随着互联网进入下半场,对于“人”、“货”、“场”三个核心元素的要求越来越高,随着数据量和流量的爆发式增长,传统的人工运营方式已经很难适应当下如此复杂的业务场景,如何精细、准确、高效、智能地联系三者成为各个平台系统越来越关注的点,于是基于千人千面个性化的推荐系统成为各个业务场景必不可少的一环。
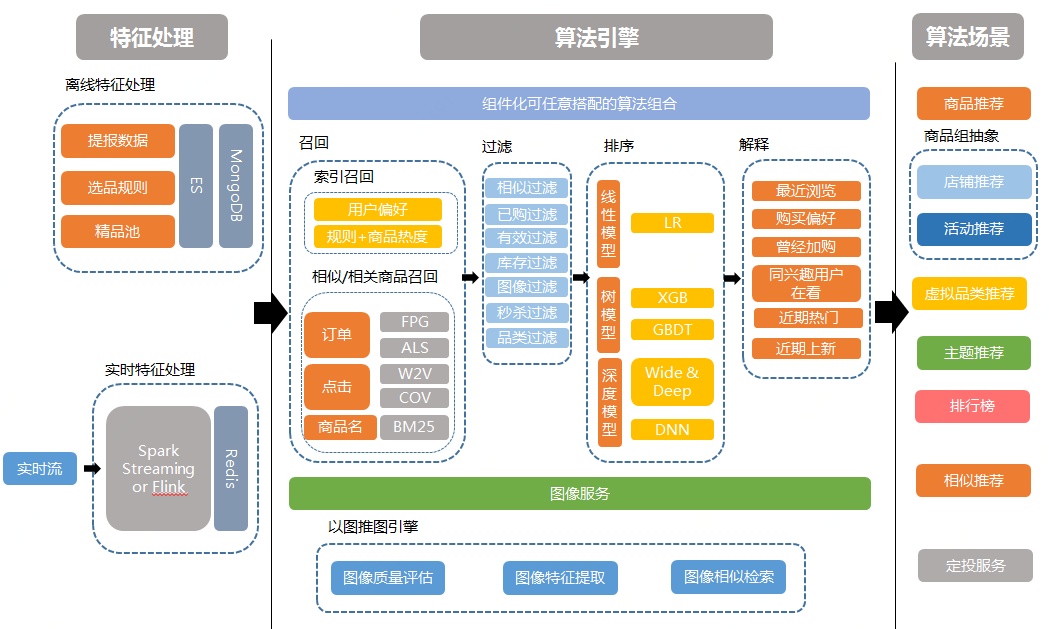
本文主要介绍在电商场景下,关于个性化推荐系统的架构方面的介绍,考虑到篇幅,其他推荐系统相关的算法大数据方面技术例如特征工程、模型训练部署等会在另外文章中介绍。先给出系统的总体技术架构图,具体模块后面详细介绍。
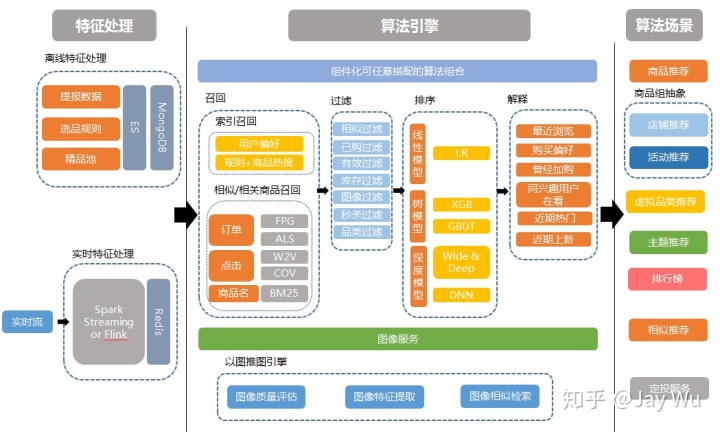
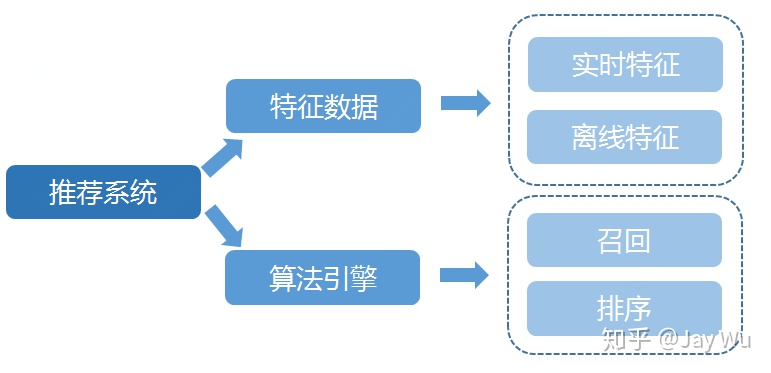
从架构图上可以看出,一个完整的推荐系统包含两大核心部分:特征数据和算法引擎。其中特征数据可以分成实时特征和离线特征,两者并行但是不同的处理技术;算法引擎又主要包含召回和排序两部分,两者是有前后依赖关系的推理流程。
1. 特征数据
特征数据根据实时性分成两种类型:离线特征和实时特征,特征数据具有数据量大的特点,基于此特点,需要选择合理的数据处理技术和存储介质。
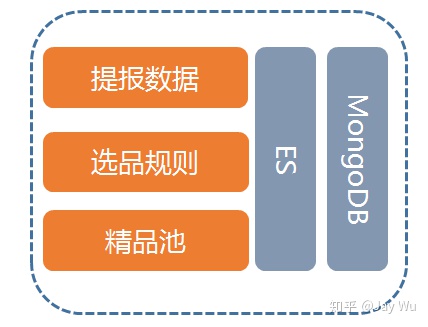
针对离线数据,主要需要结合大数据技术,通过一些分布式数据库来实现数据的部署,对于初级的推荐服务建议直接使用业内比较成熟的MongoDB或者Elasticsearch来作为数据存储介质。两者都具有比较弹性的数据存储扩展性。
针对实时数据,例如用户的实时行为,主要需要结合流式计算相关技术,例如通过Kafka的流平台,使用Spark Streaming、Flink或者Storm等来进行流式计算,考虑到实时性和数据的吞吐量,存储的方式可以直接使用REDIS这类缓存存储来实现,根据不同阶段使用的特征,进行了不同的处理,如用户偏好反馈、实时用户特征数据等。
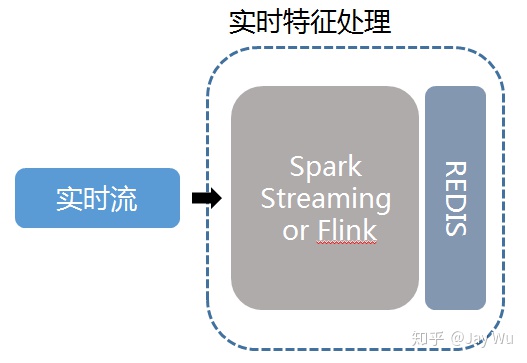
