文章目录
- 前言
- 1.编译源码
- 1.1 官网下载编译后的包
- 1.2 手动编译
- 1.2.1 安装编译相关的依赖
- 1.2.2 手动安装cmake3.13.5
- 1.2.3 手动安装snappy1.1.3
- 1.2.4 安装JDK8(已安装可忽略)
- 1.2.5 安装配置Maven
- 1.2.6 安装ProtocolBuffer 2.5.0/ProtocolBuffer 3.7.0
- 1.2.7 编译hadoop
- 1.2.8 报错
- 2.从Hadoop框架讨论大数据生态
- 2.1 hadoop三大发行版本(了解)
- 2.2 Hadoop组成
- 2.2.1 HDFS架构
- 2.2.1 YARN架构
- 2.2.1 MapReduce架构
- 3. Hadoop运行环境搭建
- 3.1 常见问题解答
- 3.2 在node1服务器上配置hadoop
- 3.3 格式化namenode并启动集群
- 3.4 编写查看Hadoop集群状态脚本
- 3.4 编写查看Hadoop集群启停脚本
前言
Hadoop集群简介
Hadoop适合一次写入,多次读取,且不支持文件的修改场景,适合用来做数据分析,不适合用来做网盘。
优点:容错性高适合海量数据的存储和管理
缺点:仅支持数据的追加,不支持直接修改,hdfs对小文件比较敏感(重点
- Hadoop集群通常包括两个集群:HDFS集群、YARN集群
- 两个集群逻辑上分离、通常物理上在一起。
- 两个集群是标准得主从架构集群
逻辑上分离指的是两个集群之间没有依赖、互不影响,物理上在一起值得是某些角色往往部署在同一台物理服务器上。而MapReduce是计算框架、代码层面的组件,没有集群之说。
Hadoop部署模式
Standalone(单机模式)
1个机器运行1个java进程,所有角色在一个进程中运行,主要用于调试
Pseudo-Distributed mode(伪分布式)
一个机器运行多个进程,每个角色一个进程,主要用于调试
Cluster mode( 集群模式)
集群模式主要用于生产环境部署,会使用N太主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上
HA mode(高可用模式)
在集群模式的基础上为单点故障部署备份角色,形成主备架构,实现容错
1.编译源码
匹配不同操作系统的本地库环境,Hadoop某些操作比如压缩、IO需要调用本地库(.so丨.dll),注:Centos本地库文件格式是so,Windows本地库dll。
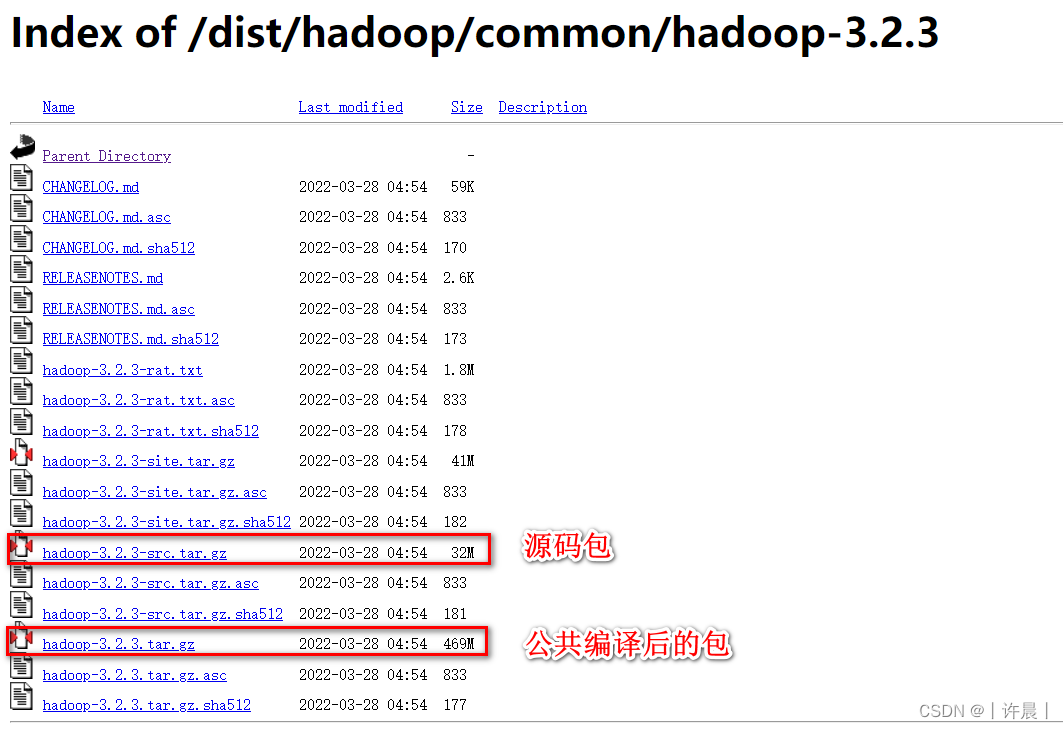
1.1 官网下载编译后的包
Hadoop官网更新了编译后的Hadoop包,跟着晨哥找到对应的版本
第一步:找到Hadoop版本列表
https://archive.apache.org/dist/hadoop/common/
推荐hadoop-3.1.4、hadoop-3.2.3、hadoop-3.3.3(需要ProtocolBuffer 3.7.1)
第二步:以3.2.3版本为例,下载编译后的包。
为什么要重新编译源码?
