文章目录
- 1. 简介
- 2. 架构及概念
- 2.1 服务器
- 2.2 数据源
- 2.3 查询执行模型
- 3. 安装
- 3.1 单机
- 3.2 客户端
- 3.2.1 命令行
- 3.2.2 JDBC
- 3.3 集群
- 3.3.1 Coordinator
- 3.3.2 Worker
- 4. 使用
- 4.1 连接器
- 4.1.1 MySQL
- 4.1.2 Hive
- 4.2 跨库关联
- 5. 监控 Web UI
- 5.1 集群概览
- 5.2 查询列表
- 5.3 查询详情
- 5.3.1 Overview
- 5.3.2 Live Plan
- 5.3.3 Stage Performance
- 5.3.4 Splits
- 5.3.5 Json
Presto 0.240
1. 简介
Presto是FaceBook开源的一个大数据分布式SQL查询引擎,是用于查询分布在一个或多个不同数据源中大数据集的工具。Presto是在机器集群上运行的分布式系统,它可以分析大量数据。使用Presto,可以使用ANSI SQL在许多数据不同的数据源上访问和查询数据。
Presto不是通用关系数据库。它不能替代MySQL,PostgreSQL或Oracle等数据库。Presto并不是设计用来处理在线事务处理(OLTP),对于为数据仓库或分析而设计和优化的许多其他数据库,也是如此。
Presto是一种工具,被设计为使用分布式查询来有效查询大量数据。如果你使用TB或PB的数据,则可能会使用与Hadoop和HDFS交互的工具。Presto旨在作为一个使用MapReduce作业管道查询HDFS的可供选择的工具(例如Hive或Pig),但Presto不仅限于访问HDFS。Presto可以扩展为在各种类型的数据源上运行,包括传统的关系数据库和其他数据源,例如Cassandra。
Presto旨在处理数据仓库和分析:数据分析,汇总大量数据并生成报告。这些工作负载通常被归类为在线分析处理(OLAP)。
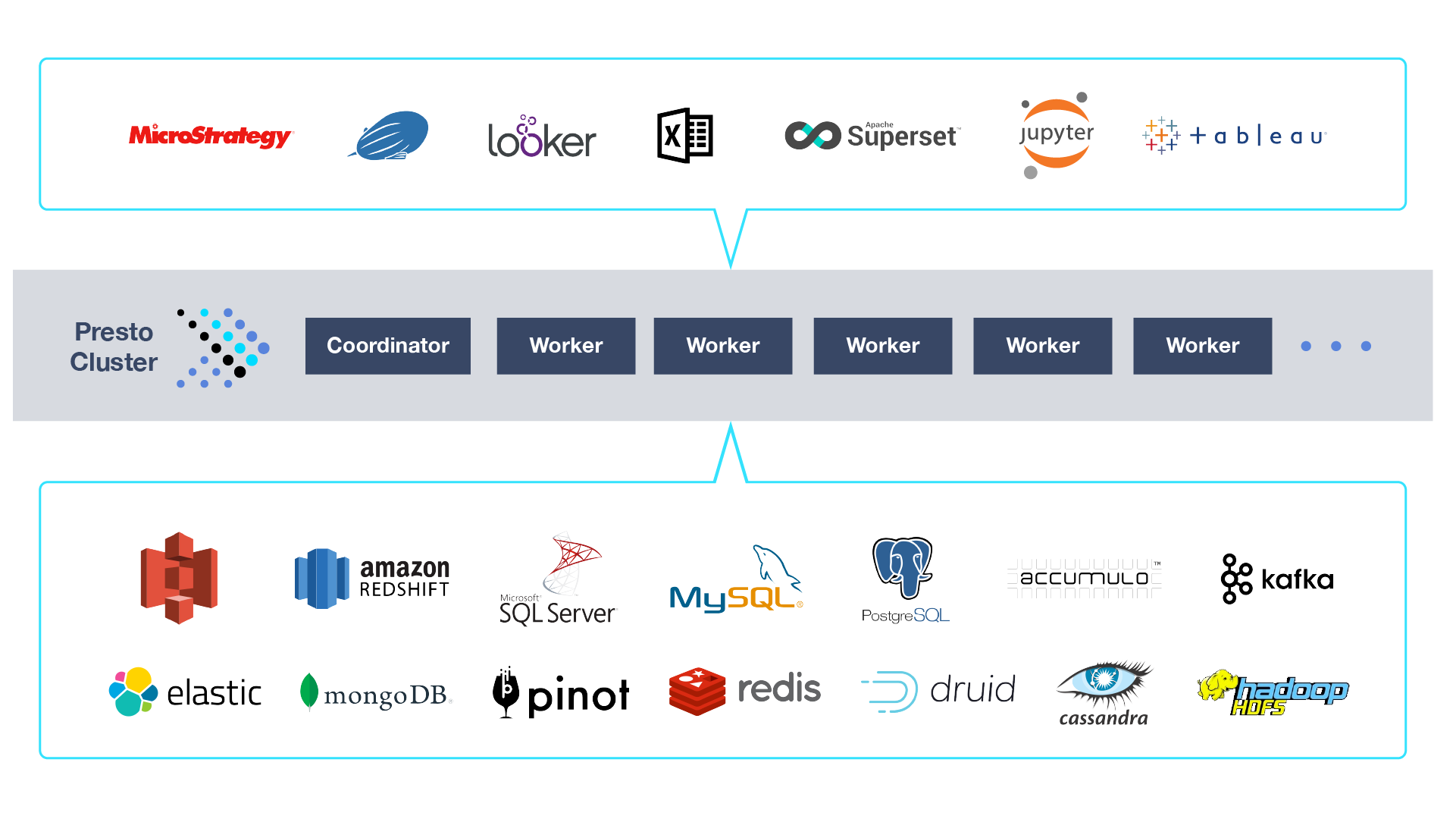
2. 架构及概念
2.1 服务器
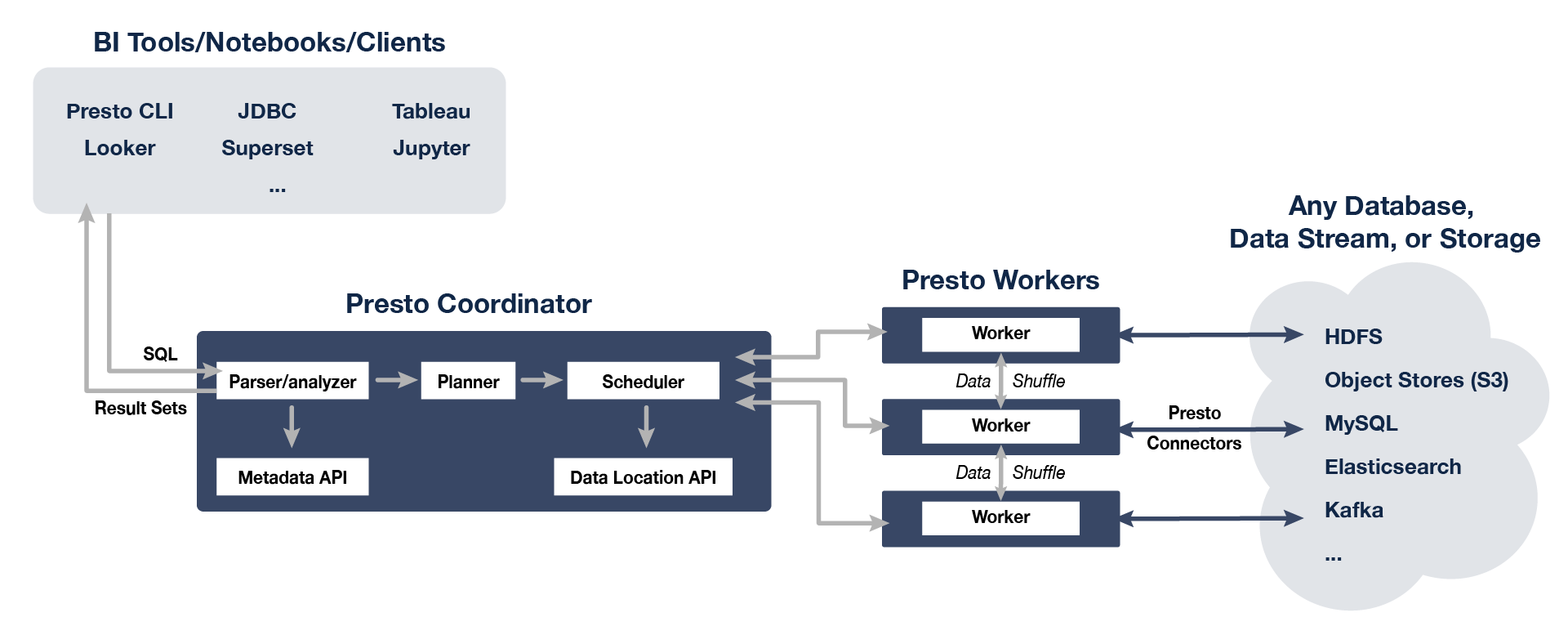
Presto服务器有两种类型:Coordinator和Worker。
Coordinator
负责解析语句,计划查询和管理Worker的服务器。它是Presto的“大脑”,也是客户端连接和提交执行语句的节点。安装一个或多个Worker的同时,必须有一个Coordinator。开发或测试时,可以将Presto的单个实例同时配置为执行这两种类型。
Coordinator跟踪每个Worker上的活动并协调查询的执行。Coordinator将创建一个涉及一系列阶段的查询逻辑模型,然后将其转换为在Worker集群上运行的一系列关联任务。
Coordinator使用REST API与Worker和客户端进行通信。
Worker
负责执行任务和处理数据。Worker从连接器获取数据并相互交换中间数据。Coordinator负责从Worker获取结果并将最终结果返回给客户端。
当Worker启动时,它将自己通知给Coordinator中的Discovery服务器,这使Coordinator可以使用它来执行任务。
Worker使用REST API与其他Worker和Coordinator进行通信。
2.2 数据源
Connector
连接器使Presto适配数据源,例如Hive或关系数据库。你可以像使用数据库驱动程序一样来使用连接器。它是Presto SPI的一种实现, 它允许Presto使用标准API与资源进行交互。
