文章目录
- 一、目标检测网络简介
- 二、one-stage
- 1、yolo
- 1.1 yolov1
- 1.2 yolov2
- 1.3 yolov3
- 1.4 yolov4
- 1.5 yolov5
- 2、SSD
- 3、RetainNet
- 二、two-stage
- 1、R-CNN
- 2、Fast R-CNN
- 3、Faster R-CNN
- 4、SPP-net
- 总结
一、目标检测网络简介
大致分为两类one-stage和two-stage,主要区别是检测目标类别与bounding box回归任务是否分开进行。
two-stage代表是rcnn系列(rcnn、fast-rcnn、faster-rcnn)等
one-stage代表是yolo系列(yolov1-yolov5)、SSD、RetainNet等
二、one-stage
1、yolo
1.1 yolov1
网络:

由最后的全连接层转化多维度张量(7730),可以将7X7 看成特征图,特征图中每点映射到原始图像一块区域(相当于将原始图像划分成7X7的网格),30=2*5+20表示预测出的bbox信息包含2个box(每个box中信息为box中心点坐标及box的宽高、置信度)及2个box对应的20类的概率值。 简单理解为在7X7网格中,每个网络都有可能预测出2个box,因此一张图最终会预测出772=98个box。
置信度作用表示该box中存在目标的可能性。

置信度得分:置信度*每类概率。(测试时使用)
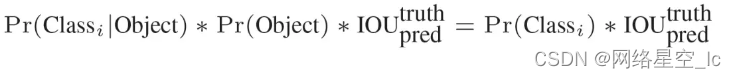
编码:将GT-box信息转化为7730的张量,有目标的cell中,对应目标类别概率设为1,其他类别概率为0,置信度为1;无目标的cell中概率置信度均为0.
