决策树理论理解:
1.什么是决策树?
一种基本的分类回归方法,决策树属于分类回归模型的范畴。
决策树的三个步骤:
- 特征选择
- 决策树生成
- 决策树修剪(剪枝)
决策树示意图
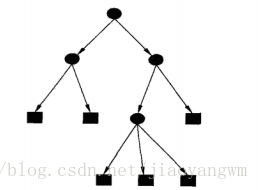
决策树目标:
分类
决策树本质:
估计条件的概率模型
决策树自我学习的目标:
选择最优决策树
决策树学习的测试:
最小化损失函数
决策树的特点:
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配的问题
适用数据类型:数值型和标称型
2.信息熵
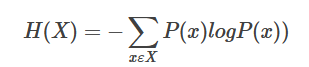
为什么是log?
在离散数学中我们学过,一个树的高度等于log(节点数),这个log(x)恰巧是询问的高度,也就是投硬币的次数!这原来就是使用log的原因
3.信息增益
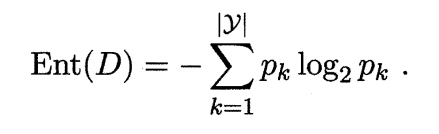
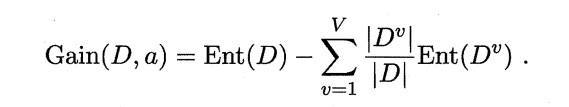
著名的 ID3 决策树学习算法[Quinlan 1986] 就是以信息增益为准则来选择划分属性。
4.信息增益率
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的 C4.5 决策树算法 [Quinlan 1993J 不直接使用信息增益,而是使用"信息增益率" (gain ratio) 来选择最优划分属性。信息增益率定义为:
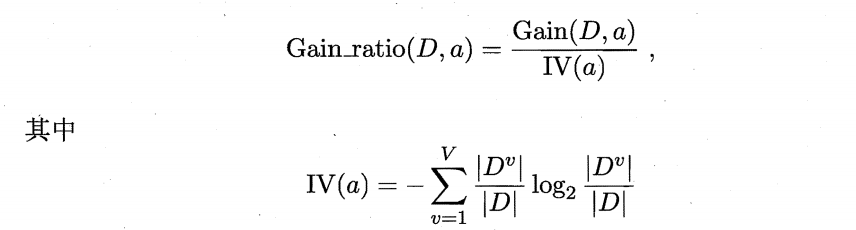
IV(a) 称为属性a的"固有值" (intrinsic value)。属性a的可能取值数目越多,则 IV(a) 的值通常会越大。
需注意的是,增益率准则对可取值数目较少的属性有所偏好。因此 C4.5
算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:
先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
5.基尼值和基尼指数
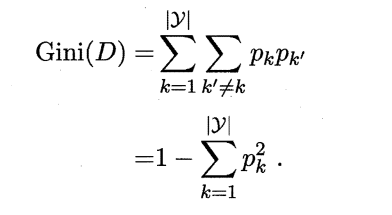
直观的讲, 基尼值 Gini(D) 反映了从数据集 D 中随机抽取两个样本,其类别标记不一致的概率。因此,基尼值 Gini(D) 越小,则数据集 D 的纯度越高。针对某一具体属性 a ,其基尼指数定义为:
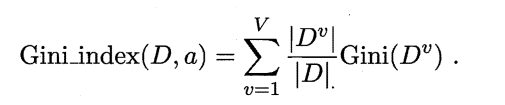
5.数据拟合问题
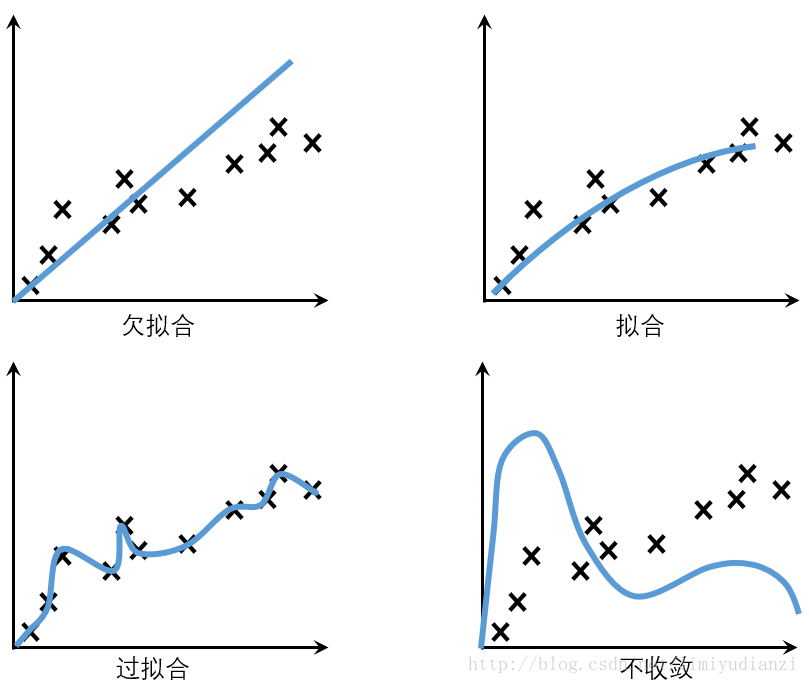
6.过拟合
过拟合也就是泛化能力差
泛化能力(generalization ability)是指一个机器学习算法对于没有见过的样本的识别能力。我们也叫做举一反三的能力,或者叫做学以致用的能力。
怎么判断是不是过拟合?