除了以上的技术选型和设计方案,在系统的发展过程中,随着数据量的井喷式发展,整个数据量的读写IO压力会越来越巨大,也逐渐成为系统的瓶颈,优化的方式是对数据需要进行压缩,本团队使用的方式是Google的Protobuf技术,总体使用下来压缩后为压缩前存储空间的一半左右,同时Protobuf的解析效率也是非常高的,优于json格式的解析效率。
2. 算法引擎
对于算法引擎,最核心的两部分是召回(Recall)和排序(Ranking)。召回是从海量的数据里快速拿到相对少量(比如一千左右)的数据,这一步最重要的是快和尽可能准。排序是从召回的数据中进行模型的精细排序,特点是复杂和精确。
2.1 召回(RECALL)
召回的算法和形式多样,如基于内容召回、相似召回、相关召回、模型召回等等。但召回需要具备高并发与快召回的特点。为了在规定的时间内完成数据的快速召回,将形式多样的召回方法或结果建立了大量的倒排索引,直接推入缓存系统,如:相关相似关系(item2item或者user2item)和规则关系召回(rule);为了适应索引灵活更新和服务灵活扩展,底层也使用了MongoDB与Elasticsearch这种可扩展的分布式弹性存储介质来辅助数据存储,建立对应的索引关系,触发索引导入缓存,如规则关系召回。
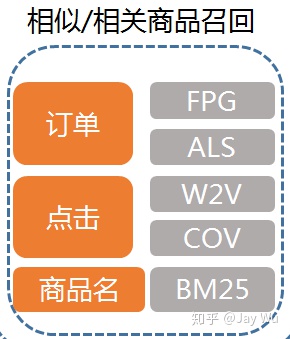
相似相关召回的数据一般是通过用户行为、订单、点击和素材文本信息等数据通过算法离线或者实时处理好生成pair对,直接存储在例如REDIS这类缓存中,吞吐量天然比较高。下图是举例了部分数据和算法:
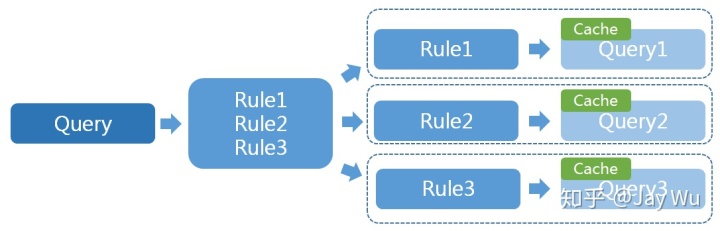
规则召回是从海量的数据中根据Query规则来进行召回。这里提高吞吐量的方式除了选择高性能的硬件设备和合适的分布式数据库外,我们团队的核心思想是使用高速的缓存来进一步实现高吞吐的召回,基于这个核心思路,设计了一套拆分Query增加缓存实现的方式来提高整个召回的性能。