损失函数:包含坐标、有无目标的置信度及概率的误差损失。
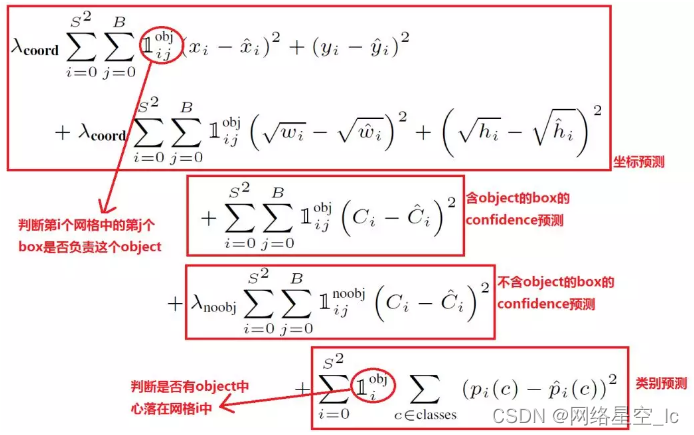
预测使用NMS算法进行筛选,选取出最优的box
优点
(1)yolo很快,它将整张图作为网络的输入,直接在输出层回归 bounding box 的位置和所属的类别(将对象检测作为一个回归问题)
(2)yolo会基于整张图片信息进行预测,而其他滑窗式的检测框架,只能基于局部图片信息进行推理。
(3)yolo学到的图片特征更为通用。
缺点:
(1)物体检测精度低,召回率低。
(2)容易产生物体的定位错误。
(3) 对小物体的检测效果不好(尤其是密集的小物体,因为一个栅格只能预测 2 个物体)。
1.2 yolov2
参考:https://zhuanlan.zhihu.com/p/106704786
改进:
(1)批规范化(Batch Normalization)
使用 Batch Normalization 对网络进行优化,去掉 dropout,让网络提高了收敛性,BN 层可以起到一定的正则化效果,能提升模型收敛速度,防止模型过拟合。
(2)高分辨率分类器(High Resolution Classifier)
先用224×224的输入来训练大概160个epoch,然后再把输入调整到448×448再训练10个epoch,然后再与训练好的模型上进行fine-tuning,检测的时候用448×448。
(3)使用 Anchor Boxes
作者借鉴了Faster R-CNN的思想,引入anchor
删除了全连接层和最后一个pooling层,使得最后的卷积层可以有更高的分辨率。