训练时准确率高,验证时准确率低。
欠拟合(under-fitting)是和过拟合相对的现象,可以说是模型的复杂度较低,没法很好的学习到数据背后的规律。就好像开普勒在总结天体运行规律之前,他的老师第谷记录了很多的运行数据,但是都没法用数据去解释天体运行的规律并预测,这就是在天体运行数据上,人们一直处于欠拟合的状态,只知道记录过的过去是这样运行的,但是不知道道理是什么。
过拟合产生的原因:
- 1.神经网络的学习能力过强,复杂度过高
- 2.训练时间太久
- 3.激活函数不合适
- 4.数据量太少
解决办法:
- 1.降低模型复杂度,dropout
- 2.即时停止
- 3.正则化
- 4.数据增强
6.评价一个模型的好坏原则:奥卡姆剃刀
“如无必要,勿增实体”。
7.集中交叉验证方法
留一法
如果设原始数据有N个样本,那么每个样本单独作为验证集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标。、
m-交叉验证
样本分为m组,n与)(N-(n)/m)进行交叉验证。
8.数据集分割原则
原始数据集分割为训练集与测试集,必须遵守两个要点:
- 1、训练集中样本数量必须够多,一般至少大于总样本数的 50%;
- 2、两组子集必须从完整集合中均匀取样。均匀取样的目的是希望尽量减少训练集/测试集与完整集合之间的偏差。一般的作法是随机取样,当样本数量足够时,便可达到均匀取样的效果。
9.决策树算法应用举例以及分类:
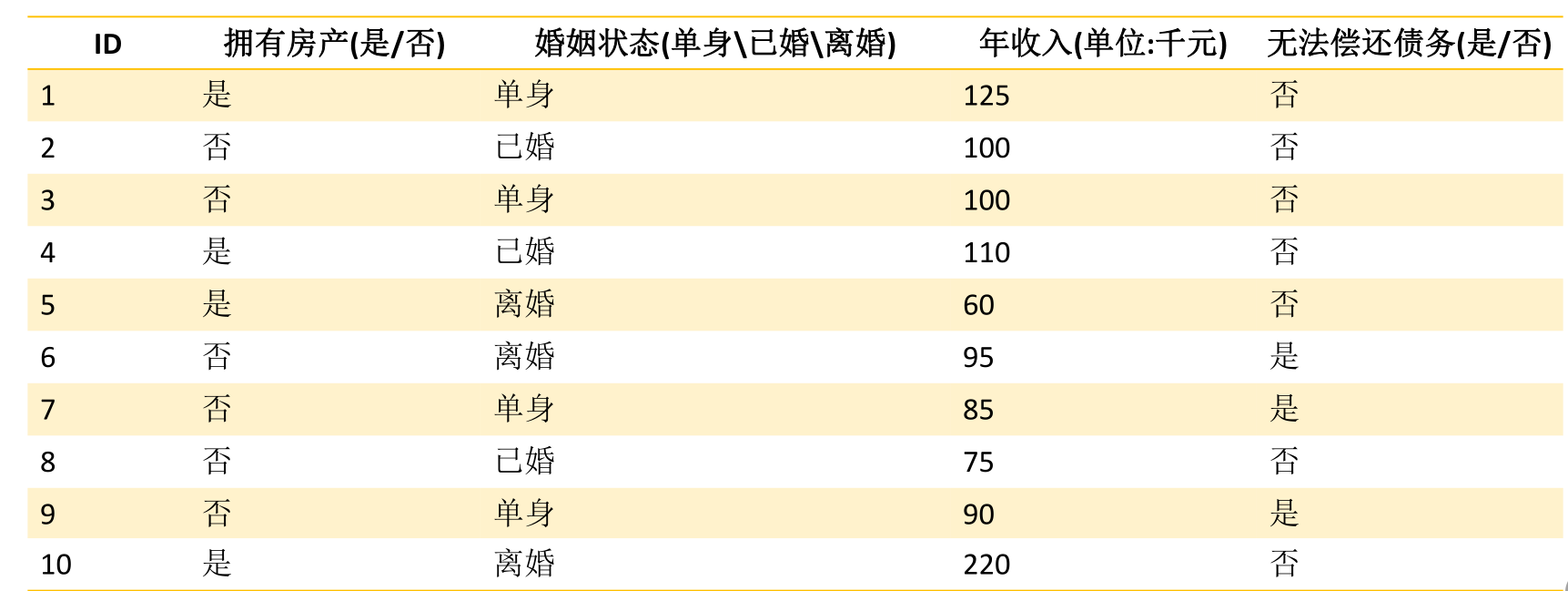
