目录
一、网络连接
二、网络爬虫基本流程
1. 发起请求
2. 获取响应内容
3. 解析数据
4. 保存数据
三、浏览器F12的运用
1. 选择按钮
2. Elements元素按钮
3. Network网络捕捉按钮
4. 用户代理(重点)
5. 用户代理设置
四、查看网页源码的另外一个方式
一、网络连接
网络连接像是在自助饮料售货机上购买饮料一样:购买者只需选择所需饮料,投入硬币(或纸币),自助饮料售货机就会弹出相应的商品。如下图示,计算机(购买者)带着请求头和消息体(硬币和所需饮料)向服务器(自助饮料售货机)发起一次Request请求(购买),相应的服务器(自助饮料售货机)会返回本计算机相应的HTML文件作Response(相应的商品)。

对于学习爬虫技术,我们只需知道最基本的网络连接原理即可。计算机一次Request请求和服务器端的Response回应,即实现了网络连接。
二、网络爬虫基本流程
知道网络连接的基本原理后,爬虫原理就很好理解了。网络爬虫是指按照一定规则获取网络信息的程序。也可以这样说,爬虫是通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。爬取程序的基本流程如下:
1. 发起请求
通过URL模拟计算机向服务器发送Request请求,并等待服务器响应。
2. 获取响应内容
当服务器正常响应时,会返回服务器端的Response,即URL,对应的页面内容。
3. 解析数据
返回的页面内容可能是HTML、JSON字符串、二进制数据等类型,需要采用不同的方法进行处理。
4. 保存数据
解析后的数据可以保存成多种形式的数据,例如文本、数据库或其他特定类型的文件。
三、浏览器F12的运用
学习网络爬虫,我们首先需要一个浏览器,推荐使用谷歌浏览器(百度搜索谷歌浏览器,然后在官网https://www.google.cn/chrome/下载即可)。然后打开谷歌浏览器(其它浏览器也行)按下电脑F12键,出现下图所示内容。
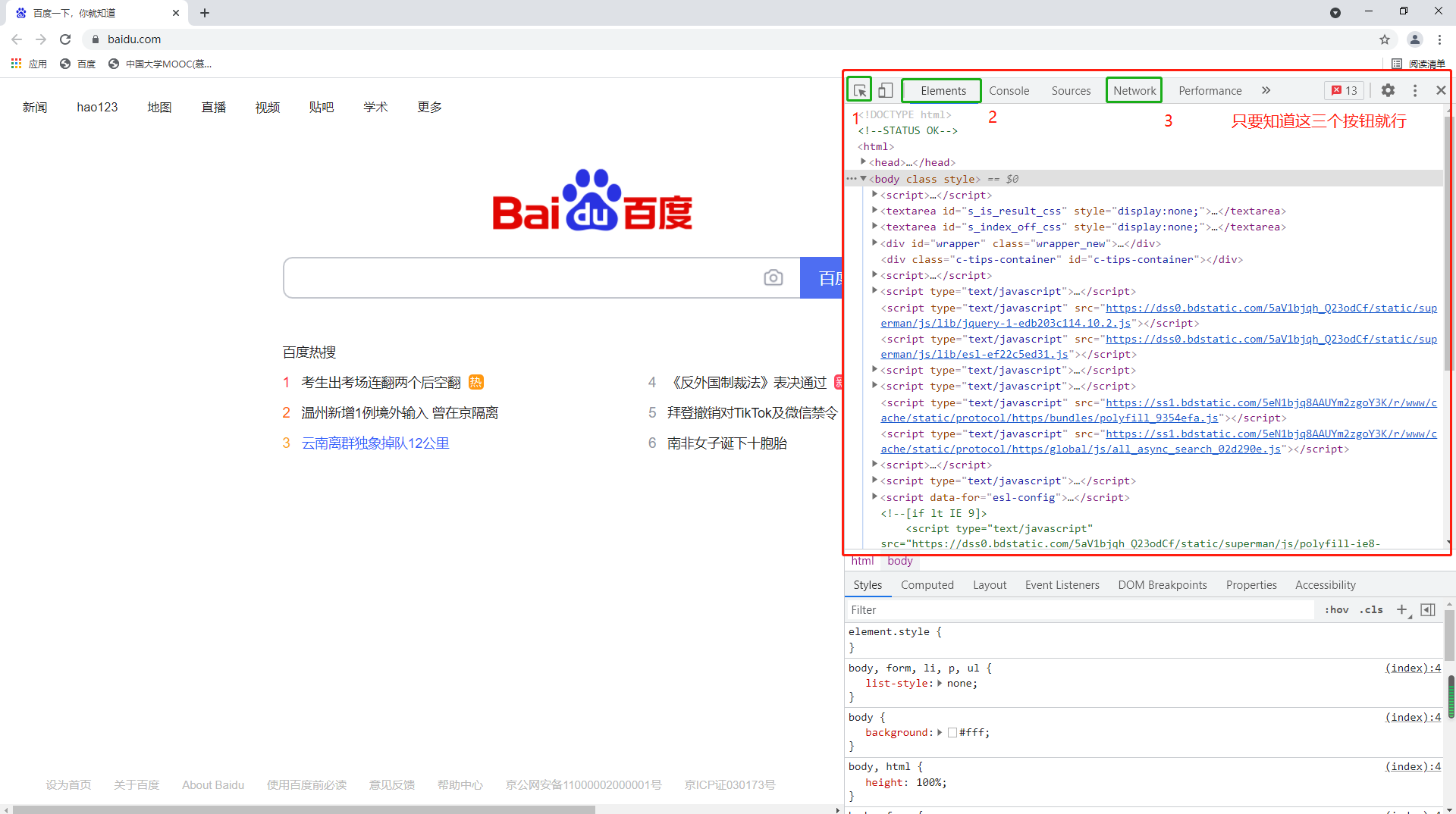
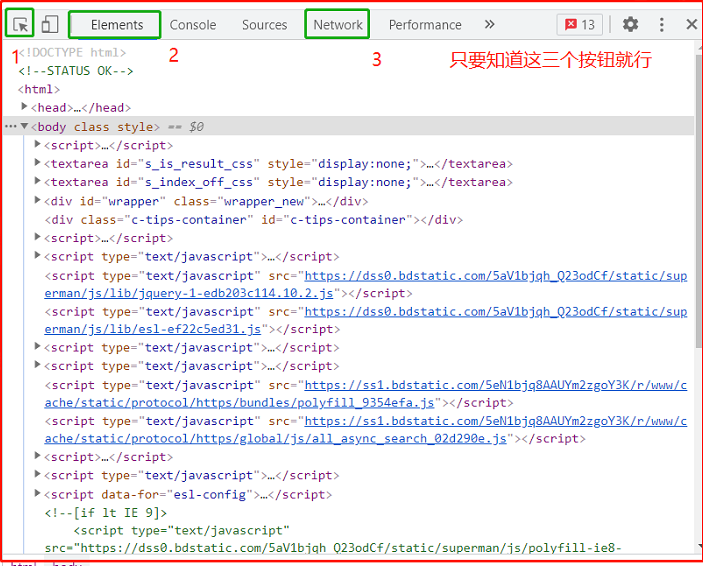