一般的Query都是通过多个条件来组合实现的,电商的个性化推荐场景下,每个User的Query条件可能会有区别,造成Query的千人千面,这时候即使在Query层面加上缓存,也很难达到很理想的缓存命中率。于是该如何提高缓存命中率呢?我们的思路是把大的Query根据其中的条件拆分成各个独立的原子条件进行多路Query,在小条件的Query上增加缓存。由于Query的粒度变小,不同用户之间可能会共享一些同样的Query条件,从而达到提高缓存命中率的目标。方案如下图:
2.2 排序(RANKING)
排序这部分核心是模型的训练,模型算法训练本文不过多阐述,在系统架构上面主要提两点:不同模型的工程特性和模型的热部署。
模型的工程特性上面,我们团队在系统的发展过程中,接触使用过线性模型、树模型和其他深度模型。

针对电商复杂的推荐场景,线性模型是使用最简单但是效果比较普通,这里就不过多介绍了。
树模型,代表是GBDT和XGBoost。树模型在电商推荐的场景下已经被证明效果不错并且也在业内被广泛使用,这里介绍此类模型是因为相比其他的深度学习模型,树模型已经被其他多种编程语言兼容(例如大多数后台应用使用的JAVA语言),使得树模型的使用门槛相对较低,能更容易出效果。
深度学习模型,模型比较复杂,一般模型使用tensorflow技术,通过tensor serving部署模型API接口,在推理效果上上限比较高,但需要更复杂的特征工程和模型训练。
对于模型的热部署,此机制可以在日常的工作中减少很多发布量,让模型的更新更自由和方便。针对集成在工程中的模型,我们团队使用zookeeper的同步机制来实现模型的在线更新。至于深度学习模型,tensor serving直接已经支持了模型的热部署。
写在最后
本文主要从推荐系统的工程架构方面和大家分享了一些较基础的技术方案,当然详细的推荐系统远不止文章中这近千个文字可以表述完整的,这里也只是抛砖引玉,各位看官如果有问题、建议或者新的看法,欢迎留言一起探讨。同时,后续也计划继续推出推荐系统的特征篇和算法篇,希望大家可以在技术的世界里一起成长。
最后
以上就是怕黑小天鹅最近收集整理的关于实现实时个性化推荐_从0到1打造推荐系统-架构篇的全部内容,更多相关实现实时个性化推荐_从0到1打造推荐系统-架构篇内容请搜索靠谱客的其他文章。








发表评论 取消回复