文章目录
- 介绍
- 论文和实现
- 构造grouped sample pairs
- 模型架构
- 结果
介绍
Unsupervised domain adaptation (UDA)无监督领域自适应不需要目标域任何标签数据,但是需要大量的目标域数据才能适应数据的分布,并没有任何的语义信息(标签)。半监督的领域适应只需要少量的目标域标签数据就能达到超过UDA的性能。实际应用中也更符合要求,我们可以在新的领域得到少量的标签数据。FADA(Few-Shot Adversarial Domain Adaptation)方法采用对抗学习的思想学习一个嵌入子空间,在最大化不同类中间的差别的同时,最小化同类样本的差别(不管是源域还是目标域)。
论文和实现
论文:https://arxiv.org/abs/1711.02536
代码:https://github.com/dupanfei1/deep-transfer-learning-for-waveform/tree/master/semisupervised/FADA
(ubuntu16.04 python3.5, torch0.3.1可运行)
构造grouped sample pairs

G1: 同一类数据对,均来自源域
G2:同一类数据对,分别来自源域和目标域
G3:不同类数据对,均来自与源域
G4: 不同类数据对,分别来自于源域和目标域
模型架构
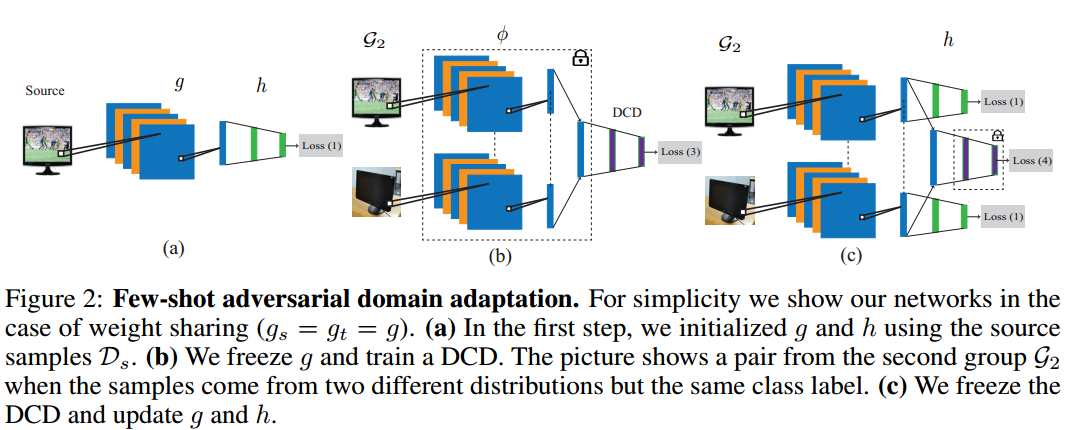
第一步:源域预训练,训练得到g和h,loss如下

第二步:利用Siamese网络的思想,源域和目标域分别对应一个编码网络,DCD是domain-class discriminator(4分类),对G1对标记为0,G2对标记1,G3对标记2,G4对标记3。此阶段固定g 不变,训练DCD网络,尽可能混淆DCD保证类别的语义对齐关系。
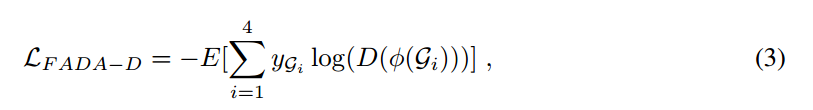
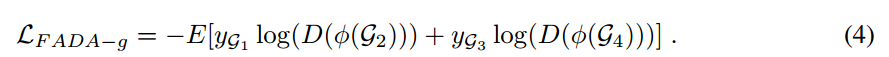
我们的目标是G1,G2不能被区分(无论什么domain,同一个class),G3,G4不能被区分(无论什么domain,都是不同的class),G1,G2(都是同类对)和G3,G4(都是不同类对)尽可能区分。从损失函数可以看到,要让G1,G2分布尽可能一致,G3,G4分布尽可能一致。
第三步:固定DCD,再更新g和h。
迭代进行第二步第三步
算法如下:

总loss
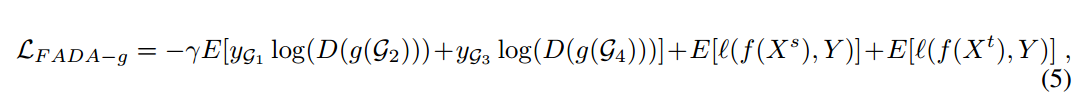
用gamma作为权衡系数,保证分类和混淆之间的平衡。
结果


代码参考:https://github.com/Coolnesss/fada-pytorch
最后
以上就是干净自行车最近收集整理的关于半监督领域自适应之FADA--Few-Shot Adversarial Domain Adaptation的全部内容,更多相关半监督领域自适应之FADA--Few-Shot内容请搜索靠谱客的其他文章。








发表评论 取消回复