点击上方“AI算法修炼营”,选择加星标或“置顶”
标题以下,全是干货
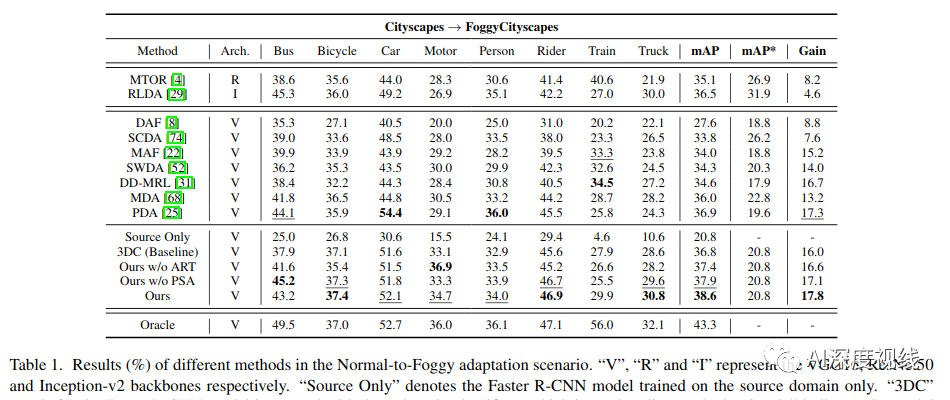
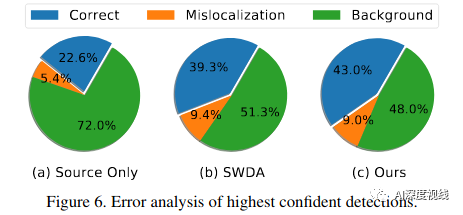
性能优于PDA、MDA和SWDA等网络。
作者团队:北京航空航天大学
1
引言

近年来,在基于深度学习的目标检测中见证了巨大的进步。但是,由于domain shift问题,将现成的检测器应用于未知的域会导致性能显著下降。为了解决这个问题,本文提出了一种新颖的从粗到精的特征自适应方法来进行跨域目标检测。
在粗粒度阶段,与文献中使用的粗糙图像级或实例级特征对齐不同,采用注意力机制提取前景区域,并通过多层对抗学习根据边缘分布对边缘区域进行对齐。
在细粒度阶段,通过最小化具有相同类别但来自不同域的全局原型的距离来进行前景的条件分布对齐。
由于这种从粗到细的特征自适应,前景区域中的领域知识可以有效地传递。在各种跨域检测方案中进行了广泛的实验,结果证明了所提出方法的广泛适用性和有效性。
2
主要思路及贡献
针对的问题:
目前的CNN模型在直接应用于新场景时,由于存在所谓的"域移位"或"数据集偏置"现象,导致性能下降。
主要思路
本文作者提出了一个由粗到精的跨域目标检测的特征自适应框架。如下图所示:
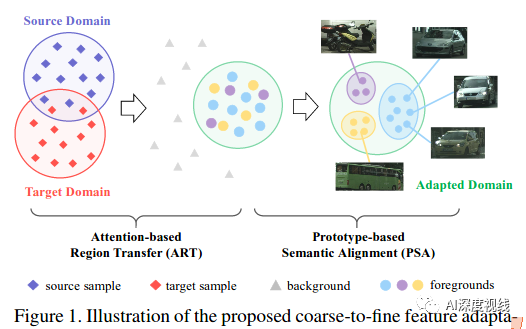
问题一:考虑到与背景相比,不同域之间的前景具有很多的共同特征。
作者提出了一个基于注意力的区域转移(ART)模块来突出前景的重要性,它以一种不区分类的粗糙方式工作。利用高级特征中的注意机制提取感兴趣的前景目标,并在特征分布对齐时对其进行标记。通过多层对抗性学习,利用复杂的检测模型可以实现有效的领域交叉。
问题二:对象的类别信息会进一步细化前面的自适应特征,在这种情况下,需要区分不同种类的前景目标。不过这在某些batch中可能会出现目标不匹配的情况,这使得UDA的语义匹配比较困难。
作者使用了一个基于原型的语义对齐(PSA)模块来构建跨域的每个类别的全局原型。原型在每次迭代中都进行自适应更新,从而抑制了假伪标签和类不匹配的负面影响。
主要贡献:
•设计了一种新的由粗到精的自适应方法,用于跨域两阶段目标检测,逐步准确地对齐深度特征。
•提出了两个自适应模块,基于注意的区域转移(ART)和基于原型的语义对齐(PSA)方法,利用类别信息学习前景区域的领域知识。
•针对一些典型的场景,在三个主要的基准上进行了大量的实验,结果是最先进的,证明了所提方法的有效性。
3
网络架构
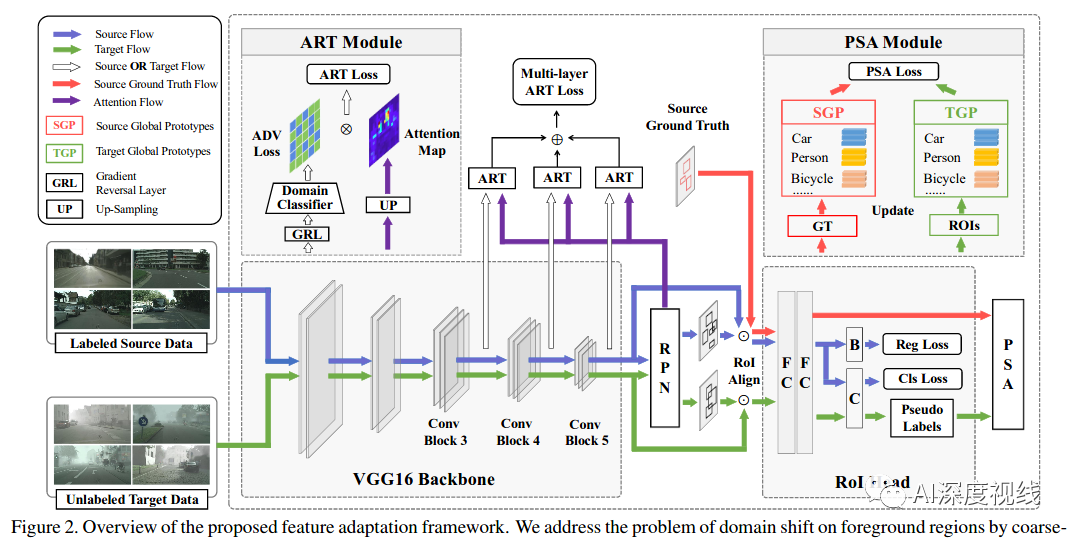
