文章目录
- Hadoop高手之路7-Hadoop的新特性
- 一、Hadoop2.0以上新特性
- 二、Yarn资源管理框架
- 1. yarn体系结构
- 2. yarn的工作流程
- 三、HDFS的高可用HA
- 1. HDFS的高可用(HA)架构
- 2. 搭建Hadoop高可用HA集群
- 1) 规划集群节点
- 2) 环境准备
- 3) 配置HA集群
- (1) 修改core-site.xml
- (2) 修改hdfs-site.xml
- (3) 修改mapred-site.xml
- (4) 修改yarn-site.xml
- (5) workers
- (6) hadoop-env.sh
- 4) 分发配置文件到ha002和ha003
- 5) 启动HA集群
- (1) 启动各节点的zookeeper
- (2) 启动各节点监控NM的管理日志JournalNode
- (3) 在ha001上格式化NM,并将格式化后的目录复制到ha002中
- (4) 在ha001上格式化ZKFC
- (5) 在ha001上启动HDFS
- (6) 在node1上启动yarn
- 3. 测试HA,模拟node1宕机

Hadoop高手之路7-Hadoop的新特性
一、Hadoop2.0以上新特性
| 组件 | hadoop1.0局限和不足 | hadoop2.0及以上改进 |
|---|---|---|
| HDFS | NameNode存在单点故障 | 引入了高可用HA |
| MapReduce | JobTracker | Yarn |
二、Yarn资源管理框架
1. yarn体系结构
-
