操作系统内核常需要维护数据结构的链表。Linux 内核已经同时有几个链表实现。为减少复制代码的数量, 内核已经创建了一个标准环形双向链表,并鼓励需要操作链表的人使用这个设施.
使用链表接口时,应当记住列表函数没做加锁。若驱动可能同一个列表并发操作,就必须实现一个锁方案。
为使用链表机制,驱动必须包含文件 ,它定义了一个简单的list_head 类型 结构:
struct list_head {
struct list_head *next,*prev;
}用于实际代码的链表几乎总是由某种结构类型构成,每个接口描述链表的一项。要在代码中使用链表设施,只要在构成链表的结构里嵌入一个list_head
struct my_struct {
struct list_head list;
int private;//其他特定数据类型
…
}链表头通常是一个独立的list_head结构
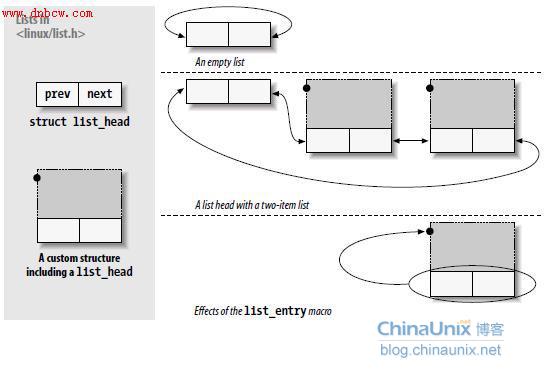
在使用链表之前,必须用INIT_LIST_HEAD宏来初始化链表头。
struct list_head my_list;
INIT_LIST_HEAD(&my_list);也可在编译时用下面宏初始化链表
LIST_HEAD(my_list);在头文件中声明了下列操作链表函数:
static inline void list_add(struct list_head *new, struct list_head *head)在链表头后面添加新项---通常在链表头部,这样,可以被用来建栈。注意:head不一定链表名义上的头,链表头本质上与其他项无任何区别。
static inline void list_add_tail(struct list_head *new, struct list_head *head)在链表头前面添加新项--即在链表的末尾处添加。可用list_add_tail来建立FIFO队列。
static inline void list_del(struct list_head *entry)
static inline void list_del_init(struct list_head *entry);删除链表中的给定项,如果该项还可能被重新插入到另一个链表中的话,应该使用list_del_init,它会重新初始化链表的指针。
static inline void list_move(struct list_head *list, struct list_head *head);
static inline void list_move_tail(struct list_head *list, struct list_head *head);吧给定项移动到链表的开始处,如果要把给定项放到新链表的末尾,使用list_move_tail。
static inline int list_empty(const struct list_head *head);如果给定的链表为空,返回一个非零值。
static inline void list_splice(struct list_head *list, struct list_head *head);通过在head之后插入list来合并两个链表。
List_head结构体有利于实现具有类似结构的链表,但调用程序通常对组成链表的大结构更感兴趣,因此定义了一些宏来方便操作大结构体。
点击(此处)折叠或打开
list_entry(struct list_head *ptr,type_of_struct,field_name);
ptr---指向正被使用的struct list_head的指针,
type_of_struct---是包含ptr的结构类型
field_name---是结构体中链表字段的名字
该宏返回当前所操作的链表项的大结构指针。struct my_struct * my_ptr =
List_entry(listptr,struct my_struct,list)
这样,遍历链表就很容易了,只需跟随prev和next指针。作为例子,假设我们想让my_struct链表中的项按照优先级降序排列,则增加新项的函数如下:
struct list_head my_list;
struct my_struct{
struct list_head list;
int priority;
} my_list;
void my_add_entry(struct my_struct *new)
{
struct list_head *ptr;
struct my_struct * entry;
for (ptr = my_list.next; ptr != &my_list; ptr = ptr->next){
entry = list_entry(ptr,struct my_struct,list);
if (entry->priority < new->priority){
list_add_tail(&new->list,ptr);
return ;
}
}
list_add_tail(&new->list,&my_struct)
}改进版
void my_add_entry(struct my_struct *new)
{
struct list_head *ptr;
struct my_struct *entry;
list_for_each(ptr,&my_list){
entry = list_entry(ptr,struct my_struct,list);
if (entry->priority < new->priority){
list_add_tail(&new->list,ptr);
return;
}
}
list_add_tail(&new->list,&my_struct);
}list_for_each(struct list_head *cursor,struct list_head *list);
创建一个for循环,每当游标指向链表中的下一项时执行一次
list_for_each_prev(struct list_head *cursor,struct list_head *list);
该版本向后遍历
list_for_each_safe(struct list_head *cursor, struct list_head *next,struct list_head *list);
当循环可能会删除链表中的项,就用该版本,它只是简单地在循环的开始出吧链表中的下一项存储在next中,这样如果cursor所指的项被删除也不会造成混乱。
用这两个宏处理链表更容易
list_for_each_entry(type *cursor,struct list_head *list,member);
list_for_each_entry_safe(type *cursor,type *next,struct list_head *list,member);
cursor是所指向包含结构体类型的指针,
member是包含结构体内list_head结构体的名字
用这两个宏就不用再在循环里地用list_entry了。最后
以上就是迷人硬币最近收集整理的关于Linux 内核链表的全部内容,更多相关Linux内容请搜索靠谱客的其他文章。








发表评论 取消回复