按住F12弹出来的内容,叫做开发者工具,是爬虫工程师的利器,我们只要会用下图这三个按钮就够了。
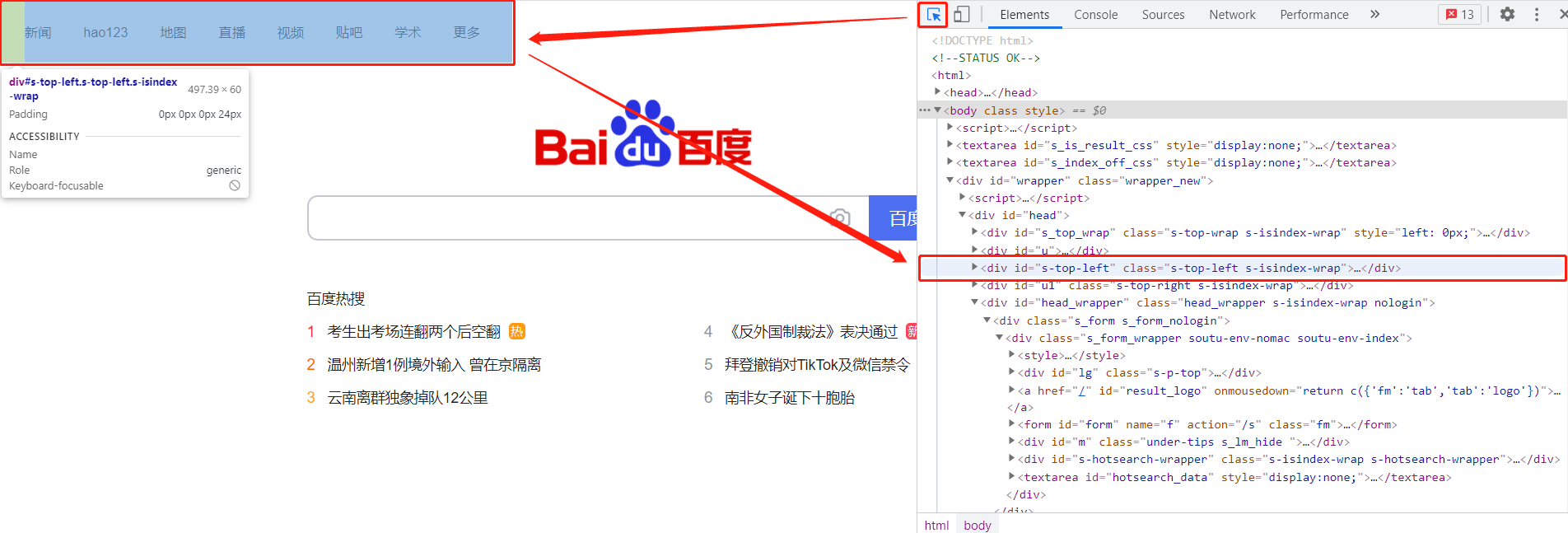
1. 选择按钮
我们点击一下它,发现选择按钮变成蓝色了,然后让鼠标在页面上移动,我们会发现页面上的颜色也会发生相应的改变。与此同时,Elements元素按钮里的内容就会随之发生变化如下图:
下面我们在选择按钮处于蓝色状态的时候,点击一下第一个标题,这时候选择按钮再次变成灰色,而Elements里的内容也不再变动,此时我们可以看到:
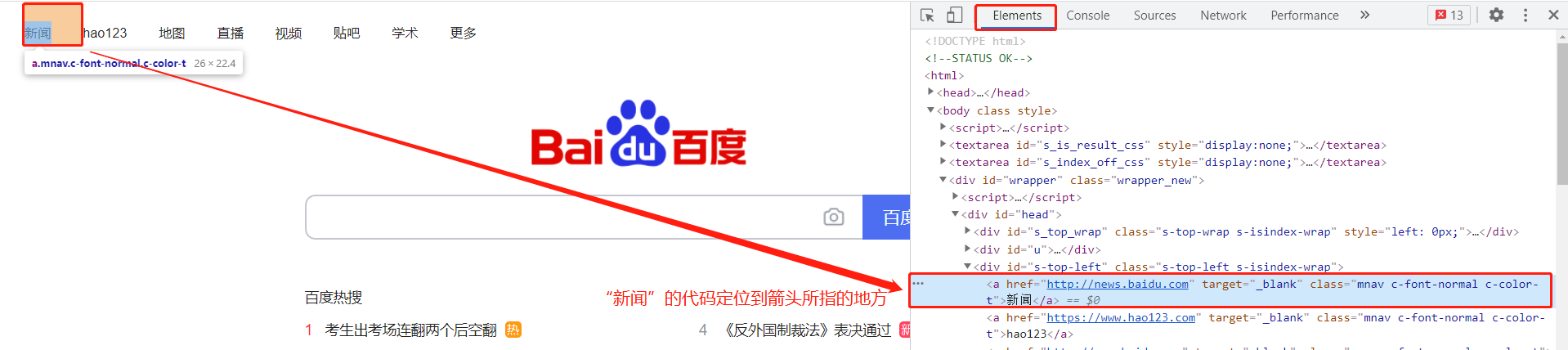
2. Elements元素按钮
元素按钮里面的内容就是网站的源码,我们最后爬虫爬到的内容也是这个样子。在上图新闻那个地方鼠标双击俩下,这两个字变成可编辑的格式了!同理,我们可以改其它几个内容,如下图:改完之后,我们可以看到这个网页最上面一栏出现“很高兴遇见你!”一行字,这一行字就是我们刚刚在源码那里改的文字。