ResourceManager:是一个全局的资源管理器,负责整个yarn集群资源的监控、分配和管理工作
-
NodeManager:是每个节点上的资源和任务管理器
-
ApplicationMaster:负责协调来自RM的资源,把获得的资源分配给内部的各个任务,实现“二次分配”。还通过NM监控容器的执行和资源的使用情况。
2. yarn的工作流程
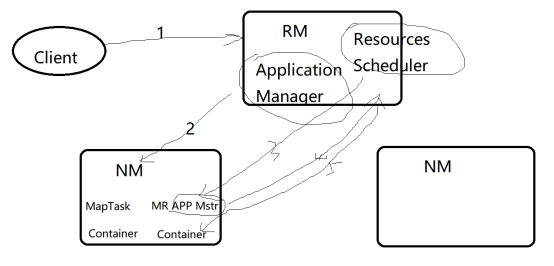
三、HDFS的高可用HA
1. HDFS的高可用(HA)架构
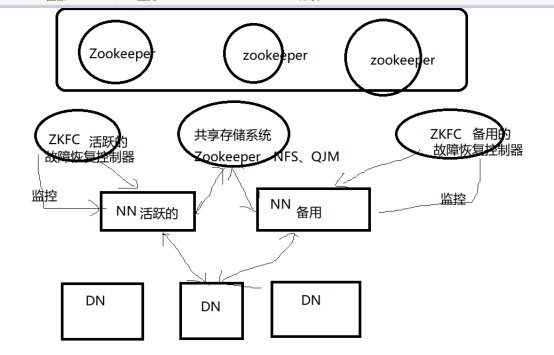
2. 搭建Hadoop高可用HA集群
1) 规划集群节点
| 服务器 | NN | DN | RM | NM | JournalManager管理日志 | Zookeeper | ZKFC |
|---|---|---|---|---|---|---|---|
| node1 | √ | √ | √ | √ | √ | √ | √ |
| node2 | √ | √ | √ | √ | √ | √ | |
| node3 | √ | √ | √ | √ |
2) 环境准备
首先搭建Hadoop集群,建议大家重新搭建,巩固前面所学的知识,也可以在原有的基础上,创建快照,如下所示:
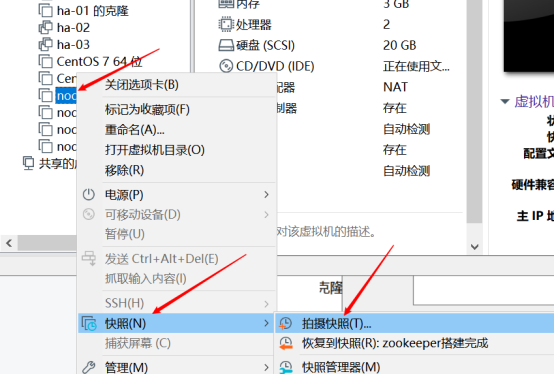
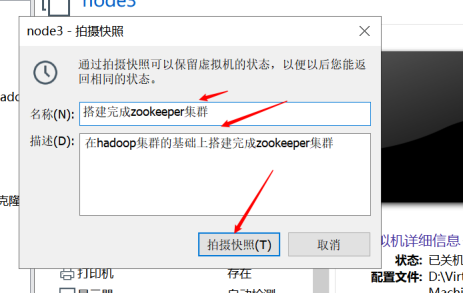
3) 配置HA集群
(1) 修改core-site.xml
<configuration>
