搭建基于LXD的实验室GPU服务器
前言
最近本人搭建了2台实验室的GPU服务器,为了分享经验以及方便实验室其他人管理服务器,在这里记录下搭建的过程。在文章的有些地方我会贴出参考的链接,而有些地方我会直接使用参考的一些内容,侵删。同时由于我对于硬件和底层方面的了解有限,因此对于每个必要的步骤都会采用尽可能简单的做法,如果有更方便,更安全的实现方法,欢迎大家的指点。
另外由于本文篇幅有些长,您可以根据目录和需要查看过程中的某一环。
文章目录
- 搭建基于LXD的实验室GPU服务器
- 前言
- 方案综述
- 最终实现的效果
- 总体流程
- 选择各种工具的理由
- 详细流程
- 一.服务器主机安装Ubuntu18.04.6 Desktop LTS
- 1.下载对应的版本
- 2.制作启动盘
- 3.正式安装Ubuntu系统
- 二.服务器主机安装NVIDIA显卡驱动程序
- 1.安装前的环境准备
- 2.安装时详细步骤
- 三.配置Lxd容器及相关工具
- 1.安装Lxd相关软件
- 2.初始化Lxd
- 3.检查Lxd初始化情况
- 4.创建容器模板
- 5.建立容器模板和宿主机的共享文件夹
- 6.添加GPU设备到容器模板并安装驱动
- 7.确认容器模板可以开机自启
- 8.模板容器安装SSH和其他工具
- 9.模板容器安装Frp
- 四.确保宿主机能够被互联网访问
- 五.分配容器给用户
- 后记
方案综述
最终实现的效果
用户可以在任何可联网环境下通过分发的秘钥访问服务器主机(跳板机),在该主机上选择某个容器环境,进入到该隔离容器后便可在受控的基础上自由访问和使用服务器所有资源并且完全不会影响到其他用户,同时可通过共享文件夹实现资源的共享。
总体流程
1.在一台新出厂的服务器主机上,安装Ubuntu18.04LTS
2.安装Lxd实现宿主机上运行多个子操作系统供用户使用
3.使用Frp内网穿透工具来满足外地访问服务器的需要
选择各种工具的理由
1.Ubuntu18.04LTS:主要原因是稳定、兼容应用多、并且使用的人较多,出了什么问题也好查好解决。当然使用更新的UbuntuLTS版本应该问题也不大,不过我没有试过。
2.LXD:一般来说服务器主机的配置都不差,比如我配的其中一台有1TSSD+2T机械硬盘,i9-11900K的CPU,以及若干RTX3090显卡。如果每次只把这一台服务器分配给一个用户使用,那资源利用率可是严重不足。所以我们需用借助某种容器工具,来构造出多个可独立运行的隔离环境,让多个用户同时在隔离环境中使用服务器主机,从而提高资源利用率。可供选择的有Docker、LXD、Podman等,选择LXD的原因是其隔离程度高、可以在每个隔离环境中创建操作系统来全权限访问主机。