Catalog(数据源)
Catalog包含Schema,并通过连接器引用数据源。
Schema(数据库)
Schema是组织表的一种方式。Catalog和Schema共同定义了一组可以查询的表。当使用Presto访问Hive或关系数据库(例如MySQL)时,Schema会转换为目标数据库中的相同概念。其他类型的连接器可能选择以对基础数据源有意义的方式将表组织到Schema中。
Table(表)
Table是一组无序的行,它们被组织成具有类型的命名列。这与任何关系数据库中的相同。从源数据到表的映射由连接器定义。
2.3 查询执行模型
Presto执行SQL语句,并将这些语句转换为在Coordinator和Worker的分布式集群中执行的查询。
Statement(SQL语句)
Presto执行与ANSI兼容的SQL语句。当Presto文档引用某条语句时,它就是指ANSI SQL标准中定义的语句,该标准由子句,表达式和谓词组成。
在Presto中,语句仅引用SQL语句的文本表示形式。执行语句后,Presto会创建一个查询以及一个查询计划,然后将其分配给一系列Worker。
Query(查询)
当Presto解析一个Statement时,它将转换为Query并创建一个分布式查询计划,然后将其实现为在Worker上运行的一系列相互关联的Stage。当你在Presto中检索有关Query的信息时,你会收到生成结果集以响应Statement所涉及的每个组件的快照。
可以将Statement视为传递给Presto的SQL语句,而Query是指为执行该SQL语句而实例化的配置和组件。Query包含Stages,Tasks, Splits,Connectors以及其他组件和数据源,它们协同工作以产生结果。
Stage(阶段)
当Presto执行Query时,它通过将执行分解为Stage层次结构来执行。Stage只是Coordinator用于查询执行计划进行管理和建模的逻辑概念。例如,如果Presto需要从Hive中存储的十亿行数据进行聚合,则可以通过创建一个根Stage来聚合其他几个Stage的输出来实现,所有这些Stage被设计为实现分布式查询计划的不同部分。
包含Query的Stage的层次结构类似于一棵树。每个Query都有一个根Stage,该Stage负责汇总其他Stage的输出。Stage是Coordinator用来为分布式查询计划建模的工具,但是Stage本身并不在Worker上运行。
Task(任务)
Stage对分布式查询计划的特定部分进行建模,但是Stage本身不会在Worker上执行。一个Stage是作为一系列Task分散在Worker中中执行,因此可以并行的执行一个Stage。
Task是Presto体系结构中的“work horse”,因为分布式查询计划被分解为一系列Stage,再转换为Task,然后对这些Task进行操作或处理Split。Task具有输入和输出,就像一个Stage可以通过一系列Task并行执行一样,一个Task正在与一系列Driver并行执行。
Split(拆分)
Task按Split操作,Split是较大数据集的一部分。Split是对外部存储系统中可寻址的数据块的一种隐晦处理。Split会被分配给那些负责读取数据的Task。分布式查询计划的最低级别的Stage通过连接器的Split来检索数据,而分布式查询计划的较高级别的中间阶段则从其他Stage检索数据。
