存在一个文本文件,如《传感器数据》,内容示例如: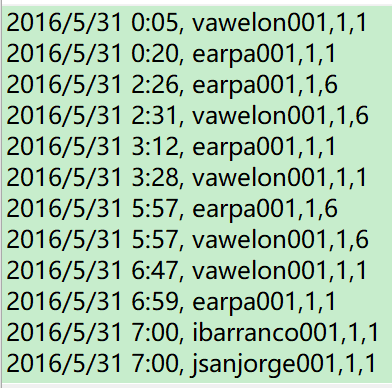
那么在第一列的是传感器获取数据的时间,第二列是传感器的编号,第三列是传感器所在的楼层,第四列是传感器所在位置的区域编号。
显然这是比较简单的一套由公司职员随身佩带的位置传感器采集的数据。
文章目录
文章目录
前言
一、思路
二、步骤
1.提取传感器编号为earpa001的数据
2.合并字符统计各楼层各区域出现的频次
总结
前言
随着智能的发展,人工到岗视察已不具有普适性,不经济也不高效。那么由传感器统计出来的数据具有更高的精准度与简便性。但是一般来说,比较简单的传感器所返回的数据都是未加工处理的,那么本题目的要求便是要求统计对应的职员在各楼层和区域出现的次数
一、思路
本题要求有两个:
1.提取传感器编号为earpa001的所有数据,要求输出文件时行尾无空格,无空行
2.统计传感器编号为earpa001的对应职员出现在各楼层和区域的次数
第一个要求很简单,读取每一行,再将每一行通过索引与earpa001对比筛选
第二个要求则需要通过遍历前一个要求的出书文件,找到对应的楼层与区域,连接起来,再通过上一个题目讲过的(具体查看python小题目1)字典的get函数的用法进行统计。
二、步骤
1.提取传感器编号为earpa001的数据
代码如下(示例):
f=open('传感器数据.txt','r',encoding='utf-8')#如果不加encoding程序会报错
fo=open('编号为earpa001的数据.txt','w')
ls=f.readlines()
d={}
for line in ls:#开始遍历文本内数据
lt=line.strip('n').split(',')#由于strip函数前一定是字符串,所以必须split函数在后
if lt[1]==' earpa001':#判断数据
fo.write("{},{},{},{}n".format(lt[0],lt[1],lt[2],lt[3]))#换行
f.close()
fo.close()
2.合并字符统计各楼层各区域出现的频次
代码如下(示例):
f=open('编号为earpa001的数据.txt','r',encoding='utf')
fo=open('earpa001_count.txt','w')
ls=f.readlines()
lt=''
d={}
for line in ls:
lt=line.strip('n').split(',')
data=lt[2]+'-'+lt[3] #字符串组装,实现楼层与区域结合
d[data]=d.get(data,0)+1
ls=list(d.items())
ls.sort(key=lambda x:x[1],reverse=True)
for i in ls:
fo.write('{}:{}n'.format(i[0],i[1])) #ls表内已经各键对值组成的元组,i就是键值对
f.close()
fo.close()
总结
d[w]=d. get(w,0)+1
其作用是增加一次元素w出现的次数。使用. get()方法获得当前字典d中w作为键对应的值,即w已经出现的次数。如果w不存在,则返回0,反之,则返回值。
几乎所有的统计频次的题都需要它,好了本期到这里结束了,咱们下期再见!
最后
以上就是诚心楼房最近收集整理的关于Python小题目2:统计文本中某特定字符组合出现的次数前言一、思路二、步骤总结的全部内容,更多相关Python小题目2:统计文本中某特定字符组合出现内容请搜索靠谱客的其他文章。








发表评论 取消回复