
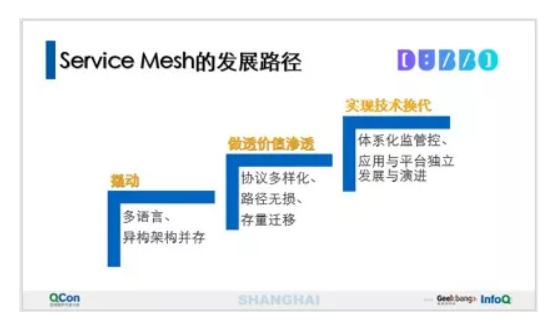
本文作者至简曾在 2018 QCon 上海站以《Service Mesh 的本质、价值和应用探索》为题做了一次分享,其中谈到了 Dubbo Mesh 的整体发展思路是“借力开源、反哺开源”,也讲到了 Service Mesh 在阿里巴巴的发路径将经历以下三大阶段:
- 撬动
- 做透价值渗透
- 实现技术换代
Dubbo Mesh 在闲鱼生产环境的落地,分享的是以多语言为撬动点的阶段性总结。
文章首发于「QCon」,阿里巴巴中间件授权转载。
闲鱼场景的特点
闲鱼采用的编程语言是 Dart,思路是通过 Flutter 和 Dart 实现 iOS、Android 两个客户端以及 Dart 服务端,以“三端一体”的思路去探索多端融合的高效软件开发模式。更多细节请参考作者同事陈新新在 2018 QCon 上海站的主题分享《Flutter & Dart 三端一体化开发》。本文将关注三端中的 Dart 服务端上运用 Dubbo Mesh 去解耦 Dubbo RPC 框架的初步实践成果。
Dart 服务端是一个服务调用胶水层,收到来自接入网关发来的 HTTP 请求后,通过 C++ SDK 调用集团广泛提供的 Dubbo 服务完成业务逻辑处理后返回结果。然而,C++ SDK 的功能与 Java 的存在一定的差距,比如缺失限流降级等对于保障大促稳定性很重要的功能。从长远发展的角度,闲鱼团队希望通过 Dubbo Mesh 能屏蔽或简化不同技术栈使用中间件(比如,RPC、限流降级、监控、配置管理等)的复杂性。这一诉求的由来,是闲鱼团队通过几个月的实践,发现在 Dart 语言中通过 C++ SDK 逐个接入不同中间件存在定制和维护成本高的问题。值得说明,所谓的“定制”是因为 C++ SDK 的能力弱于 Java SDK 而要做补齐所致。
Dart 服务端自身的业务逻辑很轻且在一些场景下需要调用 20 多次 Dubbo 服务,这对于 Dubbo Mesh 的技术挑战会显得更大。在 Dubbo Mesh 还没在生产环境落地过而缺乏第一手数据的情形下,其性能是否完全满足业务的要求是大家普遍关心的。
架构与实现
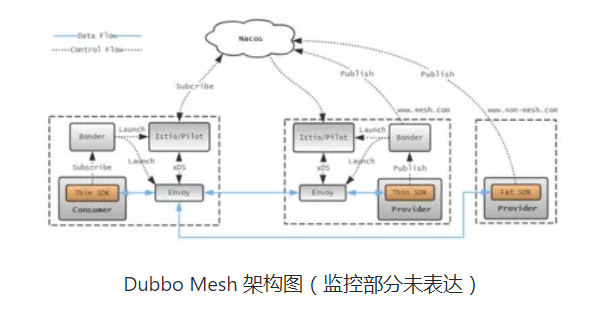
图中的虚框代表了一个Pouch容器(也可以是一台物理机或虚拟机)。左边两个容器部署了 Dubbo Mesh,剩下最右边的则没有。目前 Dubbo Mesh 主要包含 Bonder、Pilot、Envoy 三个进程,以及被轻量化的 Thin SDK。其中:
- Envoy 承担了数据平面的角色,所有 mesh 流量将由它完成服务发现与路由而中转。Envoy 由 Lyft 初创且目前成为了 CNCF 的毕业项目,我们在之上增加了对 Dubbo 协议的支持,并将之反哺到了开源社区(还有不少代码在等待社区 review 通过后才能进到 GitHub 的代码仓库)。
- Pilot 和 Bonder 共同承担控制平面的角色,实现服务注册、进程拉起与保活、集群信息和配置推送等功能。Pilot 进程的代码源于开源 Istio 的 pilot-discovery 组件,我们针对阿里巴巴集团环境做了一定的改造(比如,与Nacos进行适配去访问服务注册中心),且采用下沉到应用机器的方式进行部署,这一点与开源的集群化部署很不一样。背后的思考是,Pilot 的集群化部署对于大规模集群信息的同步是非常大的一个挑战,今天开源的 Istio 并不具备这一能力,未来需要 Nacos 团队对之进行增强,在没有完全准备好前通过下沉部署的方式能加速 Service Mesh 的探索历程。
