一个场景下的数据集训练的语义分割模型,并不能很好的适应另一个场景的数据,所以需要对场景进行迁移,从而实现模型对多场景下的数据的良好分割。最开始对这方面的研究,是为了将游戏场景生成的数据训练的模型能很好地迁移到现实场景。语义分割是在像素级别进行分类,不适合运用特征自适应。高维特征很复杂,不适合用来进行适配。文献一是对语义分割的输出进行适配,语义分割的输出是低维空间上的,包含了丰富的上下文和布局等信息。
文献一:Learning to Adapt Structured Output Space for Semantic Segmentation
code
paper
一、论文大致介绍
提出一种域自适应语义分割,主要为了解决场景迁移问题。本文所提的域自适应算法由分割网络G和判别网络D组成。源域图像用于训练分割网络,源域和目标域的分割预测作为判别网络的输入,进行对抗学习,让目标域的分割分布接近于源域的分割分布。这种模型的损失函数由两部分组成:基于源域图像的分割损失函数和源域和目标域分割预测的对抗损失。公式如下: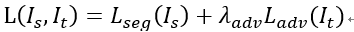
域自适应语义分割模型又分为单级对抗学习和多级对抗学习,多级模型即使用多个域适应(DA)模块,在DCNN模型中抽出几层卷积层的特征图,然后在每层特征图后面跟一个ASPP结构进行softmax输出,然后喂入到判别器中。
一级对抗学习
判别器训练: 分割softmax输出P=G(I)∈RHxWxC, C为类别数量,这里为两类(目标和源域)。将P输入基于交叉熵损失函数的全卷积判别器D。判别器的损失函数如下:
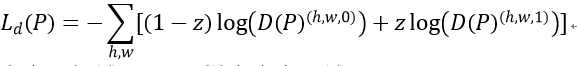
z=0,样本来自目标域,z=1,样本来自源域。
分割网络训练: 定义源域的损失函数为:
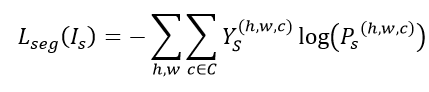
对抗学习训练: 将目标域图像输入到G中,得到预测Pt=G(It),为了让Pt接近Ps,使用对抗损失Ladv (计算的是判别为源图像的概率)
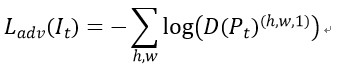
多级对抗学习
损失函数为:
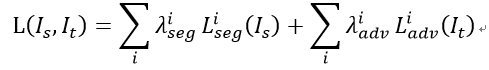
i是输出的级别。
对抗学习的过程可以表示为:
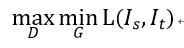
对抗学习是为了让判别器尽力能辨别出是来自源域还是目标域,分割网络能输出接近源域分布的目标域图像,让判别器无法区分。
二、网络结构
网络结构如图1所示,分割网络采用的deeplab v2模型,判别器使用了5层卷积层。
判别器
使用的4x4卷积核,步长为2,通道数为{64,128,256,512,1},最后一层分类层没有连接leaky ReLU,其他卷积层都有,参数为0.2。在最后一层卷积层后面添加了一个上采样层,没有使用BN。
分割网络
采用DeepLap-v2框架基于在ImageNet上预训练的ResNet-101,将最后的一个分类层移除,将最后两个卷积层stride2变成1,使输出特征图分辨率有效控制在输入图像的1/8倍,为了扩大感受野,在conv4和conv5中使用2x和4x孔洞卷积,最后一层之后,使用ASPP作为分类器。在softmax层后使用一个上采样层,还原为输入图像的大小。
多级适应模型
在第四层的卷积层后加上一个辅助分类器ASPP,然后添加有相同结构的判别器,用于对抗学习。
网络训练
1)使用源域图像训练分割网络G;(loss_seg=loss_seg2+λloss_seg1)
2)基于target的预测图训练判别器D ;(loss_adv_t=λ
1
_1
1loss_adv_t2+ λ
2
_2
2loss_adv_t1)
3)基于Source的预测图训练判别器D;(loss_D1,loss_D2)
4)基于target的预测图训练判别器D;(loss_D1,loss_D2)
使用工具及参数:
Pytorch、SGD优化器,momentum=0.9和0.99 weight decay=10-4,原始学习率=2.5x10-4。

图1. 算法概述。使用两个不同层的特征图的分割预测输出进行对抗学习,这就是提出的多层次对抗性学习。
三、实验结果
使用了完整的GTA5(24966张)并将模型适应于拥有2975张图像的Cityscapes训练集。在测试期间,对Cityscapes验证500张图片。
需要的数据格式:
训练集: 目标域原图、源域原图和标签图
实验分析比较了在特征和输出空间进行适应的结果对比,输出空间能接受更大范围的λadv。设置的训练参数:
λ
s
e
g
1
=
1
,
λ
a
d
v
1
=
0.001
a
n
d
λ
s
e
g
2
=
0.1
,
λ
a
d
v
2
=
0.0002
lambda^{1}_{seg}=1,lambda^{1}_{adv}=0.001 and lambda^{2}_{seg}=0.1, lambda^{2}_{adv}=0.0002
λseg1=1,λadv1=0.001andλseg2=0.1,λadv2=0.0002
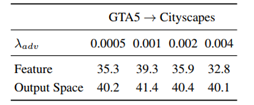
又对SYNTHIA(9400)适应Cityscapes数据集和Cityscapes数据集适应Cross-City数据集做了实验,三次试验结果如下图,与其他文献方法做了对比。分别以主干网络为VGG的模型进行对比,再基于Resnet,对单级、多级以及特征适应做了对比。

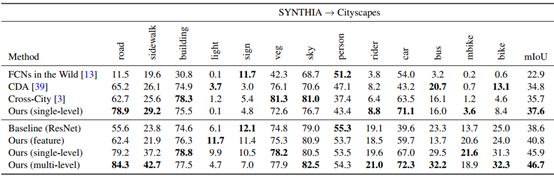
Cross-City Dataset:
不同城市的数据:Rio、Rome、Tokyo 和 Taipei,每个城市有3200张标注的图像,100张标注的图像(验证集)。数据集间的域间隙小,使用更小的权重:
λ
a
d
v
i
=
0.0005
.
lambda^{i}_{adv}=0.0005,.
λadvi=0.0005.
补充: 使用了deeplab v2模型在数据集GTA5上进行了训练,训练步数15000,并且使用Cityscapes的验证集作为模型验证集,miou=30.7%。

最后
以上就是还单身帽子最近收集整理的关于基于域自适应语义分割学习小结的全部内容,更多相关基于域自适应语义分割学习小结内容请搜索靠谱客的其他文章。








发表评论 取消回复