3.Frp:Frp是一款免费的内网穿透工具,而所谓“内网穿透”,通俗来讲即通过端口映射使得处于私有TCP/IP网络(内网)中的主机可与公网(外网)的主机之间建立连接。也就是说,如果服务器被分配了一个公网IP,那根本不需要内网穿透,因为服务器本来就可以与互联网中其他设备直接建立连接(不考虑防火墙等问题)。当然了,如果要实现比较稳定的连接效果,内网穿透最好也要借助某个自己的具有公网ip的服务器(阿里云、腾讯云等等)进行端口转发。(也可以使用VPN来代替内网穿透,这个要相对麻烦,我没有使用)
详细流程
一.服务器主机安装Ubuntu18.04.6 Desktop LTS
1.下载对应的版本
到Ubuntu官网或者其他源下载对应的操作系统镜像(iso)文件,我选择的是Ubuntu18.04.6 Desktop版本,是带Gui界面的,个人感觉在后续操作的时候会方便不少,毕竟是要配服务器的,不是要学怎么用Linux的。
当然也可以选择使用Server版本,但是会没有带Gui,有人说Server版会针对服务器有专门的优化,但是也有人说在后续(包括18.04)版本中它们两个性能差距不大。我个人是不了解,这个还是看个人偏好和具体要求,但是我后面介绍的过程是按Desktop版来的。
2.制作启动盘
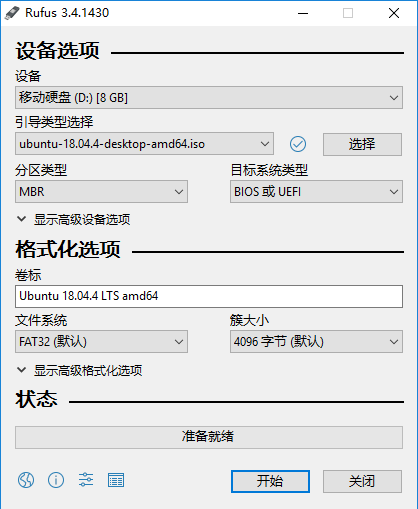
我用的是Rufus软件来进行制作U盘启动系统,这个比较简单,只需要选择好镜像文件和要被格式化的U盘,就可以一键制作了。详细过程可以参考这个:Ubuntu U盘启动工具Rufus制作。下面是Rufus的界面和选择的参数,一般除了引导类型选择之外,其他使用默认参数就好(图中OS是18.04.4的,我实际制作的是18.04.6的)。
3.正式安装Ubuntu系统
A.首先确认服务器是要准备安装双系统还是只安一个Ubuntu系统,然后按需查看磁盘占用情况,提前规划好分区,后面在安装过程中需要根据规划去进行分区。关于Linux系统的磁盘分区很有意思,根据硬件配置和使用情况去分配。可以参考一下这2篇文章:
https://www.cnblogs.com/chenlulouis/archive/2009/08/27/1554983.html
https://blog.csdn.net/u012388993/article/details/102548645
如果你像我一样打算省事、硬盘空间比较大、且只要在主机里安装一个ubuntu系统,那么你可以不做很详细的规划,在后面的安装过程中简单的把Ubuntu系统安到固态硬盘上,在那里分出一两个分区挂载/home,/var等;甚至不分区直接把根目录挂某个位置也可以接受。
注意请空出一块磁盘分区用作Lxd后端存储。
B.然后将制作好的启动盘插入到服务器主机中,然后在开机时想方设法进入到电脑的BIOS引导界面。不同厂商的电脑有不同的进入方法,但除了快捷键不同之外操作都大同小异:查阅对应厂商主机进入BIOS的快捷键,然后要在按下开机键之后,快速连续的狂按快捷键,直到看到提示并进入BIOS界面。
进入到BIOS界面之后找到具体的选项,调整开机加载操作系统的顺序(或者直接选择加载的内容),然后从U盘进入到ubuntu系统的安装界面。
