前言
java的线程池最根本的都是使用的ThreadPoolExecutor,其构造方法的参数、线程增长顺序、拒绝策略经常在面试中被问到。
但是有一个不常见的问题:keepAliveTime是怎么生效的?非核心线程是怎么超时退出的呢?其实这个问题在我们真正看完ThreadPoolExecutor的源码和逻辑之后,其实是很容易说清楚的。
先说结论:在线程池里的线程会一个死循环里阻塞式地从队列里获取任务来执行,而当线程数超过核心线程数的时候,这里的阻塞时间是keepAliveTime,超过这个时间没有获取到任务,会标记为超时。因为是死循环,下一次循环进来的时候首先判断超时了,而且当前线程数比核心线程数多,这个线程就会return null,然后结束执行。
所以,其实所有的线程都是一样的,并没有区分是核心线程还是非核心线程,只是在没有任务的时候,过了超时时间会有一些线程结束执行退出,剩下的就是核心线程了。
调试分析
代码
import java.io.IOException;
import java.util.HashMap;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.LockSupport;
public class H {
public static final ThreadPoolExecutor THREAD_POOL = new ThreadPoolExecutor(
10,
20,
1,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10));
public static void main(String[] args) throws InterruptedException, IOException {
for (int i = 0; i < 30;i++) {
