Java-SPI
1 基本概念
1.1 SPI是什么?
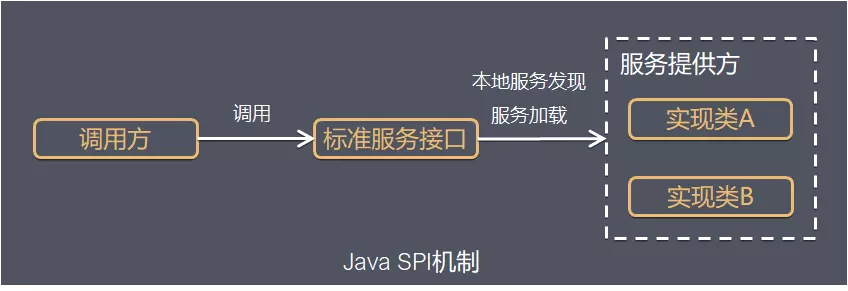
SPI,即Service Provider Interface,是JDK内置的一种服务发现机制,是一套用来被第三方实现或者扩展的API,它可以用来启用框架扩展或替换组件。
JAVA SPI = 基于接口的编程+策略模式+配置文件 组合实现的动态加载机制
1.2 SPI本质
SPI思想其实和Callback差不多,Callback的思想是调用API时添加一段代码,调用方法执行完后在合适的时机调用我们添加的代码,从而实现某种程度上的“定制”。
比如Collections.sort(List<T> list,Comparator<? super T> c),第二个参数就是我们传入的自定义比较器。当使用该方法对指定list排序时就能按我们规定的排序规则排序。
1.3 SPI的约定规则
Java SPI的具体约定如下:
- 当服务的提供者,提供了服务接口的一种实现之后,必须要同时在jar包的
META-INF/services/(因为java.util.ServiceLoader的属性private static final String PREFIX = "META-INF/services/")目录里创建一个以该服务接口来命名的文件,而该文件里就是实现该服务接口的具体实现类。 - 服务实现类需要在
META-INF/services/xxxService里指定的位置 - 服务具体实现类必须拥有一个无参构造方法,不能是
private。 - 系统使用ServiceLoader类自动动态加载
META-INF/services/中的实现类。
有了SPI约定就能直接找到服务接口的具体实现类,而不再需要在代码里显示制定了。
2 实例
2.1 自写
- 服务接口类
package demos.spi.test2; /** * @Author: chengc * @Date: 2019-09-19 20:33 */ public interface HelloService { void sayHello(); } - 实现类1
package demos.spi.test2; /** * @Author: chengc * @Date: 2019-09-19 20:38 */ public class EnglishHelloServiceImpl implements HelloService{ @Override public void sayHello() { System.out.println("hello"); } } - 实现类2
package demos.spi.test2; /** * @Author: chengc * @Date: 2019-09-19 20:38 */ public class FrenchHelloServiceImpl implements HelloService{ @Override public void sayHello() { System.out.println("bonjour"); } } resources/META-INF/services/demos.spi.test2.HelloService文件# hello service impls demos.spi.test2.EnglishHelloServiceImpl demos.spi.test2.FrenchHelloServiceImpl- 测试类
package demos.spi.test2; import java.util.Iterator; import java.util.ServiceLoader; /** * @Author: chengc * @Date: 2019-09-19 20:40 */ public class SPITest { private static ServiceLoader<HelloService> services = ServiceLoader.load(HelloService.class); public static void main(String[] args) { Iterator<HelloService> iterator = services.iterator(); while (iterator.hasNext()){ iterator.next().sayHello(); } } } - 输出结果
可以看到,我们成功调用了HelloService的所有实现类的sayHello方法。hello bonjour
2.2 Phoenix中的SPI
2.2.1 概述
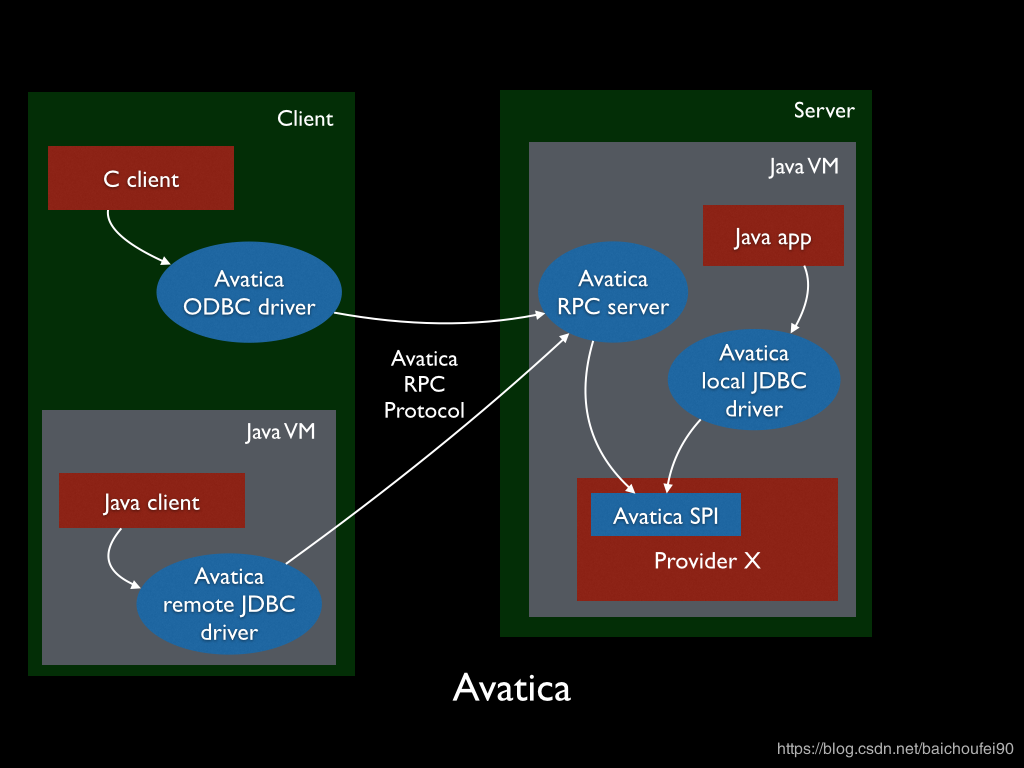