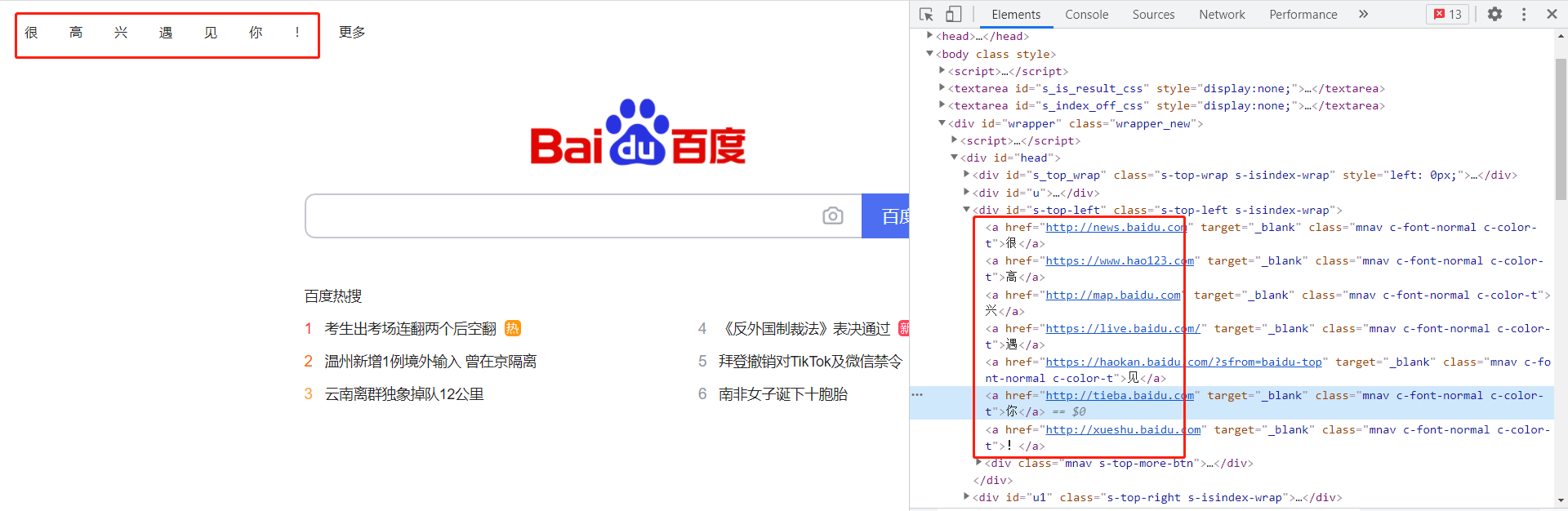
我们还可以用同样的操作,先选择选择按钮,点击下面的腾讯股价:
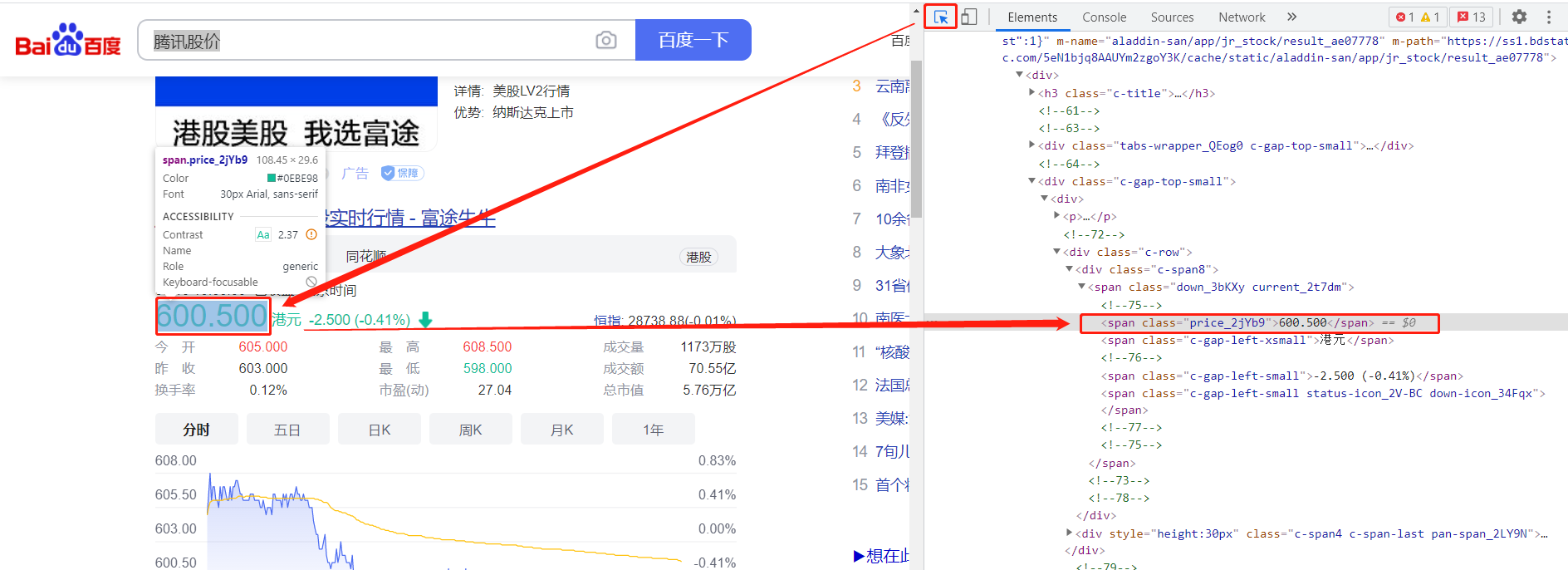
用同样的方法在Elements里对这个数字进行修改,可以改成任何你想改的数据,比如改成:
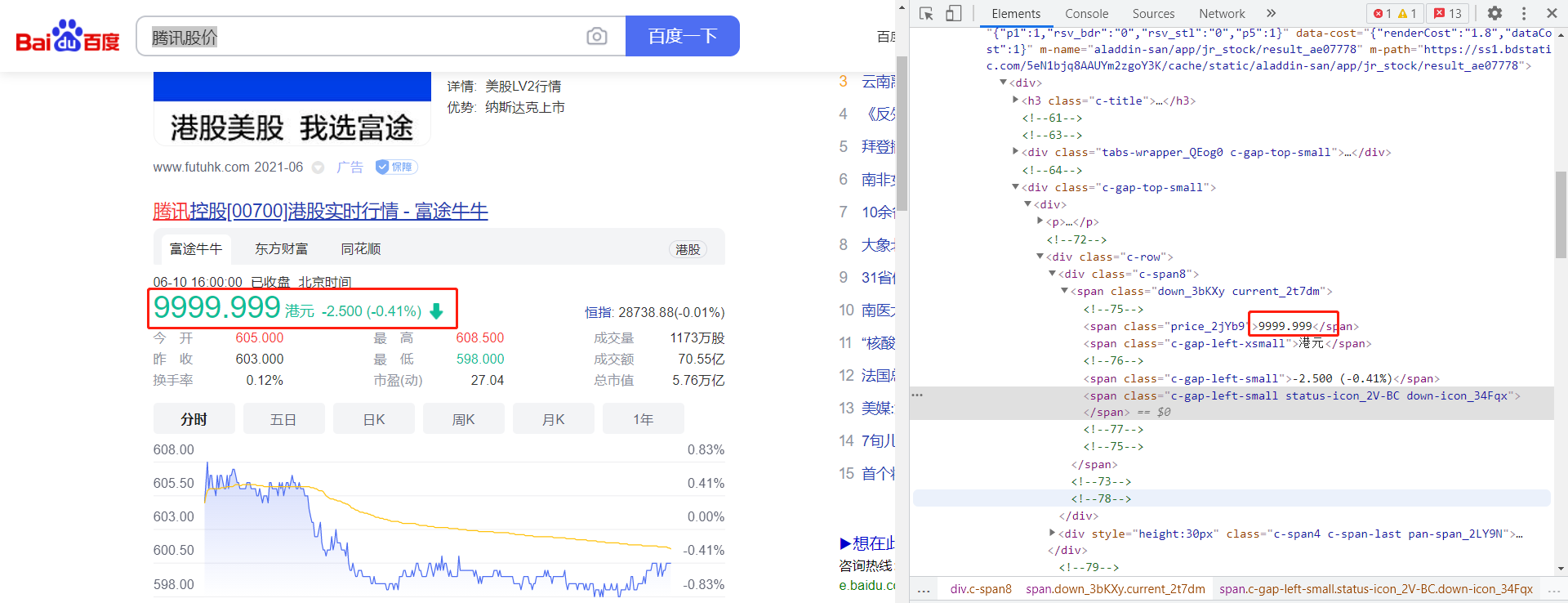
(从这张图我们要明白,有时候很多图片是可以造假的,骗子可以用这些造假的图片来诈骗你,让你上当受骗。在信息爆炸的时代,我们要学会辨别信息的真和假。)
总结:利用选择按钮和Elements元素按钮我们就可以获取我们想获取内容的在源码中的文本格式以及所在位置了。
3. Network网络捕捉按钮
切换到Network选项卡,随后重新刷新页面,可以发现这里多了很多内容,这些内容其实都是我们看到的这个网址上的子网址。
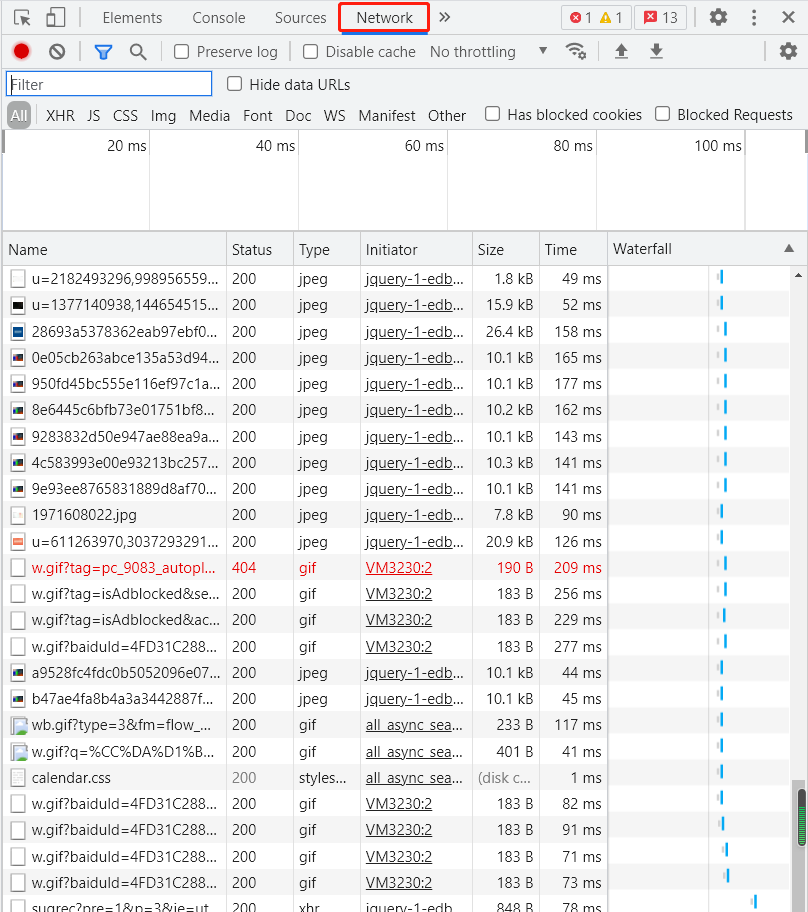
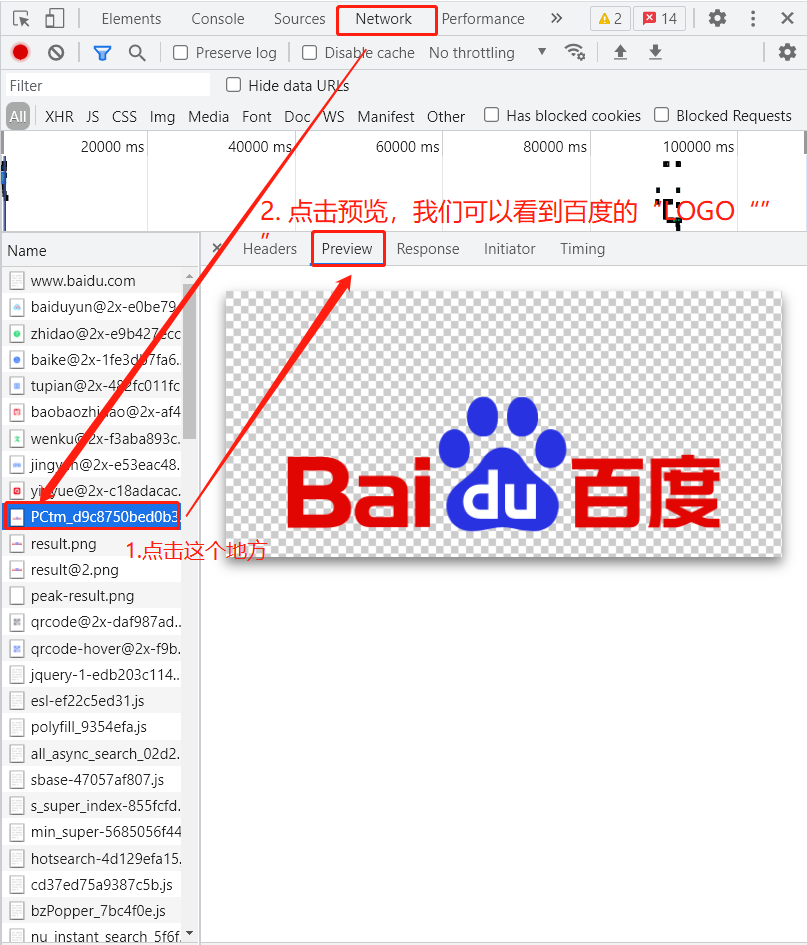
