分类寻址(网络号+主机号)
在最初定义Internet地址结构时,每个单播IP地址都有一个网络部分,用于识别接口使用的IP地址在哪个网络中可被发现;以及一个主机地址,用于识别由网络部分给出的网络中的特定主机。因此,地址中的一些连续位称为网络号,其余连续位称为主机号。基于上述分类方法,IPv4地址按照网络号和主机号的长度被分为五大类。A、B、C类用于为Internet(单播地址)中的设备接口分配地址,以及其他特殊情况下使用。类由地址中的头几位来定义:0为A类,10为B类,110为C类,1110为D类,1111为E类。D类地址供组播使用,E类地址保留。分类如下图所示:
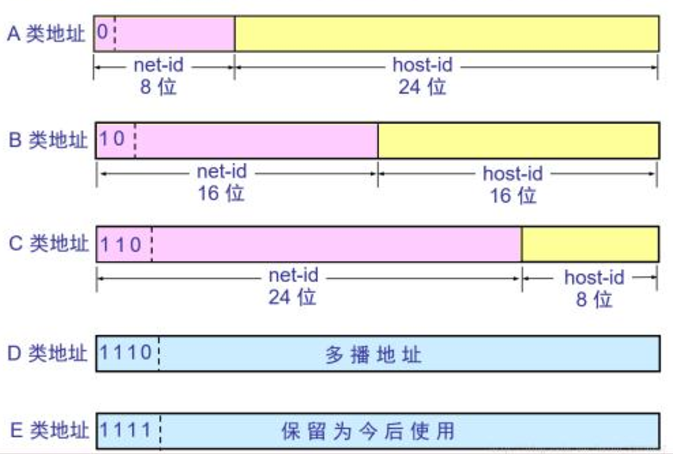
由此可得出按此分类方式得到的IPv4地址空间划分:
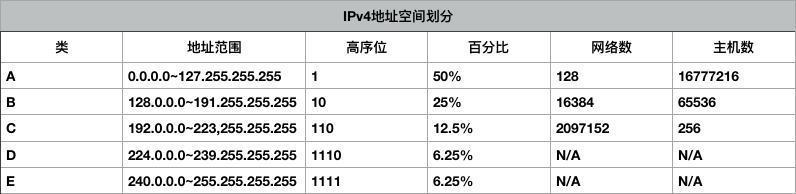
这种IP地址结构分类的特点与缺陷是显而易见的,例如A类地址的网络数少但主机数多,C类地址的网络数多而主机数少,这往往会造成一个网络号内的主机号无法完全分配,造成IP地址资源的利用率低下的问题。从而使IPv4的地址资源很快就出现了枯竭的趋势,寻找进一步细分IP地址的方法也就成为了必然。
子网寻址(细分主机号)
最初分类寻址的方法很难为接入Internet的新网段分配一个新的网络号,随着20世纪80年代初局域网(Local Area Network,LAN)的发展这一问题更为突出。为了解决这一问题,人们自然想到一种方式,在一个站点接入Internet后为其分配网络号,然后由站点管理员进一步划分本地的子网数。也即在初始的网络号+主机号的结构的基础上,将主机号划分为子网号+主机号,这样就可以在不改变核心路由基础的前提下细分网络。这种方法被称为子网寻址。子网寻址改变了最初一个IP地址的网络部分和主机部分的限制,但这样做只是针对一个站点自身而言,Internet的其余部分仍然只能看到传统的A~E的网络。从本质上来说,子网寻址为IP地址结构增加了一个额外部分,但它没有为地址增加长度。因此,一个站点管理员能在子网数和每个子网中预期的主机数之间灵活划分,不需要与其他站点协调。
子网寻址提供这种灵活性的代价是增加成本。由于当前的子网字段和主机字段是由站点指定而不是由网络号分类决定,一个站点中所有路由器和主机需要一种新的方式来确定地址中的子网部分和其中的主机部分。在出现子网之前,这个信息可直接从一个网络号中获得,只需知道是A类、B类或C类地址。
子网掩码
子网掩码(subnet mask)是由一台主机或路由器使用的分配位,以确定如何从一台主机对应IP地址中获得网络和子网信息。IP子网掩码与对应的IP地址长度相同(IPv4为32位,IPv6为128位)。其格式如下:
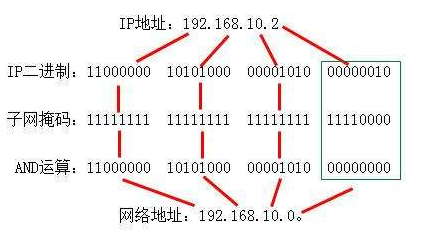
掩码由路由器和主机使用,以确定一个IP地址的网络/子网部分的结束和主机部分的开始。子网掩码中的一位设为1表示一个IP地址的对应位与一个地址的网络/子网部分的对应位相结合,并将结果作为转发数据报的基础。相反,子网掩码中的一位设为0表示一个IP地址的对应位作为主机号的一部分。如图所示:

可变长度子网掩码
子网掩码的出现让网络划分的细粒度更高,提高了IP地址资源的利用率。将一个分配给站点的网络号进一步细分为多个可分配大小相同的子网,并根据网络管理员的合理要求使每个子网能支持相同数量的主机。这种方式在复杂的网络环境中,其IP地址资源还是会有不小的浪费。因此我们自然想到了放宽一个网络的子网掩码的限制,让其长度可变,即在同一站点的不同部分,将不同长度的子网掩码应用于相同网络号。虽然这样增加了地址配置管理的复杂性,但也提高了子网结构的灵活性,因为不同子网可以容纳不同数量的主机。这就是可变长度子网掩码(Variable Length Subnet Mask,VLSM),用于分割一个网络号,使每个子网支持不同数量的主机。VLSM可对子网进行层次化编址,使得多级子网成为可能,这种高级IP寻址技术允许网络管理员对已子网进行划分,以便最有效地利用现有的地址空间。无类别域间路由和路由聚合
20世纪90年代初,在采用子网寻址缓解IPv4地址资源面临枯竭的危机后,Internet开始面临更严重的规模问题。主要体现在以下三个方面:·到1994年,一半以上的B类地址已被分配。预计B类地址大约在1995年将被用尽
·32位的IPv4地址被认为不足以应付Internet在21世纪初的预期规模
·全球性路由表的条目数(每个网络号对应一条)随着子网的出现增长得更快,路由性能将受到影响
IPv6被设想于解决第2个问题,而对于更为迫切的另外两个问题,无类别域间路由和路由聚合的概念应运而生。
无类别域间路由
为了帮助换件IPv4地址的压力,分类寻址方案通常使用一个类似VLSM的方案,扩展Internet路由系统以支持无类别域间路由(Classless InterDomain Routing,CIDR)。CIDR对原来用于分配A类、B类和C类地址的有类别路由选择进程进行了重新构建。CIDR用若干位长的前缀取代了原来IP地址结构中对网络部分的限制,这提供了一种方便的分配连续地址范围的方式。前缀
使用CIDR,未经过预定义的任何地址范围可作为一个类的一部分,但需要一个类似于子网掩码的掩码,有时也称为CIDR掩码。CIDR掩码不再局限于一个站点,而对于全球性路由系统都是可见的。因此,除了网络号之外,核心Internet路由器必须能解释和处理这种掩码。这个数字组合称为网络前缀,它用于IPv4和IPv6地址管理。消除一个IP地址中网络号和主机号的预定义分隔,将使更细粒度的IP地址分配范围称为可能。与分类寻址类似,地址空间分割成块最容易通过数值连续的地址来实现,以便用于某种类型或某些特殊用途。一个n位的前缀是一个IP地址的前n个位的预定义值。对于IPv4,n(前缀长度)的值通常在范围0~32,对于IPv6则是0~128。它通常被追加到基本IP地址,并且后面跟着一个/字符。如图所示:

CIDR建立于“超级组网”的基础上,超级组网可看作是子网划分的逆过程。子网划分时,从IP地址的主机部分借位,将其合并至网络部分;而在超级组网中,则是将网络部分的某些位合并进主机部分。
路由聚合
通过取消分类结构的IP地址,能分配各种尺寸的IP地址块。但这样做只是进一步提高了IP地址的划分细粒度,而并没有减少路由表的条目数。路由聚合通过将相邻的多个IP前缀合并成一个短前缀(称为一个聚合或汇聚),可以覆盖更多地址空间。例如,三个IP地址:190.154.27.0/26,190.154.27.64/26,190.154.27.192/26,其二进制表示如下:

路由汇聚提高了路由选择的效率,降低了对路由器内存的要求(路由表条目数减少),且当重新计算路由表或检索路由表条目,即对路由表进行分析以找出前往目标IP地址的路径时,降低了所需的CPU周期(也就是时间)。
IP地址从最初的分类寻址方式逐渐改进,增加了子网掩码,再到对有类别的路由进行重新构建,放弃了早期的有类别路由,改用无类别域间路由,都是为了更有效地利用IP地址资源。这些技术虽然大部分是为了应对IPv4地址资源不足而提出的,但对于IPv6也同样适用。这一系列技术使得IPv4的生存时间延长,但其32位的地址空间只能分配约43亿个IP地址,随着物联网等概念的兴起,接入Internet的设备将不仅仅只局限于传统意义上的计算机,且数量将大幅增加。因此IPv6的提出才是从根本上解决IP地址资源短缺的方案。
本文摘自《TCP/IP详解 卷1:协议(中文版)第2版》、百度百科,有改动
最后
以上就是粗犷店员最近收集整理的关于IP地址结构分类寻址(网络号+主机号)子网寻址(细分主机号)无类别域间路由和路由聚合的全部内容,更多相关IP地址结构分类寻址(网络号+主机号)子网寻址(细分主机号)无类别域间路由和路由聚合内容请搜索靠谱客的其他文章。








发表评论 取消回复