<!--用于设置hadoop的文件系统-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!--用于设置hadoop的临时文件目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop/tmp</value>
</property>
<!--用于设置ZooKeeper-->
<property>
<name>ha.zookeeper.quorum</name>
<value>ha001:2181,ha002:2181,ha003:2181</value>
</property>
</configuration>
(2) 修改hdfs-site.xml
<configuration>
<!--用于设置hadoop的HDFS的副本的数目-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--用于设置hadoop的namenode的name数据的目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/export/data/hadoop/name</value>
</property>
<!--用于设置hadoop的datanode的data数据的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/export/data/hadoop/data</value>
</property>
<!--开启webHDFS-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定nameservice为ns1-->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!--指定ns1下面有两个namenode,nn1和nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
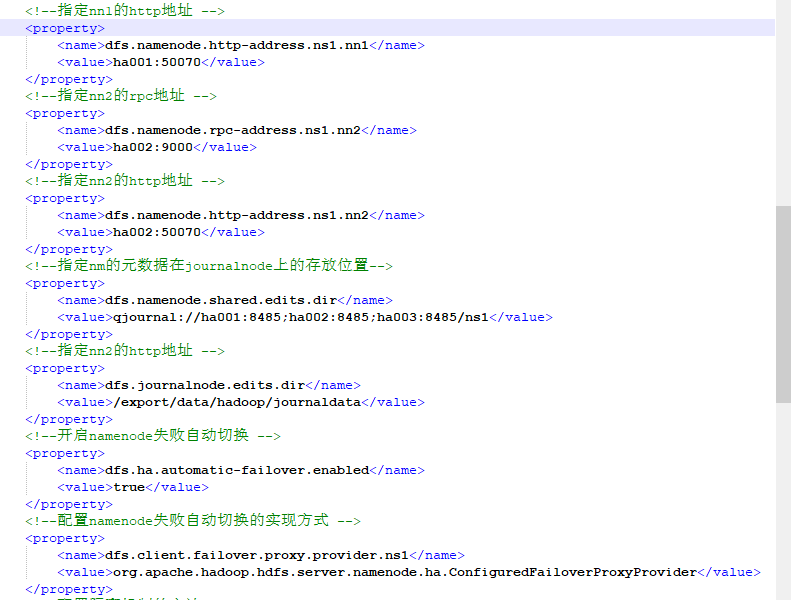
<!--指定nn1的rpc地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>ha001:9000</value>
</property>
<!--指定nn1的http地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>ha001:50070</value>
</property>
<!--指定nn2的rpc地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>ha002:9000</value>
</property>
<!--指定nn2的http地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>ha002:50070</value>
</property>
<!--指定nm的元数据在journalnode上的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ha001:8485;ha002:8485;ha003:8485/ns1</value>