THREAD_POOL.execute(() -> {
LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(1));
System.out.println("test");
});
}
CountDownLatch countDownLatch = new CountDownLatch(1);
countDownLatch.await();
}
}
找到位置
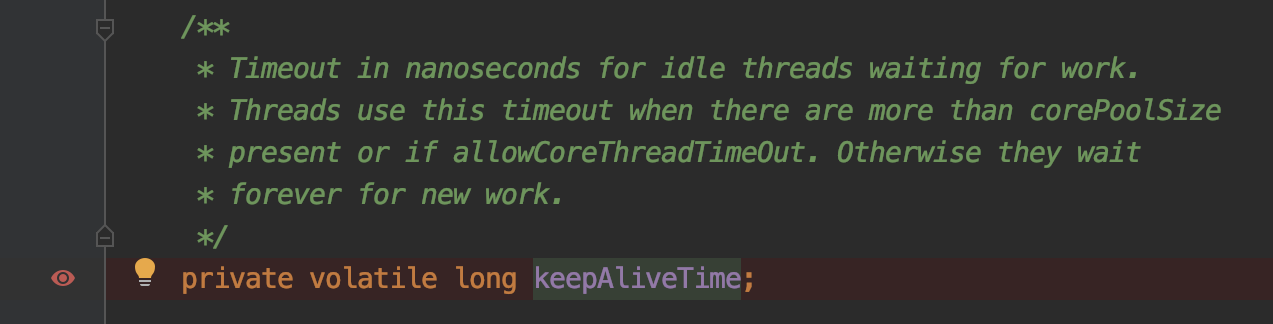
可以先在keepAliveTime打一个成员变量断点,对应配置修改成下面的形式。我们debug程序,就能看到这个keepAliveTime在哪里被执行到。然后就可以针对性的进行分析。
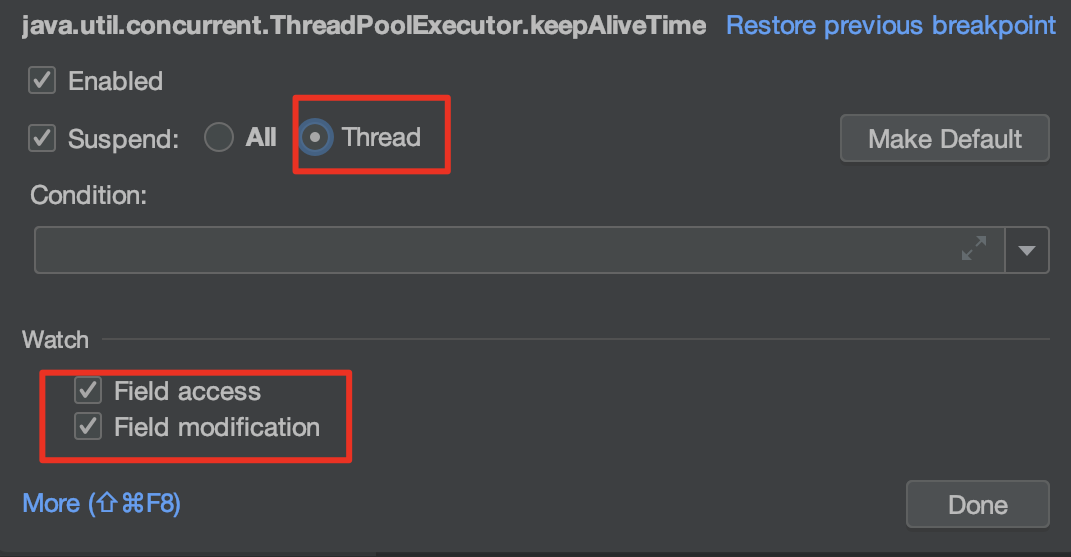
查看源码
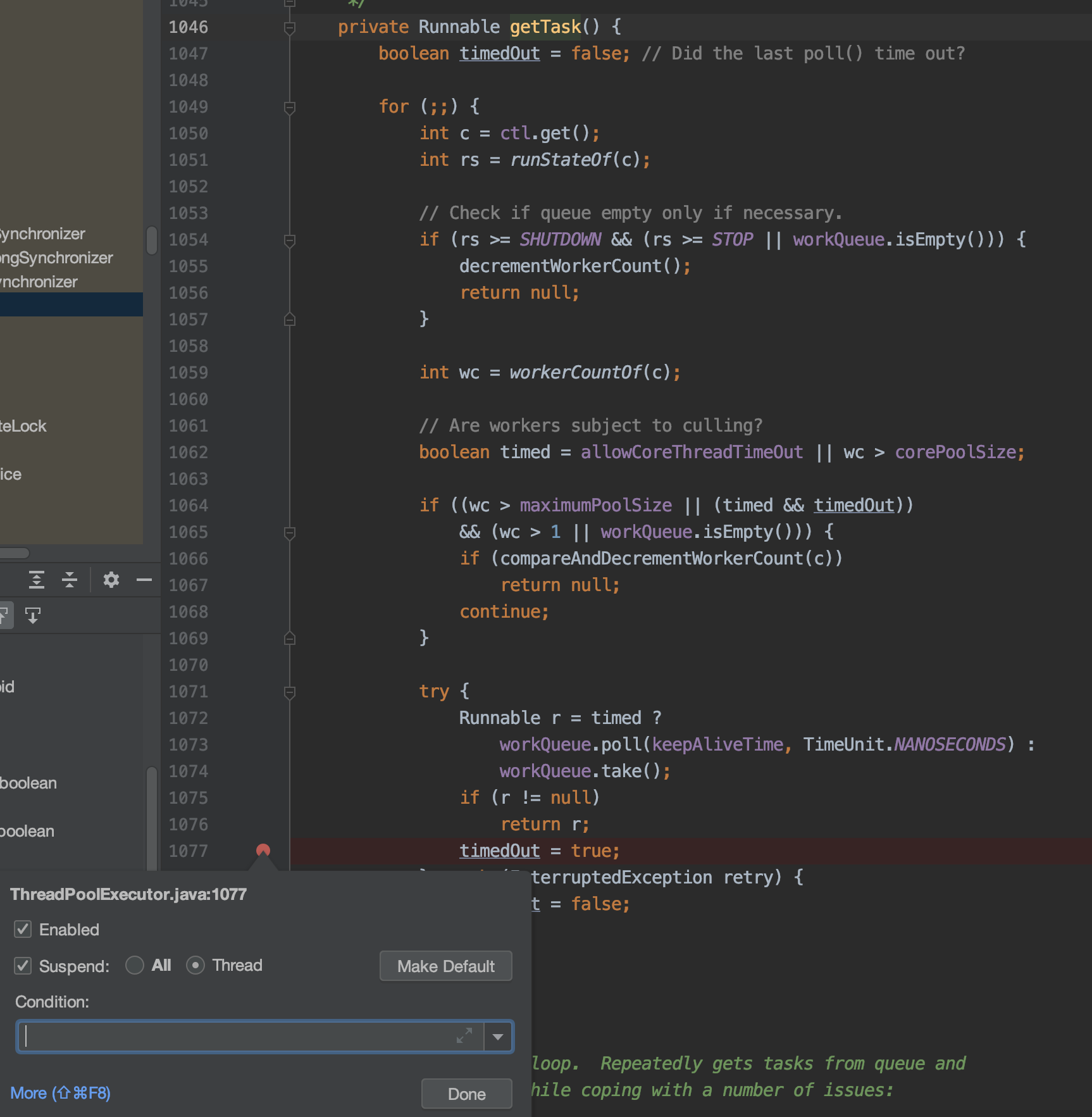
从上面的操作中我们找到使用位置是在getTask方法里,这里的调用关系是Worker.run() -> runWorerker() -> getTask()。
Worker就是线程池里的线程,runWorker就是线程的执行逻辑,其实主要是调用getTask方法获取任务,getTask的逻辑就如我们上面所说。
打如下断点,线程走到这个位置的时候说明等待已经超时,然后继续执行循环就能看到,线程会执行线程数减一的操作然后退出执行。(这里的断点一定是Thread的,不然单步调试的时候有可能会有其他线程直接执行,然后退出。当前断点线程会成为核心线程保留下来)
最后
以上就是贪玩大门最近收集整理的关于ThreadPoolExecutor 是怎么控制非核心线程超时的前言调试分析的全部内容,更多相关ThreadPoolExecutor内容请搜索靠谱客的其他文章。








发表评论 取消回复