PySpark实战
- 第零章:MySQL练习
- 0.1 SQL常用指令
- 0.2 SQL基础知识
- 第零章:XGB练习
- 0.1 XGB模型解读
- 第零章:spark和nyoka进行PMML模型的转换与加载
- 0.1 nyoka
- 0.2 spark
- 第一章:了解Spark
- 1.1 什么是Apache Spark
- 1.2 Spark作业和API
- 1.3 Spark2.0的结构
- 1.4 小结
- 第二章:弹性分布式数据集
- 2.1 RDD的内部运行方式
- 第三章:推荐系统实战
- 1.1 推荐系统介绍
- 1.2 推荐系统测评
- 1.3 推荐系统实验方法
- 第四章:利用用户行为数据
- 2.1 用户行为数据简介
前言:本教程为使用PySpark进行推荐算法实战训练的技术文档撰写,因此,会有诸多推荐算法相关应用。
第零章:MySQL练习
- 数据库地位:前端所呈现的内容,一般是经过“数据库(SQL)->服务器->前端”,MySQL这款软件是目前IT行业最热门的一款数据库软件。
- 容器:(1)存在内存中:数组、集合(缺点:断电数据即丢失);
(2)可以永久存储:文件(缺点:查询很麻烦);
(3)结合前两者可以永久存储 &易于管理和查询:数据库:DB(存储了一系列有组织&规划的数据);DBMS:数据库管理系统(如MySQL/Oracle),进行数据库的检索/插入/更新/删除、SQL:结构化查询语言,是专门用来和数据库通信的语言(和C一样) - DBA:数据库管理员职务,专门招聘
- 数据库特点:(1)数据存放流程:将数据放入表中,表再放入库中.(2)表名具有唯一性。(3)表 由列组成,也称为字段,每一列类似于JAVA中的“属性”。(4)表中的数据 按行存储,每一行类似于JAVA中的“对象”。
- 初始化库:information_schema、mysql、performance_schema、sys
0.1 SQL常用指令
- SELECT:SELECT 语句用于从表中选取数据,结果被存储在一个结果表中(称为结果集)。
- scott库创建:数据库名:scott;字符集:utf8。导入**.sql文件,运行该数据库,再刷新一次表,一般是三张重要的表“dept、emp、salgrade”
0.2 SQL基础知识
1. hive和MySQL区别和练习?
(1)结构: MySQL有四层结构:连接层、服务层、引擎层、存储层;Hive是为了数据仓库设计的,数据存储在hadoop上(MySQL存储在设备或者本地)
(2)数据更新: Hive不支持数据的改写和添加,是在加载的时候就已经确定好了;
(3)索引: Hive无索引,每次扫描所有数据,底层是MR,并行计算,适用于大数据量;MySQL有索引,适合在线查询数据;
(4)执行: Hive底层是MarReduce;MySQL底层是执行引擎
PS:MapReduce是一种分布式计算框架 ,以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。 主要用于搜索领域,解决海量数据的计算问题。 MR有两个阶段组成:Map和Reduce,用户只需实现map ()和reduce ()两个函数,即可实现分布式计算。
(5)可扩展性: Hive可扩展大数据量;MySQL存在限制
2. presto、hive和spark引擎区别?
参考知乎
(1)主流的执行引擎:Hive、Sparksql、Presto、Kylin、Impala、Druid、Clickhouse
(2)Hive和Presto有很大的相似性:
① Presto没有使用MapReduce,它是通过一个定制的查询和执行引擎来完成的。
② 它的所有的查询处理是在内存中,这也是它的性能很高的一个主要原因。
③ Presto和Spark SQL有很大的相似性,这是它区别于Hive的最根本的区别(Hive)。
(3)
第零章:XGB练习
0.1 XGB模型解读
第零章:spark和nyoka进行PMML模型的转换与加载
0.1 nyoka
0.2 spark
(1)参考pmml官方文档:https://github.com/jpmml/pyspark2pmml
(2)主要有如下几个步骤:
- 在VSCode中需要带参数运行:“args”: [“–jars”, “D:/GIitLibary/pyspark-pmml-tools/pyspark2pmml/PMML_V2.0/jpmml-sparkml-executable-1.3.15.jar”],
- 检查好jar包(下载时选好)和spark的版本对应关系(spark-shell查看)
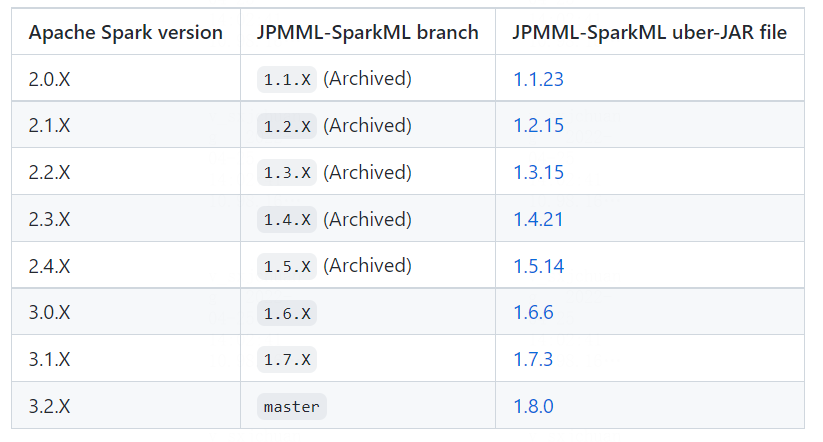
- 需要手动安装pmml包,即将spark2pmml的包放入sitepackge文件夹中
- 还可以参考博客:spark转pmml
第一章:了解Spark
快速易用的处理复杂数据的矿机!
