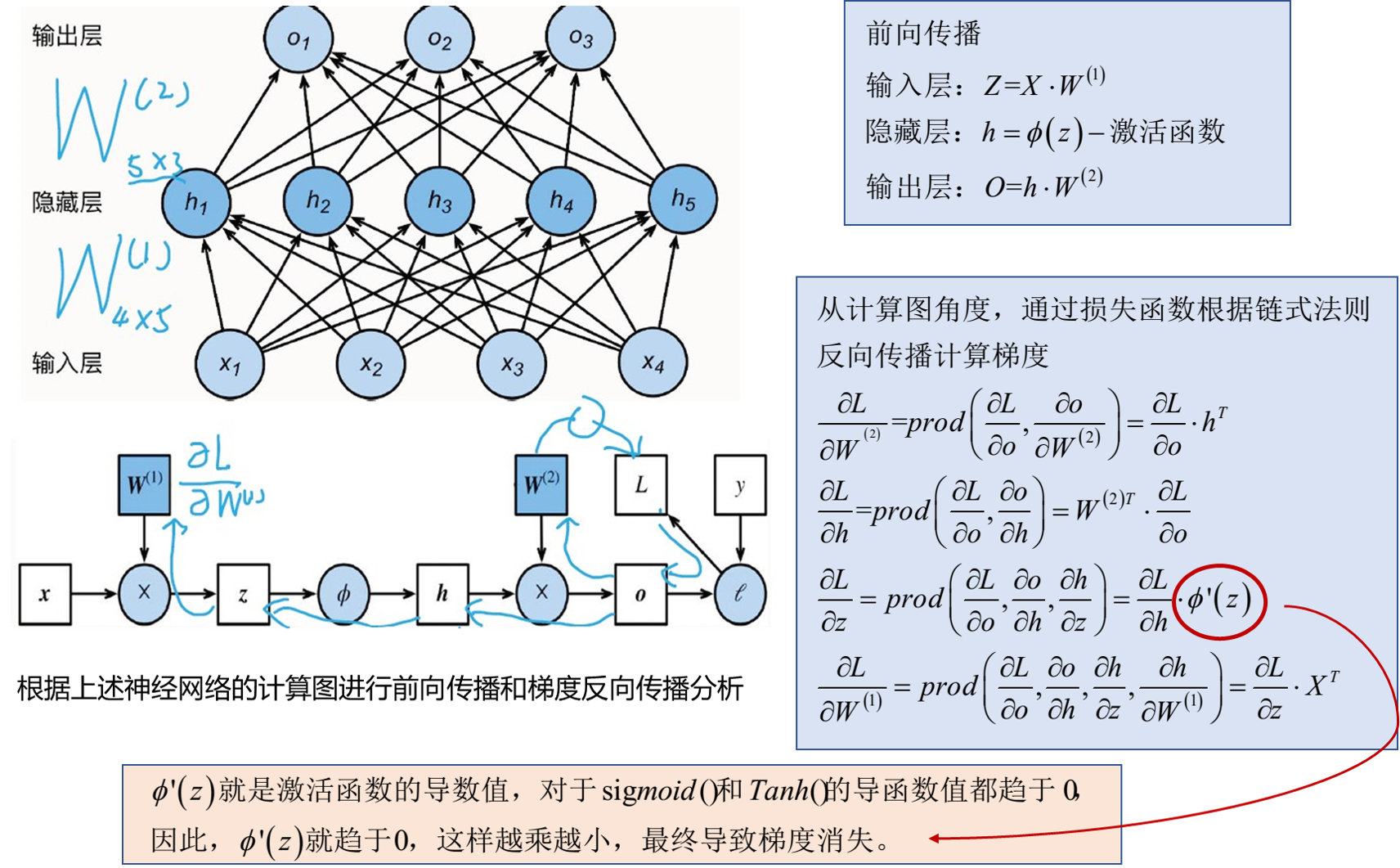
3、线性修正单元ReLU()—nn.ReLU
为了解决sigmoid和Tanh饱和激活函数的梯度消失这一问题,就提出了线性修正单元ReLU以解决。

| 计算公式 | y = m a x ( 0 , x ) y=max(0,x) y=max(0,x) |
|---|---|
| 梯度公式 | y = { 1 , x > 0 u n d e f i n e d , x = 0 0 , x < 0 y = begin{cases} 1, & x > 0 \undefined, & x=0\0,& x<0 end{cases} y=⎩⎪⎨⎪⎧1,undefined,0,x>0x=0x<0 |
| 特性 | 1、输出值均为正数,负半轴导致死神经元 2、导数是1,缓解梯度消失,但是引发梯度爆炸 |
| 分析 | |
| 由图13可知, | |
| (1)何为修正?正半轴输出函数值 y = x y=x y=x,但负半轴不再服从线性关系,输出为0,因此称为修正线性单元。 | |
| (2)导函数值:正半轴梯度为1,链式求导每次乘以1不会改变梯度尺度,不会造成梯度消失。但随着梯度不断相乘,也有可能造成梯度不断变大而造成梯度爆炸的问题。 | |
| (3)函数值:负半轴输出函数值均为0,导致死神经元现象,导致经过激活函数后没有输出。 | |
| 针对负半轴死神经元而引起的一系列问题,有很多改进。 |