- Thin SDK 是 Fat SDK 经过裁剪后只保留了对 Dubbo 协议进行编解码的能力。为了容灾,当 Thin SDK 位于 Consumer 侧时增加了一条容灾通道,细节将在文后做进一步展开。
数据链路全部采用单条 TCP 长连接,这一点与非 mesh 场景是一致的。Pilot 与 Envoy 两进程间采用的是 gRPC/xDS 协议进行通讯。
图中同时示例了 mesh 下的 Consumer 能同时调用 mesh 下的服务(图中以 www.mesh.com 域名做示例)和非 mesh 下的服务(图中以 www.non-mesh.com 域名做示例)。闲鱼落地的场景为了避免对 20 多个依赖服务进行改造,流量走的是 mesh 下的 Consumer 调用非 mesh 下的 Provider 这一形式,读者可以理解为图中最左边的容器部署的是 Dart 服务端,它将调用图中最右边容器所提供的服务去实现业务逻辑。
容灾
从 Dubbo Mesh 下的 Provider 角度,由于通常是集群化部署的,当一个 Provider 出现问题(无论是 mesh 组件引起的,还是 Provider 自身导致的)而使服务无法调通时,Consumer 侧的 Envoy 所实现的重试机制会将服务请求转发到其他 Provider。换句话说,集群化部署的 Provider 天然具备一定的容灾能力,在 mesh 场景下无需特别处理。
站在 Dubbo Mesh 的 Consumer 立场,如果完全依赖 mesh 链路去调用 Provider,当 mesh 链路出现问题时则会导致所有服务都调不通,这往往会引发业务可用性问题。为此,Thin SDK 中提供了一个直连 Provider 的机制,只不过实现方式比 Fat SDK 轻量了许多。Thin SDK 会定期从 Envoy 的 Admin 接口获取所依赖服务的 Provider 的 IP 列表,以备检测到 mesh 链路存在问题时用于直连。比如,针对每一个依赖的服务获取最多 10 个 Provider 的 IP 地址,当 mesh 链路不通时以 round robin 算法向这些 Provider 直接发起调用。由于容灾是针对 mesh 链路的短暂失败而准备的,所以 IP 地址的多少并不是一个非常关键的点。Thin SDK 检测 mesh 链路的异常大致有如下场景:
- 与 Envoy 的长连接出现中断,这是 Envoy 发生 crash 所致。
- 所发起的服务调用收到 No Route Found、No Healthy Upstream 等错误响应。
优化
在闲鱼落地 Dubbo Mesh 的初期我们走了一个“弯路”。
具体说来,最开始为了快速落地而采用了 Dubbo over HTTP 1.1/2 的模式,也即,将 Dubbo 协议封装在 HTTP 1.1/2 的消息体中完成服务调用。这一方案虽然能很好地享受 Envoy 已完整支持 HTTP 1.1/2 协议而带来的开发工作量少的好处,但性能测试表明其资源开销并不符合大家的预期。体现于,不仅 Consumer 侧使用 mesh 后带来更高的 CPU 开销,Provider 侧也因为要提供通过 HTTP 1.1/2 进行调用的能力而导致多出 20% 的 CPU 开销且存在改造工作。最终,我们回到让 Envoy 原生支持 Dubbo 协议的道路上来。