有兄弟就要问了,既然官方提供了编译后的源码包,为什么还要手动编译呢?
对于Hadoop乃至其他大数据软件来说,编译源码要从以下几个角度考虑
官方编译后的安装包,是一个最大公约数的安装包,能够在所有的平台上运行,但是呢对于某些平台的本地库兼容性不太友好。
- 我们在Hadoop中的压缩,解压,IO操作,需要调用系统本地库,Java语言对一些功能实现不了,这些压缩,IO,都是通过C,C++来实现的,因此Hadoopp通过JNDI调用一些动态库,在不同的平台运行可能就要针对不同的平台进行不同本地库编译,操作系统之间的差异很大,32位和64位也不一样,作为linux也有不同的发行版本。
- 修改源码,重构源码再编译
1.2 手动编译
理解了了为什么要编译,下面是编译的具体操作流程
源码包根目录下文件:BULIDING.txt
各个环境版本最好保持一致,大版本一致就行比如jdk只要是java8就行。为了节省读者时间,晨哥已经把hadoop3.1.4、hadoop3.2.3、hadoop3.3.3编译好了,直接点击编译成品包里,有编译好的三个版本供大家下载。感兴趣的同学可以自行下载各个版本的搭建包自行编译。Hadoop3各个版本下载链接
Build instructions for Hadoop
----------------------------------------------------------------------------------
Requirements:
* Unix System
* JDK 1.8 (必需要安装的)
* Maven 3.3 or later (必需要安装的,)
* ProtocolBuffer 2.5.0(hadoop-3.3.0以前必须且必须是这个版本,之后的版本ProtocolBuffer 用ProtocolBuffer 3.7.1)
* CMake 3.1 or newer (if compiling native code) (必需是手动安装的)
* Zlib devel (if compiling native code) (Hadoop3.1.x f不用,但是Hadoop3.2.x必装,否则报错)
* Cyrus SASL devel (if compiling native code)
* One of the compilers that support thread_local storage: GCC 4.8.1 or later, Visual Studio,
Clang (community version), Clang (version for iOS 9 and later) (if compiling native code)
* openssl devel (if compiling native hadoop-pipes and to get the best HDFS encryption performance) (需要,直接使用yum源安装即可)
* Linux FUSE (Filesystem in Userspace) version 2.6 or above (if compiling fuse_dfs) (以下都不需要管)
* Doxygen ( if compiling libhdfspp and generating the documents )
* Internet connection for first build (to fetch all Maven and Hadoop dependencies)
* python (for releasedocs)
* bats (for shell code testing)
* Node.js / bower / Ember-cli (for YARN UI v2 building)
jar包准备(hadoop源码、JDK8、maven、ant 、protobuf)
1.2.1 安装编译相关的依赖
1、yum install gcc gcc-c++
2、yum install autoconf automake libtool curl
3、yum install lzo-devel zlib-devel openssl openssl-devel ncurses-devel
4、yum install snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop libXtst
1.2.2 手动安装cmake3.13.5
#yum卸载已安装cmake 版本低
yum erase cmake
#解压
tar zxvf cmake-3.13.5.tar.gz
#编译安装
cd /opt/cmake-3.13.5
#编译时间很长,请耐心等待
./configure
#安装
make && make install
#验证
[root@node4 ~]# cmake -version
cmake version 3.13.5
# 卸载cmake
xargs rm < install_manifest.txt
1.2.3 手动安装snappy1.1.3
#卸载已经安装的
cd /usr/local/lib
rm -rf libsnappy*
#上传解压
tar zxvf snappy-1.1.3.tar.gz
#编译安装
cd /opt/snappy-1.1.3
./configure
make && make install
#让动态链接库为系统所共享(添加完后需要调用下ldconfig,不然添加的library会找不到)
ldconfig
#验证是否安装
[root@node4 snappy-1.1.3]# ls -lh /usr/local/lib |grep snappy
-rw-r--r-- 1 root root 511K Nov 4 17:13 libsnappy.a
-rwxr-xr-x 1 root root 955 Nov 4 17:13 libsnappy.la
lrwxrwxrwx 1 root root 18 Nov 4 17:13 libsnappy.so -> libsnappy.so.1.3.0
lrwxrwxrwx 1 root root 18 Nov 4 17:13 libsnappy.so.1 -> libsnappy.so.1.3.0
-rwxr-xr-x 1 root root 253K Nov 4 17:13 libsnappy.so.1.3.0
1.2.4 安装JDK8(已安装可忽略)
1.2.5 安装配置Maven
#解压安装包
tar zxvf apache-maven-3.5.4-bin.tar.gz
#配置环境变量
vim /etc/profile.d/my_eny.sh
export MAVEN_HOME=//opt/apache-maven-3.6.3