</property>
<!--指定nn2的http地址 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/data/hadoop/journaldata</value>
</property>
<!--开启namenode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置namenode失败自动切换的实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
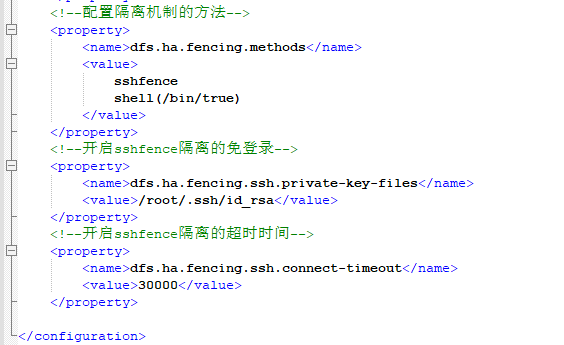
<!--配置隔离机制的方法-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!--开启sshfence隔离的免登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--开启sshfence隔离的超时时间-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>

(3) 修改mapred-site.xml
<configuration>
<!--用于设置hadoop的MapReduce的运行框架为yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.1.4/</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.1.4/</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.1.4/</value>
</property>
</configuration>

(4) 修改yarn-site.xml
<configuration>
<!--用于设置hadoop的yarn是否需要辅助shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--是否开启RM ha,默认是开启的-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>ha001</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>ha002</value>
</property>
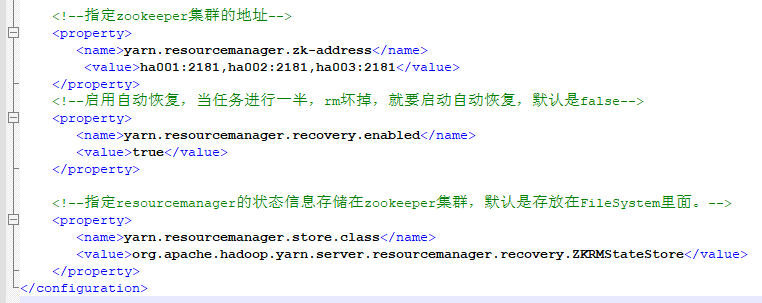
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>ha001:2181,ha002:2181,ha003:2181</value>
</property>
<!--启用自动恢复,当任务进行一半,rm坏掉,就要启动自动恢复,默认是false-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里面。-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>

(5) workers
ha001
ha002
ha003

(6) hadoop-env.sh