1.1 什么是Apache Spark
1.2 Spark作业和API
1.3 Spark2.0的结构
1.4 小结
第二章:弹性分布式数据集
2.1 RDD的内部运行方式
第三章:推荐系统实战
1.1 推荐系统介绍
1. 用户有明确需求的情况下: 可以根据用户自己的喜好去挑选物品,即使在海量物品的情况,只要根据系统的分类即可精准获取;
2. 用户没有明确需求: (1)请教”专家“,如:看电影、餐后娱乐;(2)个性化推荐系统:通过联系用户和信息,一方面帮助用户发现对自己有价值的信息。另一方面,让信息能够被有效地展现,实现信息消费者和信息生产者的双赢。
推荐系统和搜索引擎算两种互补的技术
3. 基本原理:通过一定方式将用户和物品联系起来,如利用好友、用户的历史兴趣记录以及用户的注册信息等。
4. 应用领域:电子商务(亚马逊/淘宝):个性化推荐列表&相关推荐列表;电影和视频网站(Netflix/抖音):
1.2 推荐系统测评
- 明确结构:3个参与方:用户、物品提供者和提供推荐系统的网站;3个评价方面:(1)推荐系统需要推荐到真正感兴趣的事物。(用户"获利")(2)要让被推荐的事物多样化而不是仅推荐几个大型的、著名的事物。(物品提供者获利)(3)能够让推荐系统本身搜集到高质量的用户反馈,需要不断完善推荐的质量,增加用户和网站的交互,提高网站的收录。(网站获利)
- 具体指标(用户维度、物品维度、时间维度):用户满意度、预测准确度(RMSE/MAE)、TopN推荐(主流)(准确率/召回率)、覆盖率(信息熵&基尼系数)(等待不断完善)、马太效应(强者更强,破坏生态)高低(通过基尼系数评定)、多样性、新颖性、惊喜度、信任度、实时性、健壮性、商业目标完成率
1.3 推荐系统实验方法
- 离线实验:(1)通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集;(2)将数据集按照一定的规则分为训练集和测试集;(3)再训练集上训练用户兴趣模型,在测试集上进行预测;(4)通过事先定义的离线指标评测算法在测试集上的预测结果。==缺点:==无法获得很多商业上的关注点,如点击率、转化率、离线指标难以评判系统好坏
- 用户调查:上线测试前进行一次称为用户调查的测试,即需要观察和记录一些真实用户的行为,让他们统一回答一些问题,通过对比分析他们的行为和答案与我们预测的答案之间的差距来了解系统的性能。==缺点:==成本高、统计意义难以保证、与真实的在线测试差别大
- 在线实验:完成离线实验和必要的用户调查后,将推荐系统上线做AB测试:通过一定的规则将用户随机分成几组,并对不同组的用户采用不同的算法,通过统计不同组用户的各种不同的评价指标(点击率)来比较不同的算法。==缺点:==AB测试设计复杂(前后端之间有很多其他层,这些层之间进行AB测试会有很多互相的干扰)、出问题后的风险大
第四章:利用用户行为数据
2.1 用户行为数据简介
最后
以上就是开心香烟最近收集整理的关于【技术文档】PySpark学习笔记~ 持续更新第零章:MySQL练习第零章:XGB练习第零章:spark和nyoka进行PMML模型的转换与加载第一章:了解Spark第二章:弹性分布式数据集第三章:推荐系统实战第四章:利用用户行为数据的全部内容,更多相关【技术文档】PySpark学习笔记~内容请搜索靠谱客的其他文章。








发表评论 取消回复