基本概念
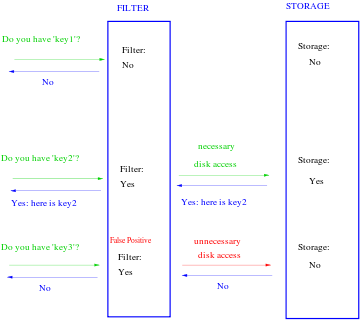
Bloom filter是一个空间高效(space- efficient)概率算法,被用于测试一个元素是否存在于一个集合中。
存在假阳性(false positive,表示实际是假但误辨为真的情况)匹配的可能,但不存在假阴性(false negatives)的可能。也就是说,一次查询返回的结果是可能在集合里或者绝对不在集合里。
最常用的操作是校验元素是否存在于集合中,也可以添加元素,但不可以删除元素。
同时,越多元素被加入到集合中,假阳性的概率就会越高。
Bloom filter一般应用在内存有限的索引场景,在可容忍的低误判的情况下,以极低的存储代价,实现去除绝大部分不必要的查询的便利。
定义
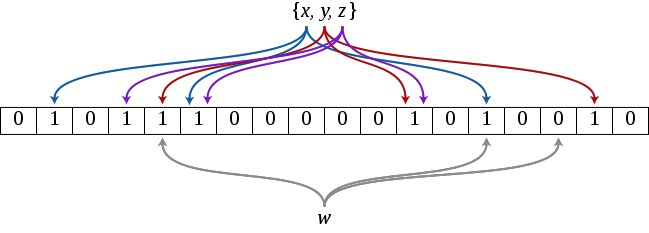
一个空的bloom filter是一个有 m 位的位数组,同时也定义 k 个哈希函数,每一个哈希函数映射元素到位数组的其中一个位。
添加:设置每一个哈希函数映射到的位为1。
查询:查询每一个哈希函数映射到的位是否都为1。只要有任意一个位不为1,则表明该元素绝对不存在。如果都为1,但也只能表明该元素可能存在(对于一般的bloom filter实现)。
删除:不支持。
补充:
要枚举所有在bloom filter中的元素是很困难的(譬如,需要许多的硬盘读取)
假阳性比例过高时,可以重新生成一个过滤器(以使得过滤器的假阳性低于某一个标准),只是这是一种相对非常少见的情况。
应用
- Google Bigtable、Apache Hbase、Apache Cassandra、PostgreSQL使用bloom filter来减少在磁盘上对不存在的行或列的查找。避免代价高昂的磁盘查询可以有效地提高数据库的查询性能。
- Google Chrome使用bloom filter来识别有害url。
- Microsoft Bing使用多层级的bloom filter来作为搜索的索引(BitFunnel,github上有对应的repo)。
- Bitcoin曾使用bloom filter来加速同步数字钱包。
- Medium使用bloom filter以避免对同一用户重复推荐相同的文章。
- Ethereum使用bloom filter在区块链上快速搜索logs。
概率分析
假阳性的概率(probability of false positive)
一个重要的前提条件,哈希函数映射到数组的每一个不同位置的概率是相等的,即简单均匀散列(simple uniform hashing)。
假设 m 为数组的位数,在对布隆过滤器插入一个元素时,某一位未被某一哈希函数(映射到)设置为1的概率是
1
−
1
m
1 - frac{1}{m}
1−m1 。
因为数组长度为m,任意某一位被任意某一哈希函数设置为1的概率是
1
m
frac{1}{m}
m1 ,那么未被设置为1即可得。
假设 k 为哈希函数的数量,每一个都是互相独立的(任意一个哈希的结果不依赖于任意其他的哈希结果),那么数组中的某一位未被散列函数设置为1的概率是 ( 1 − 1 m ) k (1 - frac{1}{m})^k (1−m1)k 。
根据微积分的知识,我们知道一个特殊的极限(也是自然对数 e 的定义)
l
i
m
x
→
−
∞
(
1
−
1
m
)
k
=
1
e
lim_{x to -infty}{(1 - frac{1}{m})^k} = frac{1}{e}
limx→−∞(1−m1)k=e1
又因为
(
1
−
1
m
)
k
=
(
(
1
−
1
m
)
m
)
k
m
≈
e
−
k
m
(1-frac{1}{m})^k = ((1-frac{1}{m})^m)^frac{k}{m} approx e^{-frac{k}{m}}
(1−m1)k=((1−m1)m)mk≈e−mk
所以我们可以得到,插入 n 个元素后,数组中任意某一位仍然为 0 的概率为
(
1
−
1
m
)
k
n
≈
e
−
k
n
m
(1-frac{1}{m})^{kn} approx e^{-frac{kn}{m}}
(1−m1)kn≈e−mkn
未被置1的概率为
1
−
(
1
−
1
m
)
k
n
≈
1
−
e
−
k
n
m
1 - (1-frac{1}{m})^{kn} approx 1 - e^{-frac{kn}{m}}
1−(1−m1)kn≈1−e−mkn
现在,如果需要检验一个实际上元素不在集合中,但 k 个哈希函数映射的位置却都置为了1的情况,也就是假阳性的情况的概率:
(
1
−
[
1
−
1
m
]
k
n
)
k
≈
(
1
−
e
−
k
n
m
)
k
(1 - [1-frac{1}{m}]^{kn})^k approx (1 - e^{-frac{kn}{m}})^k
(1−[1−m1]kn)k≈(1−e−mkn)k
另有一个分析方法可以不依赖独立性的假设,证得与前面的结果一致。
进一步推断可得,当数组的位数 m 增加时,假阳性的概率会降低;当插入元素的次数 n 增加时,假阳性的概率会增加。
