采用方法二:
【SQLite】SqlLite在VisualStudio2017中C#的使用_Kevin's life的博客-CSDN博客_vs2017sqlite插件 https://blog.csdn.net/ght886/article/details/83791418补充:
https://blog.csdn.net/ght886/article/details/83791418补充:
vs连接数据库:
可以在这里单独连接进行独立操作:
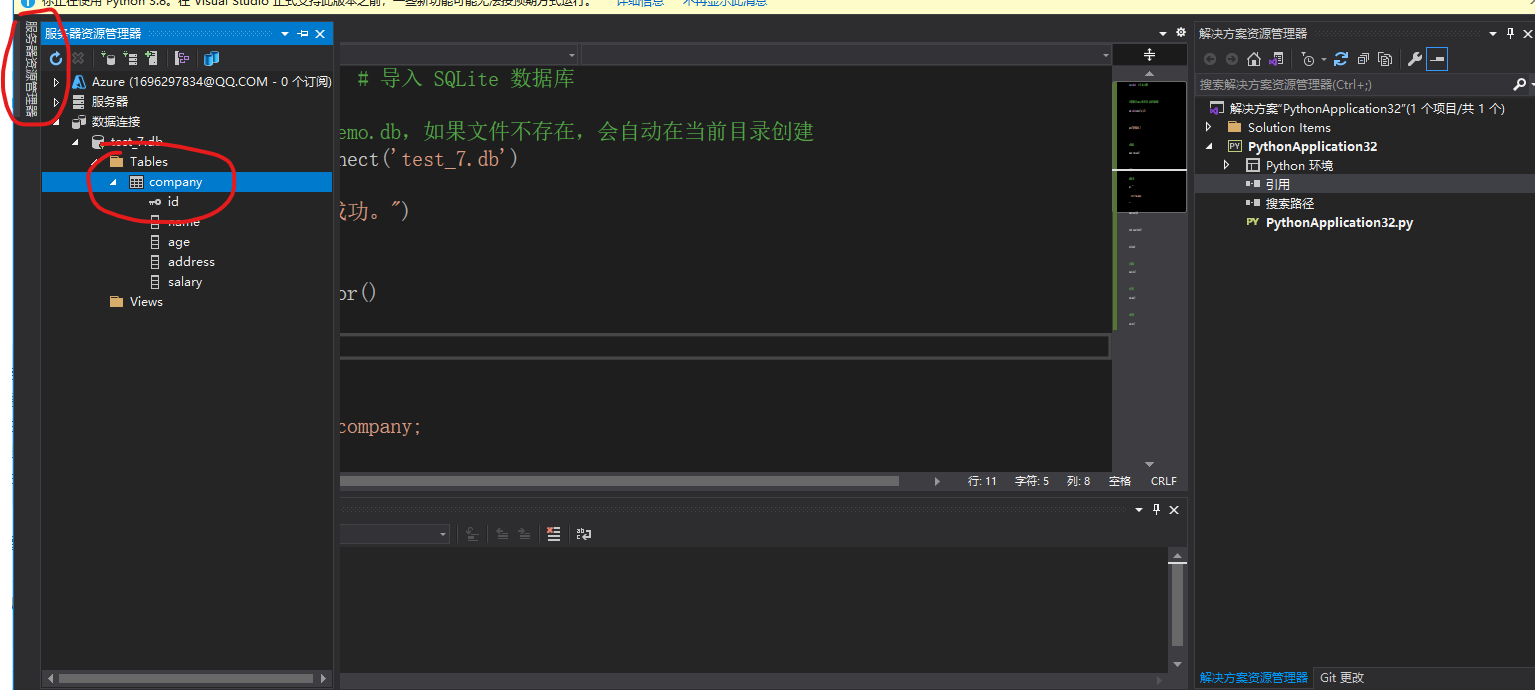
1、连接新建的SQLite数据库
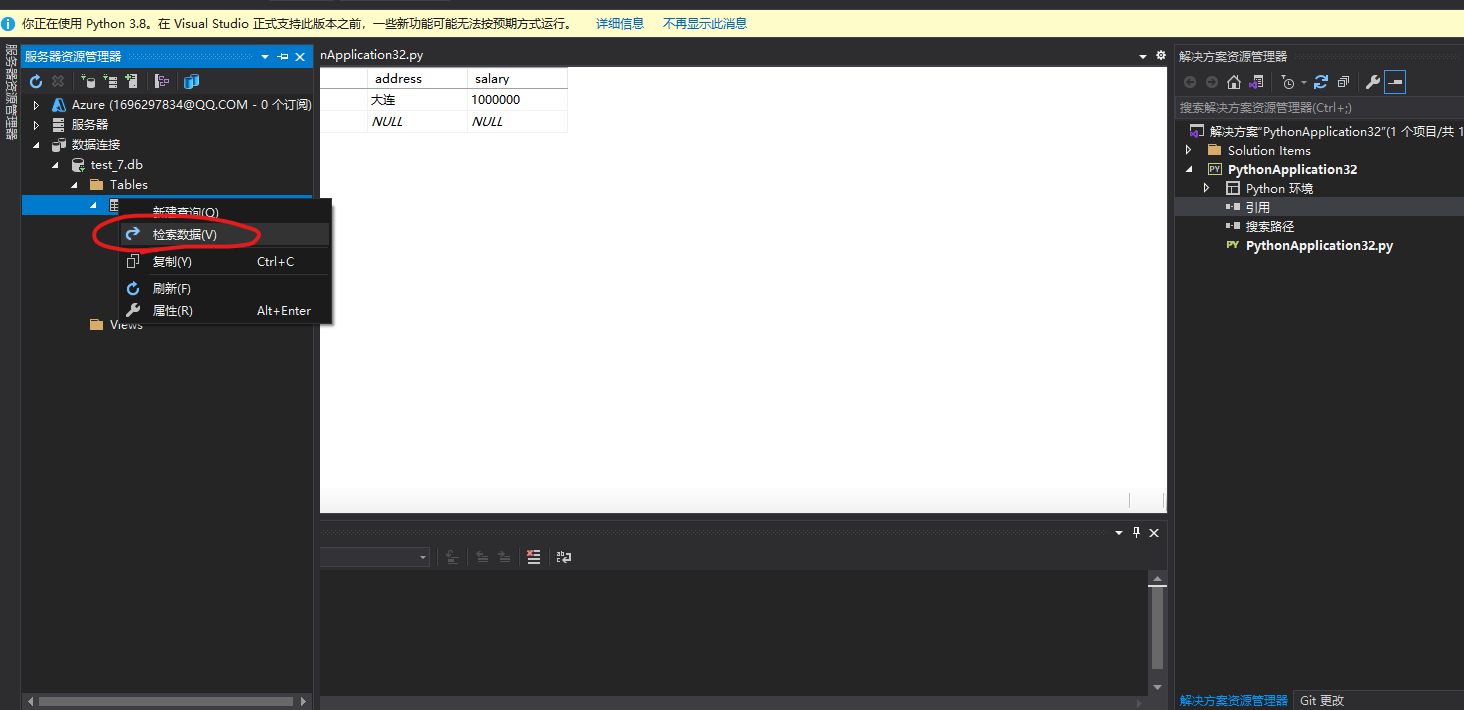
2、检索数据库
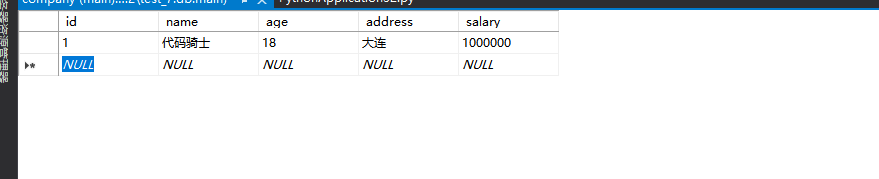
3、可视化查表
为什么使用SQLite:
SQLite 不是一个客户端/服务器结构的数据库引擎,而是一种嵌入式数据库,它的数据库就是一个文件。SQLite 将整个数据库,包括定义、表、索引以及数据本身,作为一个单独的、可跨平台使用的文件存储在主机中。由于 SQLite 本身使用 C 语言写的,而且体积很小,所以经常被集成到各种应用程序中。Python 就内置了 SQLite3,所以在 Python 中使用 SQLite 不需要安装任何模块,直接使用。
sqlite和mysql的使用方法具体参考:
python3基础:操作mysql数据库_小小小小人ksh的博客-CSDN博客_python连接mysqlhttps://blog.csdn.net/kongsuhongbaby/article/details/84948205Python 操作数据库_lucky-billy的博客-CSDN博客_python数据库https://blog.csdn.net/qq_34139994/article/details/108328492
下面进行实例演示:
第一步:创建或打开数据库文件:
import sqlite3
conn = sqlite3.connect("test_7.db")#.db表示数据库文件,这句代码的意思是,如果当前目录下没有test.db文件就创建,如果有就打开
print("open or create database successfully.");
第二步:打开数据库并建表
import sqlite3 # 导入 SQLite 数据库
# 连接数据库文件 demo.db,如果文件不存在,会自动在当前目录创建
conn = sqlite3.connect('test_7.db')
print("创建库成功。")
# 获取游标
cursor = conn.cursor()
#创建表
#结构化书写
sql = '''
create table company
(
id int primary key not null,
name char(50) not null,
age int not null,
address char(50),
salary real
);
'''
print("创建表成功。")
cursor.execute(sql)
# 关闭游标
cursor.close()
# 提交事务
conn.commit()
# 断开连接
conn.close() 
第三步:插入数据
import sqlite3 # 导入 SQLite 数据库
# 连接数据库文件 demo.db,如果文件不存在,会自动在当前目录创建
conn = sqlite3.connect('test_7.db')
print("打开数据库成功。")
# 获取游标
cursor = conn.cursor()
#创建表
#结构化书写
sql = '''
insert into company values(2,'CodeKinght',18,'大连',1000000);