当Presto计划Query时,Coordinator将查询连接器以获取表可用的所有拆分的列表。Coordinator跟踪哪些机器正在运行哪些Task,以及哪些Task正在处理哪些Split。
Driver(驱动)
Task包含一个或多个并行Driver,因此可以并行的执行一个Task。一个Driver就是作用于Split上的一系列Operator的集合。Driver根据数据进行操作,并组合运算符以产生输出,再将其由一个Task聚合,然后在另一个Stage传递给另一个Task。Driver是一系列运算符实例,或者你可以将Driver视为内存中一组物理运算符。它是Presto架构中最低的并行度。Driver具有一个输入和一个输出。
Operator(算子)
Operator操作,转换和产生数据。一个Operator代表对一个Split的一种操作,Operator所代表的一个计算和操作作用于Split,并产生输出结果。例如,表扫描从连接器获取数据并生成可被其他运算符使用的数据,而过滤器运算符通过在输入数据上应用谓词来消费数据并生成子集。
Exchange(交换)
在Presto节点之间为查询的不同阶段交换传输数据,用于连接不同的stage。Task将数据产生到输出缓冲区中,并使用交换客户端使用其他任务中的数据。
3. 安装
3.1 单机
官网下载
解压,然后在安装目录中创建文件夹etc,在文件夹etc中依次创建配置文件:node.properties、jvm.config、config.properties、log.properties,还有连接器配置。
node.properties(节点属性,特定于每个节点的环境配置)
node.environment=production
node.id=1
node.data-dir=/usr/local/softwares/presto/presto-server-0.240/data
node.environment:当前环境名称。集群中的所有Presto节点必须具有相同的环境名称。
node.id:此Presto安装的唯一标识符,这对于每个节点都必须是唯一的。在重新启动或升级Presto时,此标识符应保持一致。如果在一台计算机上运行多个Presto安装(即同一台计算机上的多个节点),则每个安装必须具有唯一的标识符。
node.data-dir:数据目录的位置(文件系统路径)。Presto将在此处存储日志和其他数据。
jvm.config(Java虚拟机的命令行选项)
-server
-Xmx5G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
config.properties(Presto服务器的配置)
以下配置让该台机器既是Coordinator(Discovery),又是Worker。
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8100
query.max-memory=3GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://192.168.110.40:8100
coordinator:允许此Presto实例充当Coordinator(接受来自客户端的查询并管理查询执行)。
node-scheduler.include-coordinator:允许在Coordinator上安排工作。对于较大的集群,Coordinator上的处理工作会影响查询性能,因为计算机的资源无法用于计划,管理和监视查询执行的关键任务。这里该节点既是Coordinator又是Worker,所以设为true。