export MAVEN_OPTS="-Xms4096m -Xmx4096m"
export PATH=:$MAVEN_HOME/bin:$PATH
source /etc/profile
#验证是否安装成功
[root@node4 ~]# mvn -v
Apache Maven 3.5.4
#添加maven 阿里云仓库地址 加快国内编译速度
vim /opt/apache-maven-3.6.3/conf/settings.xml
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>central</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云谷歌仓库</name>
<url>https://maven.aliyun.com/repository/google</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云阿帕奇仓库</name>
<url>https://maven.aliyun.com/repository/apache-snapshots</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云spring仓库</name>
<url>https://maven.aliyun.com/repository/spring</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云spring插件仓库</name>
<url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云grails-core</name>
<url>https://maven.aliyun.com/repository/grails-core</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云gradle-plugin</name>
<url>https://maven.aliyun.com/repository/gradle-plugin</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云mapr-public</name>
<url>https://maven.aliyun.com/repository/mapr-public</url>
</mirror>
</mirrors>
1.2.6 安装ProtocolBuffer 2.5.0/ProtocolBuffer 3.7.0
#解压
tar zxvf protobuf-2.5.0.tar.gz
#编译安装
cd /opt/protobuf-2.5.0
./configure
make && make install
#让动态链接库为系统所共享(添加完后需要调用下ldconfig,不然添加的library会找不到)
ldconfig
#验证是否安装成功
[root@node4 protobuf-2.5.0]# protoc --version
libprotoc 2.5.0
#卸载
#查看执行文件路径
which protoc
sudo rm /usr/local/bin/protoc //执行文件
sudo rm -rf /usr/local/include/google //头文件
sudo rm -rf /usr/local/lib/libproto* //库文件
sudo rm -rf /usr/lib/protoc
1.2.7 编译hadoop
#上传解压源码包
tar zxvf hadoop-3.2.3-src.tar.gz
#编译
cd /opt/hadoop-3.2.3-src
mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib
#参数说明:
Pdist,native :把重新编译生成的hadoop动态库;
DskipTests :跳过测试
Dtar :最后把文件以tar打包
Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】
Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径
编译之后的安装包路径
/opt/hadoop-3.2.1-src/hadoop-dist/target
1.2.8 报错
[ERROR] Failed to execute goal org.apache.hadoop:hadoop-maven-plugins:3.2.1:cmake-compile (cmake-compile) on project hadoop-hdfs-native-client: CMake failed with error code 1 -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <args> -rf :hadoop-hdfs-native-client
解决办法:更换Hadoop源码包版本,推荐Hadoop3.1.4、Hadoop3.2.3、Hadoop3.3.3
2.从Hadoop框架讨论大数据生态
2.1 hadoop三大发行版本(了解)
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera内部集成了很多大数据框架。对应产品CDH。
Hortonworks文档较好。对应产品HDP。
- Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/ - Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。Cloudera的标价为每年每个节点10000美元。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。 - Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(4)Hortonworks目前已经被Cloudera公司收购。
2.2 Hadoop组成
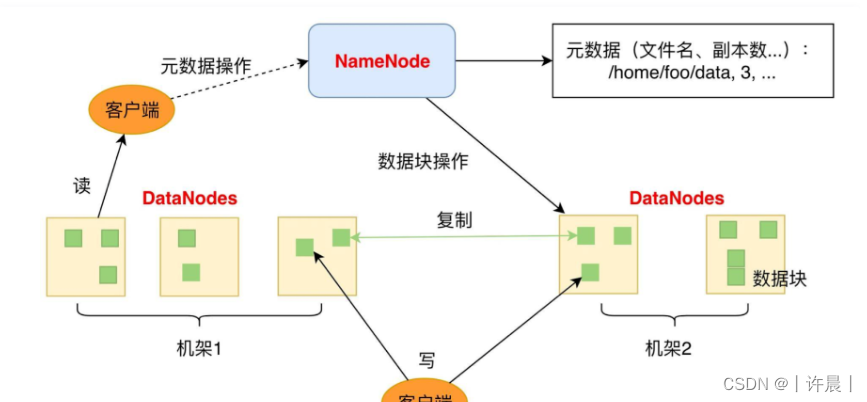
2.2.1 HDFS架构
2.2.1 YARN架构
2.2.1 MapReduce架构
3. Hadoop运行环境搭建
3.1 常见问题解答
| node1 | node2 | node3 |
|---|---|---|
| nn | rm | 2nn |
| dn | dn | dn |
| nm | nm | nm |
问题一:nn为什么有两个端口?