'''
cursor.execute(sql)
print("插入数据成功。")
# 关闭游标
cursor.close()
# 提交事务
conn.commit()
# 断开连接
conn.close()
第四步:查询数据:
import sqlite3 # 导入 SQLite 数据库
# 连接数据库文件 demo.db,如果文件不存在,会自动在当前目录创建
conn = sqlite3.connect('test_7.db')
print("打开数据库成功。")
# 获取游标
cursor = conn.cursor()
#创建表
#结构化书写
sql = '''
select * from company;
'''
cursor.execute(sql)
result = cursor.fetchall();
print(result)
# 关闭游标
cursor.close()
# 提交事务
conn.commit()
# 断开连接
conn.close() 
第五步:删除数据
import sqlite3 # 导入 SQLite 数据库
# 连接数据库文件 demo.db,如果文件不存在,会自动在当前目录创建
conn = sqlite3.connect('test_7.db')
print("打开数据库成功。")
# 获取游标
cursor = conn.cursor()
#创建表
#结构化书写
sql = '''
delete from company where id=2;
'''
cursor.execute(sql)
print("删除数据成功。")
# 关闭游标
cursor.close()
# 提交事务
conn.commit()
# 断开连接
conn.close() 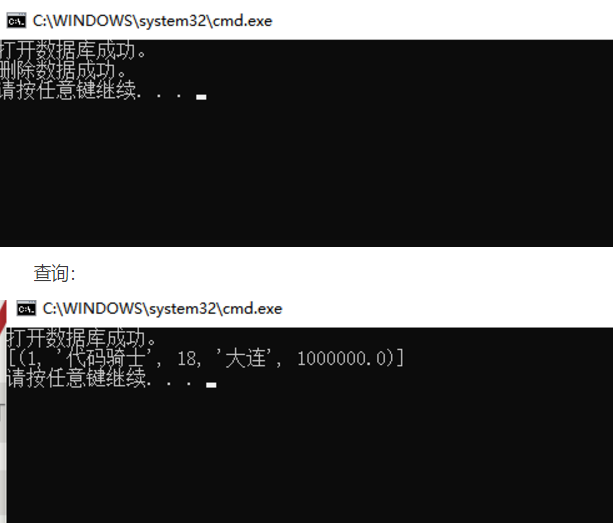
查询多行指定数据:
import sqlite3 # 导入 SQLite 数据库
# 连接数据库文件 demo.db,如果文件不存在,会自动在当前目录创建
conn = sqlite3.connect('test_7.db')
# 获取游标
cursor = conn.cursor()
#创建表
#结构化书写
sql = '''
select id,name,address,salary from company;
'''
cursor.execute(sql)
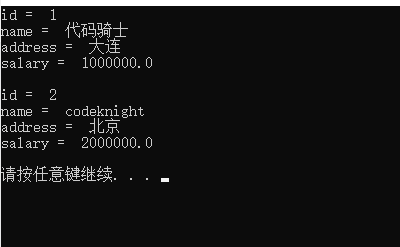
for row in cursor:
print("id = ",row[0])
print("name = ",row[1])
print("address = ",row[2])
print("salary = ",row[3],"n")
# 关闭游标
cursor.close()
# 提交事务
conn.commit()
# 断开连接
conn.close() 输出:
上次我们爬取了豆瓣电影Top250条电影信息,并将其内容保存在了Excel表中,这次我们对保存数据的函数稍作修改将保存数据的位置改为数据库,具体代码如下。
上期回顾:
(10条消息) 保姆级爬虫零基础一条龙式教程(超详细)_代码骑士的博客-CSDN博客https://blog.csdn.net/qq_51701007/article/details/124301264?spm=1001.2014.3001.5502
将爬取到的信息存储进数据库:
修改部分:
#数据库初始化
def init_db(dbpath):
#创建数据表
sql = '''
create table movieTop250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric,
rated numeric,
instroduction text,