在Phoenix中,我们不需要加入代码Class.forName("org.apache.phoenix.queryserver.client.Driver")就能自动完成类org.apache.phoenix.queryserver.client.Driver的加载,直接就能开始DriverManager.getConnection使用该Driver,这就是因为使用了SPI。
2.2.2 原理
下面分析其运行流程,不过鉴于大家还不知道SPI原理,请先阅读第三章SPI的实现原理后回到这里。
- 在Phoenix中,phoniex-query-client里的
org.apache.phoenix.queryserver.client.Driver继承自org.apache.calcite.avatica.remote.Driver(祖先实现了java.sql.Driver接口)。遵循SPI规范,Phoenix开发者在phoniex-query-client module的resources/META-INF/services下就有一个java.sql.Driver文件,内容如下:
也就是说声明了Driver接口的Phoenix-Client实现类。org.apache.phoenix.queryserver.client.Driver - DriverManager.getConnection
我们在运行JDBC程序时都会有这么一个做法,在这里面会有个clinit的方法调用loadInitialDrivers关键代码如下:// 这一步就是创建一个泛型为指定接口类`java.sql.Driver`的ServiceLoader实例 // 并指定ClassLoader为当前线程上下文ClassLoader,即AppClassLoader ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class); // 获取该ServiceLoader实例的provider iterator Iterator<Driver> driversIterator = loadedDrivers.iterator(); try{ // 每次遍历的时候先用`iterator.hasNext`根据 // 去classPath下的META-INF/services/java.sql.Driver // 读取一个用户定义的服务接口文件里的实现类全限定名 // 这里就是org.apache.phoenix.queryserver.client.Driver while(driversIterator.hasNext()) { // 使用LazyIterator,按约定的服务接口路径读取实现类类名,完成具体Driver加载 //(注意这里就是懒加载)、初始化并放入providers缓存 driversIterator.next(); } } catch(Throwable t) { // Do nothing } - 加载
org.apache.phoenix.queryserver.client.Driver时,由于继承自org.apache.calcite.avatica.remote.Driver,所以还要先加载其父类。然后父类org.apache.calcite.avatica.remote.Driver的clinit方法会调用DriverManager.registerDriver注册到DriverManager。最后本类org.apache.phoenix.queryserver.client.Driver也会调用DriverManager.registerDriver注册到DriverManager。 - 后面就可以开心的使用该Driver进行各种操作了。
2.3 Flink中的SPI
2.3.1 定义
Flink中大量使用Java SPI机制,比如FlinkSql Connector就是用了SPI来查找Connector对应的 Factory。
比如我们开发一个Kudu Connector,则需要先在flink-connectors/flink-connector-kudu/src/main/resources/META-INF/services/org.apache.flink.table.factories.Factory文件中定义如下:
org.apache.flink.connector.kudu.table.KuduDynamicTableFactory
这用来高速JavaSPI机制,KuduDynamicTableFactory是Factory类的一个实现类,在加载Factory类时会自动查找加载KuduDynamicTableFactory。
当然,还需要定义用来创建DynamicTableSink实现类KuduDynamicTableSink的KuduDynamicTableFactory:
public class KuduDynamicTableFactory implements DynamicTableSinkFactory {
public static final String IDENTIFIER = "kudu";
...
