文章目录
- 1. Tensorflow特点
- 2. Tensoflow进阶
- 2.1 图
- 2.2 会话
- 2.3 张量
- 2.4 变量
- 2.5 模型保存与加载
- 2.6 自定义命令行参数
- 3. Tensorflow IO操作
- 3.1 线程和队列
- 3.2 读取数据
- 3.3 图像文件读取
- 4. 可视化学习Tensorboard
- 4.1启动Tenosrboard
- 4.2 添加节点汇总操作
- 5. 分布式Tensorflow
- 5.1 分布式接口
1. Tensorflow特点
- 真正的可移植性
- 引入各种计算设备的支持包括CPU/GPU/TPU,以及能够很好运行在移动端,如安卓,ios等
- 多语言支持
- Tensorflow有一个合理的c++使用界面,也有一个易用的python使用界面来构建和执行graphs,可以直接写python/c++程序
- 高度的灵活性和效率
- Tensorflow采用数据流图(data flow graphs),用于数值计算的开源软件库能够灵活进行组装图,执行图,效率也在不断提升
- 支持
- Tensorflow由谷歌提供支持,框架完整度很高
2. Tensoflow进阶
2.1 图
- 图默认已经注册,一组表示 tf.operation计算单位的对象tf.tensor表示操作之间流动的数据单位的对象
- 获取调用
- tf.get_default_graph()
- op,sess或者tensor的graph属性
- tf.graph()
- 使用新创建的图
2.2 会话
- tf.Session(): 运行tensorflow操作图的类,使用默认注册的图(可以指定运行图)
- 使用上下文管理器
with tf.Session() as sess:
sess.run(...)
config = tf.ConfigProto(log_device_placement=True)
# 交互式
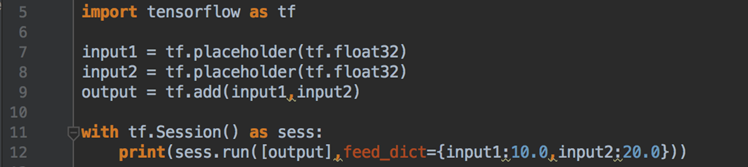
tf.InteractiveSession()- run(fetches,feed_dict=None,graph=None)
运行ops和计算tensor
嵌套列表,元祖
namedtuple,dict或ordereDict(重载的运算符也能运行) - feed_dict允许调用者覆盖图中指定张量的值,提供给placeholder使用
- 返回值异常
RuntimeError:如果它Session处于无效状态
TypeError:如果fetches或feed_dict键是不合适的类型
ValueError:如果fetches或feed_dict键无效或引用Tensor不存在
2.3 张量
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'- 张量属性
- graph:张量所属的默认图
- op:张量的操作名
- name:张量的字符串描述
- shape:张量的形状
node1 = tf.constant(3.0)
node2 = tf.constant(4.0)
sum = node1 + node2
with tf.Session() as sess:
print(sum.eval())
print(sum.graph)
print(sum.op)
print(sum.name)
print(sess.run(sum))- 张量的动态形状和静态形状
- Tensorflow中,张量具有静态形状和动态形状
- 静态形状,创建一个张量或者由操作推导出一个张量时,初始状态的形状
- tf.Tensor.get_shape:获取静态形状
- tf.Tensor.set_shape():更新Tensor对象的静态形状,通常用于在不能直接推断情况下
- 动态形状: 一种描述原始张量在执行过程中的一种状态
- tf.reshape:创建一个具有不用动态形状的新张量
tf.zeros(shape,dtype=tf.float32,name=None)
tf.ones(shape,dtype=tf.float32,name=None)
tf.constant(value,dtype=None,name='Const')
tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None)
tf.string_to_number(string_tensor,out_type=None,name=None)
tf.cast(x,dtype,name=None)
tf.shape(input,name=None)
tf.reshape(tensor,shape,name=None)
tf.concat(values,axis,name='concat')2.4 变量
- 变量也是一种op,是一种特殊的张量,能够进行存储持久化,它的值就是张量
- 变量的创建
- tf.Variable(initial_value=None,name=None) 创建一个带值initial_value的新变量
- assign(value) 为变量分配一个新值,返回新值
- eval(session=None) 计算并返回此变量的值
- name属性表示变量名字
- tf.global_variables_initializer():添加一个初始化所有变量的op
- tensorboard显示
tf.summary.FileWriter('/..',graph=default_graph) # 返回filewriter,写入时间文件制定的目录,以供给tensorboard使用
tensorboard --logdir='addr' --127.0.0.1
- 增加变量显示
- 目的:观察模型的参数,损失值等变量值的变化
- 收集变量

- 合并变量写入事件文件
- 收集变量

-
- Tensorflow运算API
# 矩阵运算
tf.matmul(x,w)
# 平方
tf.square(error)
# 均值
tf.reduce_mean(error)
# 梯度下降API
tf.train.GradientDescentOptimizer(learning_rate)