C.之后就会出现ubuntu经典的紫色Gui以及安装向导,有比较重要的选择我按照顺序列举一下:
+选择语言,最好选择中文(简体),这样可以自带中文输入法和友好的中文提示。
+键盘布局也选择对应的中文布局
+选择不连接Wifi,加快向导安装速度
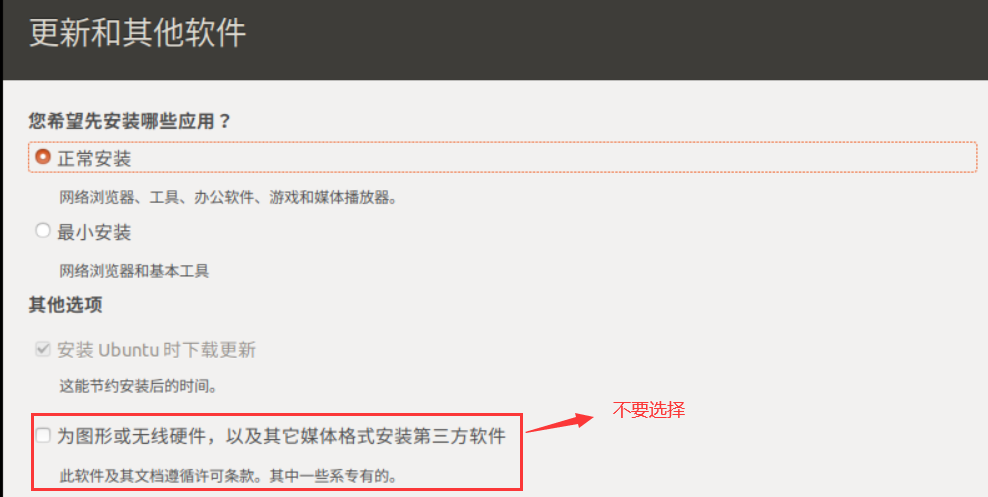
+在更新和其他软件界面,我选择的是正常安装,没有试过最小安装,比较怕的是最小安装少了后来软件要有的依赖。尤其注意在这个界面中,不要选择安装第三方驱动和工具,更不要配置安全启动密码,这些东西我们后来会自己处理,它自动给安装反而凭空添了麻烦。
+在安装类型界面,可以选择在主机上只安装一个Ubuntu还是使得Ubuntu和其它系统并存,如果自己之前已经规划了详细的分区方案,这里要选择其它选项,并进行详细的分区。
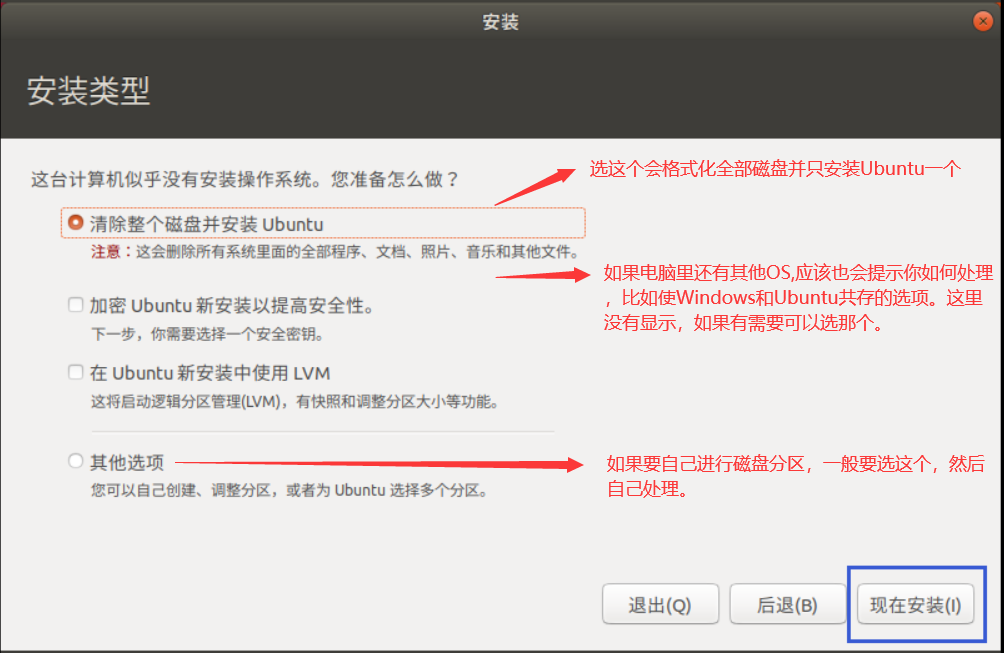
后面按照引导去自己选择,然后等待安装完成就可以了。安装完成后系统会提示要求重启,这时候实际上就可以把U盘拔下来了,如果你不放心可以等重启完成后再拔。同时在这次重启时,记得再进入BIOS界面,调整系统加载系统的顺序,并且将所谓的“安全启动(secure boot)”关闭。如何关闭安全启动,这个不同厂商的主机有不同的方法,或者也可以在ubuntu内设置,这个可以自行查阅。
至此Ubuntu系统安装完毕。
二.服务器主机安装NVIDIA显卡驱动程序
这一步非常容易出问题,网上的教程虽然多,但是怎么说的都有。我自己在两次安装时,都采用了下面的流程,没有什么问题。建议大家在实际操作之前多看几篇文章,取其可靠的共同之处,去掉没有必要的繁杂步骤。
1.安装前的环境准备
A.首先在进入刚刚安装完毕的系统后,系统会提示进行软件更新:
+要不要更新成ubuntu20.04系统,这个是绝对不要选择的;同时我们还可以根据提示,去设置停止自动检测系统升级的更新。
+要不要安装完整的语言支持,这个要进行安装。
B.然后我们需要安装必要的依赖环境:
sudo apt-get update
sudo apt-get install build-essential
C.由于我们在后面安装驱动时需要进入Ubuntu系统的命令行界面(不是终端),所以我们需要先进入到系统命令行界面去检查一下,该界面里会不会每隔一段时间产生错误或警告信息。这一步是很有必要的,因为如果有报错的话,报错信息会截断正在输入的命令,这样不仅乱而且没有办法按Backspace删除正在输入的命令。
至于怎么进入和退出系统的命令行界面,我是按Ctrl+Alt+F2进入,按Ctrl+Alt+F1退出,如果有差异可以自行查阅其他资料。
进入后等个1分钟左右,看看有没有报错,我是遇到了这个错:
PCIe Bus Error:severity=corrected,type=Physical Layer...