nn在工作的时候,一个需要和集群内部进行通信(8020),我们称之为RPC工作端口,一个给外界看,我们称之为http端口。
问题二:Hadoop 格式化失败 STARTUP_MSG: host = localhost/127.0.0.1
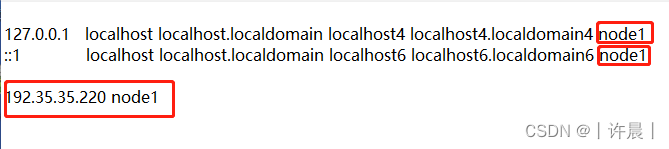
原因: hosts文件配置错误,当配置了本机IP映射 192.35.35.220 node1,第一行和第二行就不能添加 node1,否则格式化无法获取真实ip
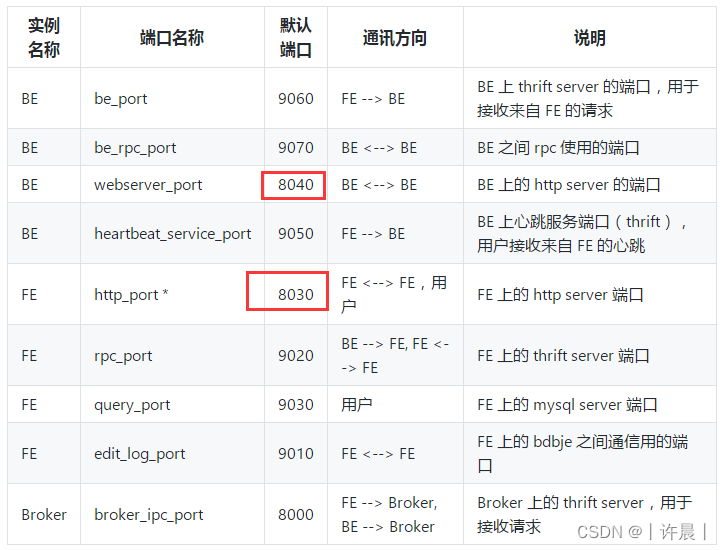
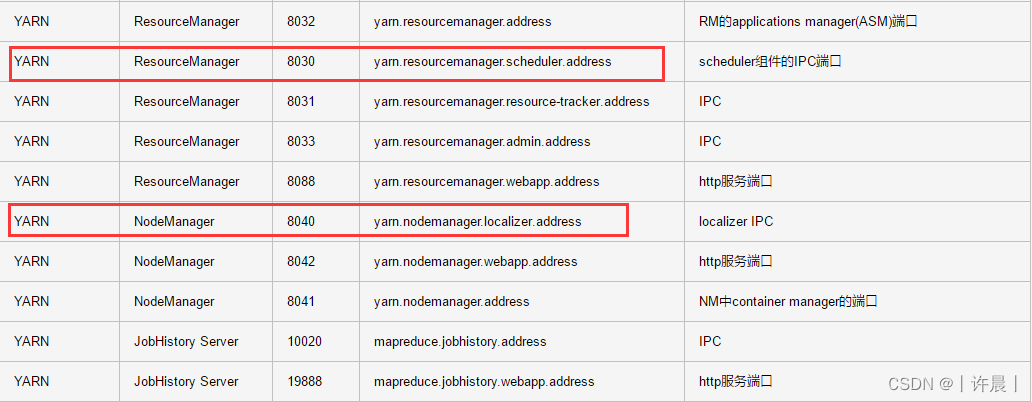
问题三:Doris与Hadoop yarn混合部署 yarn 无法启动?