缩减网络,用416416输入代替448448,这样做是希望得到的特征图都是奇数大小的宽和高,奇数大小的宽和高会使得每个特征图在划分cell的时候只有一个中心cell,因为大的目标一般会占据图像的中心,所以希望用一个中心cell去预测,而不是四个中心cell。
预测得到13135=845个box
(4)通过K-means来学习出anchor box
在K-means算法中重新定义iou距离作为样本之间距离计算
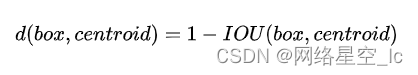
(5) 直接位置预测(Direct Location Prediction)
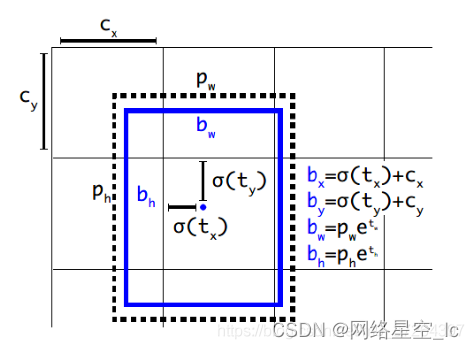
YOLOv2对框回归过程进行了改进,过去的框回归过程,由于对tx,ty 参数没有约束,使得回归后的目标框可以位移到任意位置,这也导致YOLO的框回归中存在不稳定性。改进的做法为引入sigmid函数,对预测的x,y 进行约束。
YOLOv2在框回归时,为每一个目标框预测5个参数: tx,ty,tw,th,t0 ,调整的计算公式为:

通过使用sigmid函数,将偏移量的范围限制到 (0,1) ,使得预测框的中心坐标总位于格子内部,减少了模型的不稳定性。
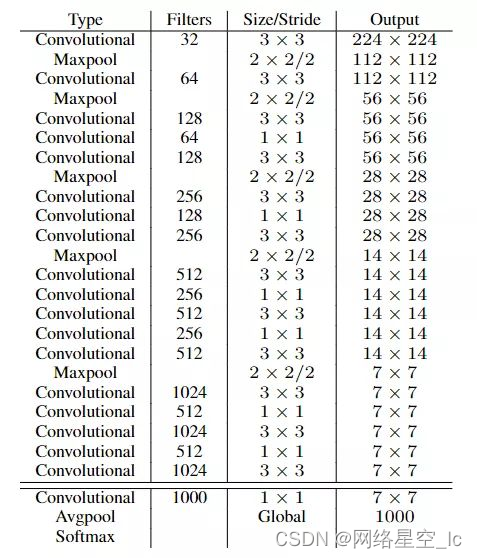
(6)网络搭建:Darknet-19,拥有19个卷积层和5个Max Pooling层,网络中使用了Batch Normalization来加快收敛最后的conv层、avgpool层和softmax层是用于分类训练时的输出结构。当进行预测时,去掉这三层,只保留箭头间的部分进行特征提取。
(7)多尺度训练