可以这样解决:
进入到系统grub文件中(/etc/default/grub)
找到“GRUB_CMDLINE_LINUX_DEFAULT=“quiet splash”;将其修改为GRUB_CMDLINE_LINUX_DEFAULT=“quiet splash pcie_aspm=off”
D.由于在Ubuntu系统的命令行界面中,默认不支持显示中文,并且输入中文很麻烦;同时我们安装的Ubuntu是中文简体版的,所以有些路径中包含中文。这样的话,如果我们在命令行界面里使用指定的文件时,该文件路径中包含中文会很麻烦。所以我们需要提前设置好一个文件夹,该文件夹不包含中文路径,把要在命令行界面使用的文件都放在那里。
2.安装时详细步骤
至于在安装时的详细步骤,我是全程参考这篇文章,基本没有什么问题:
RTX3090在ubuntu18.04下安装NVIDIA驱动、cuda、cudnn
我只按照该文章的步骤装了NVIDIA驱动,至于Cuda和Cudnn,想要顺便安装应该也没什么问题。
三.配置Lxd容器及相关工具
我认为在配置某个工具之前有必要搞清楚这个工具到底是做什么用的。而Lxd最主要的目标就是使用 Linux 容器而不是硬件虚拟化向用户提供一种接近虚拟机的使用体验。可以理解为借助Lxd这种容器管理工具,我们可以在一台主机上同时运行并管理多台机器,每一个容器模拟了一台可全权限访问资源的主机。
对于不同的需求来说,基于Lxd的容器管理方案在内部软硬件方面的初始配置大同小异。但是关于如何在网络中访问这些容器,则需要根据需求做出较大调整。Lxd提供的默认网络访问方式为宿主机通过 DHCP 的方式给每个容器分配经过NAT的IP地址,这样外网是无法直接访问处于内网的某个容器的。注意这里的内网指的是所有的Lxd容器构成的局部网络,不包括宿主机(即运行Lxd的服务器)和其他位于互联网中的主机,所以我们需要一种对于用户来说能够通过网络访问到这些位于内网的容器的方式,因为容器的ip只在内网环境才可以相互识别并使用嘛。那么怎么做呢,答案是使用内网穿透,使得用户通过宿主机的端口映射访问到内网的容器。可能我说的不太好理解,但是有一点很清楚:如果使用Lxd默认的网络访问方式,比较合理的方案是在宿主机和容器之间进行内网穿透来访问容器。
我们当然可以修改Lxd默认的网络访问方式,但是由于我对网络方面的了解不是很多,所以使用的是比较简单的默认方式。
在安装Lxd容器时,我大部分内容都参考了这篇文章里的Lxd部分:搭建实验室公共 GPU 服务器。不过由于步骤稍有不同,我会把我安装的流程记录下来,侵删。
1.安装Lxd相关软件
要安装的软件分别为:
- LXD:用于创建和管理容器
- ZFS:用于管理物理磁盘,支持 LXD 高级功能,负责容器存储。
- Bridge-Utils:用于搭建网桥,负责容器上网。
sudo apt-get install lxd zfsutils-linux bridge-utils
2.初始化Lxd
在终端内运行以下命令配置Lxd初始化参数:
sudo lxd init
这是上面提到的文章里的截图,我会在下面按顺序进行解释:
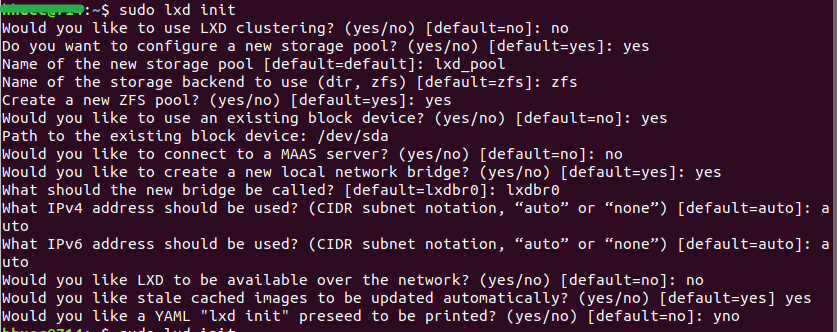
- 是否创建LXD Clustering?——否,用不到。
- 是否配置一个新的存储池?——是,我们安装ZFS就是为了让它管理用于存储容器的存储池的。
- 存储池名字?——随便起,但要记下来。
- 使用的后端存储管理工具——当然是刚刚安装的zfs
- 创建一个新的ZFS pool吗?——创建
- 是否使用已存在的磁盘分区用作Lxd存储?——填yes,不然很麻烦
- 磁盘分区的路径?——这个可以通过查询空闲的磁盘分区得到(sudo fdisk -l),不过这里要注意,最好填写真实的磁盘分区比如“/dev/sda”,而不是虚拟分区比如“/dev/loop5”。
- 是否连接MAAS Server?——不连接,用不到。
- 是否创建新的网桥?——创建,这个要看对服务器上网策略的选择,我使用的是最简单的也是默认的方式,通过为Lxd设置一个网桥,让容器都通过宿主机进行NAT方式的上网。如果有其他需求可以查阅其他资料。
- 新网桥的名字?——随便起,但要记下来。
- 使用IPv4吗?——auto,使用
- 使用IPv6吗?——auto,使用