Envoy 支持 Dubbo 协议经历了两大阶段。第一个阶段 Envoy 与上游的通讯并没有采用单条长连接,使得 Provider 的 CPU 开销因为多连接而存在不可忽视的递增。第二个阶段则完全采用单条长连接,通过多路复用的模式去除了前一阶段给 Provider 所带去的额外 CPU 开销。
Dubbo Mesh 在闲鱼预发环境上线进行性能与功能验证时,我们意外地发现,Istio 原生 Pilot 的实现会将全量集群信息都推送给处于 Consumer 侧的 Envoy(Provider 侧没有这一问题),导致 Pilot 自身的 CPU 开销过大,而频繁的全量集群信息推送也使得 Envoy 不时会出现 CPU 负荷毛刺并遭受没有必要的内存开销。为此,我们针对这一问题做了集群信息按需加载的重大改造,这一优化对于更大规模与范围下运用 Dubbo Mesh 具有非常重要的意义。优化的大致思路是:
- Thin SDK 提供一个 API 供 Consumer 的应用在初始化时调用,周知其所需调用的服务列表。
- Thin SDK 通过 HTTP API 将所依赖的服务列表告诉 Bonder,Bonder 将之保存到本地文件。
- Envoy 启动时读取 Bonder 所保存的服务列表文件,将之当作元信息转给 Pilot。
- Pilot 向 Nacos 只订阅服务列表中的集群信息更新消息且只将这些消息推送给 Envoy。
监控
可观测性(observability)是 Service Mesh 非常重要的内容,在服务调用链路上插入了 Envoy 的情形下,愈加需要通过更强的监控措施去治理其上的所有微服务。Dubbo Mesh 的监控方案并没有使用 Istio/Mixer 这样的设计,而是沿用了阿里巴巴集团内部的方式,即信息由各进程以日志的形式输出,然后通过日志采集程序将之送到指定的服务端进行后期加工并最终展示于控制台。目前 Dubbo Mesh 通过 EagleEye 去跟踪调用链,通过ARMS去展示其他的监控信息。
性能评估
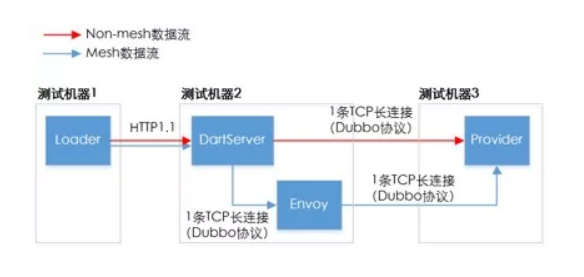
为了评估 Dubbo Mesh 的性能能否满足闲鱼业务的需要,我们设计了如下图所示的性能比对测试方案。
其中:
- 测试机器是阿里巴巴集团生产环境中的 3 台 4 核 8G 内存的 Pouch 容器。
- 蓝色方框代表的是进程。测试数据全部从部署了 DartServer 和 Envoy 两进程的测试机 2 上获得。
- 性能数据分别在非 mesh(图中红色数据流)和 mesh(图中蓝色数据流)两个场景下获得。显然,Mesh 场景下的服务流量多了 Envoy 进程所带来的一跳。
- DartServer 收到来自施压的 Loader 进程所发来的一个请求后,将发出 21 次到 Provider 进程的 RPC 调用。在评估 Dubbo Mesh 的性能时,这 21 次是串行发出的(下文列出的测试数据是在这一情形下收集的),实际闲鱼生产环境上线时考虑了进行并行发送去进一步降低整体调用时延(即便没有 mesh 时,闲鱼的业务也是这样实现的)。
- Provider 进程端并没有部署 Envoy 进程。这省去了初期引入 Dubbo Mesh 对 Provider 端的改造成本,降低了落地的工作量和难度。
设计测试方案时,我们与闲鱼的同学共创了如何回答打算运用 Dubbo Mesh 的业务方一定会问的问题,即“使用 Dubbo Mesh 后对 RT(Response Time)和 CPU 负荷的影响有多大”。背后的动机是,业务方希望通过 RT 这一指标去了解 Dubbo Mesh 对用户体验的影响,基于 CPU 负荷的增长去掌握运用新技术所引发的成本。