# learning_rate:学习率 method: 方法 return:梯度下降op-
- tensorflow变量作用域
tf.variable_scope(<scope_name>)
# 创建指定名字的变量作用域
# 让模型代码更加清晰,作用分明2.5 模型保存与加载
tf.train.Saver(var_list=None,max_to_keep=5)
- var_list:指定将要保存个还原的变量,它可以作为一个dict或者一个列表传递
- max_to_keep:指示要保留的最近检查点文件的最大数量
- 创建新文件时,会删除较旧的文件,如果无或0,则保留所有检查点文件,默认是5
saver.save(sess,"./model")
saver.restore(sess,"./model")
# 保存格式:checkpoint文件2.6 自定义命令行参数
- tf.app.run(),默认调用main()函数,运行程序。main(argv)必须传一个参数。
- f.app.flags,它支持应用从命令行接受参数,可以用来指定集群配置等。
- 在tf.app.flags下面有各种定义参数的类型
- DEFINE_string(flag_name, default_value, docstring)
- DEFINE_integer(flag_name, default_value, docstring)
- DEFINE_boolean(flag_name, default_value, docstring)
- DEFINE_float(flag_name, default_value, docstring)
- 第一个也就是参数的名字,路径、大小等等。第二个参数提供具体的值。第三个参数是说明文档
- tf.app.flags.FLAGS,在flags有一个FLAGS标志,它在程序中可以调用到我们前面具体定义的flag_name.
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('data_dir', '/tmp/tensorflow/mnist/input_data',
"""数据集目录""")
tf.app.flags.DEFINE_integer('max_steps', 2000,
"""训练次数""")
tf.app.flags.DEFINE_string('summary_dir', '/tmp/summary/mnist/convtrain',
"""事件文件目录""")
def main(argv):
print(FLAGS.data_dir)
print(FLAGS.max_steps)
print(FLAGS.summary_dir)
print(argv)
if __name__=="__main__":
tf.app.run()3. Tensorflow IO操作
3.1 线程和队列
- TensorFlow提供了两个类来帮助多线程的实现:tf.Coordinator和 tf.QueueRunner。
- Coordinator类可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常,
- QueueRunner类用来协调多个工作线程同时将多个张量推入同一个队列中
- 队列的概念FIFOQueue和RandomShuffleQueue
- 多个线程准备训练样本,并且把这些样本推入队列。
- 一个训练线程执行一个训练操作
同步执行队列
# 创建一个队列
Q = tf.FIFOQueue(3, dtypes=tf.float32)
# 数据进队列
init = Q.enqueue_many(([0.1, 0.2, 0.3],))
# 定义操作,op,出队列,+1,进队列,注意返回的都是op
out_q = Q.dequeue()
data = out_q + 1
en_q = Q.enqueue(data)
with tf.Session() as sess:
# 初始化队列,是数据进入
sess.run(init)
# 执行两次入队加1
for i in range(2):
sess.run(en_q)
# 循环取队列
for i in range(3):
print(sess.run(Q.dequeue()))异步执行队列
#主线程,不断的去取数据,开启其它线程来进行增加计数,入队
#主线程结束了,队列线程没有结束,就会抛出异常
#主线程没有结束,需要将队列线程关闭,防止主线程等待
Q = tf.FIFOQueue(1000,dtypes=tf.float32)
# 定义操作
var = tf.Variable(0.0)
increment_op = tf.assign_add(var,tf.constant(1.0))
en_op = Q.enqueue(increment_op)
# 创建一个队列管理器,指定线程数,执行队列的操作
qr = tf.train.QueueRunner(Q,enqueue_ops=[increment_op,en_op]*3)
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 生成一个线程协调器
coord = tf.train.Coordinator()
# 启动线程执行操作
threads_list = qr.create_threads(sess,coord=coord,start=True)
print(len(threads_list),"----------")
# 主线程去取数据
for i in range(20):
print(sess.run(Q.dequeue()))
# 请求其它线程终止
coord.request_stop()
# 关闭线程
coord.join(threads_list)3.2 读取数据
- 文件队列生成函数
- tf.train.string_input_producer(string_tensor, num_epochs=None, shuffle=True, seed=None, capacity=32, name=None)
- 产生指定文件张量
- 文件阅读器类