info text
)
'''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()#获取游标
cursor.execute(sql)
conn.commit()
conn.close()
#保存到数据库
def saveDataToDB(datalist,dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
if index == 4 or index == 5:
continue
data[index] = '"'+data[index]+'"'
sql='''
insert
into
movieTop250(info_link,pic_link,cname,ename,score,rated,instroduction,info)
values(%s)'''%",".join(data)
#print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()完整代码:
import urllib.request as ur
import urllib.error as ue
import urllib.parse as up
from bs4 import BeautifulSoup
import re
import sqlite3
#创建正则表达式
#影片链接
findLink=re.compile(r'<a href="(.*?)">')#(.*?):.*:任意字符出现多次 ?:前面的元组内容出现仅出现一次
#影片图片
findImagSrc=re.compile(r'<img.*src="(.*?)"',re.S);#re.S:将换行符忽视掉
#片名
findTitle = re.compile(r'<span class="title">(.*)</span>')
#评分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
#评价人数
findJudge = re.compile(r'<span>(d*)人评价</span>')
#找到概况
findInq = re.compile(r'<span class="inq">(.*)</span>')
#相关内容
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
def main():
baseurl = "https://movie.douban.com/top250?start="
datalist = getData(baseurl)
dbpath = "moveTop.db"
saveDataToDB(datalist,dbpath)
#得到一个指定的URL内容
def askURL(url):
#模拟请求头
header = {"Remote Address":"140.143.177.206:443","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}
#保存网页信息的字符串
html=""
#请求网页信息
req = ur.Request(url,headers=header)
try:
res = ur.urlopen(req)
html=res.read().decode("utf-8")
#print(html)
except ue.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#爬取网页
def getData(baseurl):
dataList = []#用来存储网页信息
for i in range(0,10):#调用获取页面信息函数10次250条
url = baseurl+str(i*25)#左闭右开