8030和8040端口冲突
3.2 在node1服务器上配置hadoop
第一步:上传编译好的hadooop文件并解压到 /opt目录
第二步:配置hadoop环境变量
#hadoop
export HADOOP_HOME=/opt/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新并验证环境变量
[root@node1 hadoop-3.3.0]# source /etc/profile
[root@node1 hadoop-3.3.0]# hadoop version
Hadoop 3.3.0
Source code repository Unknown -r Unknown
Compiled by root on 2021-07-15T07:35Z
Compiled with protoc 3.7.1
From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4
This command was run using /opt/hadoop-3.3.0/share/hadoop/common/hadoop-common-3.3.0.jar
第二步:cd /opt/hadoop-3.3.0/etc/hadoop,修改以下文件
- hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_333
#文件最后添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 指定HDFS数据的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置该root用户允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
</configuration>
- hdfs-site.xml
<!-- 指定secondarynamenode运行位置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:50090</value>
</property>
- mapred-site.xml
<!--MapReduce执行时由Yarn来进行资源调度-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--给MapReduce指定Hadoop的安装位置-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
- yarn-site.xml
<!-- 指定YARN的主角色(ResourceManager)的地址 -->
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定YARN的主角色(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node2:8035</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:8036</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:"" -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 保存的时间7天,单位是秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
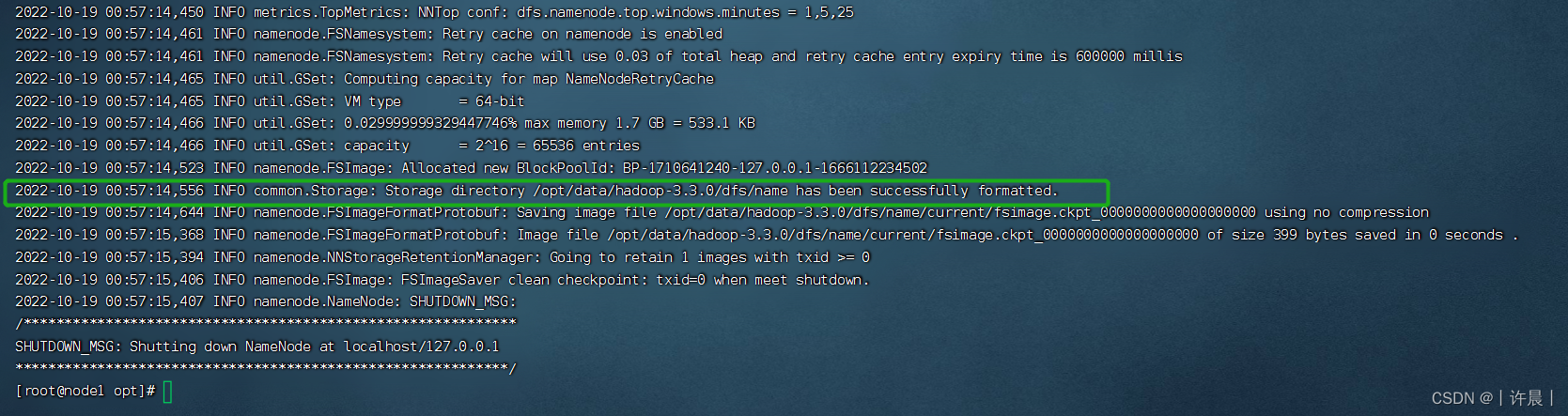
3.3 格式化namenode并启动集群
由于namenode我们安装在node1服务器上,所以在node1服务器上执行命令
hdfs namenode -format
3.4 编写查看Hadoop集群状态脚本
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps $@ | grep -v Jps
done
3.4 编写查看Hadoop集群启停脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh node1 "/opt/hadoop-3.3.0/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh node2 "//opt/hadoop-3.3.0/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh node1 "/opt/hadoop-3.3.0/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh node1 "/opt/hadoop-3.3.0/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh node2 "//opt/hadoop-3.3.0/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh node1 "//opt/hadoop-3.3.0/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
最后
以上就是野性花生最近收集整理的关于【博学谷学习记录】超强总结,用心分享丨大数据超神之路(五):Hadooop基础篇前言1.编译源码2.从Hadoop框架讨论大数据生态3. Hadoop运行环境搭建的全部内容,更多相关【博学谷学习记录】超强总结,用心分享丨大数据超神之路(五):Hadooop基础篇前言1.编译源码2.从Hadoop框架讨论大数据生态3.内容请搜索靠谱客的其他文章。








发表评论 取消回复