如上图所示,介绍了本文用于跨域对象检测的功能适配框架,包含一个检测网络和两个适配模块。
3.1 检测网络 backbone
作者选了功能强大的Faster R-CNN 作为基础检测器backbone。Faster R-CNN 是一个两阶段的检测器,由三个主要组件组成:1)提取图像特征的骨干网络G,2)同时预测对象范围和对象得分的区域提议网络(RPN),以及3)兴趣(RoI)头,包括边界框回归器B和分类器C以进行进一步细化.Faster R-CNN的整体损失函数定义为:
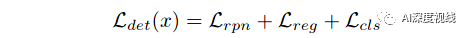
3.2 适配模块 Adaptation Modules
思路来源:
与大多数现有研究(通常会减少整个特征空间中的域偏移)不同,作者采用的方法是在各个域之间共享更多共同属性的前景上进行特征对齐。同时,与当前将所有目标的样本视为一个整体的方法相反,作者认为类别信息有助于完成此任务,从而突出显示每个类别的分布以进一步细化特征对齐。
为此,设计了两个自适应模块,即基于注意力的区域转移(ART)和基于原型的语义对齐(PSA),以实现前景中从粗到精的知识转移。
3.2.1 ART:Attention-based Region Transfer
ART模块旨在引起更多关注,以在前景区域内对齐两个域之间的分布。它由两部分组成:域分类器和注意机制。
Domain 分类器
为了对齐跨域的特征分布,作者将多个域分类器D集成到主干网络G的最后三个卷积块中,在这里构建了一个二人极大极小博弈。具体来说,域分类器D试图区分特征来自哪个域,而主干网络G旨在混淆分类器。在实践中,G和D之间通过梯度反向层(Gradient Reverse Layer, GRL)进行连接,梯度反向层可以逆转流过G的梯度。当训练过程收敛时,G倾向于提取域不变的特征表示。在形式上,第l-th卷积块中对抗性学习的目标可以表示为:
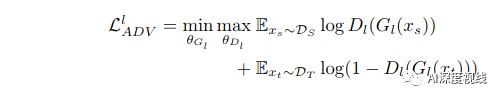
Attension 机制
要使用检测任务对对目标进行本地化和分类,roi通常比背景更重要。然而,域分类器在没有聚焦的情况下对整个图像的所有空间位置进行对齐,这可能会降低自适应性能。为了解决这一问题,作者又提出了一个注意机制来实现前向感知的分布对齐,利用RPN中的高级特征来生成注意力地图,如图3所示。
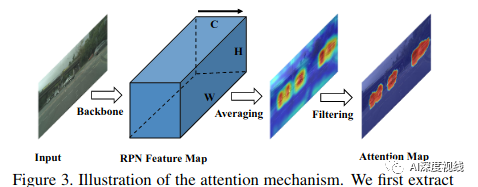
具体来说:
给定任意域中的图像x,将Frpn(x)∈RH×W×C作为FPN模块中卷积层的输出特征图,其中H×W和C分别为特征图的空间维数和通道数。
通过对激活值进行跨通道的平均来构建一个空间注意图。