}
这里定义了IDENTIFIER为kudu。
2.3.2 调用
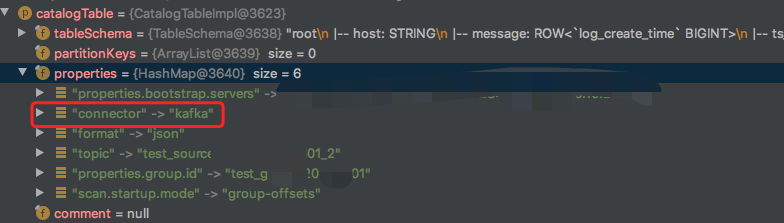
比如在Blink下调用时,会调用FactoryUtil#createTableSink方法,这里就传入了CatalogTable,内部就包含了一个名为properties的HashMap:
匹配Factory的时候,会先调用如下方法找到所有实现自Factory接口的类:
private static List<Factory> discoverFactories(ClassLoader classLoader) {
try {
final List<Factory> result = new LinkedList<>();
ServiceLoader
// 泛型为`Factory`的ServiceLoader实例,
// 清空provider缓存,后序调用iterator方法时都会重新开始懒查找和初始化provider,就像新创建loader时一样。
.load(Factory.class, classLoader)
// 构建懒加载Interator
.iterator()
// 将所有实现了Factory的类实例全部放入result list中
.forEachRemaining(result::add);
return result;
} catch (ServiceConfigurationError e) {
LOG.error("Could not load service provider for factories.", e);
throw new TableException("Could not load service provider for factories.", e);
}
}
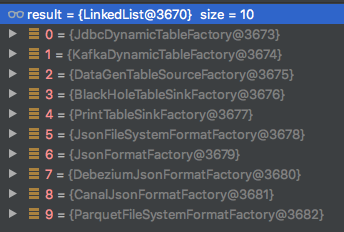
result list内容如下:
然后检查每个类是否可由DynamicTableSinkFactory AssignableFrom,这个是一个native方法:
final List<Factory> foundFactories = factories.stream()
.filter(f -> factoryClass.isAssignableFrom(f.getClass()))
.collect(Collectors.toList());
过滤后结果:
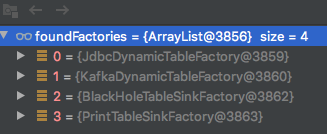
此时就需要用前面提到的connector属性名字比如kafka来匹配了,即为下面代码中的factoryIdentifier变量:
final List<Factory> matchingFactories = foundFactories.stream()
.filter(f -> f.factoryIdentifier().equals(factoryIdentifier))
.collect(Collectors.toList());
最后返回return (T) matchingFactories.get(0);

调用该实现类的createDynamicTableSink方法来创建具体的DynamicTableSink实现类如KafkaDynamicSink
3 SPI的实现原理
3.1 重要属性
// 这里就写死了SPI定义文件的路径前缀
private static final String PREFIX = "META-INF/services/";
// 服务接口的缓存,泛型S就是服务接口类
// 初始为空
// key为接口的某个实现类的全限定名,value为该实现类的具体实例
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// 当前懒查找的遍历器,reload方法时providers清空,初始化lookupIterator
private LazyIterator lookupIterator;
3.2 重要方法
3.2.1 ServiceLoader.load(HelloService.class)
public static <S> ServiceLoader<S> load(Class<S> service) {
// 获取当前线程上下文类加载器,用户线程就是AppClassLoader
ClassLoader cl = Thread.currentThread().getContextClassLoader();
// 该方法会创建一个ServiceLoader实例,见3.2.2
return ServiceLoader.load(service, cl);
}
ServiceLoader#load(service, cl)如下
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
3.2.2 ServiceLoader(Class svc, ClassLoader cl)
调用ServiceLoader.load(service, cl)时其实就是创建一个ServiceLoader实例
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
// 关键是这个reload方法
reload();
}
3.2.3 ServiceLoader.reload()
调用该方法清空provider缓存后,后序调用iterator方法时都会重新开始懒查找和初始化provider,就像新创建loader时一样。
此方法适用于可以将新的provider程序安装到正在运行的JVM中的情况。
public void reload() {
// 清空loader的provide cache,以使得重载所有provider
providers.clear();
// 使用目标服务接口类和classLoader构建一个LazyIterator
lookupIterator = new LazyIterator(service, loader);
}
3.2.4 services.iterator()
执行此Iterator<HelloService> iterator = services.iterator()方法时,返回如下:
// 这里的泛型S就是我们制定的服务接口类,如HelloService
public Iterator<S> iterator() {
return new Iterator<S>() {
// 已知的provider遍历器
// 在首次遍历的时候,knownProviders为空
// 以后创建遍历器的时候,knownProviders便有值了
// 当然前提是没有调用reload方法
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
// 首次执行时,该方法为false,返回lookupIterator.hasNext()
if (knownProviders.hasNext())