由于网络中只包含卷积层和池化层,YOLOv2为了增加网络的鲁棒性,在训练过程中动态调整网络的输入大小,同时相应地调整网络的结构以满足输入。因为网络下采样32倍,要求输入尺寸包含因数32。
(8)损失函数

损失函数详解
无法解决重叠问题的分类
1.3 yolov3
改进:
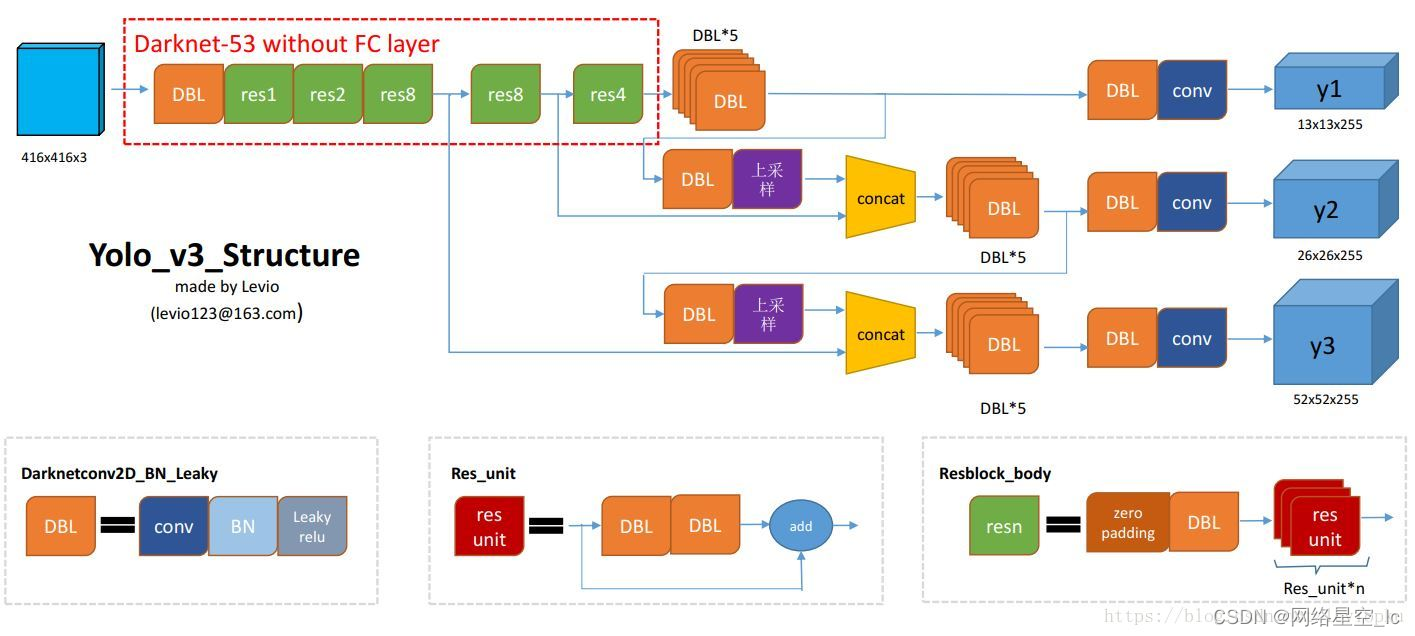
YOLOv3 借鉴了 FPN 的思想,从不同尺度提取特征。相比 YOLOv2,YOLOv3 提取最后 3 层特征图,不仅在每个特征图上分别独立做预测,同时通过将小特征图上采样到与大的特征图相同大小,然后与大的特征图拼接做进一步预测。用维度聚类的思想聚类出 9 种尺度的 anchor box,将 9 种尺度的 anchor box 均匀的分配给 3 种尺度的特征图
用逻辑回归替代 softmax 作为分类器
在 YOLO v3 在网络结构中把原先的 softmax 层换成了逻辑回归层,从而实现把单标签分类改成多标签分类
(1)网络:DarkNet-53
(2)损失函数
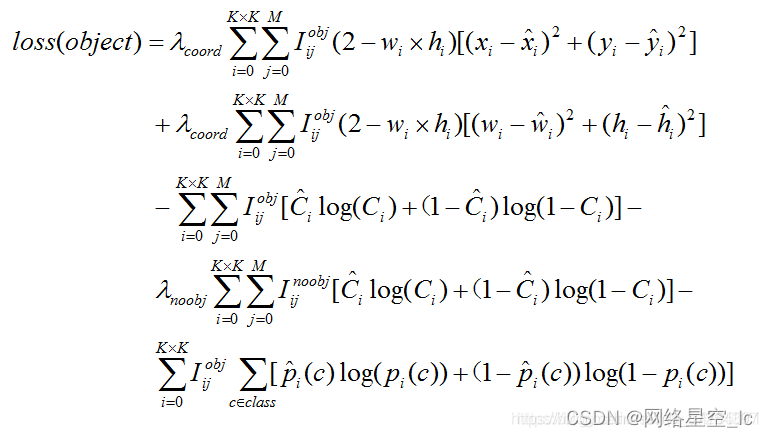
1.4 yolov4
改进:
(1)输入端:Mosaic数据增强、cmBN、SAT自对抗训练。
(2)BackBone主干网络:CSPDarknet53、Mish激活函数、Dropblock
(3)Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
(4)Prediction输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
1.5 yolov5
(1)输入端:Mosaic数据增强、自适应锚框计算