- 是否配置Lxd在网络上可见?——否,在默认配置下填否就可以,除非要进行其他网络配置。
- 是否允许过时缓存自动更新?——是
- 打印YAML格式的初始化配置信息——否,用不到。
3.检查Lxd初始化情况
可以使用下面的命令测试和检查,如果显示没有什么异常可以直接进行下一步。
sudo zpool list <your storage pool name> # 查看ZFS的后端存储池
sudo lxc info # 查看LXD的配置信息
sudo lxc profile show default # 查看默认容器配置
4.创建容器模板
通过创建容器模板,我们在日后需要新容器的时候可以直接copy模板,然后只要做少量修改就可以分配使用了,非常节省时间。
首先我们需要为容器模板指定其操作系统版本使其可以正常运行,这通过为其指定特定的系统镜像来实现。我们可以运行下面的命令来进行:
# 创建一个remote链接,指向TUNA镜像站
sudo lxc remote add tuna-images https://mirrors.tuna.tsinghua.edu.cn/lxc-images/ --protocol=simplestreams --public
# 查看镜像列表,寻找合适的镜像的FINGERPRINT,用于下载
sudo lxc image list tuna-images:
按照需要寻找合适OS版本(这里我找的也是Ubuntu18.04LTS):
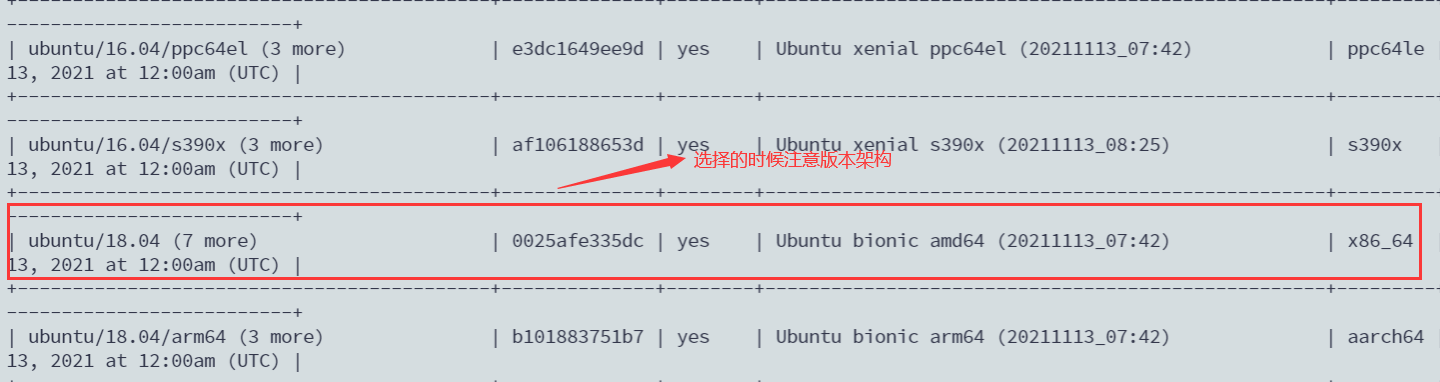
最后根据找到的系统镜像指纹下载镜像并创建容器:
# FINGERPRINT是镜像的指纹,在上条命令下查找,ContainerTemplateName是自己定义的容器模板名称
sudo lxc launch tuna-images:<FINGERPRINT> <ContainerTemplateName>
最后可以使用sudo lxc list查看创建的容器、使用sudo lxc exec <ContainerTemplateName> bash进入到指定容器模板的终端内。
5.建立容器模板和宿主机的共享文件夹
通过建立模板和宿主机的共享文件夹,我们可以实现多用户的文件共享功能。也就是说,如果我们配置了某个模板和宿主机的共享文件夹,那么该模板、通过该模板产生的容器和宿主机都可以共享使用那个文件夹。
首先到宿主机下建立一个文件夹用作共享文件夹:
sudo mkdir <your share-file path>
然后使得容器模板的访问权力和宿主机暂时相同
sudo lxc config set <ContainerTemplateName> security.privileged true
最后运行命令设置共享目录,其中shareName为虚拟的设备名称,lxd会虚拟出该设备并导通接通两者共享目录,path1为宿主机下共享目录路径,path2为容器下共享目录路径。
sudo lxc config device add <ContainerTemplateName> <shareName> disk source=<path1> path=<path2>
6.添加GPU设备到容器模板并安装驱动
A.我们之前通过系统镜像启动了容器模板,但是这个容器现在非常干净,甚至在它看来连GPU都没有。因此我们需要为其指定宿主机的GPU:
# 为容器添加所有GPU
sudo lxc config device add <ContainerTemplateName> gpu gpu
# 添加指定GPU
sudo lxc config device add <ContainerTemplateName> gpu0 gpu id=0
B.然后我们也需要像原先安装Ubuntu系统一样为这个容器内的“主机”安装驱动,并且安装的驱动版本要和宿主机的驱动版本相同,否则会出现意想不到的麻烦:
# 进入容器模板
sudo lxc exec <ContainerTemplateName> bash
# 安装驱动
sudo sh NVIDIA-Linux-x86_64-xxx.xx.run --no-kernel-module
在具体安装过程中,也会有一些安装选项,我们的选择和之前宿主机时安装的选择是一样的,可以参考那部分的内容。然后运行nvidia-smi看一下驱动是否安装成功.