我们把滚轴拖到最上面,点击图中所示的地方,发现右边会弹出一些框,选择Prewiew,我们可以看到它就是baidu的logo。
4. 用户代理(重点)
(1)基本原理
首先来看什么是代理。代理实际上指的就是代理服务器(Proxy Server),它的功能是代理网络用户获取网络信息。形象地说,代理服务器就是网络信息的中转站。
在用户正常请求一个网站时,发送了请求给Web服务器,Web服务器把响应传回给用户。如果设置了代理服务器,实际上就是在本机和服务器之间搭建了一个桥,此时本机不是直接向Web服务器发起请求,而是向代理服务器发起请求,请求会发送给代理服务器,然后由代理服务器再发送给Web服务器,接着由代理服务器把Web服务器返回的响应转发给本机。
这样用户同样可以正常访问网页,但在这个过程中,Web服务器识别出的真实P就不再是用户本机的IP了,成功实现了IP伪装,这就是代理的基本原理。
(2)代理的作用
(1)代理可以突破自身IP访问限制,访问一些平时不能访问的站点,比如网上常说的翻墙、科学上网之类就是使用了代理技术。
(2)使用代理可以访问一些单位或团体的内部资源。比如使用的如果是教育网内地址段的免费代理服务器,就可以对教育网开放各类FTP下载、上传,以及各类资料查询、共享等服务。
(3)使用代理可以提高访问速度。通常代理服务器都会设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也会将其保存到缓冲区中,当其他用户再访问相同的信息时,则直接从缓冲区中取出信息传给用户,以提高访问速度。
(4)使用代理可以隐藏真实IP,上网者可以通过代理服务隐藏自己的IP,进而免受攻击。对于爬虫来说,使用代理就是为了隐藏自身IP,防止自身的1P被封锁。因为通常大数据量的访问会引起对方主机的怀疑,从而有可能造成封锁IP的访问权限。
(3)寻找用户代理
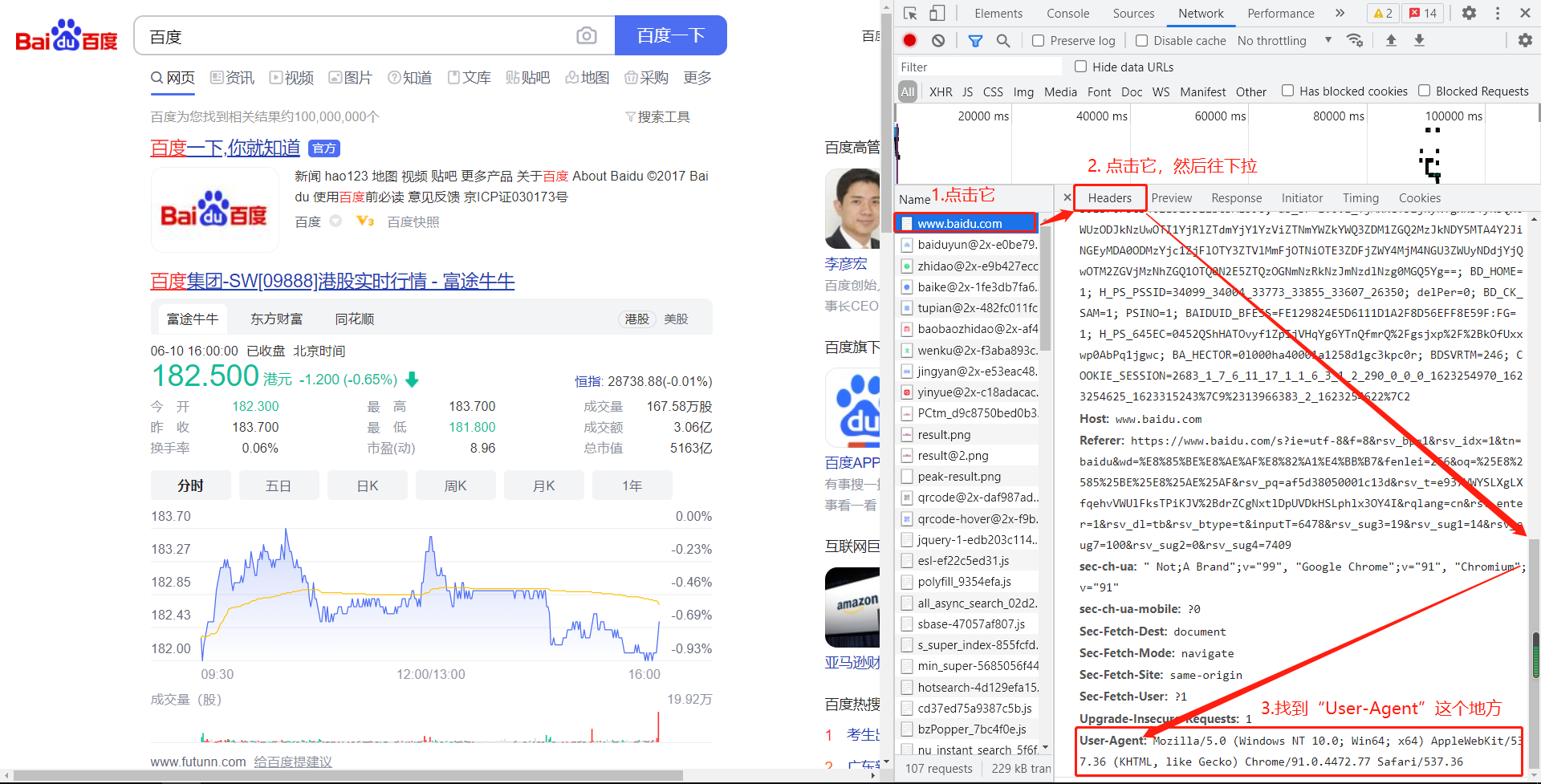
(这里是重中之重的重点!!!)