我是靠谱客的博主 甜蜜小鸽子,这篇文章主要介绍【论文阅读】Learning Semantic Representations for Unsupervised Domain Adaptation,现在分享给大家,希望可以做个参考。
Learning Semantic Representations for Unsupervised Domain Adaptation 2018 ICML
代码地址:https://github.com/Mid-Push/Moving-Semantic-Transfer-Network Tensorflow
一. 主要贡献
这篇文章解决的主要问题是如何用有标签的数据去标记无标签的数据? 之前的方法都忽略了样本的语义信息,比如之前的算法可能将目标域的背包映射到源域的小汽车附近。 这篇文章最要的贡献就是提出了 moving semantic transfer network 这个网络,简称mstn,其主要是通过 对齐源域(有标签)和 目标域(伪标签,网络预测一个标签)相同类别的中心,以学习到“样本的语义信息。
二. 主要方法
2.1 基本框架

该方法中损失函数主要由三部分组成:
其主要表达形式如下:
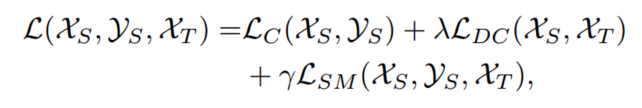
- LC(XS,yS)指的是源域的分类损失;
- LDC(XS,XT)指的是域对抗的相似性损失,目标是骗过discriminator,让其不知道特征是来自于源域还是目标域。
- 前两项比较中规中矩,文章的主要创新点就是在第三项上,作者将其命名为semantic transfer loss ;分类器可以给目标域预测标签,但是其预测的标签不一定是对的,如何尽量保证目标域预测标签是对的呢?作者引入了 centroid alignment,其解决方案是对齐目标域和源域相同类别的中心,伪标签带来的负面影响可以被伪标签带来的正面影响消除。(这句话的意思就是,预测的伪标签有正确的也有错误的,我们的目标是对齐源域和目标域相同类别的中心,形成一个中心,那伪标签正负样本,我们认为两者可以相互抵消),具体表达形式如下:
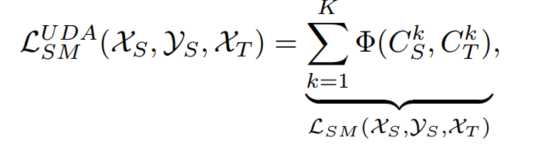
UDA代表unsupervised domain adaptation , 这个函数目标就是减小两个域之间的距离。
2.2 semantic transfer loss 计算过程
这个过程就比较好理解了,不断迭代去更新类别的中心,当前batch得到的中心会不断去影响之前的类别中心,影响系数由
θ
theta
θ 来决定,
θ
theta
θ在本实验中设置为0.7。

论文中对于小的数据集(数据类别少,batch_size设置大),将当前step学习到的中心就为中心,不考虑之前的中心信息
Moving Average:适合数据集大,batch_size 小的情况。
三. 实验
3.1 实验设置
数据库
- Office-31: 有三个不同域的数据,都是31个类别。
三个域样本个数:Amazon:2817 Webcam:795 DSLR:498 - ImageCLEF-DA: 也是三个域,每个域12个类别,每个类别都是50张图片;三个域的数据来源分别是:Caltech-256,ImageNet ILSVRC 2012,Pascal VOC 2012。
- MNIST-USPS-SVHN,手写数字集
实现细节
- CNN 采用的是AlexNet作为基本结构,fc7后面接了一个bottleneck layer(瓶颈层,主要作用是降维;
- 鉴别器,我们采用的是RevGard相同的结构:x-》1024-》1024-》1,
- 超参数的设置:
θ
theta
θ = 0.7,
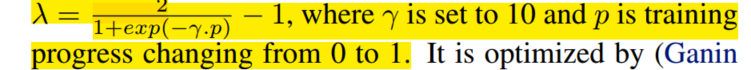
3.2 实验结果
在Office-31 上的结果:

ImageCLEF-DA 实验结果

手写数字集上的结果:

最后
以上就是甜蜜小鸽子最近收集整理的关于【论文阅读】Learning Semantic Representations for Unsupervised Domain Adaptation的全部内容,更多相关【论文阅读】Learning内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复