GMM和DNN都拟合一个观测序列的概率分布,然后作为HMM的观测状态概率矩阵B。
GMM-HMM建模能力有限,无法准确的表征语音内部复杂的结构,所以识别率低;用DNN代替GMM来进行观察状态概率的输出,实现DNN-HMM声学模型框架,大大提高了识别率。
GMM是生成模型,采用无监督学习,DNN是判别模型,采用有监督学习。
GMM对HMM中的后验概率的估计需要数据发布假设,同一帧元素之间需要相互独立,因此GMM-HMM使用的特征是MFCC,这个特征已经做了去相关性处理。
DNN-HMM不需要对声学特征所服从的分布进行假设,使用的特征是FBank,这个特征保持着相关性。
DNN的输入可以采用连续的拼接帧,因而可以更好地利用上下文的信息。
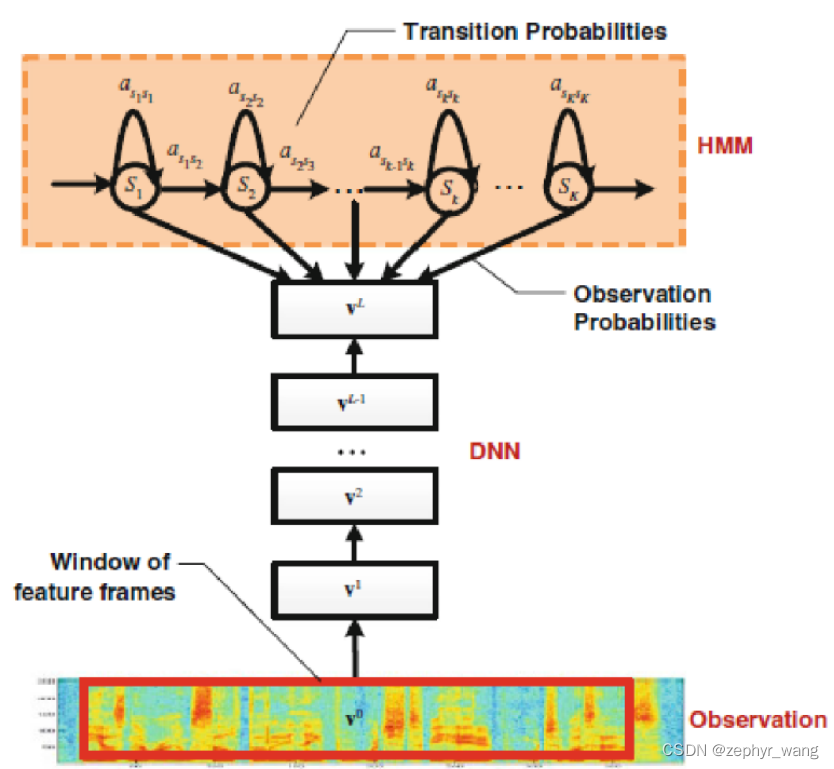
GMM-HMM参见:https://blog.csdn.net/zephyr_wang/article/details/127655618
最后
以上就是土豪台灯最近收集整理的关于语音识别DNN-HMM的全部内容,更多相关语音识别DNN-HMM内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复