分类目录:《深入理解深度学习》总目录
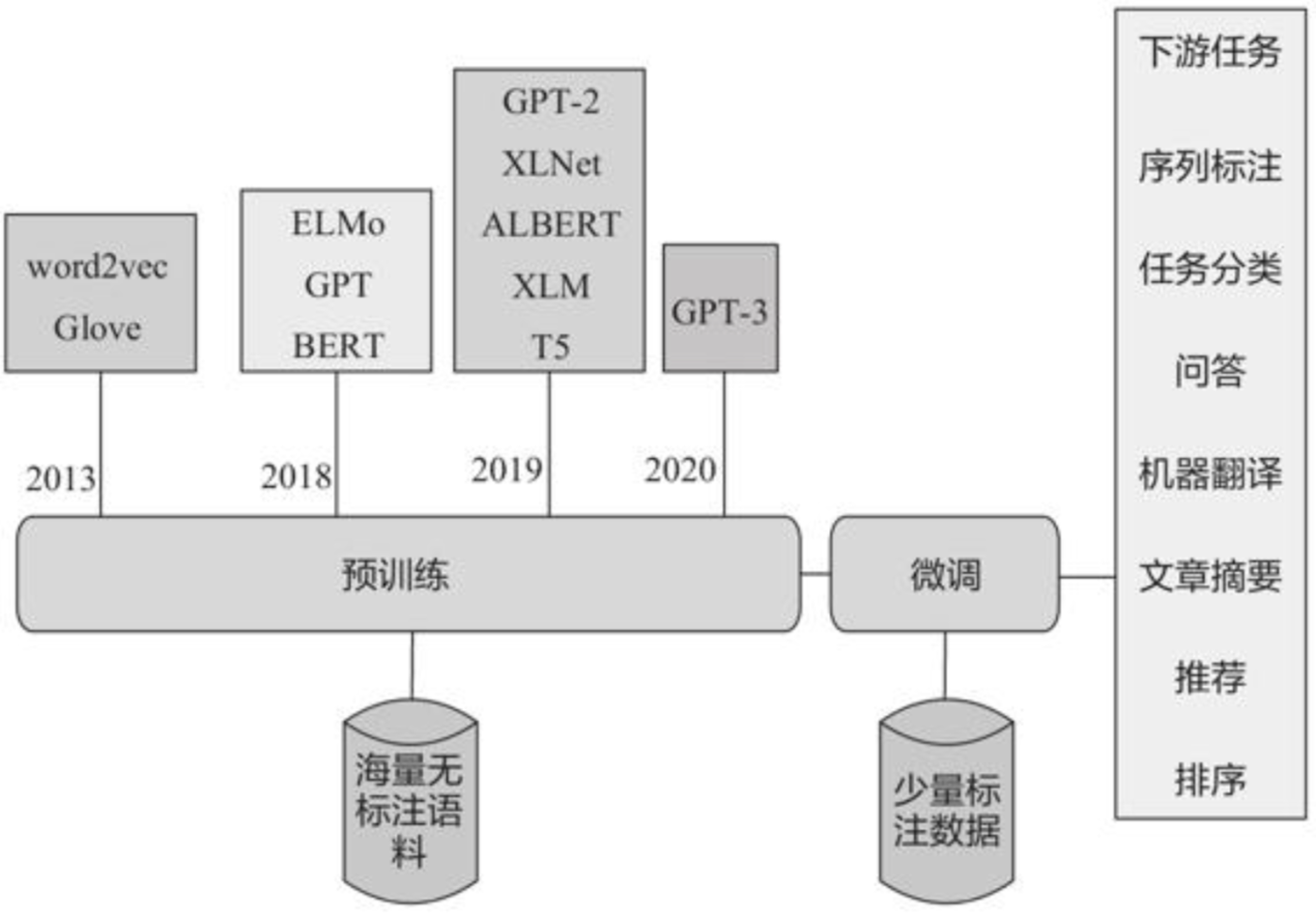
近些年基于深度学习的NLP技术的重大进展主要包括NNLM(2003)、Word Embedding(2013)、Seq2Seq(2014)、Attention(2015)、Transformer(2017)、GPT(2018)、BERT(2018)、XLNet(2019)、GPT-2(2019)、GPT-3(2020)等,主要预训练模型的大致发展脉络见下图:
各种主要预训练模型的特征、抽取特征方法、使用语言模型类别等内容:
| 模型 | 语言模型 | 特征提取 | 上下文 | 创新点 |
|---|---|---|---|---|
| ELMO | LM | Bi-LSTM | 单向 | 拼接两个单向语言模型的结果 |
| GPT | LM | Transformer(Decoder) | 单向 | 首次使用Transformer进行特征提取 |
| BERT | MLM | Transformer(Encoder) | 双向 | 使用MLM同时获取上下文特征表示 |
| ENRIE | MLM | Transformer(Encoder) | 双向 | 引入知识 |
| XLNet | PLM | Transformer-XL | 双向 | PLM+双注意力流+Transformer-XL |
| ALBERT | MLM | Transformer(Encoder) | 双向 | 词嵌入参数因式分解+共享隐藏层数+句子间顺序预测 |
这些模型各有优点和缺点,新模型往往是在解决旧模型缺点的基础上提出的:

常见预训练模型
预训练模型很多,发展也很迅速,下面我们介绍几种常用的预训练模型。
ELMo
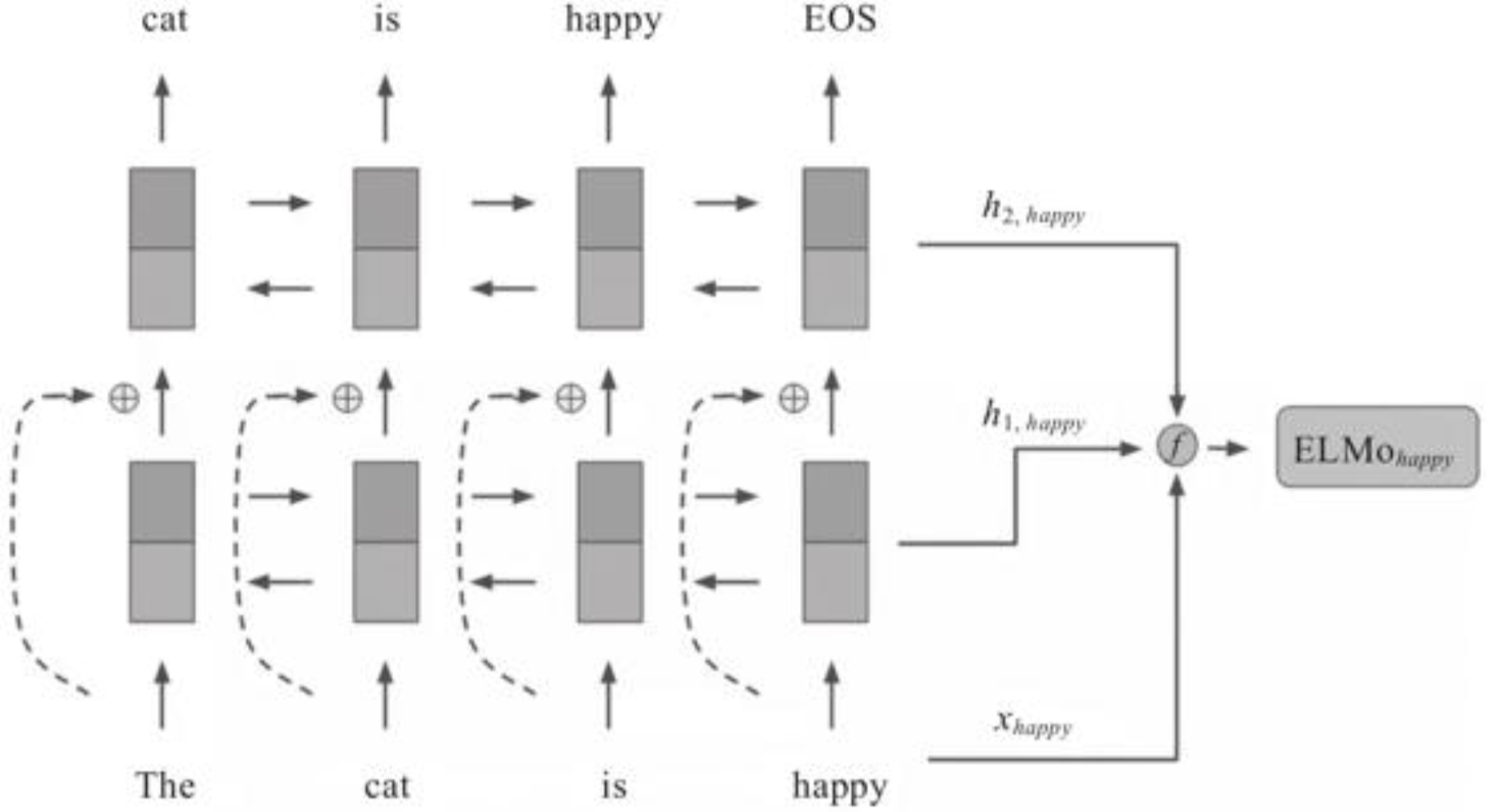