http-server.http.port:指定HTTP服务器的端口。Presto使用HTTP进行内部和外部所有通信。
query.max-memory:查询可以使用的最大分布式内存量(整个集群最大用户内存中一个Query可用的最大用户内存,默认20GB)。
query.max-memory-per-node:查询可在任何一台计算机上使用的最大用户内存量(单个Worker一个Query可用的最大用户内存,默认JVM max memory * 0.1)。
query.max-total-memory-per-node:查询可在任何一台计算机上使用的最大用户和系统内存量,其中系统内存是读取器,写入器和网络缓冲区等在执行期间使用的内存(单个Worker一个Query可用的最大用户和系统内存,默认JVM max memory * 0.3)。
discovery-server.enabled:Presto使用Discovery服务来查找集群中的所有节点。每个Presto实例在启动时都会向Discovery服务注册。为了简化部署并避免运行其他服务,Coordinator可以运行Discovery服务的嵌入式版本。它与Presto共享HTTP服务器,因此使用相同的端口。
discovery.uri:Discovery服务器的URI。因为我们已经在Coordinator中启用了Discovery的嵌入式版本,所以它应该是Coordinator的URI。此URI不得以斜杠结尾。
log.properties(日志级别)
com.facebook.presto=INFO
连接器配置
在文件夹etc下创建文件夹catalog,Presto通过catalog中的连接器访问数据,连接器提供目录内部的所有模式和表。
以MySQL为例:
mysql4_23.properties(文件名任意,但是需要properties格式的文件。该文件名也用于Presto客户端连接时使用。)
connector.name=mysql
connection-url=jdbc:mysql://192.168.4.23:4306
connection-user=root
connection-password=root
connector.name:指定连接器的名称,固定。
每个连接器配置不一定相同,具体可查看Presto 官方连接器文档

回到安装目录,运行Presto服务器。注意config.properties文件夹中配置的内存大小,不要超过jvm.config配置的堆大小。
前台运行
./bin/launcher run
后台运行
./bin/launcher start
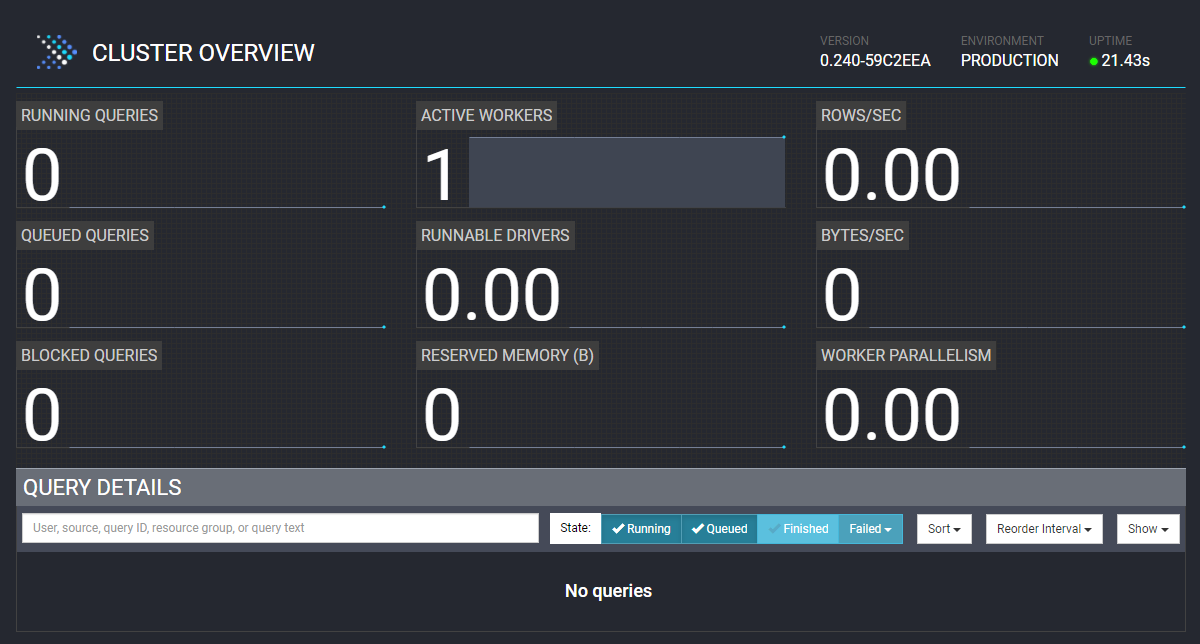
访问config.properties中配置的地址,可看到当前活动的Worker有一个。
3.2 客户端
3.2.1 命令行
官网下载
将jar包更名为presto-cli,再添加可运行权限chmod u+x presto-cli
./presto-cli --server 192.168.110.40:8100 --catalog mysql4_23
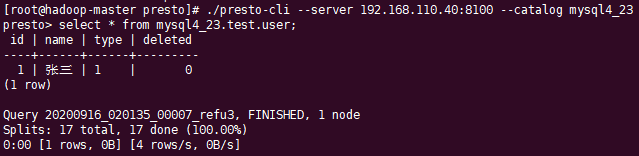
3.2.2 JDBC
添加依赖
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-jdbc</artifactId>
<version>0.240</version>
</dependency>
这里演示MySQL,需要MySQL开启SSL。其他连接器可查看官方JDBC Driver文档