- class tf.TextLineReader 阅读文本文件逗号分隔值(CSV)格式
- tf.FixedLengthRecordReader 要读取每个记录是固定数量字节的二进制文件
- tf.TFRecordReader 读取TfRecords文件
- 解码
由于从文件中读取的是字符串,需要函数去解析这些字符串到张量
- tf.decode_csv(records,record_defaults,field_delim = None,name = None)将CSV转换为张量,与tf.TextLineReader搭配使用
- tf.decode_raw(bytes,out_type,little_endian = None,name = None) 将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用
- 生成文件队列
- 将文件名列表交给tf.train.string_input_producer函数。
- string_input_producer来生成一个先入先出的队列,文件阅读器会需要它们来取数据。string_input_producer提供的可配置参数来设置文件名乱序和最大的训练迭代数,QueueRunner会为每次迭代(epoch)将所有的文件名加入文件名队列中,如果shuffle=True的话,会对文件名进行乱序处理。一过程是比较均匀的,因此它可以产生均衡的文件名队列
# 读取CSV格式文件
# 1、构建文件队列
# 2、构建读取器,读取内容
# 3、解码内容
# 4、现读取一个内容,如果有需要,就批处理内容
import tensorflow as tf
import os
def readcsv_decode(filelist):
"""
读取并解析文件内容
:param filelist: 文件列表
:return: None
"""
# 把文件目录和文件名合并
flist = [os.path.join("./csvdata/",file) for file in filelist]
# 构建文件队列
file_queue = tf.train.string_input_producer(flist,shuffle=False)
# 构建阅读器,读取文件内容
reader = tf.TextLineReader()
key,value = reader.read(file_queue)
record_defaults = [["null"],["null"]] # [[0],[0],[0],[0]]
# 解码内容,按行解析,返回的是每行的列数据
example,label = tf.decode_csv(value,record_defaults=record_defaults)
# 通过tf.train.batch来批处理数据
example_batch,label_batch = tf.train.batch([example,label],batch_size=9,num_threads=1,capacity=9)
with tf.Session() as sess:
# 线程协调员
coord = tf.train.Coordinator()
# 启动工作线程
threads = tf.train.start_queue_runners(sess,coord=coord)
# 这种方法不可取
# for i in range(9):
# print(sess.run([example,label]))
# 打印批处理的数据
print(sess.run([example_batch,label_batch]))
coord.request_stop()
coord.join(threads)
return None
if __name__=="__main__":
filename_list = os.listdir("./csvdata")
readcsv_decode(filename_list)3.3 图像文件读取
def readpic_decode(file_list):
"""
批量读取图片并转换成张量格式
:param file_list: 文件名目录列表
:return: None
"""
# 构造文件队列
file_queue = tf.train.string_input_producer(file_list)
# 图片阅读器和读取数据
reader = tf.WholeFileReader()
key,value = reader.read(file_queue)
# 解码成张量形式
image_first = tf.image.decode_jpeg(value)
print(image_first)
# 缩小图片到指定长宽,不用指定通道数
image = tf.image.resize_images(image_first,[256,256])
# 设置图片的静态形状
image.set_shape([256,256,3])
print(image)
# 批处理图片数据,tensors是需要具体的形状大小
image_batch = tf.train.batch([image],batch_size=100,num_threads=1,capacity=100)
tf.summary.image("pic",image_batch)
with tf.Session() as sess:
merged = tf.summary.merge_all()
filewriter = tf.summary.FileWriter("/tmp/summary/dog/",graph=sess.graph)
# 线程协调器
coord = tf.train.Coordinator()
# 开启线程
threads = tf.train.start_queue_runners(sess=sess,coord=coord)
print(sess.run(image_batch))
summary = sess.run(merged)
filewriter.add_summary(summary)
# 等待线程回收
coord.request_stop()