html = askURL(url)#保存获取到的网页源码
#逐一解析
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):#查找比较好的字符串放入列表
#print(item) 测试:查看电影item全部信息
data = [] #保存一部电影的所有信息
item = str(item)
#影片详情链接
Link = re.findall(findLink,item)[0]#re库用来通过正则表达式查找指定字符串,0表示只要第一次找到的
data.append(Link)
ImagSrc = re.findall(findImagSrc,item)[0]
data.append(ImagSrc)
Title = re.findall(findTitle,item)#区分中英文
if len(Title)==2:
ctitle=Title[0]
data.append(ctitle)
otitle = Title[1].replace("/","")#去掉无关符号
data.append(otitle)#添加外国名
else:
data.append(Title[0])
data.append(' ')#表中留空
Rating = re.findall(findRating,item)[0]
data.append(Rating)
Judge = re.findall(findJudge,item)[0]
data.append(Judge)
Inq = re.findall(findInq,item)
if len(Inq)!=0:
Inq=Inq[0].replace("。","")#去掉句号
data.append(Inq)
else:
data.append(" ")#表留空
Bd = re.findall(findBd,item)[0]
Bd = re.sub('<br(s+)?/>(s+)?'," ",Bd)#去掉<br/>
Bd = re.sub('/'," ",Bd)#去掉/
data.append(Bd.strip())#去掉前后空格
dataList.append(data)#把处理好的一部电影信息放入dataList
return dataList
#数据库初始化
def init_db(dbpath):
#创建数据表
sql = '''
create table movieTop250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric,
rated numeric,
instroduction text,
info text
)
'''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()#获取游标
cursor.execute(sql)
conn.commit()
conn.close()
#保存到数据库
def saveDataToDB(datalist,dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
if index == 4 or index == 5:
continue
data[index] = '"'+data[index]+'"'
sql='''
insert
into
movieTop250(info_link,pic_link,cname,ename,score,rated,instroduction,info)
values(%s)'''%",".join(data)
#print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
if __name__ == "__main__":
main()
print("爬取成功!")
