import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torchvision import datasets, transforms
import os
import struct
import numpy as np
class mnistNet(nn.Module):
def __init__(self):
super(mnistNet, self).__init__()
self.conv1 = nn.Conv2d(1, 30, 5, 1)
self.conv2 = nn.Conv2d(30, 60, 5, 1)
self.fc1 = nn.Linear(4 * 4 * 60, 300)
self.fc2 = nn.Linear(300, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4 * 4 * 60)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def load_mnist(path, kind='train'):
# 读取mnist数据到numpy
labels_path = os.path.join(path, '%s-labels-idx1-ubyte' % kind)
images_path = os.path.join(path, '%s-images-idx3-ubyte' % kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II', lbpath.read(8))
labels = np.fromfile(lbpath, dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
magic, num, rows, cols = struct.unpack('>IIII', imgpath.read(16))
images = np.fromfile(imgpath, dtype=np.uint8).reshape(len(labels), 784)
images = images.reshape((-1, 28, 28))
return images, labels
class datasetsMnist(Dataset):
def __init__(self, root, kind, augment=None):
# mnist 图像及label
self.images, self.labels = load_mnist(root, kind)
self.augment = augment
if kind=="train":
# 随机设置255,使label(%98)失效
c=np.linspace(0, 60000-1,60000)
a2 = np.random.choice(c, size=int(60000*0.98), replace=False ).astype(np.int32)
self.labels[a2] = 250
def __getitem__(self, index):
image = self.images[index]
image = self.augment(image) # 这里对图像进行了数据增强
return image, self.labels[index]
def __len__(self):
return len(self.images)
def train(args, device):
# 定义数据
train_transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_datasets = datasetsMnist('./mnist/MNIST/raw', "train", train_transform)
train_loader = torch.utils.data.DataLoader(train_datasets, num_workers=8, batch_size=args.train_batch_size, shuffle=True)
test_transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
test_datasets = datasetsMnist('./mnist/MNIST/raw', "t10k", test_transform)
test_loader = torch.utils.data.DataLoader(test_datasets, num_workers=4, batch_size=args.test_batch_size, shuffle=True)
# 定义模型
student_model = mnistNet().to(device)
mean_teacher = mnistNet().to(device)
# 回归器
optimizer = optim.SGD(student_model.parameters(), lr=args.lr, momentum=args.momentum)
for epoch in range(args.epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.float().to(device), target.long().to(device)
idx = torch.where(target<20) # 过滤target
if idx[0].shape==torch.Size([0]): continue
optimizer.zero_grad()
# print(target.shape)
# print(target_HT.shape)
output = student_model(data)
# 防止梯度传递到mean_teacher模型
with torch.no_grad():
mean_t_output = mean_teacher(data)
# 以mean_teacher的推理结果为target, 计算student_model的均方损失误差
const_loss = F.mse_loss(output, mean_t_output)
# 计算总体误差
weight = 0.2
# 有target的样本与target进行损失计算
loss = F.nll_loss(output[idx], target[idx]) + weight*const_loss
# loss = F.nll_loss(output, target[idx])
loss.backward()
optimizer.step()
# update mean_teacher的模型参数
alpha = 0.95
for mean_param, param in zip(mean_teacher.parameters(), student_model.parameters()):
mean_param.data.mul_(alpha).add_(1 - alpha, param.data)
# print('Train Epoch: {}tLoss: {:.6f}'.format(epoch, loss.item()))
test(student_model, device, test_loader, "student")
test(mean_teacher, device, test_loader, "teacher")
if (args.save_model and False):
torch.save(student_model.state_dict(), "mnist_cnn.pt")
def test(model, device, test_loader, name):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.float().to(device), target.long().to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # 计算loss
pred = output.argmax(dim=1, keepdim=True) # 推理结果
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('{} Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)'.format( name,
test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
model.train()
if __name__ == '__main__':
# 配置
parser = argparse.ArgumentParser(description='半监督学习pyTorch')
parser.add_argument('--train_batch_size', type=int, default=30)
parser.add_argument('--test_batch_size', type=int, default=30)
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--lr', type=float, default=0.01, help='learning rate')
parser.add_argument('--momentum', type=float, default=0.5, help='SGD momentum')
parser.add_argument('--no-cuda', action='store_true', default=False)
parser.add_argument('--save-model', action='store_true', default=False)
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
# device = torch.device("cuda" if use_cuda else "cpu")
device = torch.device("cuda")
# 训练
train(args, device)
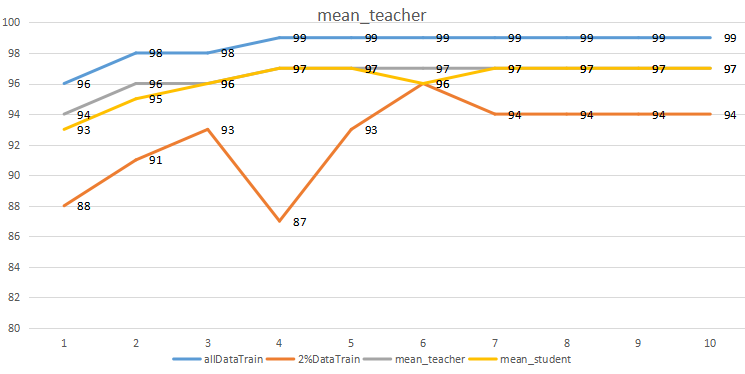
结论:
- 使用60000个有标签数据进行训练,得到了最好的测试效果;
- 仅使用2%的有标签数据进行训练,测试有较大波动;
- 使用2%的有标签数据和98%的无标签数据进行训练,整体效果处于两则之间。
最后
以上就是香蕉向日葵最近收集整理的关于使用mean_teacher算法对MNIST数据集进行测试的全部内容,更多相关使用mean_teacher算法对MNIST数据集进行测试内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复