一.出现问题
在前一段时间日常环境很不稳定,前端调用mtop接口会出网络异常或服务不存在的异常。查询了服务器上的HSF会有偶尔挂死的情况,服务器上的接口服务都不可用。于是我们对服务器上的状况进行了排查。
二.排查问题的过程
在这次的问题排查主要是围绕JVM的内存使用情况,生成对象分布情况以及GC情况来讨论的。中间有一些细节一开始存有疑问,迷雾的排除不算太顺利。首先要感谢下基础架构事业群的右席,井桐,梁希,坤谷 ,蚂蚁的寒泉子,中间技术部的思邪,望淘以及我们部的行默,今为,张霸,常晓师兄的一起讨论与问题排查的推动。为了写一篇比较干货,看了之后能立即上手开始排查一些类似问题的论文,我废话不多说,写一篇忽略掉曲折过程,直达终点的BLOG,有不当之处欢迎看官指出 :)
三.排查问题的步骤
1.查看服务器大概情况
首先最容易想到的是top命令,它能够实时显示系统中各个进程的资源占用状况,经常用来监控linux的系统状况,比如cpu、内存的使用。我上下当时截图的状况
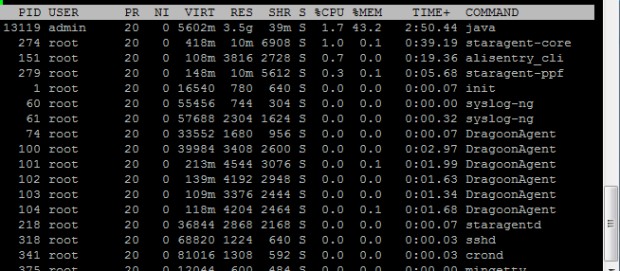
由于前段时间服务不可用了,于是我们重启了ali-tomcat服务,发现Java进程重启之后最显著的问题就是占用内存挺多,虚拟内存总量占了5.5G+,43.2%。
2.查看Java进程突然不服务的原因
先查看过了一些业务日志与关系紧密的中间件,组件(比如HSF,Mtop等)的日志,无明显历史错误。于是我们在考虑Java进程突然不可用的原因。这里推荐一个很实用的命令:dmesg。dmesg可以用来查看开机之后的系统日志,其中可以捕捉到一些系统资源与进程的变化信息。dmesg |grep -E ‘kill|oom|out of memory’ 来搜索内存溢出的信息挺实用。我们这次就是用来这个命令查出来是内存溢出的原因。上图
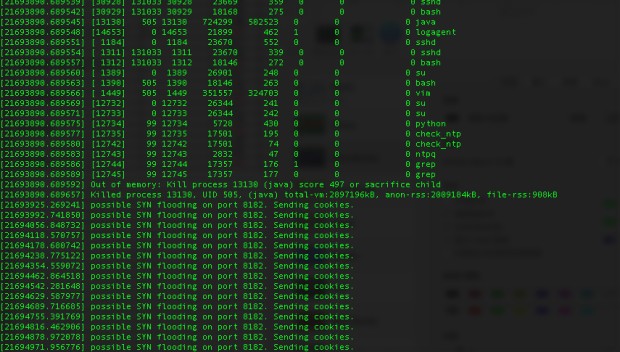
由图可见,内存不足,Java进程被杀死的案发现场清晰可见。
3. 查看JVM状态
关于OOM出现的情况,一般可以猜想是内存泄露,或者是加载了过多class或者创建了过多对象,给JVM分配的内存不够导致。于是我们用一下常用的JDK自带工具来观察下JVM的状态:
1. ps -aux|grep java 当服务重新部署后,可以找出当前Java进程的PID
2. jstat -gcutil pid interval 用于查看当前GC的状态,它对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控。
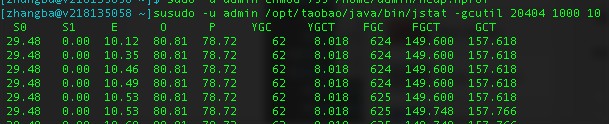
图中可见,Full GC次数远大于Young GC 。由此可见可能是老年代空间大小不足,导致应用需要频繁Full GC,因为Full GC要将新生代、旧生代、持久代一起进行GC。
3. jmap -histo:live pid 可用统计存活对象的分布情况,从高到低查看占据内存最多的对象。上图
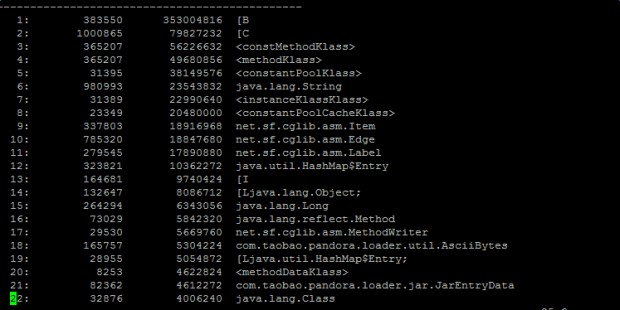
由图上看,Java进程top时发现占用虚拟内存5.5G,而byte[]数组占用了3G。很有可能它就是凶手!