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
2、SSD
详细参考:https://www.cnblogs.com/MY0213/p/9858383.html
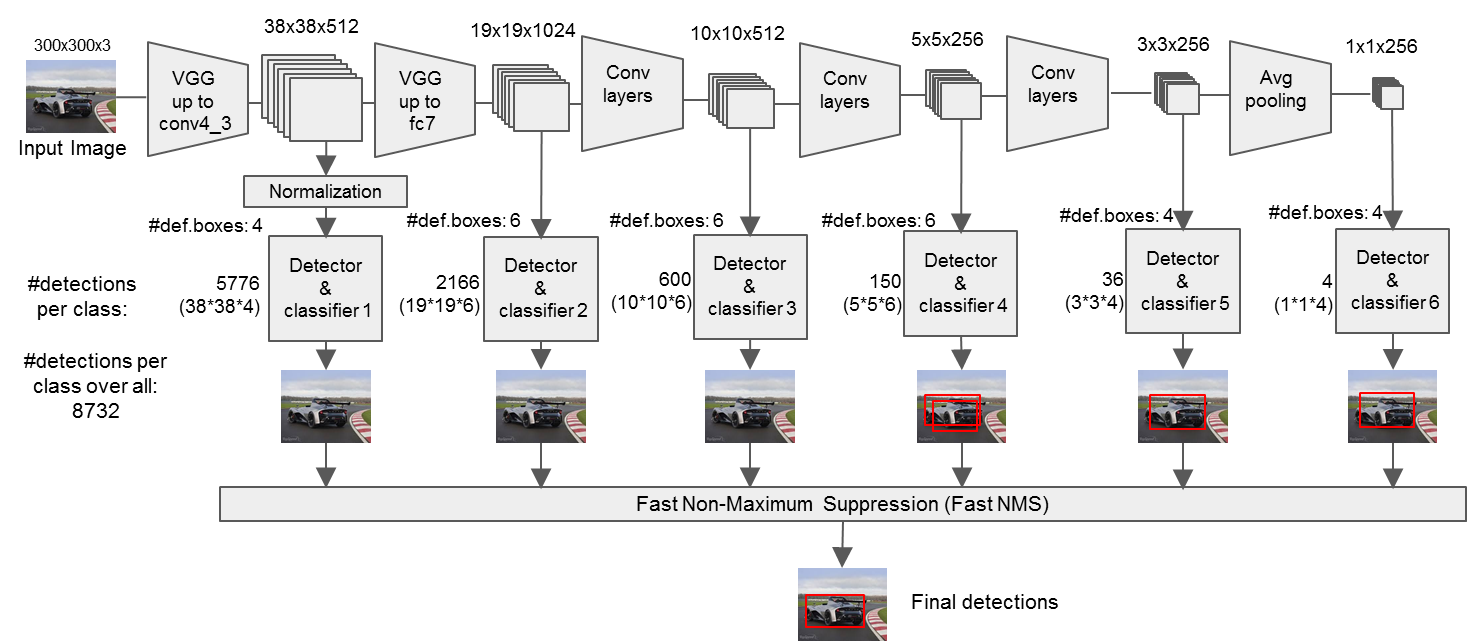
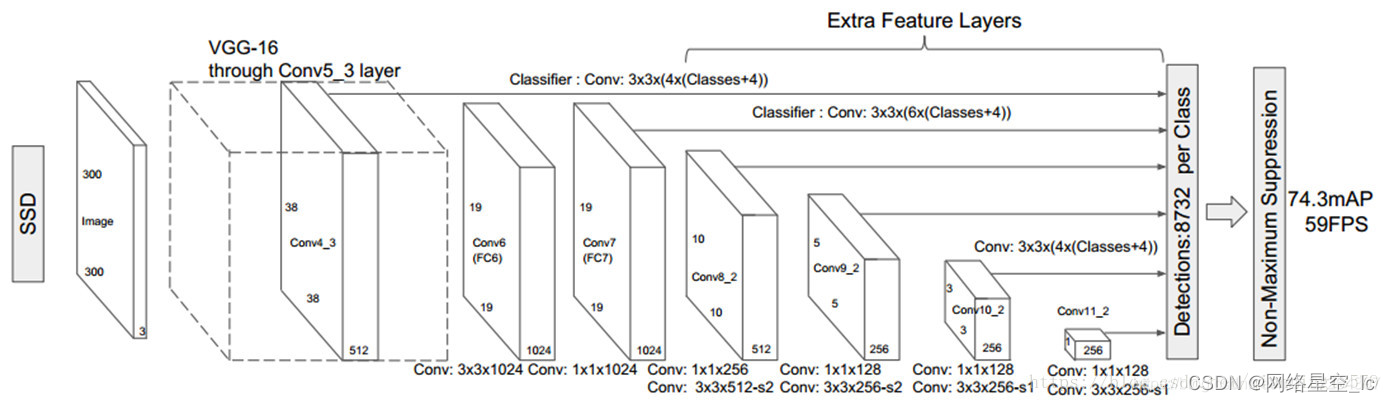
以VGG16网络卷积组作为SSD网络前一部分,后面的2个全连接层用卷积层替换,并追加4组卷积组。
从整个SSD网络中选择conv4_3、conv7、conv8_2、conv9_2、conv10_2、conv11_2卷积层的特征图预测出box,由不同层特征图预测出不同尺寸的目标(多尺度),浅层预测出小目标,深层预测出大目标并且每个特征图(fpfp)中的每个点映射到原图感受视野区域(中心点),如3838特征图在原始图片300300中对应的视野区域为88,每个点预测出K个box,每个box中信息包含位置及对应各类别概率值©,所以各层抽取的特征图最后转化为(fp,fp,K,(C+4))。K的为4、6、6、6、4、4分别对应各fp。
①、网络构建
②、先验框构造
参考:https://blog.csdn.net/BistuSim/article/details/83048407
先验框目的主要是为了筛选出符合与GT-box最优的框,再与GT-box计算位置损失与置信度损失。
匹配的策略:首先选择与GT Box具有最大IOU的先验框作为正样本;其次,若某个先验框的的IOU>0.5,也认为是正样本。这样使得网络可以对多个先验框进行预测,可以预测目标的多种形状。
先验框尺度设置:随着特征图大小降低,先验框尺度线性增加

③、损失函数