return true;
// 这里其实执行的是LazyIterator.hasNextService
return lookupIterator.hasNext();
}
// lookupIterator懒加载
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
3.2.5 LazyIterator.hasNextService
private boolean hasNextService() {
// nextName初始为null
if (nextName != null) {
return true;
}
// configs初始为null
if (configs == null) {
try {
// fullName就是META-INF/services/类的全限定名
// 如META-INF/services/demos.spi.test2.HelloService
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
// 获取该资源文件的枚举
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
// pending初始为空
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
// configs(比如HelloService文件)有内容时不会走这
return false;
}
// pending是从demos.spi.test2.HelloService文件中解析
// 出的所有实现类名构成的数组的遍历器
pending = parse(service, configs.nextElement());
}
// 获取首个实现类名称
nextName = pending.next();
return true;
}
3.2.6 LazyIterator.next
if (acc == null) {
// 会走这一步
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
3.2.7 LazyIterator.nextService
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
// 获取当前实现类名
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
// 使用指定类加载器加载该实现类,但并不初始化
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
// 实现类初始化并强转为接口类
S p = service.cast(c.newInstance());
// 以实现类全限定名为key放入缓存
providers.put(cn, p);
// 返回该实现类的实例
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
3.3 小结
其实SPI的原理就是:
ServiceLoader<HelloService> services = ServiceLoader.load(HelloService.class)这一步就是创建一个泛型为指定接口类如HelloService的ServiceLoader实例,并指定ClassLoader为当前线程上下文ClassLoader- 每次遍历的时候先用
iterator.hasNext读取一个用户定义的服务接口文件里的实现类全限定名 - 然后再用
iterator.next()使用LazyIterator,按约定的服务接口路径读取实现类类名,完成加载(注意这里就是懒加载)并放入providers缓存 - 执行
iterator.next().sayHello()就是调用该实现类实例的某实现方法 - 以后再次创建iterator进行遍历的时候就是使用knownProviders以及providers缓存了,无需再次加载
4 SPI常见的使用场景
- JDBC加载不同类型的Driver。
- jdbc4.0以前,还需
Class.forName(“xxx”)来装载驱动。 - jdbc4也基于spi的机制来发现驱动提供商了,可以通过
META-INF/services/java.sql.Driver文件里来指定实现类的方式对外暴露Driver。
- jdbc4.0以前,还需
- 日志门面模式接口的实现类加载,SLF4J加载不同提供商的日志实现类
- Spring
Spring中大量使用了SPI,比如:对servlet3.0规范、对ServletContainerInitializer的实现、自动类型转换Type Conversion SPI(Converter SPI、Formatter SPI)等 - Dubbo
Dubbo中也大量使用SPI的方式实现框架的扩展, 不过它对Java提供的原生SPI做了封装,允许用户扩展实现Filter接口。在程序执行时会根据用户的配置来按需取接口的具体实现类。 - Phoenix-Avatica使用SPI
5 SPI总结
5.1 优点
- 解耦
调用者无需知道服务提供者具体类信息,模块之间依赖不需要对实现类硬编码,即可执行方法调用。一旦代码里涉及具体的实现类,就违反了可插拔的原则。这种情况下,如果需要增删改实现,就必须要修改调用方的代码,这是很糟糕的。 - 可动态添加实现类
可调用ServiceLoader.reload()方法,将新的provider安装到正在运行的JVM中。也就是说,可以直接动态替换或升级实现类。
5.2 缺点
- 需要遍历
回忆下执行代码:Iterator<HelloService> iterator = services.iterator(); while (iterator.hasNext()){ iterator.next().sayHello(); }
也就是要执行某个实现类时,需要遍历查找,遍历中就要加载所有实现类。
- 无法通过服务名称加载指定实现类
- ServiceLoader实例非线程安全
5.3 Dubbo
针对原生JDK SPI缺点,我们可以考虑使用Dubbo实现的SPI机制。
java 的spi 只有简单的 策略选择 ,针对接口级别 ,dubbo spi 支持 键值对 配合url bus ,支持方法级别的adaptive
参考文档
- JDK8API-ServiceLoader
- Oracle-JDK SPI-intro
- 深入理解Java SPI机制
- 深入理解Java中的spi机制
- 深入理解 Java 中 SPI 机制
- 高级开发必须理解的Java中SPI机制
最后
以上就是壮观早晨最近收集整理的关于Java-SPIJava-SPI1 基本概念2 实例3 SPI的实现原理4 SPI常见的使用场景5 SPI总结参考文档的全部内容,更多相关Java-SPIJava-SPI1内容请搜索靠谱客的其他文章。








发表评论 取消回复