C.最后需要查看容器模板内的/dev文件夹下有没有nvidia-uvm这个文件,也就是说,看一下该容器模板能否识别到nvidia-uvm这个设备。如果没有需要给容器模板添加这个设备(从宿主机的对应位置):
lxc config device add <ContainerTemplateName> nvidia-uvm unix-char path=/dev/nvidia-uvm
如果我们发现宿主机也没有该文件,那么需要手动挂载该设备到宿主机上,然后再执行上面的命令:
nvidia-modprobe -u -c=0 # 或者modprobe nvidia-uvm
mknod -m 666 /dev/nvidia-uvm c `grep nvidia-uvm /proc/devices | awk '{print $1}'` 0
7.确认容器模板可以开机自启
有人会说服务器是一直不关机的啊,测什么开机能不能自启动?但是服务器难免会遇到被断电的情况,如果在那种情况下服务器在开机后还需要有人专门跑到服务器机房敲敲打打,那真的太麻烦了,因此我们可以通过保证服务器重启后可以自启动所提供的服务来确保其稳定性。
就我所知,Lxd容器应该是默认开机自启的,不过由于版本的问题,最好亲自试一下。我们需要重启服务器主机,然后使用sudo lxc list查看容器的状态,如果发现其没有自启动,则需要手动指定自启动:
lxc config set <ContainerTemplateName> boot.autostart true
如果运行上面的命令报错,而且大意是说什么路径不存在等等,那么需要检查一下宿主机上我们刚刚手动挂载的nvidia-uvm是不是存在,如果不存在则说明我们需要在开机后运行开机脚本手动挂载nvidia-uvm。关于在Ubuntu18.04设置开机自启动脚本,网上的说法都很一致,可以参考一下这篇文章:Ubuntu18.04设置开机自启脚本。在开机脚本文件(比如/etc/rc.local)中加入nvidia-modprobe -u -c=0来达到手动挂载nvidia-uvm设备的目的。
与此同时,我们最好把Lxd容器的开机自启动时间延后一些,留出一段时间让系统先把该挂载的设备挂载上,然后再自启动,这样不会像前面一样报什么路径不存在的错导致无法自启动:
lxc config set <ContainerTemplateName> boot.autostart.delay 2 # delay后面的数字单位是秒,1秒或者2秒足够了
8.模板容器安装SSH和其他工具
由于我们的容器需要被远程连接访问,因此需要安装ssh服务,过程比较简单:
sudo apt-get install openssh-server
然后启动服务就可以了:
sudo service ssh start
为了保证安全,也可以让用户使用私钥远程登录,而不是密码。首先切换到某个普通用户中,然后进入到~/.ssh目录里,如果没有该目录,则需要用户先在本地自己登录一下生成.ssh文件夹:
ssh <usrname>@127.0.0.1
然后就可以按照流程生成私钥了:
# 进入SSH目录
cd ~/.ssh
# 生成RSA
ssh-keygen -t rsa
# 复制公钥内容到authorized_keys
cat id_rsa.pub >> authorized_keys
# 赋予id_rsa正确的权限
sudo chmod 400 id_rsa
# 重启SSH服务
sudo service ssh restart
将生成的id_rsa文件复制出来将来可以把它交付给用户使之使用秘钥登录。
同时我们可以在这时候安装一些开发工具和环境了,比如conda、python、cuda等,不过作为容器模板来说,我认为最好不要安装,将来通过模板生成容器后让用户自己安装也不迟。
9.模板容器安装Frp
如果我们使用了Lxd默认的网络访问方式,那么最好通过内网穿透来让位于内网中的容器能够被外网访问到。内网穿透的工具有很多,比如Frp、花生壳等等,这里我使用了Frp,因为配置起来十分的简单。
Frp工作的方式是这样的:首先需要一台位于外网的主机(这台主机必须能够被位于内网的主机们访问到),在这台主机上运行frp-server程序;然后在处于内网中的主机上运行frp-client程序。这中间还会涉及到客户端和服务端之间远程连接的服务端口号以及映射端口号等等配置参数,这些参数分别由ini文件指定来保证内网穿透的正常运行。这是frp的文档,有兴趣可以去详细的学习一下。
我们到frp的github主页上找到最新的release版本,下载并解压。可以得到我们关心的4个文件:frps(就是frp-server程序)、frps.ini、frpc(就是frp-client程序)、frpc.ini。其中前两个应该保存在服务端,在我们的需求下,它们应该保存在服务器宿主机(运行着Lxd管理程序的Ubuntu18.04.6 Desktop)上;而后面两个应该保存在Lxd容器上。
下面是宿主机上frps.ini的内容:
[common]
# 指定服务端和客户端绑定的端口
bind_port = 7001
# frp管理后台端口,请按自己需求更改
dashboard_port = 7500
# frp管理后台用户名和密码
dashboard_user = admin
dashboard_pwd = admin
enable_prometheus = true
# frp日志配置
log_file = /var/log/frps.log
log_level = info
log_max_days = 3
# 限制端口,要对端口做好管理
allow_ports = 3000-4000
# 最大连接数量
max_pool_count = 20