过滤(设置为零)那些小于给定阈值的值,这些值更有可能属于背景区域。
由于注意图的大小与不同卷积块的特征不一致,采用双线性插值进行上采样,从而得到相应的注意图。
由于注意力地图可能并不总是那么准确,如果一个前地区域被误认为背景,它的注意力权重被设置为零,则无法起到效果。因此,这里在注意图中添加了一个跳跃连接以增强其性能。
注意图A(x)∈RH×W可以表示为:
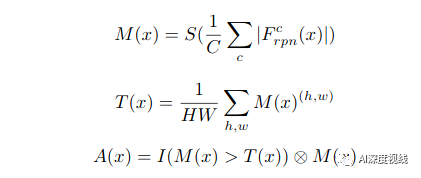
最终的ART模块的目标函数可以表示为:
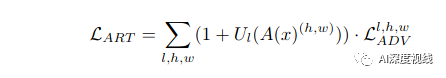
3.2.2 PSA:Prototype-based Semantic Alignment
PSA不是直接训练分类器,而是尝试最小化跨领域具有相同类别的一对原型(PSk,PTk)之间的距离,从而保持特征空间中的语义一致性。形式上,原型可以定义为:
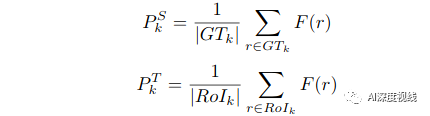
原型的好处有两方面:
(1) 原型没有额外的可训练参数,可以在线性时间内计算出来;
(2) 伪标签的负面影响可以被原型生成时数量大得多的正确伪标签所抑制。
注意:为了解决同一批源图像和目标图像的前景目标可能存在类别不一致使得该batch中所有类的类别对不齐的问题,需要动态地维护全局原型,每个小批的本地原型类型自适应地更新这些原型,如下所示:
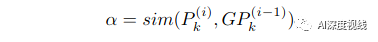
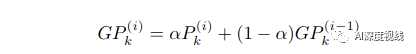
注意:不能直接对齐本地原型,而是缩小源全局原型GPSk和目标全局原型GPTk之间的距离,以实现语义对齐。在i-th迭代时,PSA模块的目标可以表述为:
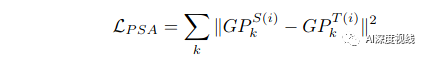
3.3 网络优化 Network Optimization
训练的伪代码如下图所示:

主要包括三个parts:
监督学习。监督检测损耗Ldet只适用于带标记的源域DS。
粗粒度的适应。利用注意机制来提取图像中的前景。然后,重点通过优化LART调整这些区域的特征分布。
细粒度的适应。首先,在目标域中预测伪标签。然后,进一步自适应地更新每个类别的全局原型。最后,通过优化LPSA实现了前台对象的语义对齐。
因此,全局的目标函数可以统一为:
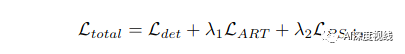
4
实验及结果
4.1 模型评估
在以下三种适应场景评估:
Normal-to-Foggy (Cityscapes→Foggy Cityscapes)