我们把滚轴滚到最上面,然后选择第一个百度的网址,然后选择右边的Headers,然后一直往下拉,在Request Headers下面我们会看到有一行叫做User-Agent,它其实就是证明了你是在通过一个浏览器在访问这个网址,这是浏览器的一个代号,当你访问别的网站的时候这个User-Agent是不变的。
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
大多时候我们理解的网址是:www.baidu.com,但其实在编程里或者它真实的名字其实是:https://www.baidu.com它前面有个“https://”这个叫做https协议(超文本传输协议)。如果我们在Python里输入www.baidu.com 它是不认识的,我们必须要加上“https://”加上才行,如下面所示。我们也可以直接使用浏览器访问该网址,然后把链接复制下来就行。
import requests
url = 'https://www.baidu.com/'
res = requests.get(url)
print(res.text)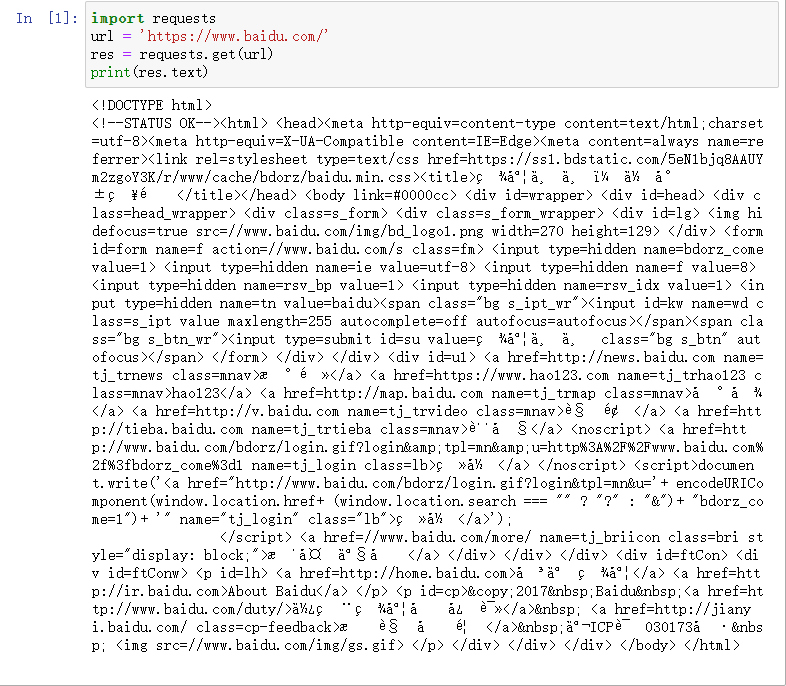
5. 用户代理设置
# coding:utf8
import requests # 用来模拟浏览器发送网络请求
# 用户代理设置
header = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
url = 'https://www.baidu.com/'
response = requests.get(url, headers=header)
r = response.text
print(r)
四、查看网页源码的另外一个方式
除了F12键,另外一个获取网页源码的方式是在网页上右击选择“查看网页源代码”,就可以获取这个网址的源代码,这个基本就是我们python爬取到的最终信息。用鼠标上下滚动,就能看到很多内容。我们不需要关心那些英文或者网页框架是什么,只需要知道我们想要获取的中文在哪里就行了。
最后
以上就是专注外套最近收集整理的关于1. Python网络爬虫基本介绍的全部内容,更多相关1.内容请搜索靠谱客的其他文章。








发表评论 取消回复