决策树基础算法主要有三类,分别为ID3,C4,5,CART,下表为他们的大致区别,我将分别讲解每一类的推导以及优缺点。

ID3算法
ID3算法是决策树的一个经典的构造算法,内部使用信息熵以及信息增益来进行构建;每次迭代选择信息增益最大的特征属性作为分割属性
C4.5算法
在ID3算法的基础上,进行算法优化提出的一种算法(C4.5);现在C4.5已经是特别经典的一种决策树构造算法;使用信息增益率来取代ID3算法中的信息增益,在树的构造过程中会进行剪枝操作进行优化;能够自动完成对连续属性的离散化处理;C4.5算法在选中分割属性的时候选择信息增益率最大的属性,涉及到的公式为:
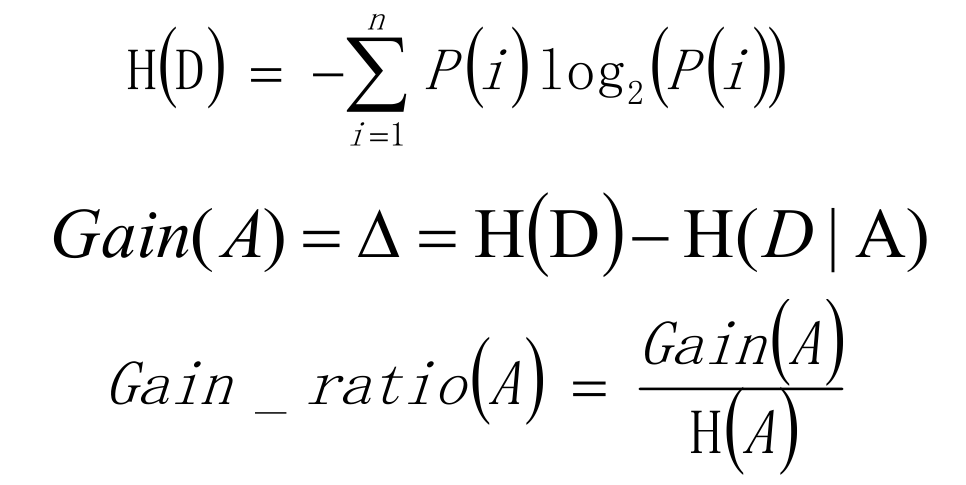
优点:
- 产生的规则易于理解
- 准确率较高
- 实现简单
- 缺点:
- 对数据集需要进行多次顺序扫描和排序,所以效率较低
- 只适合小规模数据集,需要将数据放到内存中
CART算法
使用基尼系数作为数据纯度的量化指标来构建的决策树算法就叫做CART(Classification And Regression Tree,分类回归树)算法。CART算法使用GINI增益作为分割属性选择的标准,选择GINI增益最大的作为当前数据集的分割属性;可用于分类和回归两类问题。CART构建是二叉树。
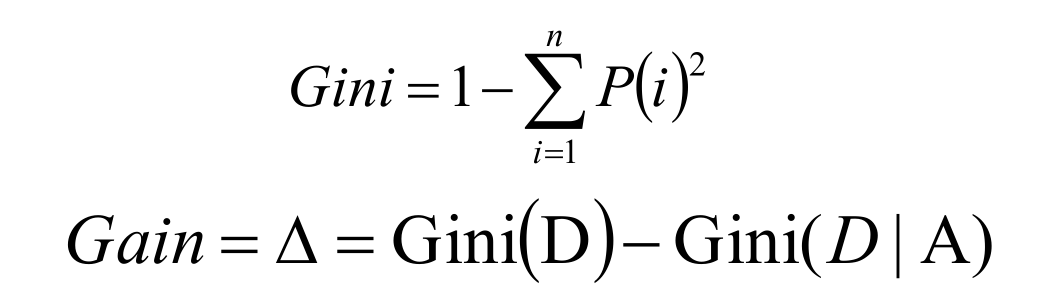
C4.5使用信息增益率、CART使用基尼系数。
最后
以上就是寂寞火车最近收集整理的关于决策树(理论初步)的全部内容,更多相关决策树(理论初步)内容请搜索靠谱客的其他文章。








发表评论 取消回复