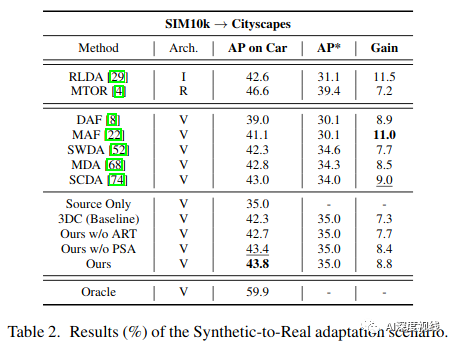
Synthetic-to-Real(SIM10k→Cityscapes)
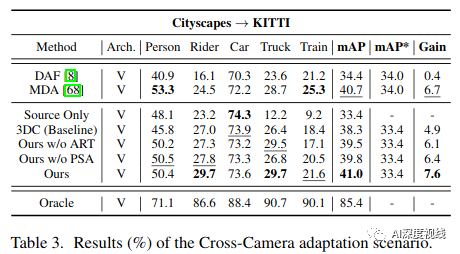
Cross-Camera(Cityscapes→KITTI).
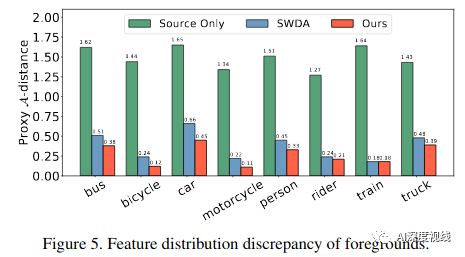
4.2 深入分析
前景特征分布差异
最高可信度检测的误差分析:
定性结果:

![]()
目标检测系列
秘籍一:模型加速之轻量化网络
秘籍二:非极大值抑制及回归损失优化
秘籍三:多尺度检测
秘籍四:数据增强
秘籍五:解决样本不均衡问题
秘籍六:Anchor-Free
视觉注意力机制系列
Non-local模块与Self-attention之间的关系与区别?
视觉注意力机制用于分类网络:SENet、CBAM、SKNet
Non-local模块与SENet、CBAM的融合:GCNet、DANet
Non-local模块如何改进?来看CCNet、ANN
语义分割系列
一篇看完就懂的语义分割综述
最新实例分割综述:从Mask RCNN 到 BlendMask
超强视频语义分割算法!基于语义流快速而准确的场景解析
CVPR2020 | HANet:通过高度驱动的注意力网络改善城市场景语义分割
基础积累系列
卷积神经网络中的感受野怎么算?
图片中的绝对位置信息,CNN能搞定吗?
理解计算机视觉中的损失函数
深度学习相关的面试考点总结
自动驾驶学习笔记系列
Apollo Udacity自动驾驶课程笔记——高精度地图、厘米级定位
Apollo Udacity自动驾驶课程笔记——感知、预测
Apollo Udacity自动驾驶课程笔记——规划、控制
自动驾驶系统中Lidar和Camera怎么融合?
竞赛与工程项目分享系列
如何让笨重的深度学习模型在移动设备上跑起来
基于Pytorch的YOLO目标检测项目工程大合集
目标检测应用竞赛:铝型材表面瑕疵检测
基于Mask R-CNN的道路物体检测与分割
SLAM系列
视觉SLAM前端:视觉里程计和回环检测
视觉SLAM后端:后端优化和建图模块
视觉SLAM中特征点法开源算法:PTAM、ORB-SLAM
视觉SLAM中直接法开源算法:LSD-SLAM、DSO
视觉SLAM中特征点法和直接法的结合:SVO
2020年最新的iPad Pro上的激光雷达是什么?来聊聊激光SLAM


最后
以上就是负责哑铃最近收集整理的关于CVPR 2020 | 通过由粗到精特征自适应进行跨域目标检测,表现SOTA!的全部内容,更多相关CVPR内容请搜索靠谱客的其他文章。








发表评论 取消回复