4.Java dump分析问题
Java dump,也叫做 Thread dump,是 JVM 故障诊断中最重要的转储文件之一。JVM 的许多问题都可以使用这个文件进行诊断,其中比较典型的包括线程阻塞,CPU 使用率过高,JVM Crash,堆内存不足,和类装载等问题。
1. jmap -dump:format=b,file=文件名 [pid] 利用Jmap dump,但是执行时出现意外了,如图所示
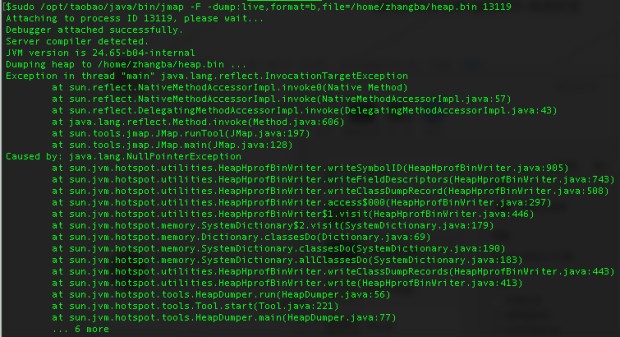
在基础架构事业群同学的提示下,发现这是JDK 7的Jmap 的Bug,stack over flow 中有这个问题的回答文档链接
2. gcore 出现了这个问题后,再其他同学的提醒下,我们尝试了gcore。在排查问题的时候,对于保留现场信息的操作,可以用gcore [pid]直接保留内存信息,这个的执行速度会比jmap -dump快不少,之后可以再用jmap/jstack等从core dump文件里提取相应的信息。
- a 先生成core dump 主要命令有
sudo gdb -q --pid //启动gdb命令
(gdb) generate-core-file //这里调用命令生成gcore的dump文件
(gdb) gcore /tmp/jvm.core //dump出core文件
(gdb) detach
//detach是用来断开与jvm的连接的
(gdb) quit
//退出b 把core文件转换成hprof
jmap -dump:format=b,file=heap.hprof /opt/taobao/java/bin /tmp/jvm.core
这样就可以使用可视化的内存分析工具来一探究竟了c 使用性能分析工具对hprof进行分析
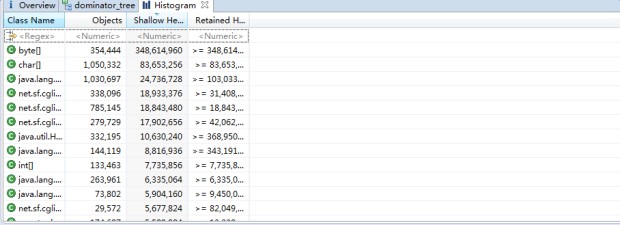
这里主要使用了2个工具:一个是 MAT,一个基于Eclipse的内存分析工具,它可以快速的计算出在内存中对象的占用大小,看看是谁阻止了垃圾收集器的回收工作,并可以通过报表直观的查看到可能造成这种结果的对象。第二个是zprofile(阿里内部工具)。直接上图
