我是靠谱客的博主 大方红牛,这篇文章主要介绍【Python】pandas合并Excel和匹配查找并输出匹配结果一:目标匹配股票公司.xlsx,一个sheet,一张表二:招商.xlsx sheet0,有额外的无效列sheet3 三张表,两表中间间隔不同,表从头开始sheet4 三张表, 表的位置不是从头开始三: 中金.xlsx 四:汇总表.xlsx,合并效果如下五:匹配结果.xlsx,匹配结果如下:六:代码如下,现在分享给大家,希望可以做个参考。
新建如下测试excel表:
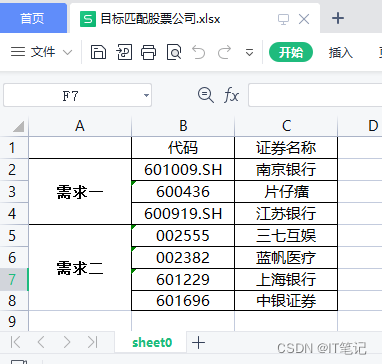
一:目标匹配股票公司.xlsx,一个sheet,一张表
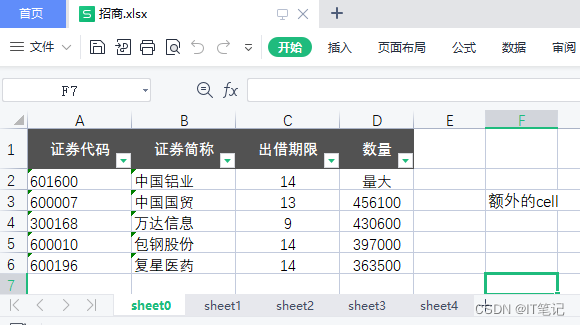
二:招商.xlsx sheet0,有额外的无效列
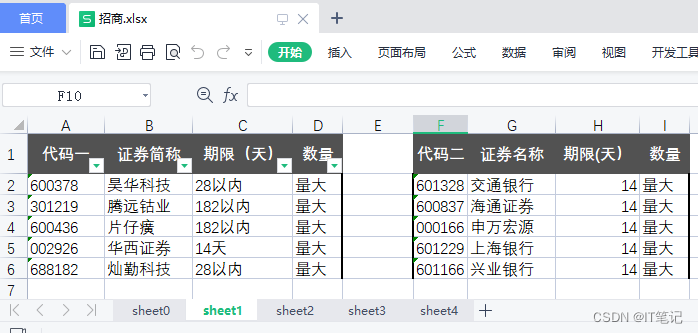
sheet1 两张表, 表的位置从头开始,中间有间隔
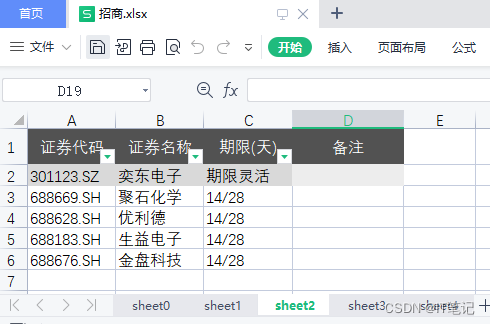
sheet2
sheet3 三张表,两表中间间隔不同,表从头开始
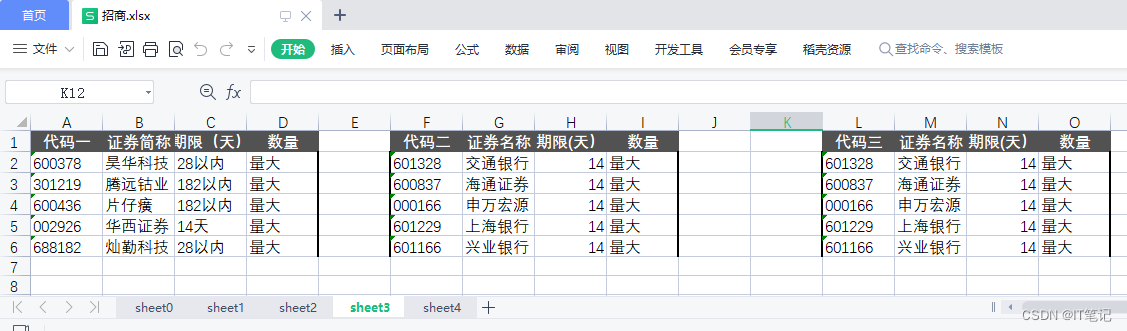
sheet4 三张表, 表的位置不是从头开始
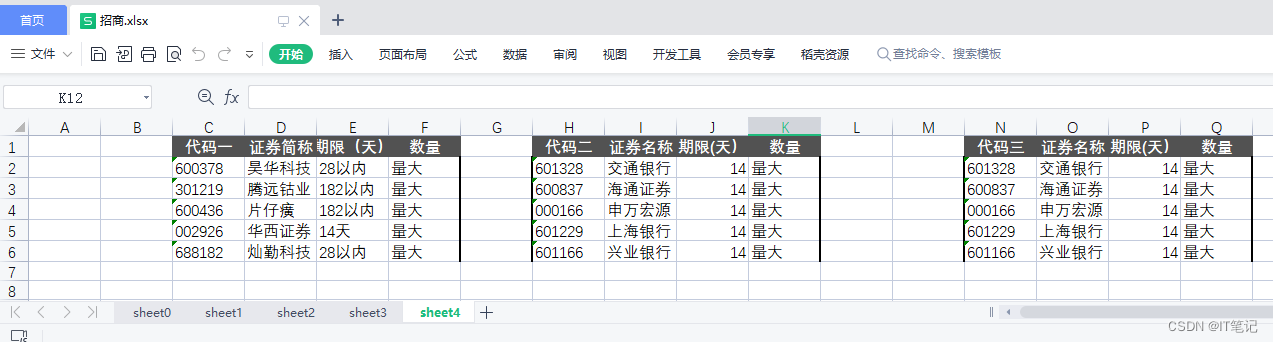
三: 中金.xlsx
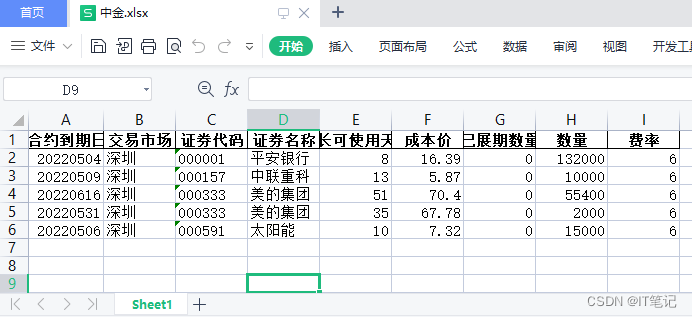
四:汇总表.xlsx,合并效果如下
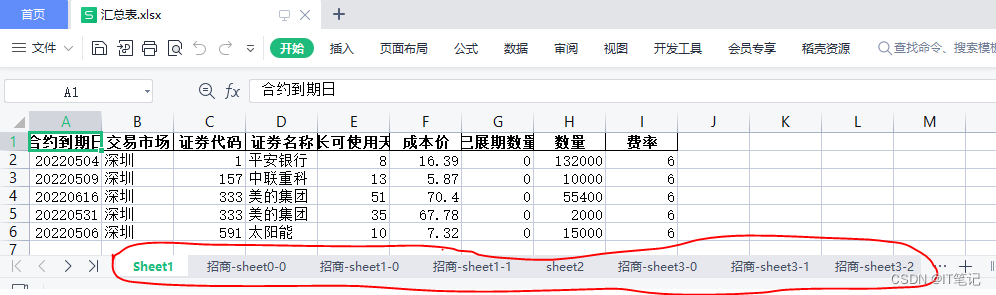
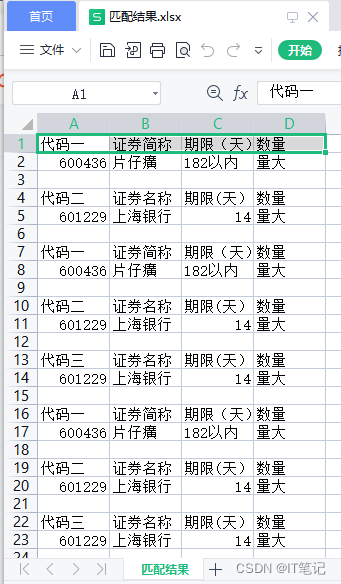
五:匹配结果.xlsx,匹配结果如下:
六:代码如下
# enconding = 'utf-8'
from pathlib import Path
import pandas as pd
import numpy as np
import os,re,time,sys
class ExeclProc(object):
def __init__(self, target_excel, merge_excel, match_result_excel):
self.cur_path = Path(os.path.dirname(__file__)) #获取当前执行文件的路径
self.merge_excel = os.path.join(self.cur_path, merge_excel) #合并总表的文件相对路径
self.workbook = pd.ExcelWriter(self.merge_excel) #新建总表
self.excels = self.cur_path.glob('*.xlsx*') # 获取文件夹下所有工作簿的文件路径
self.target_excel = os.path.join(self.cur_path, target_excel)
self.match_result = os.path.join(self.cur_path, match_result_excel)
self.save_wb = pd.ExcelWriter(self.match_result)
def exclude_new_create_execl(self, file_name):
exclude_new_create_file = []
exclude_new_create_file.append(os.path.basename(self.merge_excel))
exclude_new_create_file.append(os.path.basename(self.target_excel))
exclude_new_create_file.append(os.path.basename(self.match_result))
if file_name in exclude_new_create_file:
return True
return False
def is_single_sheet_multi_table(self,cloums):
for column in cloums:
if re.findall(r'Unnamed: d', column):#通过识别表头中有Unnamed判断有多个表
return True
return False
def save_single_sheet_multi_table_column_start_end_index(self,file, sheet_name, index, start, end):
table_name = re.sub('.xls[x]?', "-",file) + sheet_name + '-{}'
if start != end:
self.table_column_start_end[table_name.format(index)] = (start, end)
return True
return False