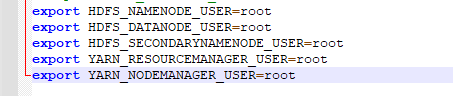
4) 分发配置文件到ha002和ha003


5) 启动HA集群
(1) 启动各节点的zookeeper
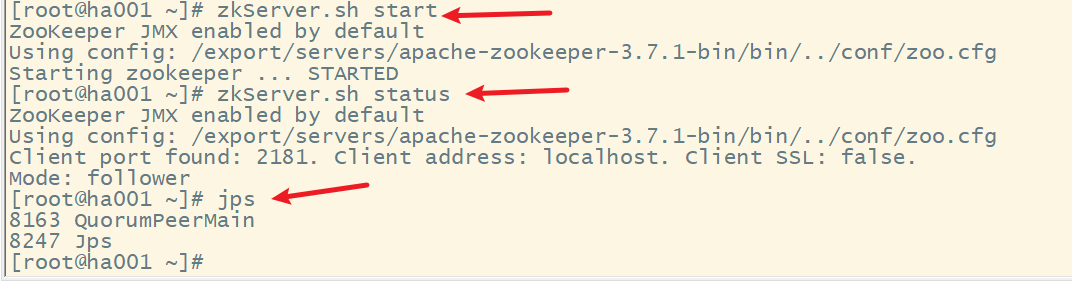
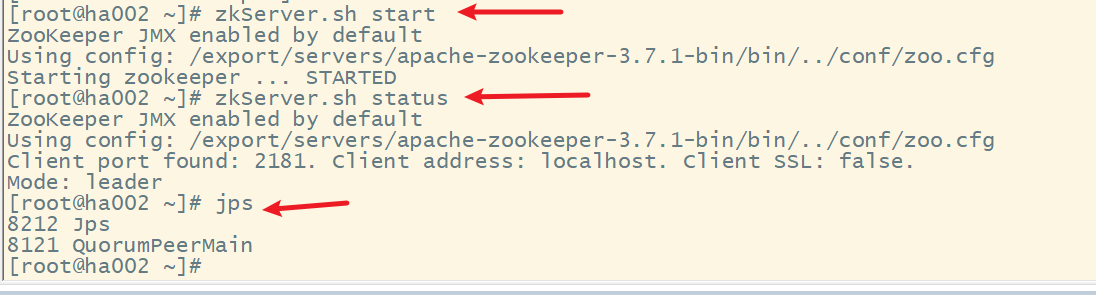
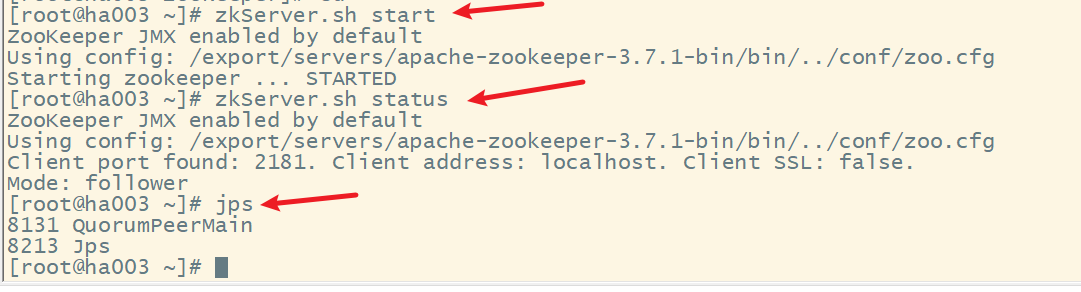
(2) 启动各节点监控NM的管理日志JournalNode
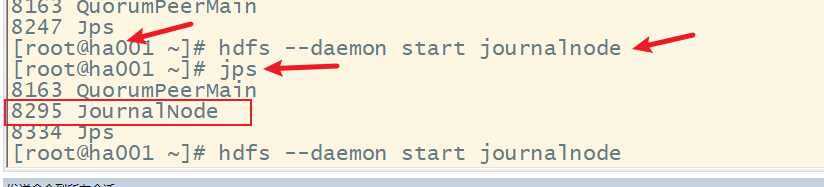
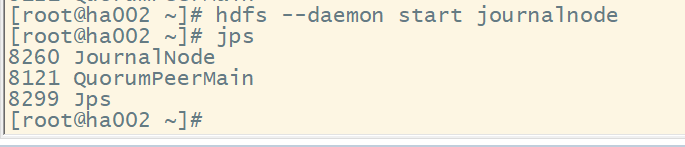
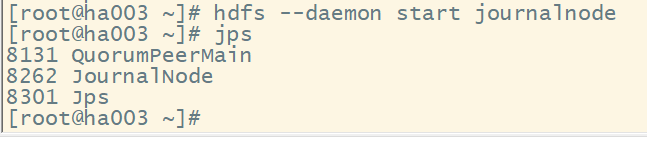
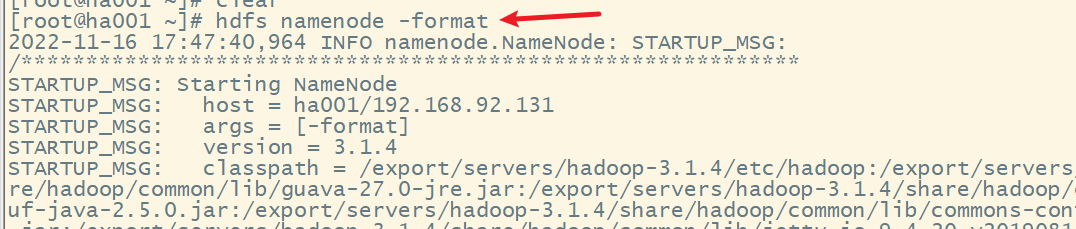
(3) 在ha001上格式化NM,并将格式化后的目录复制到ha002中
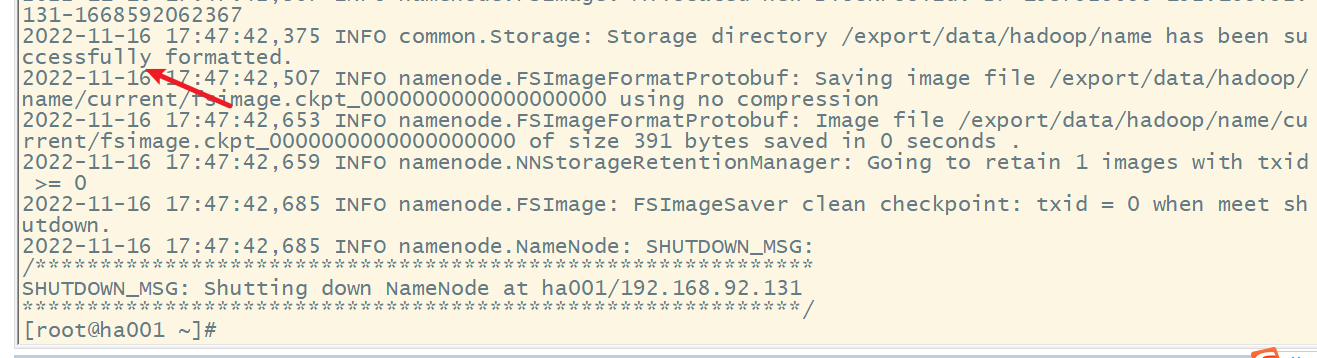
分发到ha002

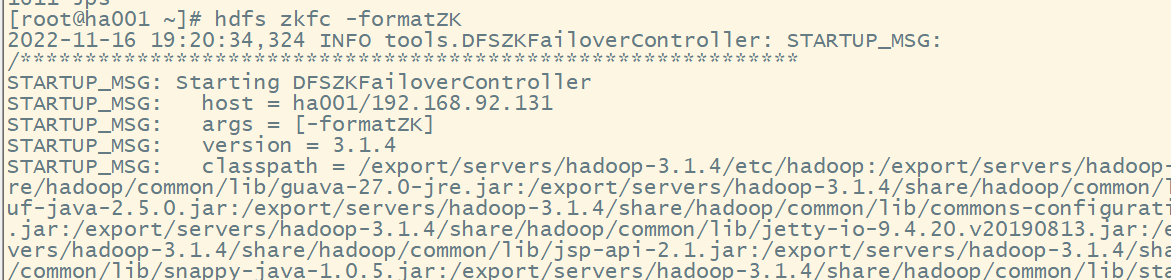
(4) 在ha001上格式化ZKFC
(5) 在ha001上启动HDFS
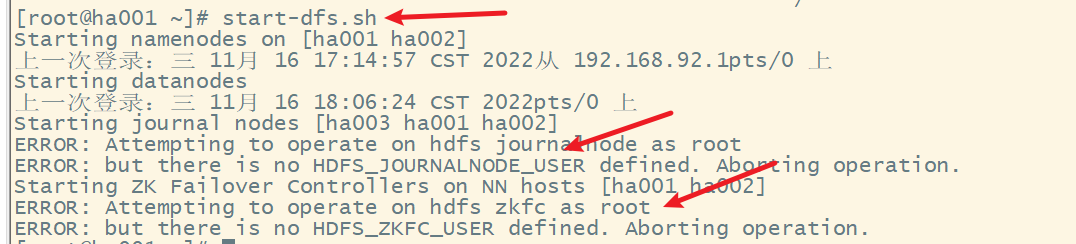
出现错误,修改hadoop-env.sh文件
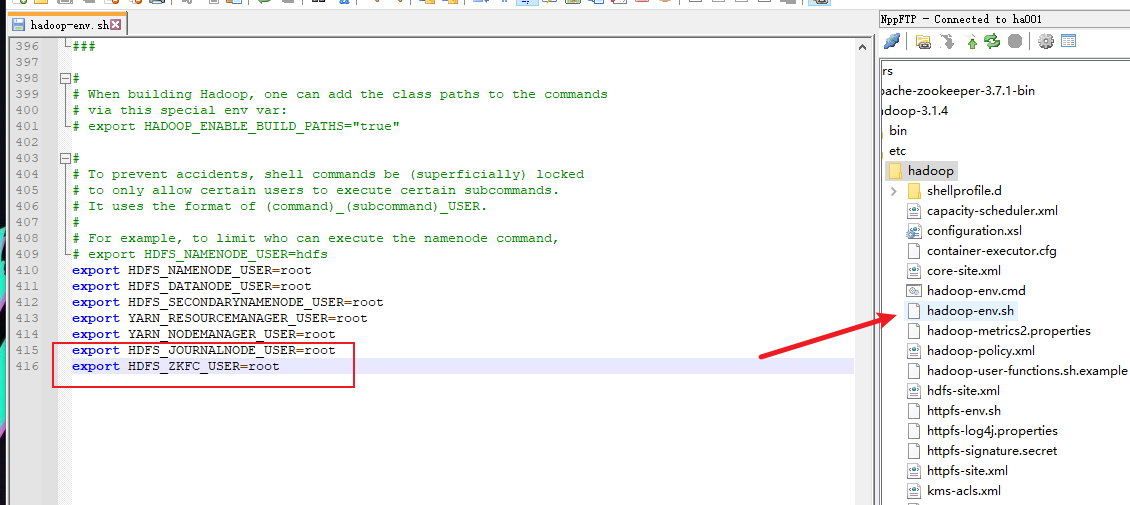
分发该文件到ha002上

停止hdfs,然后再重新启动hdfs