MAT上的图
zprofile上的图
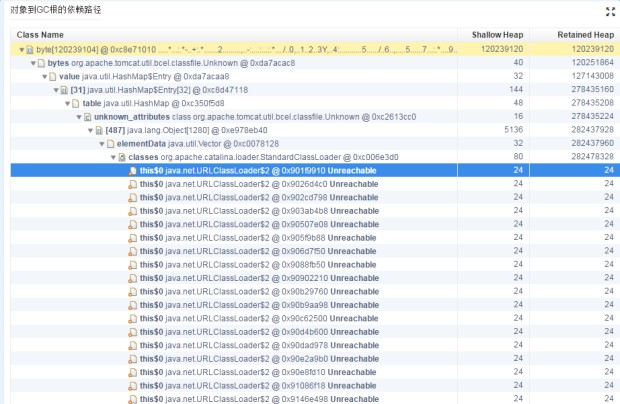
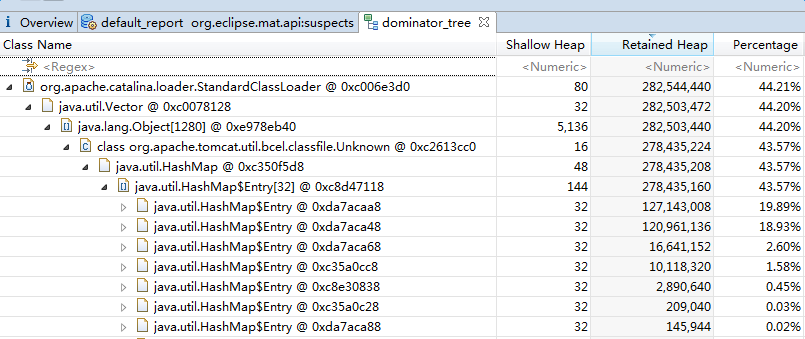
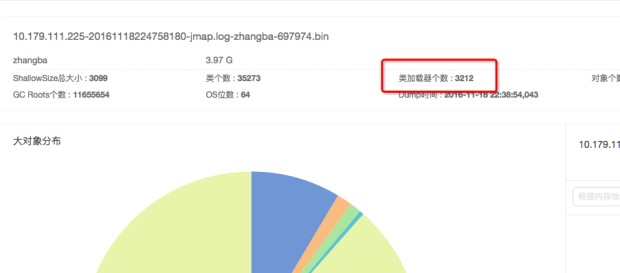
通过图中我们可以发现ali-tomcat的StandardClassLoader类加载器的Retained Size(当前对象大小+当前对象可直接或间接引用到的对象的大小总和)占用了内存的44.21%。并且类加载器的个数高达3212个。于是我们推测可能是ali-tomcat的StandardClassLoader的类加载时出了问题,导致引入的byte[]数组占用的堆大小过多,而Full GC回收不过来,导致了OOM。
5.通过tomcat查明真相
因为怀疑问题出现在StandardClassLoader,于是我们去查看了tomcat的日志,在Catalina引擎日志文件catalina.log找到了一些异样的报警和报错:
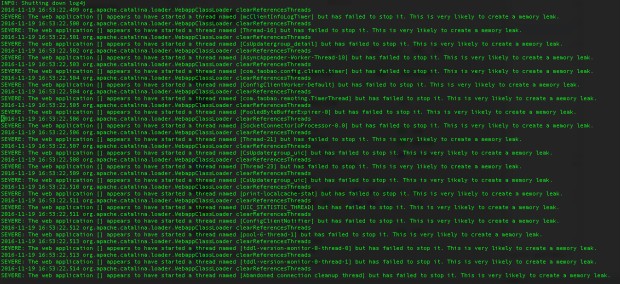
上面提示加载类时可能会有内存泄露。然后在tomcat的类加载过程中还出现了加载javassist.jar包出现了EOFException。后来拉进了中间件部门ali-tomcat的开发人员一看,原来是我们那个版本的ali-tomcat的会出现这样的问题,要升级新的版本问题就能解决。
最后
以上就是冷傲小鸭子最近收集整理的关于一次线上OOM过程的排查的全部内容,更多相关一次线上OOM过程内容请搜索靠谱客的其他文章。

![GrapeCity Documents for PDF[GcPDF]](https://www.shuijiaxian.com/files_image/reation/bcimg13.png)






发表评论 取消回复