def calc_single_sheet_multi_table_start_end_idx(self,file,sheet_name,colums):
self.table_column_start_end = {}
column_start_idx = 0
column_end_idx = 0
table_head_serial_num = 0
for column_idx,column in enumerate(colums):
if re.findall(r'Unnamed: d+', column):
if column_idx + 1 < len(colums) and re.findall(r'Unnamed: d+', colums[column_idx + 1]):
self.save_single_sheet_multi_table_column_start_end_index(file, sheet_name, table_head_serial_num, column_start_idx, column_end_idx)
else:
if self.save_single_sheet_multi_table_column_start_end_index(file, sheet_name, table_head_serial_num, column_start_idx, column_end_idx):
table_head_serial_num = table_head_serial_num + 1
column_start_idx = column_idx + 1
else:
column_end_idx = column_idx + 1
if column_idx + 1 == len(colums):
column_end_idx = column_idx + 1
self.save_single_sheet_multi_table_column_start_end_index(file, sheet_name, table_head_serial_num, column_start_idx, column_end_idx)
# print(self.table_column_start_end)
def merge_multi_table_to_multi_sheet(self,file_path,sheet_name):
df = pd.read_excel(file_path, sheet_name=sheet_name)
for key in self.table_column_start_end.keys():
data = {}
start,end = self.table_column_start_end[key]
for s in range(start,end):
colunmn_name = re.sub('.d+', '' ,df.columns.values[s]) #将数量.1中".数字"去掉
data[colunmn_name] = list(df.values[:,s])
sheet = pd.DataFrame(data)
sheet.to_excel(self.workbook,sheet_name = key,index=False)
def merge_excel_proc(self):
for file in self.excels:
if self.exclude_new_create_execl(file.name):
#print("跳过{}".format(file.name))
continue
file_path = os.path.join(self.cur_path, file.name)
sheets = pd.ExcelFile(file_path).sheet_names
for sheet_name in sheets:
df = pd.read_excel(file_path, sheet_name=sheet_name)
if self.is_single_sheet_multi_table(df.columns.values):
try:
self.calc_single_sheet_multi_table_start_end_idx(file.name, sheet_name, df.columns.values)
self.merge_multi_table_to_multi_sheet(file_path, sheet_name)
except TypeError as e:
print("=*"*40)
print("n===>【 {}-{} 】解析失败,请人工检查<===".format(file.name, sheet_name))
print(e)
print("=*"*40)
print("n")
except:
print("未知异常")
else:
to_excel_sheet_name = re.sub('.xls[x]?', '-' ,file.name) + sheet_name
df.to_excel(self.workbook,sheet_name=to_excel_sheet_name, index=False)