coord.join(threads)
return None
if __name__=="__main__":
# 获取文件列表
filename = os.listdir("./dog/")
# 组合文件目录和文件名
file_list = [os.path.join("./dog/",file) for file in filename]
# 调用读取函数
readpic_decode(file_list)4. 可视化学习Tensorboard
- 可以用 TensorBoard 来展现你的 TensorFlow 图像,绘制图像生成的定量指标图以及附加数据
# 序列化events文件
tf.summary.FileWriter('/tmp/summary/test/', graph=default_graph)4.1启动Tenosrboard
在终端启用
tensorboard --logdir=path/to/log-directory- 其中logdir指向其FileWriter序列化其数据的目录。如果此logdir目录包含从单独运行中包含序列化数据的子目录,则TensorBoard将可视化所有这些运行中的数据。一旦TensorBoard运行,浏览您的网页浏览器localhost:6006来查看TensorBoard
import tensorflow as tf
graph = tf.Graph()
with graph.as_default():
with tf.name_scope("name1") as scope:
a = tf.Variable([1.0,2.0],name="a")
with tf.name_scope("name2") as scope:
b = tf.Variable(tf.zeros([20]),name="b")
c = tf.Variable(tf.ones([20]),name="c")
with tf.name_scope("cal") as scope:
d = tf.concat([b,c],0)
e = tf.add(a,5)
with tf.Session(graph=graph) as sess:
tf.global_variables_initializer().run()
# merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter('/tmp/summary/test/', graph=sess.graph)
sess.run([d,e])4.2 添加节点汇总操作
收集操作
- tf.summary.scalar() 收集对于损失函数和准确率等单值变量
- tf.summary.histogram() 收集高维度的变量参数
- tf.summary.image() 收集输入的图片张量能显示图片
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_label, logits=y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_label, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("loss",cross_entropy)
tf.summary.scalar("accuracy", accuracy)
tf.summary.histogram("W",W)
# 合并
merged = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter(FLAGS.summary_dir, graph=sess.graph)
# 运行
summary = sess.run(merged)
#写入
summary_writer.add_summary(summary,i)5. 分布式Tensorflow
- 创建集群的方法是为每一个任务启动一个服务,这些任务可以分布在不同的机器上,也可以同一台机器上启动多个任务,使用不同的GPU等来运行。每个任务都会创建完成一下工作
5.1 分布式接口
- 创建一个tf.train.ClusterSpec,用于对集群中的所有任务进行描述,该描述内容对所有任务应该是相同的
- 创建一个tf.train.Server,用于创建一个任务,并运行相应作业上的计算任务
cluster = tf.train.ClusterSpec()
cluster = tf.train.ClusterSpec({"worker": ["worker0.example.com:2222", /job:worker/task:0
"worker1.example.com:2222", /job:worker/task:1
"worker2.example.com:2222"], /job:worker/task:2
"ps": ["ps0.example.com:2222", /job:ps/task:0
"ps1.example.com:2222"]}) /job:ps/task:1
# 第一个任务
cluster = tf.train.ClusterSpec({"worker": ["localhost:2222","localhost:2223"]})
server = tf.train.Server(cluster, job_name="worker", task_index=0)
# 第二个任务
cluster = tf.train.ClusterSpec({"worker": ["localhost:2222","localhost:2223"]})
server = tf.train.Server(cluster, job_name="worker", task_index=1)
with tf.device("/job:ps/task:0"):
weights = tf.Variable(...)最后
以上就是优美黑米最近收集整理的关于Python tensorflow基础教程总结的全部内容,更多相关Python内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复