@Test
public void mysqlTest() throws SQLException {
Connection connection = null;
// jdbc:presto://host:port/catalog/schema
String jdbcUrl = "jdbc:presto://192.168.110.40:8100/mysql4_23";
try {
connection = DriverManager.getConnection(jdbcUrl, "test", null);
Statement stmt = connection.createStatement();
String sql = "select * from user";
ResultSet rs = stmt.executeQuery(sql);
System.out.println(sql);
while (rs.next()) {
System.out.println(rs.getString(1) + "t" + rs.getString(2));
}
} finally {
if (connection != null) {
connection.close();
}
}
}
可在监控页看到查询等信息
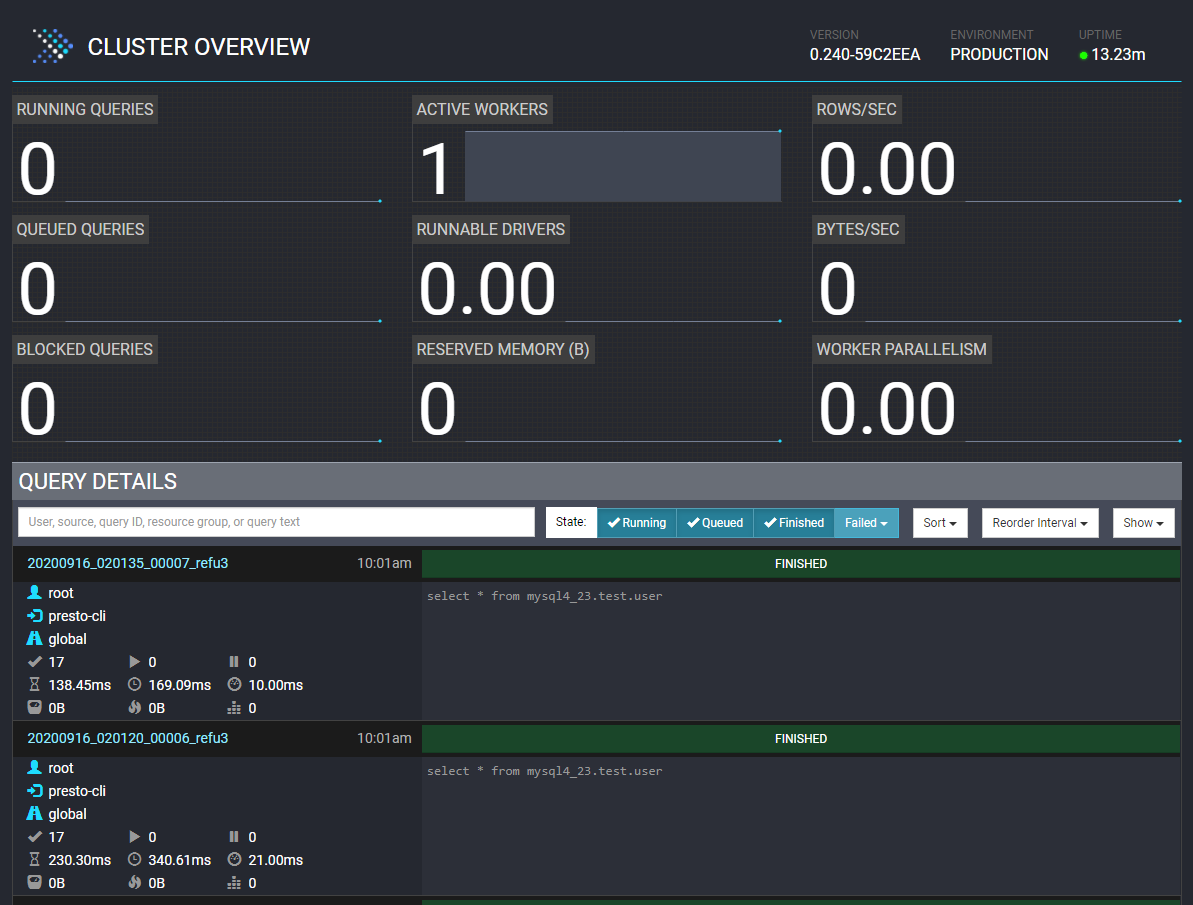
3.3 集群
这里只使用一台机器。因为一台机器上不能有两个纯Worker,所以其中一个Presto服务器既是Coordinator又是Worker,另一个纯Worker。
解压,复制两份。
3.3.1 Coordinator
配置和上方单节点相同,这里注意内存配置。
node.properties
node.environment=production
node.id=1
node.data-dir=/usr/local/softwares/presto/presto-cluster/presto-server-coordinator/data
jvm.config
-server
-Xmx2G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
config.properties
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8100
query.max-memory=1GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://192.168.110.40:8100
如果多台机器,可将node-scheduler.include-coordinator设为false,让Coordinator不作为Worker。
log.properties
com.facebook.presto=INFO
创建文件夹catalog,添加连接器。集群下,只需要配置Coordinator下的就好了。
3.3.2 Worker
node.properties
node.environment=production
node.id=2
node.data-dir=/usr/local/softwares/presto/presto-cluster/presto-server-worker-1/data
jvm.config
-server
-Xmx2G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