损失函数定义为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和:
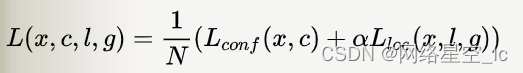
位置误差:
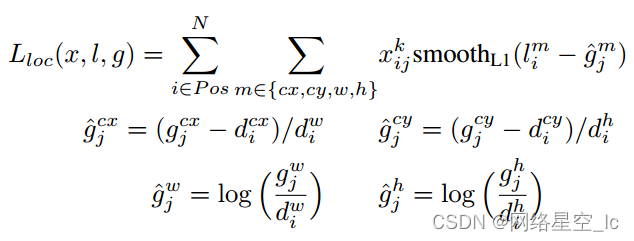
置信度误差:
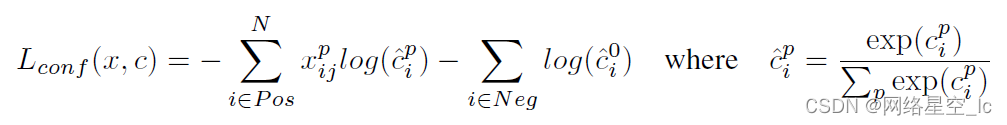
参考:https://segmentfault.com/a/1190000021845972
3、RetainNet
RetinaNet主要解决的问题就是一步做完却会导致的----类别不平衡问题,即在得到的一堆锚框中,实际上只有少数量的目标框,还有很多无用的背景图,导致极端的类别不平衡。
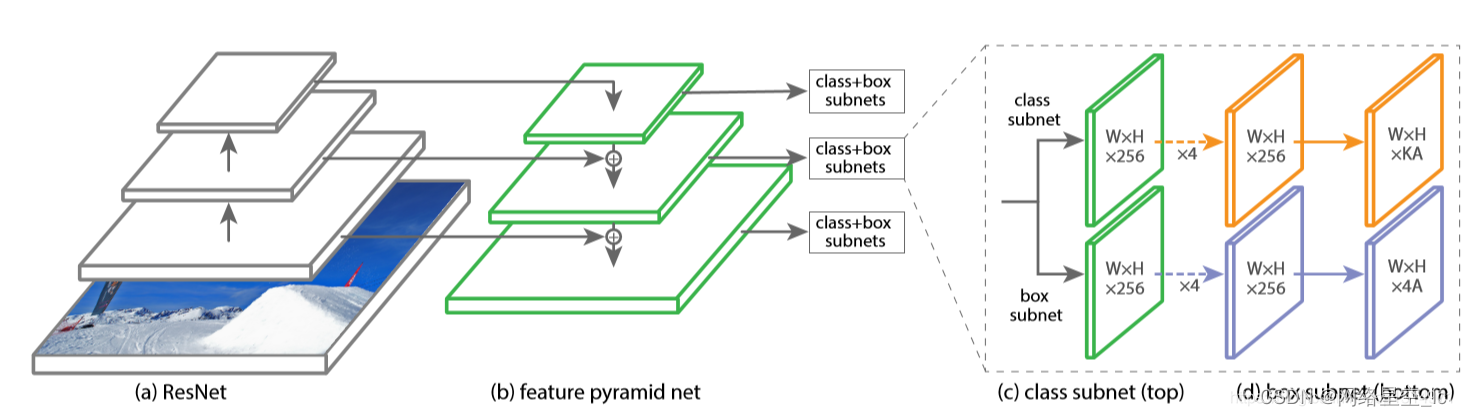
①、网络
ResNet + FPN + SubNet
②、Focal Loss
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
二、two-stage
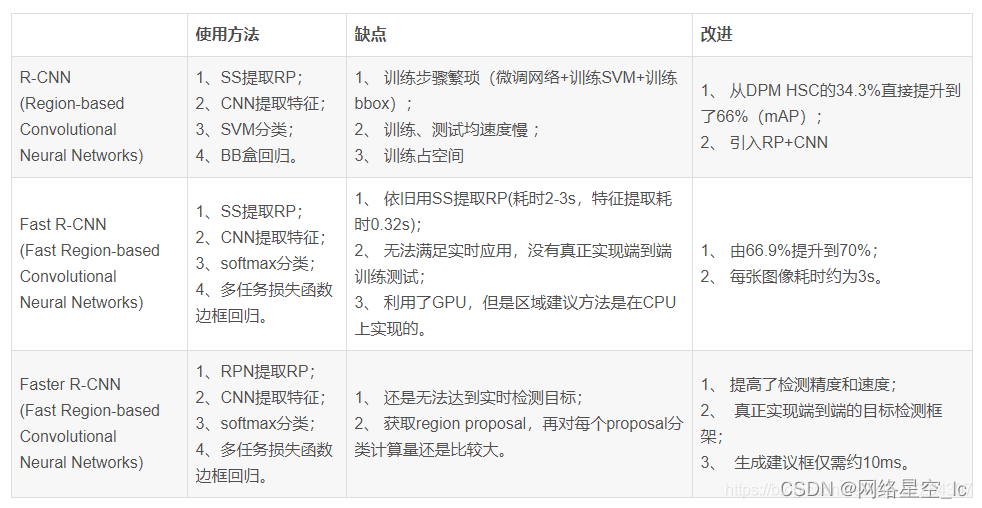
RCNN系列对比:参考
1、R-CNN
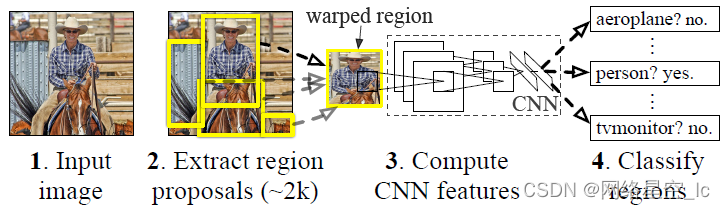
实现步骤:
①使用SS(Selective Search)算法生成约2k个候选框(Region Proposals,RP),通过warp,将RP统一变成227×227的大小。
②将生成的所有候选框送入CNN中提取特征
③使用SVM对输出的特征进行分类
④回归预测候选框
