提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、np数组的构造
- 二、np数组的变形与合并
- 三、np数组的切片与索引
- 四、常用函数
- 五、广播机制
- 六、向量与矩阵的运算
声明:本文基于Datawhale提供的资料学习理解总结而来,如有侵权,联系速删。
一、np数组的构造
一般方法通过array来构造:
import numpy as np
np.array([1,2,3])特殊数组生成方式:
【等差数列】:np.linspace , np.arange
import numpy as np
np.linspace(1,5,11) # 起始、终止(包含)、样本个数
# Out:array([1. , 1.4, 1.8, 2.2, 2.6, 3. , 3.4, 3.8, 4.2, 4.6, 5. ])
import numpy as np
np.arange(1,5,2) # 起始、终止(不包含)、步长
# Out:array([1, 3])
【特殊矩阵】: zeros, eye, full
zeros用于生成零矩阵,eye用于生成单位矩阵,full用于填充
np.zeros((2,3)) # 传入元组表示各维度大小
# Out:array([[0., 0., 0.],
# [0., 0., 0.]])
np.eye(3) # 3*3的单位矩阵
# Out:array([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
np.eye(3, k=1) # 偏移主对角线1个单位的伪单位矩阵
# Out:array([[0., 1., 0.],
# [0., 0., 1.],
# [0., 0., 0.]])
np.full((2,3), 10) # 元组传入大小,10表示填充数值
# Out:array([[10, 10, 10],
# [10, 10, 10]])
np.full((2,3), [1,2,3]) # 每行填入相同的列表
# Out:array([[1, 2, 3],
# [1, 2, 3]])【随机矩阵】:np.random
rand用于生成0-1均匀分布的随机数组:
np.random.rand(3) # 生成服从0-1均匀分布的三个随机数
#Out:array([0.55550361, 0.09152596, 0.16543795])
np.random.rand(3, 3) # 注意这里传入的不是元组,每个维度大小分开输入
#Out:array([[0.54073648, 0.25404973, 0.36529935],
# [0.30601613, 0.61560633, 0.46808499],
# [0.70884679, 0.16206435, 0.07645365]])对于服从区间a到b上的均匀分布可以如下生成:
a, b = 5, 15
(b - a) * np.random.rand(3) + a
#Out: array([12.02081464, 9.97105026, 14.22299817])也可以选择已有的库函数:
np.random.uniform(5, 15, 3)
#Out: array([5.71941508, 9.52309402, 5.44193533])randn用于生成N(0,I)的标准正态分布:
np.random.randn(3)
#Out: array([-0.80135678, -1.65845284, 1.67007456])
np.random.randn(2, 2)
#Out:
#array([[ 1.24397986, -0.62766172],
# [-0.14620696, 0.94400227]])
对于服从方差为σ²均值为 μ的一元正态分布可以如下生成:
igma, mu = 2.5, 3
mu + np.random.randn(3) * sigma
#Out: array([1.03345622, 4.28382765, 2.45767191])同样,也可选择从已有函数生成:
np.random.normal(3, 2.5, 3)
#Out: array([2.18609445, 5.50275186, 0.13237503])randint用于生成随机整数组,可以指定生成随机数组的最小值最大值(不包含)和维度大小:
low, high, size = 5, 15, (2,2) # 生成5到14的随机整数
np.random.randint(low, high, size)
#Out:
#array([[13, 11],
# [ 6, 11]])choice用于生成随机列表,可以从给定列表中以一定方式和概率抽取结果,当不指定概率时为均匀采样,默认抽取方式为有放回抽样:
my_list = ['a', 'b', 'c', 'd']
np.random.choice(my_list, 2, replace=False, p=[0.1, 0.7, 0.1 ,0.1])
#Out:array(['b', 'c'], dtype='<U1')
np.random.choice(my_list, (3,3))
#Out:
#array([['c', 'd', 'b'],
# ['c', 'd', 'b'],
# ['c', 'd', 'd']], dtype='<U1')当返回的元素个数与原列表相同时,不放回抽样等价于使用permutation函数,即打散原列表:
np.random.permutation(my_list)
#Out: array(['c', 'b', 'a', 'd'], dtype='<U1')最后,需要提到的是随机种子,它能够固定随机数的输出结果:
p.random.seed(0)
np.random.rand()
#Out: 0.5488135039273248
np.random.seed(0)
np.random.rand()
#Out: 0.5488135039273248随机种子seed括号里的数,顾名思义, 好像就是一个固定的序列集合的种子代号,例如代号0(如:0,1,2,3,4…),中包含一大串随机数,但都是固定的,所以,无论后面怎么random.rand,生成的随机数都是seed(0)集合中的随机数。
二、np数组的变形与合并
【转置】:T
np.zeros((2,3)).T
#Out:
#array([[0., 0.],
# [0., 0.],
# [0., 0.]])【合并操作】:r_, c_
在二维数组中,r_和c_分别表示上下合并与左右合并:
np.r_[np.zeros((2,3)),np.zeros((2,3))]
#Out:
#array([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]])
np.c_[np.zeros((2,3)),np.zeros((2,3))]
#Out:
#array([[0., 0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0., 0.]])一维数组和二维数组进行合并时,应当把其视作列向量,在长度匹配的情况下只能使用左右合并的c_操作:
try:
np.r_[np.array([0,0]),np.zeros((2,1))]
except Exception as e:
Err_Msg = e
Err_Msg
#Out: ValueError('all the input arrays must have same number of dimensions, but the array at index 0 has 1 dimension(s) and the array at index 1 has 2 dimension(s)')
np.r_[np.array([0,0]),np.zeros(2)]
#Out: array([0., 0., 0., 0.])