2018年的早些时候,AllenNLP的Matthew E. Peters等人在论文《Deep Contextualized Word Representations》(该论文获得了NAACL最佳论文奖)中首次提出了ELMo(Embedding from Language Model)预训练模型。从名称上可以看出,ELMo为了利用无标记数据,使用了语言模型。ELMo是最早进行语境化词嵌入的方法之一,是典型的自回归预训练模型,包括两个独立的单向LSTM实现的单向语言模型。ELMo的基本框架是一个双层的Bi-LSTM,每层对正向和反向的结果进行拼接,同时为增强模型的泛化能力,在第一层和第二层之间加入了一个残差结构。因此,ELMo在本质上还是一个单向的语言模型,其结构如下图所示:
GPT、GPT-2和GPT-3
预训练模型GPT是在OpenAI团队于2018年6月发表的一篇论文《Generative Pre-Training》中提出的。从名字上就可以看出GPT是一个生成式的预训练模型,与ELMo类似,也是一个自回归语言模型。与ELMo不同的是,其采用多层单向的Transformer Decoder作为特征抽取器,多项研究也表明,Transformer的特征抽取能力是强于LSTM的。GPT-2、GPT-3与GPT模型框架没有大的区别,GPT-2和GPT-3使用了更大的模型、更多的且质量更高的数据、涵盖范围更广的预训练数据,并采用了无监督多任务联合训练等。
BERT
BERT模型是由Google AI的Jacob Devlin和他的合作者们于2018年10月在arXiv上发表的一篇名为《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》的论文中提出的。BERT属于MLM模型,通过超大数据、巨大模型和极大的计算开销训练而成,在11个自然语言处理的任务中取得了最优(SOTA)结果,并在某些任务性能方面得到极大提升。
最后
以上就是火星上蜗牛最近收集整理的关于深入理解深度学习——预训练模型的全部内容,更多相关深入理解深度学习——预训练模型内容请搜索靠谱客的其他文章。








发表评论 取消回复