参考:https://blog.csdn.net/shenxiaolu1984/article/details/51066975
2、Fast R-CNN
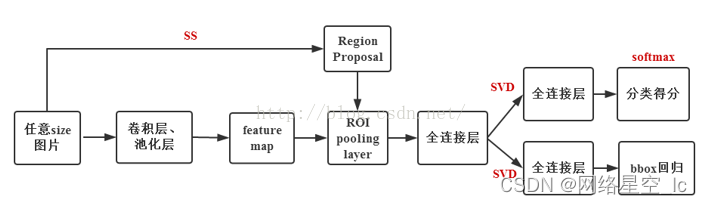
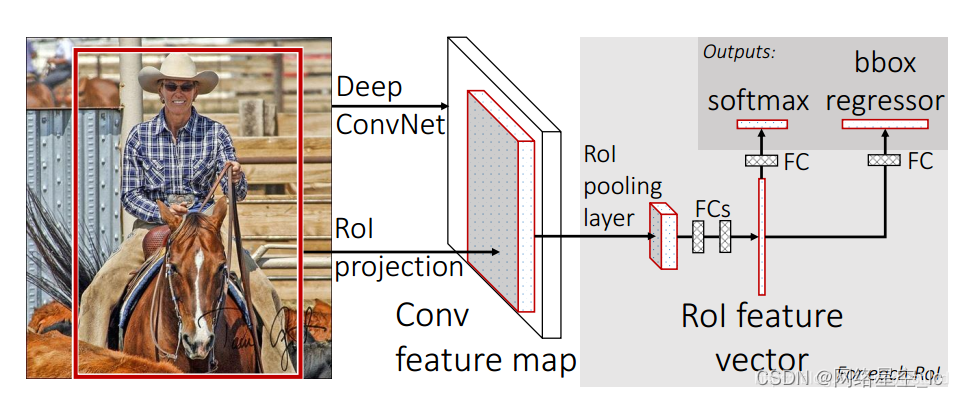
实现步骤:
①使用SS(Selective Search)算法生成约2k个候选框RP
②将原始图片送入CNN中提取特征
③将生成的RP映射到最后的卷积层得到的特征图上
④通过RoI pooling层使得每个RP成为固定尺寸的feature map
⑤利用Softmax Loss和Smooth L1 Loss对分类概率和Bb回归联合训练
参考:https://blog.csdn.net/tystuxd/article/details/85317037?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-7&spm=1001.2101.3001.4242
3、Faster R-CNN
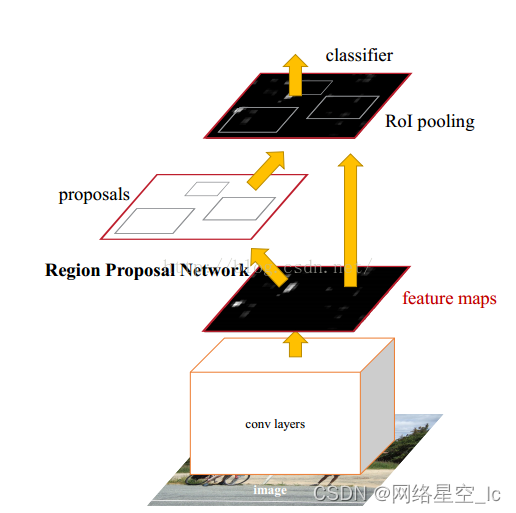
训练
1)把整张图像送入CNN中进行feature map的提取。
2)用RPN生成RP,每张图片生成300个。
3)RP映射到最后一层feature map。
4)在RoI pooling层把每个RoI生成固定大小的feature map。
5)利用Softmax Loss和Smooth L1 Loss对分类概率和Bb回归联合训练。
4、SPP-net
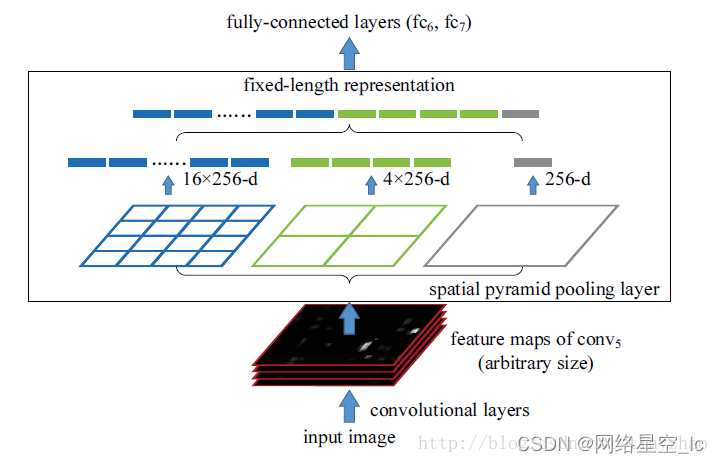
R-CNN(Selective Search + CNN + SVM)
SPP-net(ROI Pooling)
Fast R-CNN(Selective Search + CNN + ROI)
Faster R-CNN(RPN + CNN + ROI)
- 参考:https://blog.csdn.net/v_JULY_v/article/details/80170182?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-6.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-6.control
几种目标检测网络的优缺点:
- https://zhuanlan.zhihu.com/p/53361944
- https://blog.csdn.net/red_stone1/article/details/101303122
- http://www.chuangze.cn/third_1.asp?txtid=1255
- https://github.com/kuangliu/pytorch-retinanet
- Focal Loss :https://www.cnblogs.com/king-lps/p/9497836.html
- https://blog.csdn.net/qq_17448289/article/details/52871461
总结
最后
以上就是朴素小馒头最近收集整理的关于目标检测网络一、目标检测网络简介二、one-stage二、two-stage总结的全部内容,更多相关目标检测网络一、目标检测网络简介二、one-stage二、two-stage总结内容请搜索靠谱客的其他文章。








发表评论 取消回复