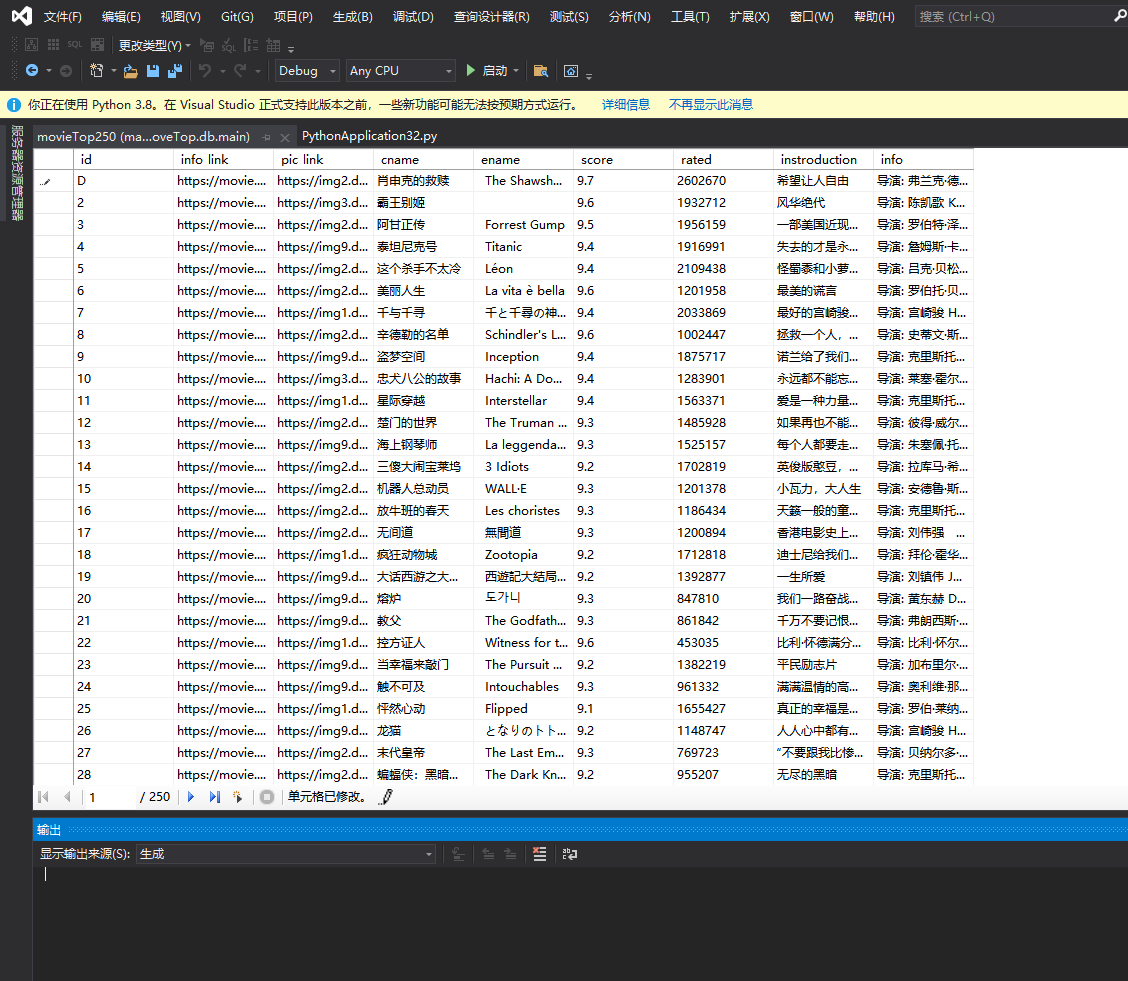
输出结果:
查看数据库:
最后
以上就是美满白猫最近收集整理的关于爬虫保姆级教程2:在visual studio中使用python项目连接SQLite数据库--爬虫数据保存之数据库vs连接数据库:下面进行实例演示: 将爬取到的信息存储进数据库:的全部内容,更多相关爬虫保姆级教程2:在visual内容请搜索靠谱客的其他文章。








发表评论 取消回复