config.properties
coordinator=false
http-server.http.port=8101
query.max-memory=1GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=1GB
discovery.uri=http://192.168.110.40:8100
log.properties
com.facebook.presto=INFO
将两个服务器都启动,等待Discovery服务查询集群中节点完毕后,监控页显示有两个Worker。
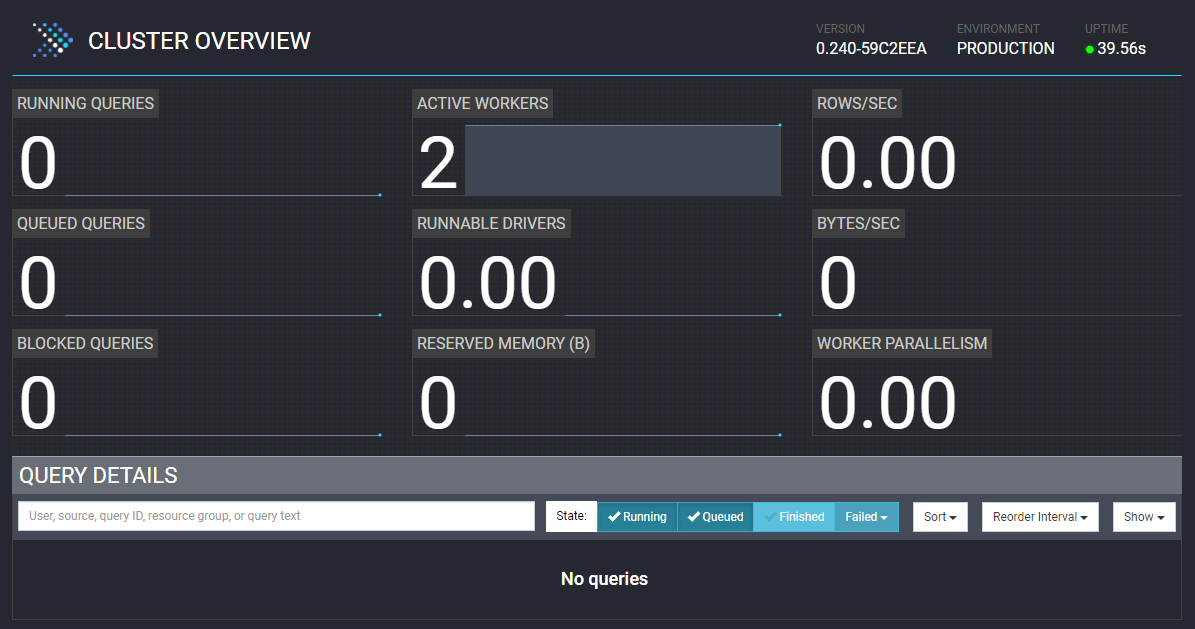
4. 使用
4.1 连接器
4.1.1 MySQL
mysql4_23.properties
connector.name=mysql
connection-url=jdbc:mysql://192.168.4.23:4306
connection-user=root
connection-password=root
使用Presto客户端连接
./presto-cli --server 192.168.110.40:8100 --catalog mysql4_23
4.1.2 Hive
修改 hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.110.40:9083</value>
</property>
启动Hive
./bin/hive --service metastore
在etc/catalog文件夹下新建hive110_40.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://192.168.110.40:9083
使用Presto客户端连接
./presto-cli --server 192.168.110.40:8100 --catalog hive110_40 --schema default
--schema:可不指定schema
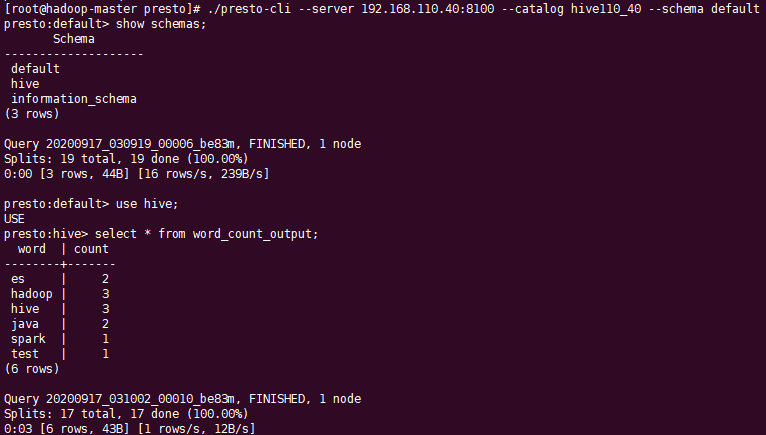
4.2 跨库关联
MySQL创建表user,添加一些数据。
Hive创建表address,再将数据添加到表中
create table address(
address_id int,
user_id int,
address string
)ROW format delimited fields terminated by ',' STORED AS TEXTFILE;
load data inpath 'hdfs:/browerTest/input/address.csv' into table address;
混合查询,这边的--catalog 用system ,--schema 用 runtime
./presto-cli --server 192.168.110.40:8100 --catalog system --schema runtime
查看MySQL和Hive中的数据
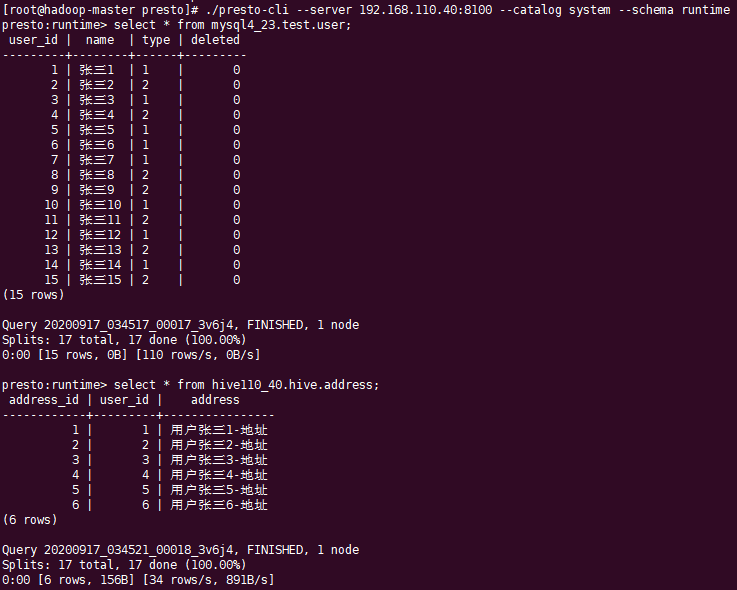
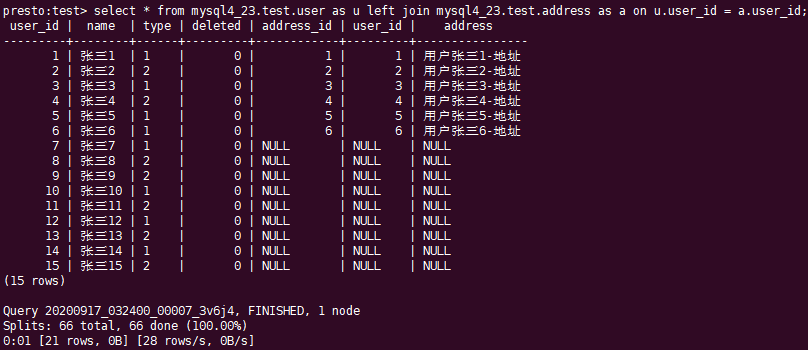
将两表根据user_id关联
5. 监控 Web UI
5.1 集群概览
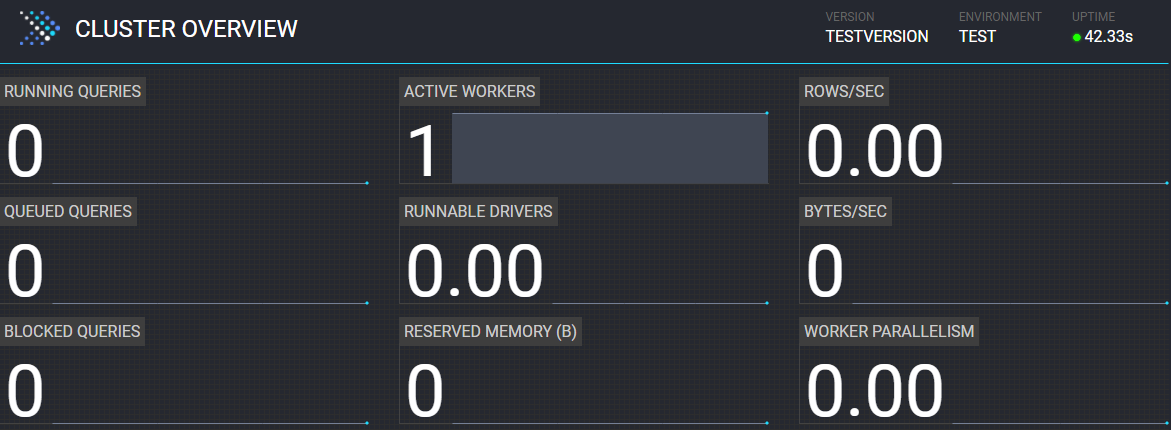