np.c_[np.array([0,0]),np.zeros((2,3))]
#Out:
#array([[0., 0., 0., 0.],
# [0., 0., 0., 0.]])【维度变换】:reshape
reshape能够把原数组按照新的维度重新排列。在使用时,有两种模式,分别为C模式与F模式,分别以逐行和逐列的顺序进行填充读取
target = np.arange(8).reshape(2,4)
target
#Out:
#array([[0, 1, 2, 3],
# [4, 5, 6, 7]])
arget.reshape((4,2), order='C') # 按照行读取和填充
#Out:
#array([[0, 1],
# [2, 3],
# [4, 5],
# [6, 7]])
target.reshape((4,2), order='F') # 按照列读取和填充
#Out:
#array([[0, 2],
# [4, 6],
# [1, 3],
# [5, 7]])
因为被调用数组的大小是确定的,reshape允许有一个维度存在空缺,此时只需填充-1即可:
target.reshape((4,-1))
#Out:
#array([[0, 1],
# [2, 3],
# [4, 5],
# [6, 7]])三、np数组的切片与索引
数组的切片模式除使用slice类型的start:end:step切片,还可以直接传入列表指定某个维度的索引进行切片:
target = np.arange(9).reshape(3,3)
target
#Out:
#array([[0, 1, 2],
# [3, 4, 5],
# [6, 7, 8]])
target[:-1, [0,2]] #(最后一行之前,索引为0,2的列)
#Out:
#array([[0, 2],
# [3, 5]])此外,还可利用np.ix_在对应的维度上使用布尔索引,但此时不能使用slice切片:
target[np.ix_([True, False, True], [True, False, True])]
#Out:
#array([[0, 2],
# [6, 8]])
target[np.ix_([1,2], [True, False, True])]
#Out:
#array([[3, 5],
# [6, 8]])当数组维度为一维时,可直接进行布尔索引,而无需np.ix_:
new = target.reshape(-1)
new[new%2==0]
#Out: array([0, 2, 4, 6, 8])四、常用函数
为方便理解,假设下述函数输入的数组都是一维的
where
是一种条件函数,可以指定不满足条件位置对应的填充值:
a = np.array([-1,1,-1,0])
np.where(a>0, a, 5) # 对应位置为True时填充a对应元素,否则填充5
#Out: array([5, 1, 5, 5])nonzero,argmax,argmin
这三个函数返回的都是索引,nonzero返回非零的索引,argmax,argmin分别返回最大和最小数的索引:
a = np.array([-2,-5,0,1,3,-1])
np.nonzero(a)
#Out: (array([0, 1, 3, 4, 5], dtype=int64),)
a.argmax()
#Out: 4
a.argmin()
#Out: 1any,all
any 指当序列至少存在一个 True 或非零元素时返回 True ,否则返回 False
all 指当序列元素全为 True 或非零元素时返回 True ,否则返回 False
a = np.array([0,1])
a.any()
#Out: True
a.all()
#Out: Falsecumprod,cumsum,diff
cumprod, cumsum 分别表示累乘和累加函数,返回同长度的数组, diff 表示和前一个元素做差,由于第一个元素为缺失值,因此在默认参数情况下,返回长度是原数组减1
a = np.array([1,2,3])
a.cumprod()
#Out: array([1, 2, 6])
a.cumsum()
#Out: array([1, 3, 6])
np.diff(a)
#Out: array([1, 1])统计函数
常用的统计函数包括 max, min, mean, median, std, var, sum, quantile ,其中分位数计算是全局方法,因此不能通过 array.quantile 的方法调用:
target = np.arange(5)
target
#Out: array([0, 1, 2, 3, 4])
target.max()
#Out: 4
np.quantile(target, 0.5) # 0.5分位数
#Out: 2.0但是对于含有缺失值的数组,它们返回的结果也是缺失值,如果需要略过缺失值,必须使用 nan* 类型的函数,上述的几个统计函数都有对应的 nan* 函数。
target = np.array([1, 2, np.nan])
target
#Out: array([ 1., 2., nan])
target.max()
#Out: nan
np.nanmax(target)
#Out: 2.0
np.nanquantile(target, 0.5)
#Out: 1.5对于协方差和相关系数分别可以利用 cov, corrcoef 计算:
target1 = np.array([1,3,5,9])
target2 = np.array([1,5,3,-9])
np.cov(target1, target2)
#Out:
#array([[ 11.66666667, -16.66666667],
# [-16.66666667, 38.66666667]])
np.corrcoef(target1, target2)
#Out:
#array([[ 1. , -0.78470603],
# [-0.78470603, 1. ]])最后,需要说明二维 Numpy 数组中统计函数的 axis 参数,它能够进行某一个维度下的统计特征计算,当 axis=0 时结果为列的统计指标,当 axis=1 时结果为行的统计指标:
target = np.arange(1,10).reshape(3,-1)
target
#Out:
#array([[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]])
target.sum(0)
#Out: array([12, 15, 18])
target.sum(1)
#Out: array([ 6, 15, 24])五、广播机制
广播机制用于处理两个不同维度数组之间的操作,这里只讨论不超过两维的数组广播机制。
标量和数组的操作
当一个标量和数组进行运算时,标量会自动把大小扩充为数组大小,之后进行逐元素操作:
res = 3 * np.ones((2,2)) + 1
res
#Out:
#array([[4., 4.],
# [4., 4.]])
res = 1 / res
res
#Out:
#array([[0.25, 0.25],
# [0.25, 0.25]])二维数组之间的操作
当两个数组维度完全一致时,使用对应元素的操作,否则会报错,除非其中的某个数组的维度是 m×1 或者 1×n ,那么会扩充其具有 1 的维度为另一个数组对应维度的大小。例如, 1×2 数组和 3×2 数组做逐元素运算时会把第一个数组扩充为 3×2 ,扩充时的对应数值进行赋值。但是,需要注意的是,如果第一个数组的维度是 1×3 ,那么由于在第二维上的大小不匹配且不为 1 ,此时报错。
res = np.ones((3,2))
res
#Out:
#array([[1., 1.],
# [1., 1.],
# [1., 1.]])
res * np.array([[2,3]]) # 第二个数组扩充第一维度为3
#Out:
#array([[2., 3.],
# [2., 3.],
# [2., 3.]])
res * np.array([[2],[3],[4]]) # 第二个数组扩充第二维度为2
#Out:
#array([[2., 2.],
# [3., 3.],
# [4., 4.]])
res * np.array([[2]]) # 等价于两次扩充,第二个数组两个维度分别扩充为3和2
#Out:
#array([[2., 2.],
# [2., 2.],
# [2., 2.]])一维数组与二维数组的操作
当一维数组 Ak 与二维数组 Bm,n 操作时,等价于把一维数组视作 A1,k 的二维数组,使用的广播法则与【b】中一致,当 k!=n 且 k,n 都不是 1 时报错。
np.ones(3) + np.ones((2,3))
#Out:
#array([[2., 2., 2.],
# [2., 2., 2.]])
np.ones(3) + np.ones((2,1))
#Out:
#array([[2., 2., 2.],
# [2., 2., 2.]])
np.ones(1) + np.ones((2,3))
#Out:
#array([[2., 2., 2.],
# [2., 2., 2.]])六、向量与矩阵的计算
向量内积:dot

a = np.array([1,2,3])
b = np.array([1,3,5])
a.dot(b)
#Out: 22向量范数与矩阵范数:np.lianlg.norm
在矩阵范数的计算中,最重要的是ord参数,可选值如下:

matrix_target = np.arange(4).reshape(-1,2)
matrix_target
#Out:
#array([[0, 1],
# [2, 3]])
np.linalg.norm(matrix_target, 'fro')
#Out: 3.7416573867739413
np.linalg.norm(matrix_target, np.inf)
#Out: 5.0
np.linalg.norm(matrix_target, 2)
#Out: 3.702459173643833vector_target = np.arange(4)
vector_target
#Out: array([0, 1, 2, 3])
np.linalg.norm(vector_target, np.inf)
#Out: 3.0
np.linalg.norm(vector_target, 2)
#Out: 3.7416573867739413
np.linalg.norm(vector_target, 3)
#Out: 3.3019272488946263矩阵乘法:@
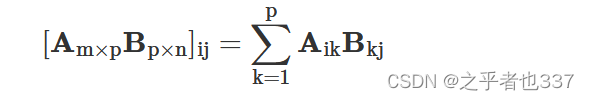
a = np.arange(4).reshape(-1,2)
a
#Out:
#array([[0, 1],
# [2, 3]])
b = np.arange(-4,0).reshape(-1,2)
b
#Out:
#array([[-4, -3],
3 [-2, -1]])
a@b
#Out:
#array([[ -2, -1],
# [-14, -9]])最后
以上就是幸福灰狼最近收集整理的关于运用Pandas进行数据分析——(2)Numpy基础声明:本文基于Datawhale提供的资料学习理解总结而来,如有侵权,联系速删。的全部内容,更多相关运用Pandas进行数据分析——(2)Numpy基础声明:本文基于Datawhale提供内容请搜索靠谱客的其他文章。








发表评论 取消回复