源码分析
以太坊源码中使用到的bloom filter的实现:github.com/steakknife/bloomfilter
计算假阳性概率,与数学分析的公式相似
( 1 − e − k ( n + 0.5 ) m − 1 ) k (1 - e^{-frac{k(n + 0.5)}{m - 1}})^k (1−e−m−1k(n+0.5))k
func (f *Filter) FalsePosititveProbability() float64 {
k := float64(f.K())
n := float64(f.N())
m := float64(f.M())
return math.Pow(1.0-math.Exp(-k)*(n+0.5)/(m-1), k)
}
根据数列位数 m 和 预计加入元素的最大数量 maxN 来预估最佳的映射函数个数 K
K
=
c
e
i
l
(
m
∗
log
e
2
m
a
x
N
)
K = ceil(frac{m * log_e 2}{maxN})
K=ceil(maxNm∗loge2)
ceil即使取下界。
func OptimalK(m, maxN uint64) uint64 {
return uint64(math.Ceil(float64(m) * math.Ln2 / float64(maxN)))
}
根据预计加入元素的最大数量 maxN 和 可接受最大假阳性概率 p 来预估最佳的数列位数 m
m = c e i l ( − m a x N ∗ l o g 2 p ( l o g e 2 ) 2 ) m = ceil(frac{-maxN * log_2 p}{(log_e 2)^2}) m=ceil((loge2)2−maxN∗log2p)
func OptimalM(maxN uint64, p float64) uint64 {
return uint64(math.Ceil(-float64(maxN) * math.Log(p) / (math.Ln2 * math.Ln2)))
}
bloom filter 内部结构
type Filter struct {
lock sync.RWMutex //使用读写锁保证线程安全
bits []uint64 // 数列,采用位向量bitvector的方式存储
keys []uint64 // 散列函数keys,此处存储散列算法用到的随机数
m uint64 // 数列的位数
n uint64 // 已经插入的元素数
}
哈希函数
先取待哈希的值的Sum64值到rawHash。
Filter.keys是存放着 n 个随机数。取每一个其中的数与rawHash进行异或XOR操作,得到的结果放到hashes的切片中。
func (f *Filter) hash(v hash.Hash64) []uint64 {
rawHash := v.Sum64()
n := len(f.keys)
hashes := make([]uint64, n)
for i := 0; i < n; i++ {
hashes[i] = rawHash ^ f.keys[i]
}
return hashes
}
添加元素
0x3f(16进制) = 0011 1111(二进制) = 63 (十进制)
F.bits[i>>6] |= 1 << uint(i&0x3f) 位向量(bit vector)的set操作。
整个添加的流程即有 n 个随机数,进行异或得到 n 个中间值,然后再求余(一种散列映射的方式),根据位向量set到filter的数列里。
func (f *Filter) Add(v hash.Hash64) {
f.lock.Lock()
defer f.lock.Unlock()
for _, i := range f.hash(v) {
// f.setBit(i)
i %= f.m
f.bits[i>>6] |= 1 << uint(i&0x3f)
}
f.n++
}
验证元素是否存在
类似,迭代「哈希,求余,位向量test操作」 。
// false: f definitely does not contain value v
// true: f maybe contains value v
func (f *Filter) Contains(v hash.Hash64) bool {
f.lock.RLock()
defer f.lock.RUnlock()
r := uint64(1)
for _, i := range f.hash(v) {
// r |= f.getBit(k)
i %= f.m
// &=,若有0,即表示元素存在的任意一位为0,r都会是0
r &= (f.bits[i>>6] >> uint(i&0x3f)) & 1
}
return uint64ToBool(r)
}
最后
以上就是火星上白昼最近收集整理的关于bloom filter浅析(基本概念,概率分析,源码分析)基本概念概率分析源码分析的全部内容,更多相关bloom内容请搜索靠谱客的其他文章。








发表评论 取消回复