| Running Queries:运行中的查询。 Presto集群中当前正在运行的查询总数。包含所有的用户。 | Active Workers:活动Worker。 集群中活动Worker节点的数量。 | Rows/Sec:行/秒。 集群中正在运行的所有查询中每秒处理的总行数。 |
| Queued Queries:已排队的查询。 所有用户的Presto集群的排队查询总数。 已排队的查询正在等待协调器根据资源组配置安排它们。 | Runnable Drivers:可运行的Driver。 集群中可运行Driver的平均数量。 | Bytes/Sec:字节/秒。 集群中所有正在运行的查询中每秒处理的字节总数。 |
| Blocked Queries:已阻止的查询。 集群中被阻止查询的数量。由于缺少可用拆分或其他资源,无法处理被阻止的查询。 | Reserved Memory:保留的内存。 Presto中保留的内存总量(以字节为单位)。 | Worker Parallelism:Worker并行数。 Worker并行的总数,即集群中运行的所有查询中所有Worker之间的线程CPU时间总量。 |
5.2 查询列表
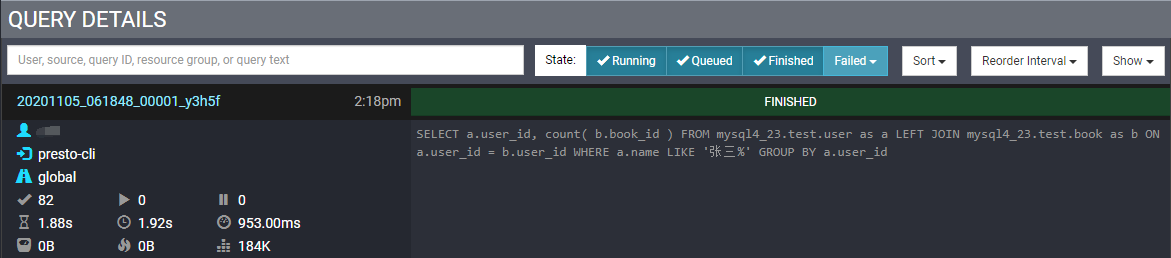
| Completed Splits:查询已完成的Split数量。 该示例显示了82个已完成的拆分。在查询执行开始时,该值为0。在查询执行期间,拆分完成时该值增加。 | Running Splits:查询的运行中的Split数量。 查询完成后,该值始终为0。但是,在执行过程中,此数字会随着拆分运行和完成而改变。 | Queued Splits: 查询的已排队的Split数量 查询完成后,该值始终为0。但是,在执行过程中,此数字会随着拆分在排队状态和运行状态之间移动而改变。 |
| Wall Time:执行查询所花费的总时间(不包括排队时间)。 即使您正在分页结果,该值也会继续增长。 | Total Wall Time:该值与Wall Time相同,除了它还包括排队时间。 Wall Time不包括查询排队的任何时间。 这是你从提交查询到收到结果所需的总时间。 | Peak Total Memory: 查询执行期间的峰值总内存使用量。 查询执行期间的某些操作可能需要大量内存,因此知道峰值是什么很有用。 |
| Current Total Reserved Memory:查询执行时使用的当前总保留内存。 对于完成的查询,此值为0。 | CPU Time:处理查询所花费的总CPU时间。 这个值通常是比Wall Time长,因为Worker和Worker的线程之间的并行执行全部分开计算并累加。例如,如果四个CPU花费1秒来处理查询,则最终的总CPU时间为4秒。 | Cumulative User Memory:在整个查询处理中使用的累积用户内存。 这并不意味着所有内存都被同时使用。 这是累积的内存量。 |
5.3 查询详情

5.3.1 Overview
概览页包括:Session,Execution,Resource Utilizations Summary,Timeline,Query,Prepare Query,Stages和Tasks。
Stages
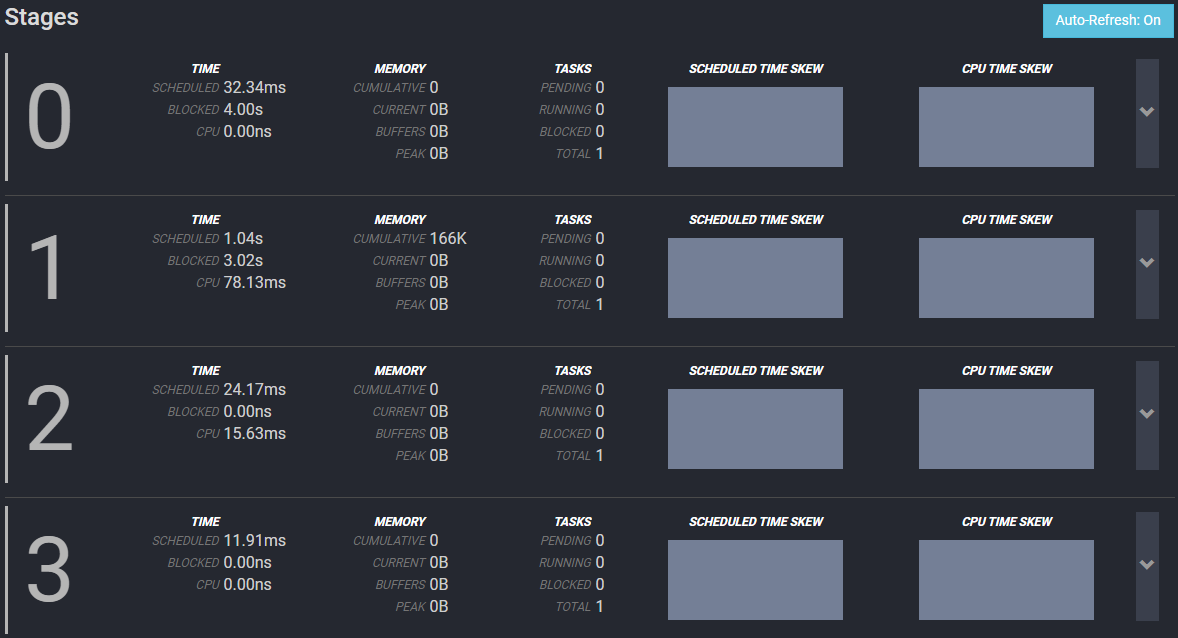
| Time | Memory | Tasks |
|---|---|---|
| SCHEDULED:在完成该Stage的所有任务之前,该Stage保持调度的时间。 | CUMULATIVE:在整个Stage中使用的累积内存。 这并不意味着所有内存都被同时使用。 它是处理期间使用的累积内存量。 | PENDING:该Stage的待处理任务数。 查询完成后,此值始终为0。 |