面对这一问题通常的回答是“在某某 QPS 下,RT 增加了 x%,CPU 负荷增加了 y%”,但这样的回答如果不进行具体测试是无法给出的(会出现“鸡和蛋的问题”)。因为每个业务的天然不同使得一个完整请求的 RT 会存在很大的差别(从几毫秒到几百毫秒),而实现业务逻辑所需的计算量又最终决定了机器的 CPU 负荷水平。基于此,我们设计的测试方案在于评估引入 Dubbo Mesh 后,每经过一跳 Envoy 所引入的 RT 和 CPU 增量。当这一数据出来后,业务方完全可以基于自己业务的现有数据去计算出引入 Dubbo Mesh 后的而掌握大致的影响情况。
显然,背后的逻辑假设是“Envoy 对于每个 Dubbo 服务调用的计算量是一样的”,事实也确实如此。
测试数据
以下是 Loader 发出的请求在并发度为 100 的情形下所采集的数据。
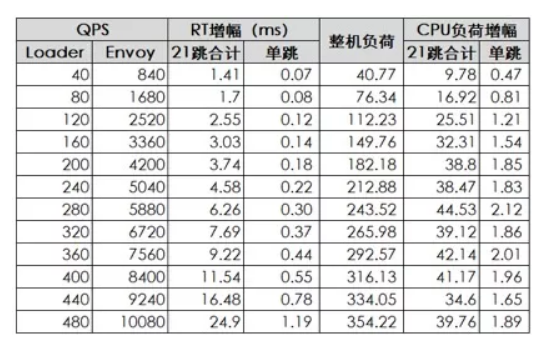
表中:
- Envoy 的 QPS 是 Loader 的 21 倍,原因在上面测试方案部分有交代。
- “单跳”的数据是从“21 跳合计”直接除以 21 所得,其严谨性值得商榷,但用于初步评估仍具参考价值(有数据比没有数据强)。
- “整机负荷”代表了在 mesh 场景下测试机器 2 上 DartServer 和 Envoy 两进程的 CPU 开销总和。测试表明,CPU 负荷高时 Envoy 带来的单跳 RT 增幅更大(比如表中 Loader 的 QPS 是 480 时)。给出整机负荷是为了提醒读者关注引入 mesh 前业务的正常单机水位,以便更为客观地评估运用 Dubbo Mesh 将带来的潜在影响。
- “CPU 负荷增幅”是指 CPU 增加的幅度。由于测试机是 4 核的,所以整机的 CPU 负荷是 400。
从表中数据来看,随着机器整体负荷的增加“CPU 负荷增幅”在高段存在波动,这与 RT 在高段的持续增大存在相关,从 RT 在整体测试中完全符合线性增长来看整体数据合理。当然, 后面值得深入研究数据背后的隐藏技术细节以便深入优化。
线上数据
Dubbo Mesh 正式生产环境上线后,我们通过对上线前后的某接口的 RT 数据进行了全天的比对,以便大致掌握 mesh 化后的影响。2019-01-14 该接口全面切成了走 Dubbo Mesh,我们取的是 2019-01-20 日的数据。
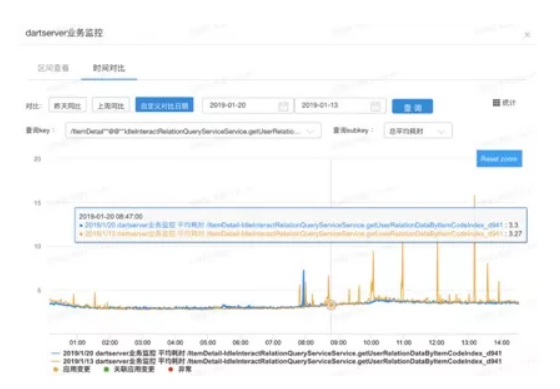
图中蓝色是 mesh 化后的 RT 表现(RT 均值 3.3),而橙色是 mesh 化前的 RT 表现(RT 均值 3.27,取的是 2019-01-13 的数据)。由于线上每天的环境都有所不同,要做绝对的比较并不可能。但通过上面的比较不难看出,mesh 化前后对于整体 RT 的影响相当的小。当整体 RT 小于 5 毫秒是如此,如果整体 RT 是几十、几百毫秒则影响就更小。
为了帮助更全面地看待业务流量的波动特点,下面分别列出了两天非 mesh(2019-01-06 和 2019-01-13)和两天 mesh(2019-01-20 和 2019-01-23)的比对数据。
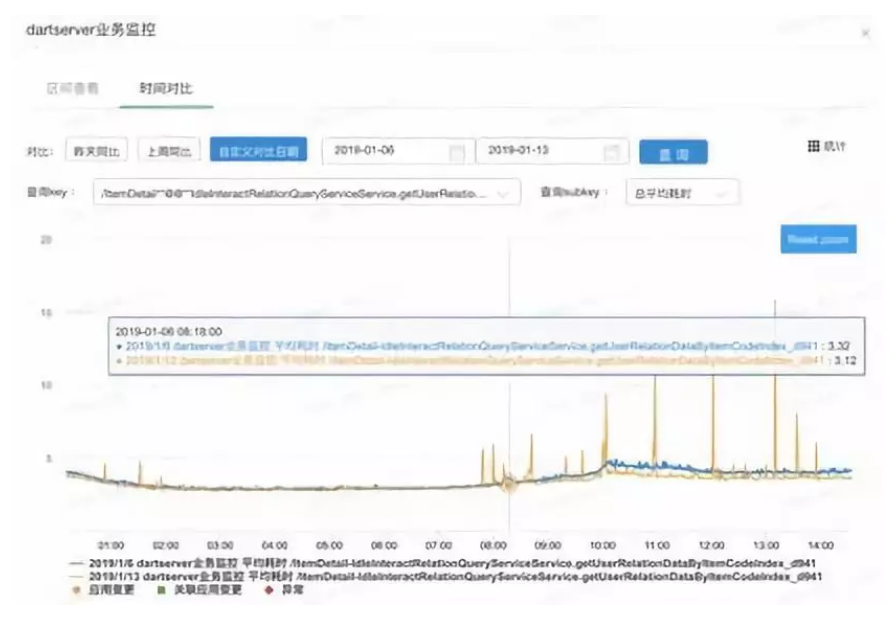
总之,生产环境上的数据表现与前面性能评估方案下所获得的测试数据能很好地吻合。
洞见
Dubbo Mesh 在闲鱼生产环境的落地实践让我们收获了如下的洞见:
- 服务发现的时效性是 Service Mesh 技术的首要关键。 以集群方式提供服务的情形下(这是分布式应用的常态),因为应用发布而导致集群中机器状态的变更如何及时准确地推送到数据平面是极具挑战的问题。对于阿里巴巴集团来说,这是 Nacos 团队致力于解决的问题。开源版本的 Istio 能否在生产环境中运用于大规模分布式应用也首先取决于这一能力。频繁的集群信息推送,将给控制平面和数据平面都带去负荷扰动,如何通过技术手段控制好扰动是需要特别关注的,对于数据平面来说编程语言的“确定性”(比如,没有 VM、没有 GC)在其中将起到不可忽视的作用。
- 数据平面的软件实现最大程度地减少内存分配与释放将显著地改善性能。有两大举措可以考虑:
- 逻辑与数据相分离。 以在 Envoy 中实现 Dubbo 协议为例,Envoy 每收到一个 RPC 请求都会动态地创建 fitler 去处理,一旦实现逻辑与数据相分离,filter 的创建对于每一个 worker 线程有且只有一次,通过这一个 filter 去处理所有的 RPC 请求。
- 使用内存池。 Envoy 的实现中基本没有用到内存池,如果采用内存池对分配出来的各种 bufffer 通过链表进行缓存,这将省去大量的内存分配与释放而改善性能。再则,对于处理一个 RPC 请求而多次分散分配的动作整合成集中一次性分配也是值得运用的优化技巧。
- 数据平面的 runtime profiling 是关键技术。 Service Mesh 虽然对业务代码没有侵入性,但对服务流量具有侵入性,如何在出现业务毛刺的情形下,快速地通过 runtime profiling 去发现问题或自证清白是非常值得关注的点。
心得
一年不到的探索旅程,让团队更加笃定“借力开源,反哺开源”的发展思路。随着对 Istio 和 Envoy 实现细节的更多掌握,团队很强列地感受到了走“站在巨人的肩膀上”发展的道路少走了很多弯路,除了快速跟进业界的发展步伐与思路,还将省下精力去做更有价值的事和创新。
此外,Istio 和 Envoy 两个开源项目的工程质量都很高,单元测试等质量保证手段是日常开发工作中的基础环节,而我们也完全采纳了这些实践。比如,内部搭建了 CI 环境、每次代码提交将自动触发单元测试、代码经过 code review 并完成单元测试才能入库、自动化性能测试等。
展望
在 2019 年接下来的日子,我们将着手:
- 与 Sentinel 团队形成合力,将 Sentinel 的能力纳入到 Dubbo Mesh 中补全对 HTTP 和 Dubbo 协议的限流、降级和熔断能力。
- 在阿里巴巴集团大范围 Kubernetes(Sigma 3.1)落地的背景下,与兄弟团队探索更加优雅的服务流量透明拦截技术方案。
- 迎合 Serverless 的技术发展趋势,深化通过 Dubbo Mesh 更好地轻量化应用,以及基于 Dubbo Mesh 对服务流量的天然敏感性去更好地实现 auto-scaling。
- 在产品的易用性和工程效率方面踏实进取。
未来,我们将及时与读者分享阿里巴巴集团在 Service Mesh 这一新技术领域的探索成果,也期待与大家有更多的互动交流。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
最后
以上就是想人陪纸鹤最近收集整理的关于Dubbo Mesh 在闲鱼生产环境中的落地实践的全部内容,更多相关Dubbo内容请搜索靠谱客的其他文章。








发表评论 取消回复