1.加载机制概述
dubbo良好的扩展性与两个方面密不可分:
1.整个框架中针对不同场景,恰到好处的使用了各种设计模式
2.加载机制,基于Dubbo SPI加载机制,让整个框架的接口和具体实现完全解耦,从而奠定了整个框架良好可扩展的基础。
提起SPI机制肯定绕不过去 JAVA自带的SPI。
JAVA SPI使用了策略模式,一个接口多种实现。我们只声明接口,具体的实现并不在程序中直接确定,而是由程序外的配置掌控,用于具体实现的装配。
(1)声明接口
package com.org.wwls.api;
public interface Developer {
public void develop();
}
(2)在MATE-INF/services/目录下,创建一个以接口全路径命名的文件,
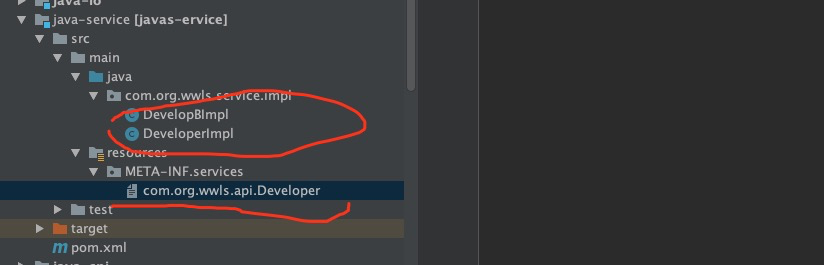
文件内容:
com.org.wwls.service.impl.DeveloperImpl com.org.wwls.service.impl.DevelopBImpl
测试类:
package com.org.wwls.spi;
import com.org.wwls.api.Developer;
import java.util.ServiceLoader;
public class SPITest {
public static void main(String[] args) {
ServiceLoader<Developer> serviceLoader =ServiceLoader.load(Developer.class);
serviceLoader.forEach(c->{
c.develop();
});
System.out.println("SPI 执行完毕");
}
既然JDK自带的有SPI,为什么还要dubbo扩展自己的SPI呢?
与JAVA SPI相比,dubbo SPI做了一些改进和优化官网有这么一段话
1.JDK标准的SPI会一次性的实例化扩展点所有实现,如果有扩展实现则初始化很耗时,如果没有用也得加载,则浪费资源。
2.如果扩展点加载失败,则连扩展点的名字都获取不了。
3.增加了堆扩展 Ioc 和AOP的支持,一个扩展可以直接setter注入其他扩展。
Dubbo SPI配置
| 名称 | 描述 |
| SPI配置文件路径 | META-INF/services/ 、META-INF/dubbo、META-INF/dubbo/internal |
| SPI配置文件名称 | 全路径类名 |
| 文件内容格式 | key=value方式,多个用换行分割 |
1.2 扩展点的分类与缓存
Dubbo SPI可以分为 Class缓存、实例缓存。这两种缓存又能根据扩展类的种类分为普通扩展类、包装扩展类(Wrap类)、自适应扩展类(Adaptive)
2.扩展点注解
2.1 扩展点注解:@SPI
@SPI注解可以用在类,接口和枚举类上,Dubbo框架中都是使用在接口上。主要作用就是标记这个接口是一个Dubbo SPI接口,即是一个扩展点,可以有多个不同的内置或用户定义的实现。运行时需要通过配置找到具体实现类。
代码如下:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface SPI {
/**
* default extension name
*/
String value() default "";
}
使用案例:
@SPI("fixed")
public interface ThreadPool {
/**
* Thread pool
*
* @param url URL contains thread parameter
* @return thread pool
*/
@Adaptive({THREADPOOL_KEY})
Executor getExecutor(URL url);
}
2.2扩展点自适应注解:@Adaptive
@Adaptive注解可以标记在类、接口、枚举和方法上,但是在整个Dubbo框架中,只有几个地方使用在类级别上
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface Adaptive {
String[] value() default {};
}
注意注解参数是数组
例如:
@Adaptive public class AdaptiveExtensionFactory implements ExtensionFactory 和
@Adaptive
public class AdaptiveCompiler implements Compiler
,其他的都标注在方法上。如果标注在接口的方法上,即方法级别的注解,则可以通过参数动态获取实现类。方法级别的注解在第一次getExtension时,会自动生成和编译
一个动态的Adaptive类,从而达到动态实现类的效果。
为啥有些实现类上会标注@Adaptive 呢?
放在实现类上主要是为了直接固定对应的实现而不需要动态生成代码实现。
在代码中会缓存 两个与@Adaptive 有关的对象,一个缓存在cachedAdaptiveClass中,即Adaptive具体实现类的Class类型;另外一个缓存在cachedAdaptiveInstance中,即Class的具体实例化对象。
在扩展点初始化时候,如果发现实现类有@Adaptive注解,则直接赋值给cachedAdaptiveClass,后续实例化的时候,就不会再动态生成代码,直接实例化并缓存到cachedAdaptiveInstance中。
如果注解在接口方法上,则会根据参数,动态获得扩展类的实现,会生成Adaptive类,再缓存到cachedAdaptiveInstance中。
2.3扩展点自动激活注解
@Activate可以标注在类、接口、枚举类、和方法上。主要使用在有多个扩展点实现、需要根据不同条件被激活的场景中,如Filter㔿多个同时激活,因为每个Filter实现的是不同的功能。
@Activate 可以传入以下参数:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
@Deprecated
public @interface Activate {
/***URL中的分组如果匹配则激活,可以设置多个*/
String[] group() default {};
/**查找URL中如果包含该key值,则会激活*/
String[] value() default {};
@Deprecated
String[] before() default {};
@Deprecated
String[] after() default {};
/***整形,直接的排序信息*/
int order() default 0;
}
3.ExensionLoader的工作原理
且看下回分解
4.扩展点动态编译的实现原理
且看下回分解
参考文献《dubbo官网介绍》 《深入理解Apache Dubbo与实战》
最后
以上就是苹果毛豆最近收集整理的关于【001】dubbo SPI扩展点加载机制1.加载机制概述2.扩展点注解3.ExensionLoader的工作原理4.扩展点动态编译的实现原理的全部内容,更多相关【001】dubbo内容请搜索靠谱客的其他文章。








发表评论 取消回复