self.workbook.save()
self.workbook.close()
def read_flag_excel_info(self):
sheets = pd.ExcelFile(self.target_excel).sheet_names
self.company = []
for index,sheet_name in enumerate(sheets):
df = pd.read_excel(self.target_excel, sheet_name=sheet_name)
for columns in df.columns.values:
if not self.is_match_security_name(columns): continue
self.company.extend(df[columns]) #保存目标公司名称
break
def is_match_security_name(self, security_name):
security_name_list = ['证券名称','证券简称', '股票','股票公司']
if security_name in security_name_list:return True
return False
def get_table_head_deadline(self, columns):
deadline_time_keys = ["期限(天)", "期限(天)", "期限", "最长可使用天数", "出借期限", "合约期限(天)"]
for column_idx, columns in enumerate(columns):
if columns in deadline_time_keys:
return (column_idx, columns)
return None
def get_table_special_head_deadline(self, df, rowIdx):
speci_time_rule = r'(d+)s*[((]?天[))]?'
deadline_time = ''
publish_quantity = ''
for column_idx, columns in enumerate(df.columns.values):
mm = re.findall(speci_time_rule, columns)
if len(mm) > 0:
deadline_time = deadline_time + mm[0] + '/'
publish_quantity = publish_quantity + str(df.values[rowIdx, [column_idx]][0]) + '/'
#print('===={}-{}'.format(deadline_time, publish_quantity))
return (deadline_time, publish_quantity)
def get_publish_quantity_index(self, columns):
publish_quantity_keys = ["数量上限", "数量上限", "潜在可出借(股)", "数量", "预计市值(千万元)","委托数量","预计规模"]
for column_idx, columns in enumerate(columns):
if columns in publish_quantity_keys:
return (column_idx, columns)
return None
def rebuild_match_row(self, company_name, df, rowIdx, publish_quantity_column, deadline_time_column):
rebuild_row = []
rebuild_row.append('')
rebuild_row.append(company_name)
if publish_quantity_column != None:
rebuild_row.extend(df.values[rowIdx, [publish_quantity_column[0]]])
else:
rebuild_row.extend(df.values[rowIdx])
if deadline_time_column != None:
rebuild_row.extend(df.values[rowIdx, [deadline_time_column[0]]])
else:
rebuild_row.extend(df.values[rowIdx])
return rebuild_row
def rebuild_match_head(self, sheet_name, security_name, publish_quantity_column, deadline_time_column):
rebuild_head = []
rebuild_head.append(sheet_name)
rebuild_head.append(security_name)
if publish_quantity_column != None:
rebuild_head.append(publish_quantity_column[1])
else:
rebuild_head.append('数量')
if deadline_time_column != None:
rebuild_head.append(deadline_time_column[1])
else:
rebuild_head.append('期限')
return rebuild_head
def save_match_company_info(self):
merge_sheets = pd.ExcelFile(self.merge_excel).sheet_names
self.match_company = []
for sheet_name in merge_sheets:
df = pd.read_excel(self.merge_excel, sheet_name=sheet_name)
is_find_match_company = False
match_company_info = []
security_name = "证券名称"
publish_quantity_column = self.get_publish_quantity_index(df.columns.values)
deadline_time_column = self.get_table_head_deadline(df.columns.values)
for column_idx, columns in enumerate(df.columns.values):
if not self.is_match_security_name(columns): continue
for company in self.company:
for rowIdx, company_name in enumerate(df[columns]):
if company == company_name:
is_find_match_company = True
rebuild_row = []
deadline_time, publish_quantity = self.get_table_special_head_deadline(df, rowIdx)
if len(deadline_time) > 0 and len(publish_quantity) > 0:
rebuild_row.append('')
rebuild_row.append(company_name)
rebuild_row.append(publish_quantity)
rebuild_row.append(deadline_time)
elif publish_quantity == None or deadline_time_column == None:
rebuild_row.append('')
rebuild_row.append(company_name)
rebuild_row.append('')
rebuild_row.append('')
else:
rebuild_row = self.rebuild_match_row(company_name, df, rowIdx, publish_quantity_column, deadline_time_column)
match_company_info.extend([rebuild_row])
if is_find_match_company:
rebuild_head = self.rebuild_match_head(sheet_name, security_name, publish_quantity_column, deadline_time_column)
self.match_company.extend([rebuild_head])
merge_repeat = self.merge_repeat_info(match_company_info)
for company in merge_repeat.keys():
one_company = []
one_company.append('')
one_company.append(company)
merge_repeat[company]["数量"]= re.sub(r'//', "", merge_repeat[company]["数量"])
merge_repeat[company]["期限"]= re.sub(r'//', "", merge_repeat[company]["期限"])
#print({"company": company,"数量":merge_repeat[company]["数量"], "期限":merge_repeat[company]["期限"]})
if merge_repeat[company]["数量"].endswith('/'):
merge_repeat[company]["数量"] = merge_repeat[company]["数量"].rpartition('/')[0]