注意frps尽量和frps.ini放在同一个文件夹下,为后面可能的修改提供便利。服务端运行./frps -c ./frps.ini开启服务。
下面是容器上frpc.ini的内容:
[common]
server_addr = 10.187.60.1 # 这个地址是在初始化Lxd时,所创建的网桥的ip地址,可以通过ip a查看
server_port = 7001 # 刚刚服务端的bind_port
[ssh-template1] # 注意这里表示协议的名称,一个客户端(即一个容器)一个名称,不能有重复
type = tcp # 默认
local_ip = 127.0.0.1 # 默认
local_port = 22 # 默认
remote_port = 3000 # 一个客户端(即一个容器)一个映射端口,不能有重复
# console or real logFile path like ./frpc.log
log_file = ./frpc.log
# trace, debug, info, warn, error
log_level = info
log_max_days = 3
注意frpc尽量和frpc.ini放在同一个文件夹下,为后面可能的修改提供便利。客户端运行./frpc -c ./frpc.ini启动连接服务端的进程。
在服务端和客户端进程都开始运行后,我们可以在宿主机的终端里测试一下连接情况,运行:
ssh -p 3000 usrname@10.187.60.1
注意-p后面的参数是要访问的容器的frpc.ini内对应的remote_port号,usrname是要访问的容器的某个用户名,@后面的ip地址则是宿主机Lxd网桥的ip地址。如果运行正常应该出现类似的提示:
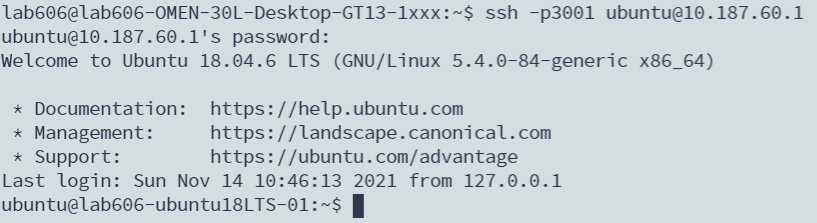
先别急,到这里都正常运行表示我们已经完成了大半的Frp配置了。下面要处理一个问题,之前我们运行./frpc -c ./frpc.ini什么的都是在终端里运行的,如果关掉终端,那么相应的进程被杀死,我们的frp就不能正常运行啦!
我们可以使用nohup命令让普通进程变成后台的守护进程来达到关掉终端,进程仍然运行的目的;但是比较推荐的一种方式是自定义服务,然后借由systemctl来进行服务的管理,这样不仅可以使得进程更加可控、可定义开机自启动而且还可以通过journalctl来管理frps或者frpc产生的日志,非常优雅。
自定义服务的方法如下:
+在/lib/systemd/system文件夹下创建名为frps.service或者frpc.service的文件。
+编辑并填入类似内容:
[Unit]
Description=frps service
After=network.target syslog.target
Wants=network.target
[Service]
Type=simple
#之前启动服务或连接服务的命令填在这里
ExecStart=<files path>/frps -c <files path>/frps.ini
[Install]
WantedBy=multi-user.target
+启动服务:sudo systemctl start frps
+启用开机自启动服务:sudo systemctl enable frps
+检查日志:sudo journalctl -u frps或者sudo systemctl status frps
四.确保宿主机能够被互联网访问
刚刚我们使用内网穿透,保证了外界用户在宿主机上可以通过端口映射访问所有的容器。要保证容器最终能够被位于互联网上的用户访问,还需要确保宿主机可以被外界所访问。
这里有两种情况:
一种是要配的服务器本身被分配了一个公网IP或者是具有同样效果的IP地址,外界可以直接访问该服务器。如果是这样,那什么工具都不用再配了,宿主机本来用那个IP就可以被外界用户访问到,可能唯一需要做的就是设置一下防火墙以及访问的黑白名单来保证安全了。在这种情况下,用户要访问某个容器,可以直接通过之前设置的在宿主机上运行的frp-server来进行端口映射:
ssh -p 3000 usrname@<公网IP地址>
第二种情况是没有公网IP被分配给服务器,服务器主机只能在处于同一网段下的局域网内被访问到,比如校园网或者某个路由器下的网络。对于这种情况,我们需要借助某个公网IP,让那个IP代理我们的服务器进行消息转发。嗯,你可能想到使用VPN了,确实可以,但是如果想要达成稳定的代理效果,恐怕需要一番功夫来挑选和配置;而另一方面,内网穿透也可以达成同样的效果,既然我们之前在“服务器主机(宿主机)—容器”层面已经成功实施了基于Frp的内网穿透,那么我们可以再次在“云服务器—要配置的服务器主机(宿主机)”层面再用一次,这样就可以确保宿主机能够被互联网上其他用户所访问到了。
所以,我们的思路是借助某个云服务器,由于外界用户可以访问该云服务器,并且我们的本地服务器(宿主机)也可以访问到,那么我们只需要让宿主机借助内网穿透在云服务器上进行端口映射的能力,外界用户就可以访问到宿主机了。这里要注意的是,如果我们打算采取这种方案,那么我们一共会进行2次内网穿透,第一次内网穿透用于保证本地服务器(宿主机)可以被互联网上其他用户所访问到,如果本地服务器具有公网IP或者打算采用VPN工具则没有必要进行这次穿透;而第二次内网穿透用于保证在宿主机上运行的Lxd容器可以被宿主机所访问到,在默认Lxd网络配置下是最好必须要进行的。
根据上一段所说的思路,我们首先挑选一个云服务器,阿里云或者腾讯云等等都可以,然后在上面运行frps,这是云服务器上frps要用到的frps.ini,仅供参考:
common]
