在Hadoop1中HDFS和MapReduce均采用了master/slave结构,这种结构虽然具有设计非常简单的优点,但是同时存在master单点故障的问题,所有长时间Hadoop处于仅用于离线存储和计算。Hadoop2中HDFS同样面临着单点故障问题,但由于每个MapReduce作业拥有自己的作业管理组件(ApplicationMaster),因此不再存在单点问题,但新引入的资源管理系统YARN也采用了Master/slave结构,同样出现了单点故障问题。
作为一个分布式系统,YARN必须具有一个特点就是高容错性,因此YARN需要考虑ApplicationMaster、NodeManager、Container和ResourceManager等服务或组件容错性、这些服务或组件的容错性机制如下:
ApplicationMaster容错:不同类型的应用程序拥有不同的ApplicationMaster,而ResouceManager负责监控ApplicationMaster的运行状态,一旦发现它运行失败或者超时,会为其重新分配资源并启动它,至于启动之后ApplicationMaster内部的状态如何恢复需要由自己保证,比如MRAppMaster在作业运行过程中将状态信息动态记录到HDFS上,一旦出现故障重启后,它能够从HDFS读取并恢复之前的运行状态,以减少重新计算带来的开销
NodeManager容错:如果NodeManager在一定时间内未向ResouceManager汇报心跳信息,则ResouceManager认为它已经死掉了,会将它上面所有正在运行的Container状态置为失败,并告诉对应的ApplicationMaster,以决定如何处理这些Container中运行的任务
Container容错:如果ApplicationMaster在一定时间内未启动分配到的Container,则ResouceManager会将该Container状态置为失败并回收它,如果一个Container在运行过程中,因为外界原因导致运行失败,则ResouceManager会转告给对应的ApplicationMaster,由它决定如何处理
Hadoop HA基本框架
在Master/slave架构中,为了解决Master的单点故障问题通常采用热备方案,即集群中存在一个对外服务的active Master和若干个处于就绪状态的Standby Master,一旦Active Master出现故障,立即采用一定的策略选取某个Standby Master转换为Active Master以正常对外提供服务,同样Hadoop2也是采用这种方案解决各系统的单点故障问题。
Hadoop2中的HDFS和YARN均采用了基于共享存储的HA解决方案,即Active Master不断将信息写入一个共享存储系统,而Standby Master则不断读取这些信息,以与Active Master的内存信息保持同步,当需要主备切换时,选中的Standby Master需先保证信息完全同步后,再将自己的角色切换至Active Master,目前而言,常用的共享存储系统有以下几个
Zookeeper: Zookeeper是一个针对大型分布式系统的可靠协调系统,提供的功能包括统一命名服务、配置管理、集群管理、共享锁和队列管理等,需要注意的是,Zookeeper设计目的并不是数据存储,但它的确可以安全可靠的存储少量数据来解决分布式环境下多个服务之间的数据共享问题。
NFS(Network File System): NFS是一种非常经典的数据共享方式,它可以透过网络,让不同的机器和不同的操作系统之间彼此共享文件
HDFS: Hadoop自带的分布式文件系统,由于它本身存在单点故障问题,因此Hadoop的单点问题不能够通过他解决
BookKeeper:由Zookeeper项目产生的一个分支项目,主要用于可靠地记录日志流,它采用的是分布式多副本解决方案