if merge_repeat[company]["期限"].endswith('/'):
merge_repeat[company]["期限"] = merge_repeat[company]["期限"].rpartition('/')[0]
one_company.append(merge_repeat[company]["数量"])
one_company.append(merge_repeat[company]["期限"])
self.match_company.extend([one_company])
self.match_company.extend([''])
if len(self.match_company) > 0:
data=pd.DataFrame(self.match_company)
data.to_excel(self.save_wb, sheet_name="匹配结果",index=False, header=None)
self.save_wb.save()
self.save_wb.close()
def merge_repeat_info(self, match_company_info):
merge_repeat = {}
for info in match_company_info[0:]:
_, company_name, _, _ = tuple(info)
merge_repeat[company_name] = company_name
merge_repeat[company_name] ={"数量":'', "期限":''}
for info in match_company_info[0:]:
_, company_name, quantity, deadline = tuple(info)
quantity = merge_repeat[company_name]["数量"] + str(quantity) + "/"
deadline = str(deadline)
if '/' not in deadline:
if deadline not in merge_repeat[company_name]["期限"]:
deadline = merge_repeat[company_name]["期限"] + str(deadline) + "/"
else:
continue
else:
for dl in deadline.split('/'):
dl = str(dl)
if dl != '' and dl not in merge_repeat[company_name]["期限"]:
merge_repeat[company_name]["期限"] = merge_repeat[company_name]["期限"] + str(dl) + "/"
deadline = merge_repeat[company_name]["期限"]
merge_repeat[company_name] ={"数量":quantity, "期限":deadline}
return merge_repeat
if __name__ == '__main__':
# ExeclProc 第一参数:表示目标
# 第二个参数:新建总表名字,用于保存所有表格中sheet合并结果
# 第三个参数:新建匹配结果表,用于保存匹配目标股票公司信息
print('n=========================匹配开始============================n')
match_result = '匹配结果.xlsx'
excel = ExeclProc('目标匹配股票公司.xlsx', '汇总表.xlsx', match_result)
excel.read_flag_excel_info()
excel.merge_excel_proc()
excel.save_match_company_info()
print('=========================匹配完成============================n')
print('======================请到 [{}] 查看匹配结果====================='.format(match_result))
time.sleep(3)
sys.exit(0)
最后
以上就是大方红牛最近收集整理的关于【Python】pandas合并Excel和匹配查找并输出匹配结果一:目标匹配股票公司.xlsx,一个sheet,一张表二:招商.xlsx sheet0,有额外的无效列sheet3 三张表,两表中间间隔不同,表从头开始sheet4 三张表, 表的位置不是从头开始三: 中金.xlsx 四:汇总表.xlsx,合并效果如下五:匹配结果.xlsx,匹配结果如下:六:代码如下的全部内容,更多相关【Python】pandas合并Excel和匹配查找并输出匹配结果一:目标匹配股票公司.xlsx,一个sheet,一张表二:招商.xlsx内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复