3种改进的ReLU修正线性单元
针对负半轴死神经元而引起的一系列问题,有很多改进。
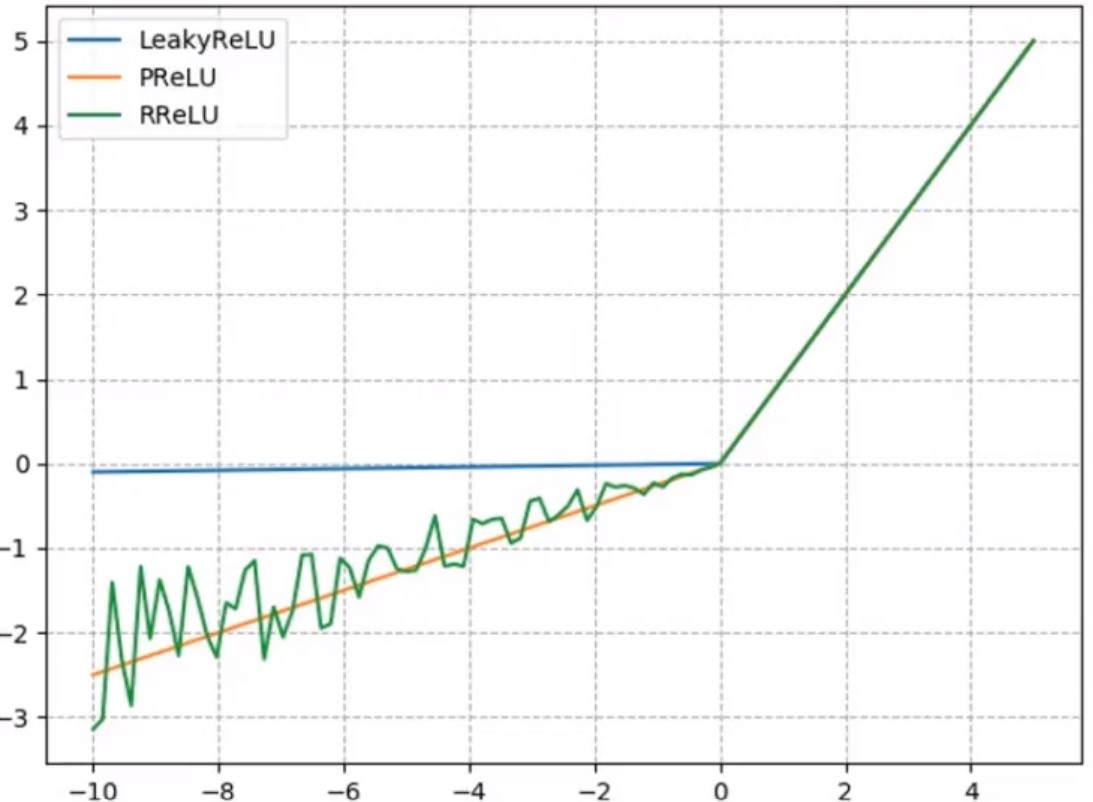
(1)nn.LeakyReLU(negative_slope):负半轴增加了1个很小的斜率,该斜率一旦设置就是固定的(如图所示曲线是增加了0.01的斜率);
(2)nn.PReLU(init):P表示斜率是可学习的参数,init用来设置可学习斜率的初始化值(如图所示初始化为0.25,随着网络的迭代更新,该斜率值是会变化的);
(3)nn.RReLU(lower均匀分布下限/upper均匀分布上限):R表示每一次的斜率都是随机的从1个均匀分布中采样得到的(如图绿色曲线所示,每一次斜率都有变化)。
关于激活函数可查阅:
激活函数的更多资料
总结
1、池化层:最大值池化、平均值池化、最大值反池化上采样
2、线性层:分析了如果没有非线性激活函数的加入,再多的线性层的叠加都等价于1层。
3、常用的激活函数sigmoid、Tanh,但这两类饱和激活函数会引发梯度消失,可采用非饱和激活函数ReLU进行替换,针对ReLU在负半轴导致死神经元的一系列问题,有一些变种函数。
最后
以上就是哭泣诺言最近收集整理的关于【学习笔记】Pytorch深度学习-网络层之池化层、线性层、激活函数层的全部内容,更多相关【学习笔记】Pytorch深度学习-网络层之池化层、线性层、激活函数层内容请搜索靠谱客的其他文章。








发表评论 取消回复