QJM(Qurom Journal Manager): QJM的基本原理就是用2N+1个节点存储数据,每次有多数据(大于等于N+1)节点成功写入数据即认为该次写成功,并能保证数据高可用,该算法最多容忍N台机器挂掉,如果多于N台挂掉,则这个算法就会失败。
在Hadoop2中,YARN HA采用了基于zookeeper的方案,而HDFS HA则提供了基于NFS、BookKeeper和QJM的三套实现方案,由于引入了共享存储系统,Hadoop中各个系统实际上是“share nothing but NameNode”,尽管几个系统采用的共享存储不同,但它们的HA架构是相同的,均分为手动模式和自动模式,其中,手动模式是指由管理员通过命令进行主备切换,这通常用于服务升级,自动模式可降低运维成本,但存在潜在危险,手动模式架构如下图,该模式中,Master自身需实现HAServiceProtocol协议,或者由一个实现该协议的服务控制,而管理员可通过一个HAServiceProtocol协议客户端控制各个Master状态。
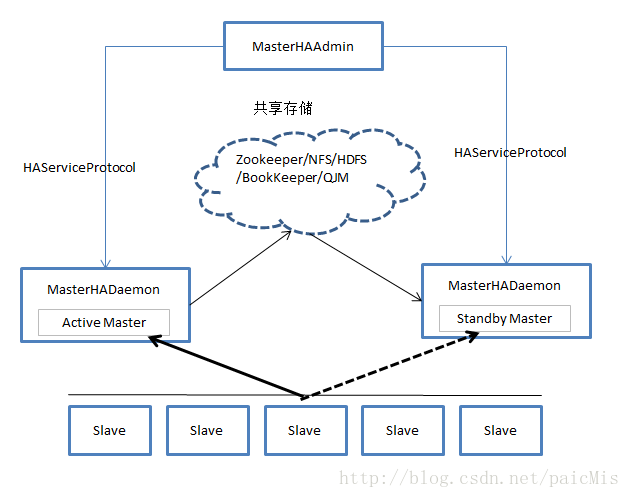
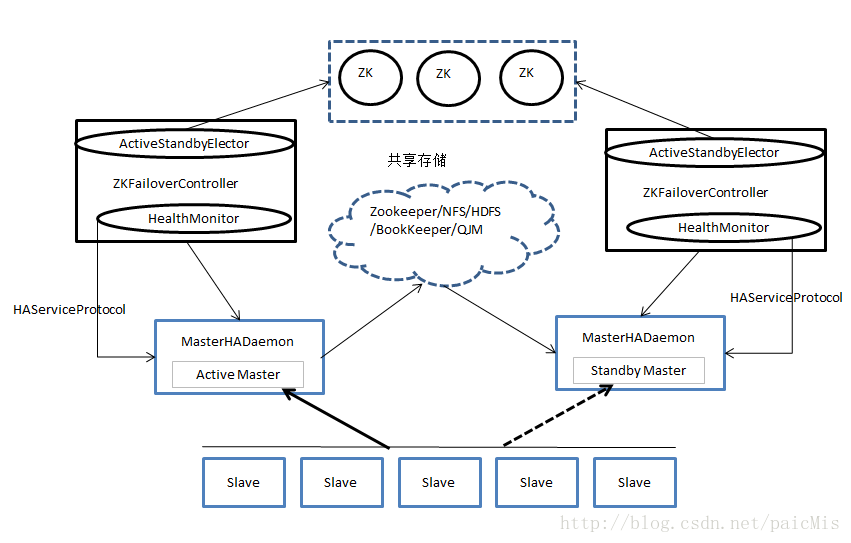
自动模式主要由以下组件构成:
- MasterHADaemon:与Master服务运行在同一个进程中,可接收外部RPC命令,以控制Master服务的启动和停止
- SharedStorage:共享存储系统,Active Master将信息写入共享存储系统,而Standby Master则读取该信息以保持与Active Master的同步
- ZKFailoverController:基于Zookeeper实现的切换控制器,主要由ActiveStandbyElector和HealthMonitor两个核心组件构成,其中ActiveStandbyElector负责与Zookeeper集群交互,通过尝试获取全局锁,以判断所管理的Master是进入Active还是进入Standby状态,HealthMonitor负责监控各个活动Master的状态,以根据他们状态进行状态切换
- Zookeeper:核心功能是通过维护一把全局锁控制整个集群有且仅有一个Active Master,当然如果SharedStorge采用了Zookeeper,则还会记录一些其他状态和运行时信息。
要解决HA问题需考虑以下几个问题
1、脑裂(brain-split)
脑裂是指在主备切换时,由于切换不彻底或其他原因,导致客户端和slave误以为出现两个Active Master,最终使得整个集群处于混乱状态,通常采用隔离(Fencing)机制解决脑裂问题,解决脑裂问题需从以下三个方面考虑:
- 共享存储隔离:确保只有一个Master往共享存储中写数据
- 客户端隔离:确保只有一个Master可以响应客户端的请求
- Slave隔离:确保只有一个Master可以向Slave下发命令
Hadoop公共库中对外提供了两种隔离实现,分别是sshfence和shellfence。其中sshfence是指通过SSH登录目标Master节点上,使用命令fuser将进程杀死;shellfence是指执行一个用户事先定义的shell命令完成隔离
2、切换对外透明
为了保证整个切换是对外透明的,Hadoop应保证所有客户端和slave能自动重定向到新的Active Master上,这通常是通过若干次尝试连接就Master不成功后,在重新尝试连接新Master完成的,整个工程有一定延迟,这个可以自行设置RPC客户端尝试机制,尝试次数和尝试超时时间等参数
最后
以上就是聪明八宝粥最近收集整理的关于Hadoop2容错机制的全部内容,更多相关Hadoop2容错机制内容请搜索靠谱客的其他文章。








发表评论 取消回复