bind_port = 7000 # 这里建议绑定的端口最好和之前那次内网穿透绑定的端口区分开
# frp日志配置
log_file = /var/log/frps.log
log_level = debug
log_max_days = 2
# 限制端口,同样建议和之前限制的端口号区分开
allow_ports = 2000-3000
max_pool_count = 20
接着在宿主机上运行frpc(我们之前那次是在宿主机上运行的frps)。这是要用的frpc.ini,由于云服务器和本地服务器的连接可能有波动,因此加入了health_check,同样仅供参考:
[common]
server_addr = <公网IP地址>
server_port = 7000
# connections will be established in advance, default value is zero
pool_count = 10
[ssh]
type = tcp
local_ip = 127.0.0.1
local_port = 22
remote_port = 2000
# frpc will connect local service's port to detect it's healthy status
health_check_type = tcp
# health check connection timeout
health_check_timeout_s = 3
# if continuous failed in 3 times, the proxy will be removed from frps
health_check_max_failed = 4
# every 10 seconds will do a health check
health_check_interval_s = 10
# console or real logFile path like ./frpc.log
log_file = ./frpc.log
# trace, debug, info, warn, error
log_level = info
log_max_days = 3
最后配置frp的后台运行和自启动,这个前面已经说过就不赘述了。但是在自定义frpc服务的时候,由于云服务器和本地服务器之间的连接没有那么稳定,需要加入连接失败的处理逻辑,如下是本地服务器(宿主机)内的frpc.service的内容,仅供参考:
[Unit]
Description=frpc service
After=network.target syslog.target
Wants=network.target
[Service]
Type=simple
#启动服务的命令
ExecStart=<files path>/frpc -c <files path>/frpc.ini
Restart=on-failure # 在服务启动失败时重启
RestartSec=5s # 在重启事件发生的5秒之后重启服务
[Install]
WantedBy=multi-user.target
那么以这种内网穿透的网络访问方式,用户如果想要访问某个容器,需要首先登录到宿主机上,然后在宿主机上再用一次ssh,选择自己的容器进行登录:
ssh -p <宿主机的远程端口号> <宿主机上某Linux用户名字>@<云服务器的公网IP>
ssh -p <容器的远程端口号> <容器上某Linux用户名字>@<宿主机上的Lxd网桥IP>
可能有人会觉得麻烦,的确对于用户来说是有一些的。但是这样做可以让宿主机变成跳板机,而服务器管理员可以在跳板机上编写登录容器的程序,除了让用户根据ssh密码和秘钥登录之外,还可以自定义访问的规则,比如根据GPU使用时间、内存使用量等等,同时该程序可以安静的保存在宿主机上,不会被其他人访问到,十分安全。就我所知有一些实验室的确也是这样做的。
另外,用户可以通过Xshell、MobaxTerm等工具自定义远程连接规则,来达成一键连接的效果。
五.分配容器给用户
到这里,其实我们已经完成了配置GPU服务器的主要工作了。这一部分无非就是根据之前的容器模板,创建新的容器,修改一些参数,然后就可以直接把新容器交付给用户使用了。
首先复制容器模板:
# 复制容器 参数一为模板容器名称,参数二为目标容器名称
sudo lxc copy <ContainerTemplateName> <newContainerName>
# 运行新容器
sudo lxc start <newContainerName>
新容器中有一些参数为了美观可以修改,比如hostname,如有需要请自行修改。而有一些参数是必须要修改的,比如用于SSH登录的Linux用户密码以及秘钥、容器内frpc.ini中的SSH协议名称和远程端口号(每个容器必须独一无二),至于修改它们的方法,和我前面介绍的大同小异,在这里就不再赘述了。
另外如果你对用户不放心,还可以在分配给他之前先做个快照:
sudo lxc snapshot <ContainerName>
(再次感谢这篇文章的作者,很多关于Frp的内容参考自这里)
后记
至此关于搭建实验室GPU服务器的过程就记录完毕了,字数着实有些多,但是实际配置的过程没有看起来那么麻烦。感觉有些事情和配服务器很像,第一次做可能会绕很多弯路,但是之后就熟练的让人心疼了。我仅把我走过的配置服务器的路径呈现给大家,希望大家可以少走一些弯路,谢谢!
最后
以上就是苗条大叔最近收集整理的关于搭建基于LXD的实验室GPU服务器(Ubuntu+LXD+Frp)搭建基于LXD的实验室GPU服务器的全部内容,更多相关搭建基于LXD内容请搜索靠谱客的其他文章。








发表评论 取消回复