前言
当前主流的语音识别大厂有科大讯飞、百度、谷歌等,但在他们官网中发现,支持java离线版的并不多,科大讯飞离线包仅基于安卓,而百度官方并没有离线版的,所以在资源查找中筛选出VOSK、CMU Sphinx,并且两者都是开源的,但CMU Sphinx官网中并没有中文模型,所以在选用上选择了VOSK.
一、VOSK是什么?
Vosk是言语识别工具包。Vosk最好的事情是:
1.支持二十+种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语,越南语,意大利语,荷兰人,加泰罗尼亚语,阿拉伯, 希腊语, 波斯语, 菲律宾语,乌克兰语, 哈萨克语, 瑞典语, 日语, 世界语
2.移动设备上脱机工作-Raspberry Pi,Android,iOS
3.使用简单的 pip3 install vosk 安装
4.每种语言的手提式模型只有是50Mb, 但还有更大的服务器模型可用
提供流媒体API,以提供最佳用户体验(与流行的语音识别python包不同)
5.还有用于不同编程语言的包装器-java / csharp / javascript等
6.可以快速重新配置词汇以实现最佳准确性
7.支持说话人识别
二、使用步骤
1.环境准备
因为该资源底层是c开发的,所以需要下载vcredist;
2.maven依赖
代码如下(示例):
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>5.7.0</version>
</dependency>
<dependency>
<groupId>com.alphacephei</groupId>
<artifactId>vosk</artifactId>
<version>0.3.32</version>
</dependency>
如果导入失败可以下载jar,build path一下;
3.语言模型
官网地址
https://alphacephei.com/vosk/models
下载想用的语言模型,如果是中文的话推荐:
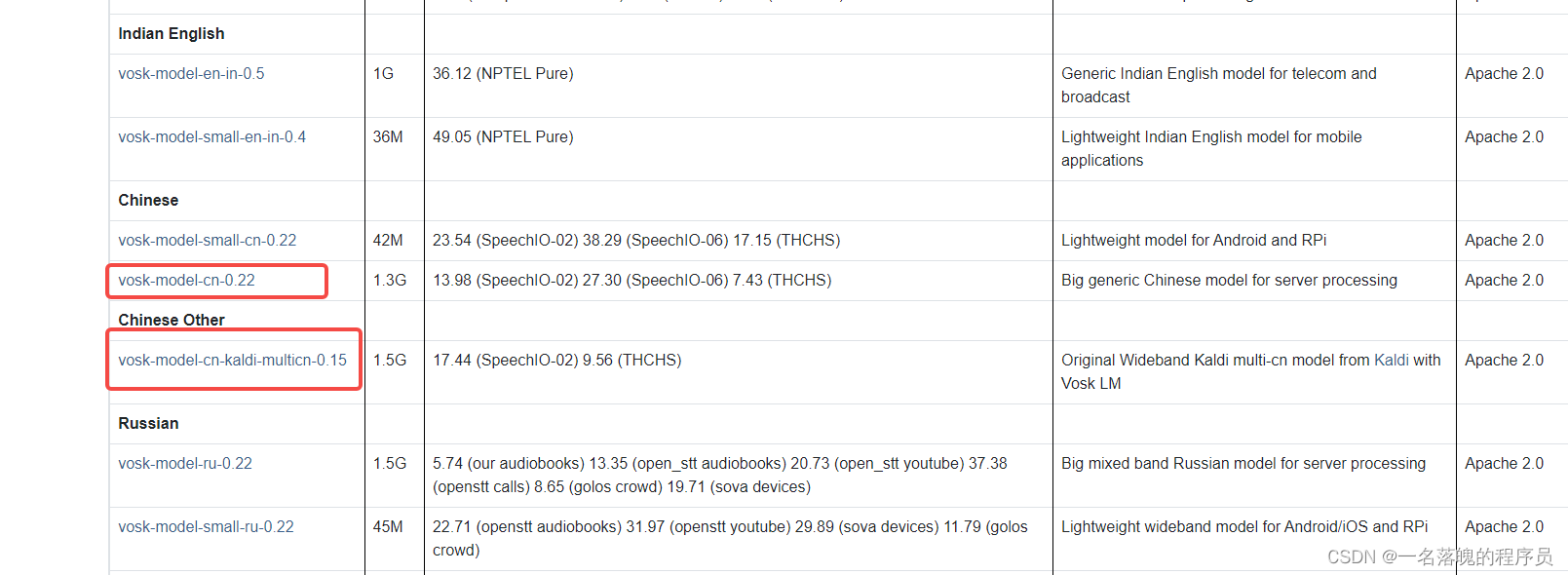
4.运行代码
将官方给出的demo添加到项目中,其中需要更改的是给的DecoderDemo,这个是调用方法,
public static void main(String[] argv) throws IOException, UnsupportedAudioFileException {
LibVosk.setLogLevel(LogLevel.DEBUG);
try (Model model = new Model("model");//该段是下载的模型路径 如 D:\vosk-model-small-cn-XXX
InputStream ais = AudioSystem.getAudioInputStream(new BufferedInputStream(new FileInputStream("cn.wav")));//该段是要转的语言文件,仅支持wav
Recognizer recognizer = new Recognizer(model, 12000)) {//该段中12000是语言频率,需要大于8000,可以自行调整
int nbytes;
byte[] b = new byte[4096];
while ((nbytes = ais.read(b)) >= 0) {
if (recognizer.acceptWaveForm(b, nbytes)) {
System.out.println(recognizer.getResult());
} else {
System.out.println(recognizer.getPartialResult());
}
}
System.out.println(recognizer.getFinalResult());
}
}
总结
这个开源最大的不足是有点慢,如果你们有合适的开源资源记得推荐一下。
最后
以上就是潇洒康乃馨最近收集整理的关于纯java离线版语音转文字前言一、VOSK是什么?二、使用步骤的全部内容,更多相关纯java离线版语音转文字前言一、VOSK是什么内容请搜索靠谱客的其他文章。








发表评论 取消回复