| BLOCKED:等待数据期间,Stage被阻塞的时间。 | CURRENT:当前用于该Stage的总保留内存。对于完成的查询,此值为0。 | RUNNING:该Stage中正在运行的任务数。 查询完成后,该值始终为0。在执行过程中,该值随着任务的运行和完成而变化。 |
| CPU:该Stage中任务的CPU时间总量。 | BUFFERS:当前数据正在等待处理的内存量。 | BLOCKED:该Stage被阻止的任务数。 查询完成后,该值始终为0。但是,在执行期间,此数字将随着任务在阻塞状态和运行状态之间移动而改变。 |
| PEAK:该Stage中的峰值总内存。 查询执行期间的某些操作可能需要大量内存,因此知道峰值是什么很有用。 | TOTAL:查询已完成的任务数。 |
Stage详情
直方图显示了跨Worker的多个任务的调度时间和CPU时间随时间的分布和变化。
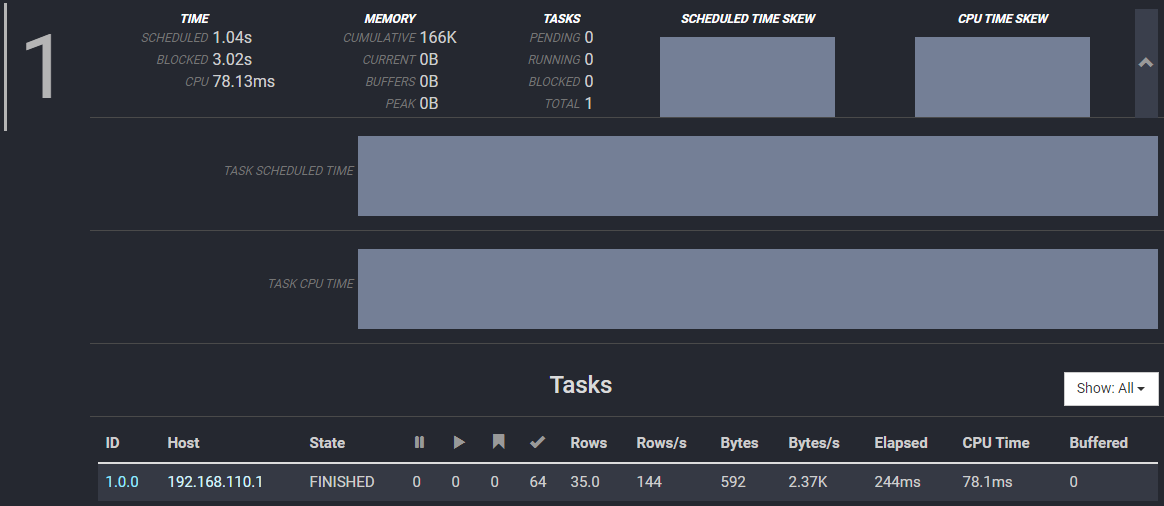
| 字段 | 描述 |
|---|---|
| ID | 任务标识符,格式为stage-id.task-id。 |
| Host | 运行任务的工作节点的IP地址。 |
| State | 任务的状态,可以是PENDING,RUNNING或BLOCKED。 |
| Pending Splits | 任务正等待Split的数量。 该值随着任务的运行而变化,并在任务完成时显示为0。 |
| Running Splits | 任务正运行Split的数量。 该值随着任务的运行而变化,并在任务完成时显示为0。 |
| Blocked Splits | 任务被阻止Split的数量。 该值随着任务的运行而变化,并在任务完成时显示为0。 |
| Completed Splits | 任务已完成Split的数量。 该值随着任务的运行而变化,并且等于任务完成时运行的拆分总数。 |
| Rows | 任务中处理的行数。 该值随着任务运行而增加。 |
| Rows/s | 任务中每秒处理的行数。 |
| Bytes | 任务中处理的字节数。 该值随着任务运行而增加。 |
| Bytes/s | 任务中每秒处理的字节数。 |
| Elapsed | 调度任务的已用Wall Time总数。 |
| CPU Time | 调度任务的CPU时间总量。 |
| Buffered | 当前缓冲数据量,等待处理。 |
5.3.2 Live Plan
在查询执行期间,实时查看Presto集群执行的查询处理。
5.3.3 Stage Performance
提供查询处理完成后Stage性能的详细可视化。
5.3.4 Splits
Split视图显示了在查询执行期间创建和处理Split的时间线。
5.3.5 Json
以JSON格式提供所有查询详细信息,该信息基于为其检索的快照进行更新。
参考:
Presto 官方文档
Presto集群部署和配置
Presto实现原理和美团的使用实践
Presto: SQL on Everything
Presto: SQL on Everything(全文翻译)
Presto 权威指南
最后
以上就是动听花瓣最近收集整理的关于Presto 官方版 单机和集群安装与使用的全部内容,更多相关Presto内容请搜索靠谱客的其他文章。






![[7]-Presto Security](https://www.shuijiaxian.com/files_image/reation/bcimg4.png)

发表评论 取消回复