GitHub
python3网络爬虫开发实战第二版——8.1
环境问题
安装
1.参考:Tesserocr 的安装 | 静觅
在 Windows 下,首先需要下载 Tesseract,它为 Tesserocr 提供了支持…
2.官方GitHub
从simonflueckiger/tesserocr-windows_build/releases下载与您的 Windows 平台和 Python 安装相对应的轮文件,并通过以下方式安装它们:
pip install <package_name>.whl
目前最高支持python3.7
验证一下
1
ImportError: cannot import name ‘_imaging’ from ‘PIL’ (C:Anaconda3libsite
重新安装 Pillow 包
pip uninstall Pillow
pip install Pillow
2
Traceback (most recent call last):
File "H:/project/python/爬虫/08 验证码识别/8.1 OCR.py", line 4, in <module>
print(tesserocr.image_to_text(image))
File "tesserocr.pyx", line 2443, in tesserocr._tesserocr.image_to_text
RuntimeError: Failed to init API, possibly an invalid tessdata path: C:Anaconda3/tessdata/
参考:RuntimeError: Failed to init API, possibly an invalid tessdata path: C:User_回忆不说话的博客-CSDN博客
把 tessdata 文件夹复制到 C:Anaconda3下即可
基础
参考:Tesserocr 的安装 | 静觅

首先利用 Image 读取了图片文件,然后调用了 tesserocr 的 image_to_text () 方法,再将将其识别结果输出。
import tesserocr
from PIL import Image
image = Image.open('image.png')
print(tesserocr.image_to_text(image)) # 没识别出来就是输出空
output:6869
还可以直接调用 file_to_text () 方法
import tesserocr
print(tesserocr.file_to_text('image.png'))
灰度化
去除干扰点

import tesserocr
from PIL import Image
image = Image.open('image2.png')
print(tesserocr.image_to_text(image))
output:3 2e i)
先查看图片的类型
from PIL import Image
import numpy as np
image = Image.open('image2.png')
print(np.array(image).shape) # (38, 112, 4) 4通道,具有透明通道的彩色图片
print(image.mode) # RGBA A是透明通道
image.convert(‘L’) 把RBGA转为更简单的L,即把图片转化为灰度图像
image = Image.open('image2.png')
image = image.convert('L') # L 灰度 0-255 越小越黑;1 二值化
threshold = 100 # 阈值 一般大于100 小于200 太大太小都可能识别不成功
array = np.array(image)
array = np.where(array > threshold, 255, 0) # 灰度大于阈值设置为255(白色),小于设置为0(黑色)
image = Image.fromarray(array.astype('uint8'))
image.save('image2_done.png')
# image.show()
print(tesserocr.image_to_text(image)) #32ec
image2_done.png
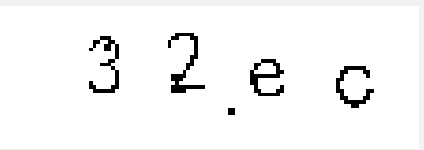
识别实战
参考:python中retry的用法_70大盗-CSDN博客_python retry
retry()在这里的功能,是在其装饰的函数运行报错后重新运行该函数
stop_max_attempt_number:在停止之前尝试的最大次数,最后一次如果还是有异常则会抛出异常,停止运行,默认为5次
wait_random_min:在两次调用方法停留时长,停留最短时间,默认为0,单位毫秒
wait_random_max:在两次调用方法停留时长,停留最长时间,默认为1000毫秒
retry_on_result:指定一个函数,如果指定的函数返回True,则重试,否则抛出异常退出
retry_on_exception: 指定一个函数,如果此函数返回指定异常,则会重试,如果不是指定的异常则会退出
import time
import re
import tesserocr
from selenium import webdriver
from io import BytesIO
from PIL import Image
from retrying import retry
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
import numpy as np
threshold = 120 # 阈值
def preprocess(image):
'''
处理图片
:param image: 图片对象
:return: 处理后的图片对象
'''
image = image.convert('L')
array = np.array(image)
array = np.where(array > threshold, 255, 0)
image = Image.fromarray(array.astype('uint8'))
# image.save('1.png')
# image.show()
return image
@retry(stop_max_attempt_number=10, retry_on_result=lambda x: x is False)
def login():
browser.get('https://captcha7.scrape.center/')
browser.find_element_by_css_selector('.username input').send_keys('admin') # 用户名
browser.find_element_by_css_selector('.password input').send_keys('admin') # 密码
captcha = browser.find_element_by_css_selector('#captcha') # 验证码
image = Image.open(BytesIO(captcha.screenshot_as_png)) # 先截取验证码图片,然后转化为图片对象
image = preprocess(image)
captcha = tesserocr.image_to_text(image) # 识别验证码
print('处理前:', captcha)
captcha = re.sub('[^A-Za-z0-9]', '', captcha) # 去除非字母和数字的字符
print('处理后:', captcha)
# 这里 '.captcha input'不行 不知道为啥?
browser.find_element_by_css_selector('.captcha input[type="text"]').send_keys(captcha) # 写入验证码
browser.find_element_by_css_selector('.login').click() # 点击登录
try:
WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH, '//h2[contains(text(),"登录成功")]')))
# WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH, '//h2[contains(., "登录成功")]')))
time.sleep(5)
browser.close()
print('登陆成功')
print('---'*10)
return True
except TimeoutException:
print('登陆失败')
print('---'*10)
return False
if __name__ == '__main__':
browser = webdriver.Chrome()
login()
处理前: 40b6
处理后: 40b6
登陆失败
------------------------------
处理前: “4 4F
处理后: 44F
登陆失败
------------------------------
处理前: 3 5b Oo
处理后: 35bOo
登陆失败
------------------------------
处理前: 47406
处理后: 47406
登陆失败
------------------------------
处理前: OF Ob
处理后: OFOb
登陆失败
------------------------------
处理前: “3dad
处理后: 3dad
登陆失败
------------------------------
处理前: 2% 67
处理后: 267
登陆失败
------------------------------
处理前: 42ad
处理后: 42ad
登陆失败
------------------------------
处理前: © BASE
处理后: BASE
登陆失败
------------------------------
处理前: 8947
处理后: 8947
登陆成功
------------------------------
进程已结束,退出代码为 0
最后
以上就是任性红酒最近收集整理的关于【爬虫】学习:OCR识别图形验证码环境问题基础灰度化识别实战的全部内容,更多相关【爬虫】学习内容请搜索靠谱客的其他文章。








发表评论 取消回复