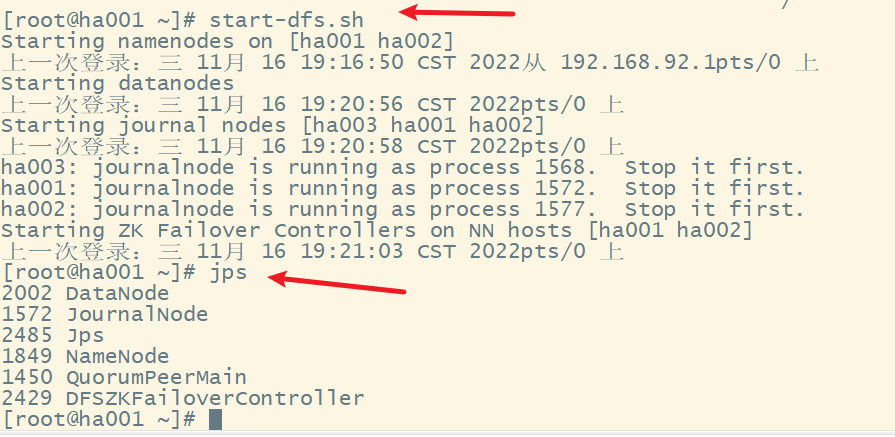
(6) 在node1上启动yarn
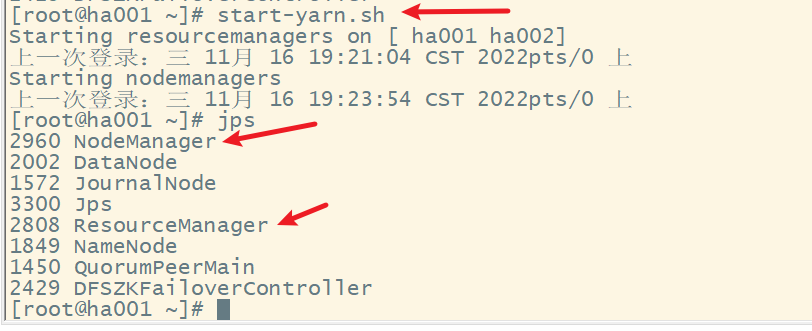
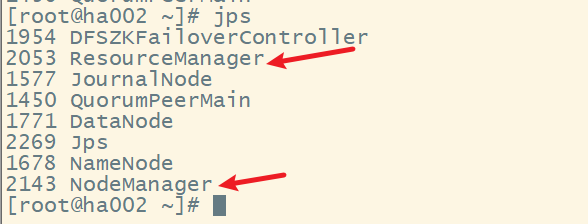
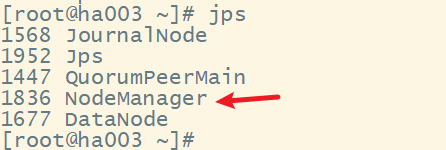
3. 测试HA,模拟node1宕机
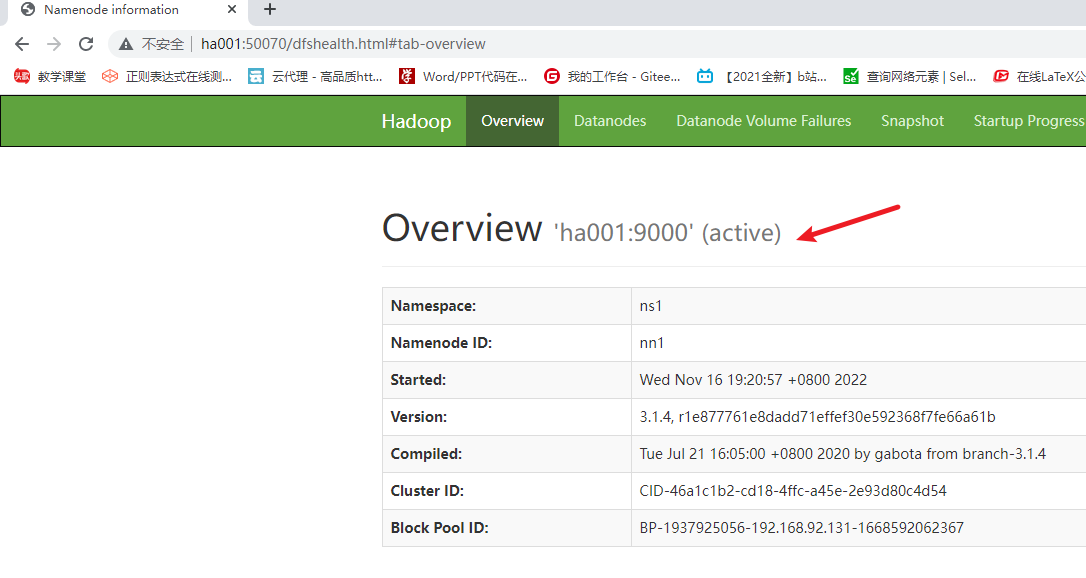
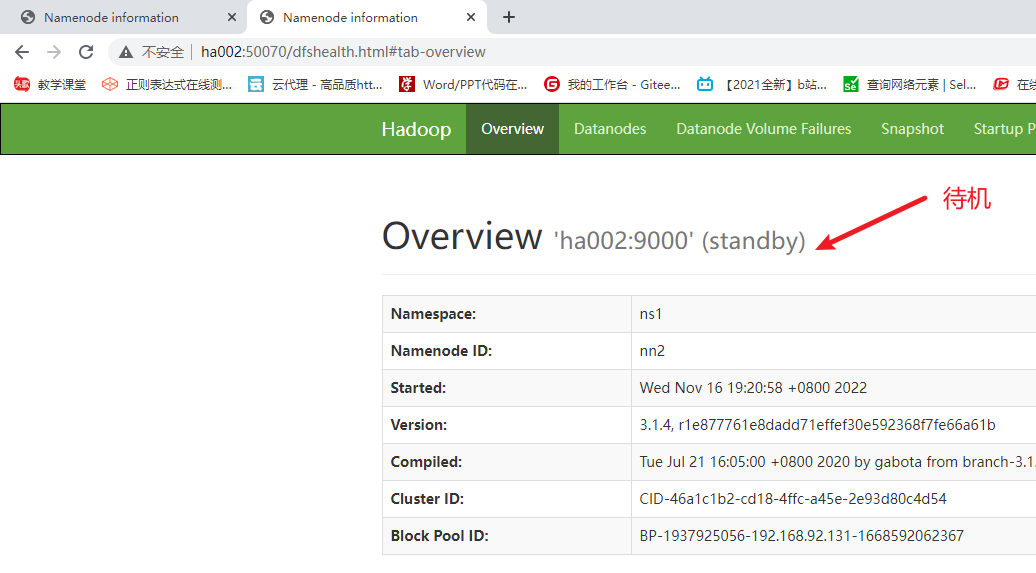
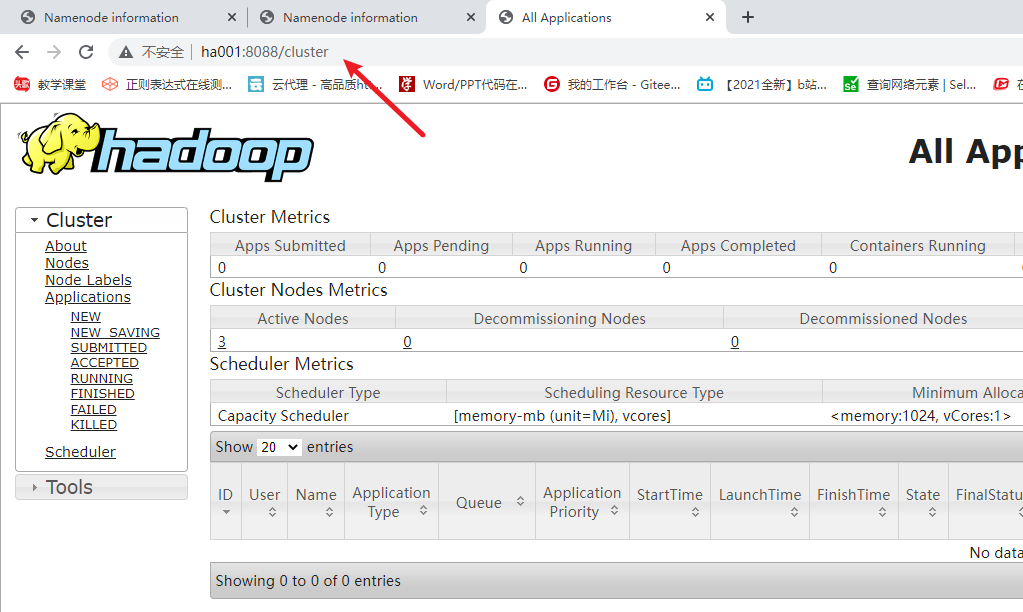
kill掉ha001的相关的进程
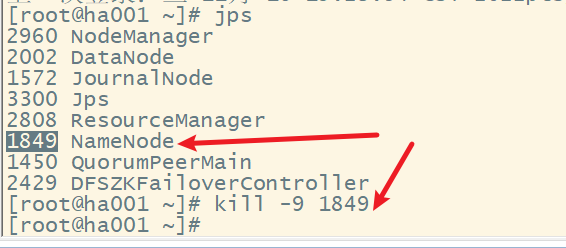
再查看
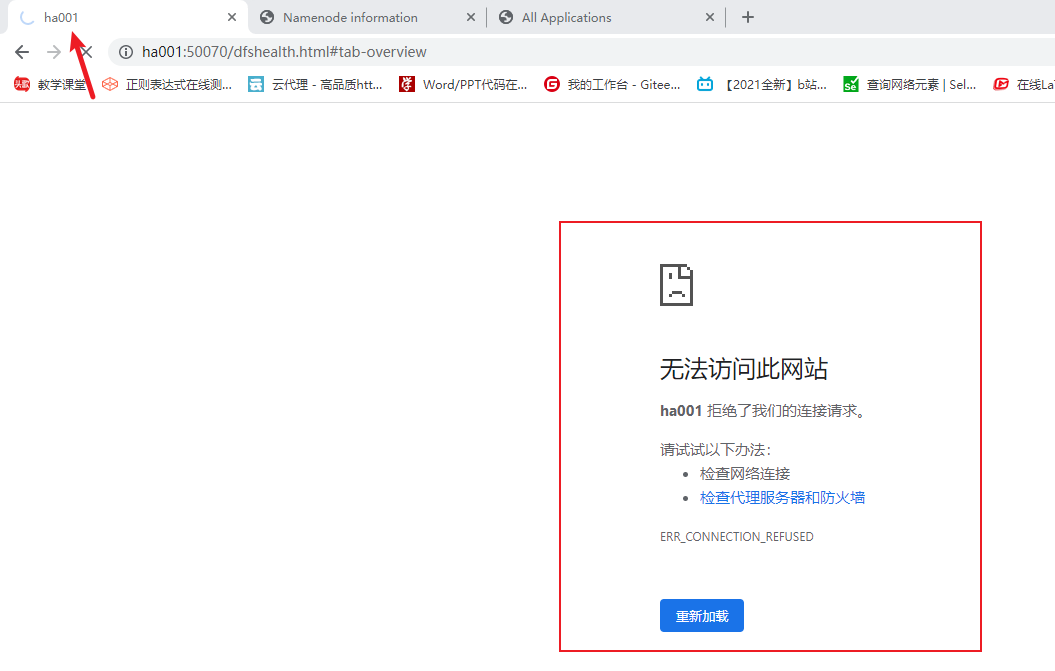
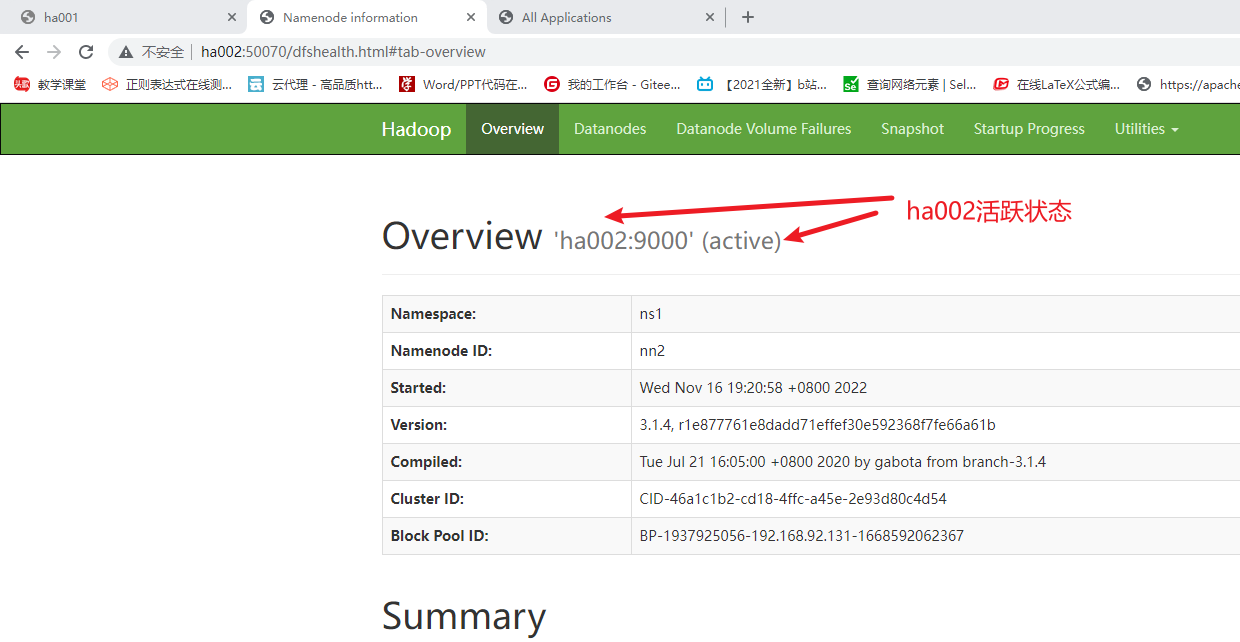
最后
以上就是合适未来最近收集整理的关于Hadoop高手之路7-Hadoop的新特性Hadoop高手之路7-Hadoop的新特性的全部内容,更多相关Hadoop高手之路7-Hadoop内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。


![[hbase] 重启后hmaster消失](https://www.shuijiaxian.com/files_image/reation/bcimg27.png)





发表评论 取消回复