今天犯了了一个傻,我竟然第一反应要人工处理一堆数据,是这样的,之前别个收集了百度风云榜的榜单值,需要处理一堆excel文件,格式是相似的。但是比较混乱,一个excel文件包含多个sheet,文件名称包含时间大类信息,每个sheet名称是小类,每个sheet的数据格式是类似的,但是包含图片链接以及各种跳格。看到这么一堆数据表,我是懵逼的,打开一张表,吃屎一样的心情,这么一张表一张表的整理,人都不好了。写VB脚本也是可以的,但是不怎么熟练,之前也只是简单处理的时候在网上搜索现成的。这时候,R语言又可以发挥作用了。
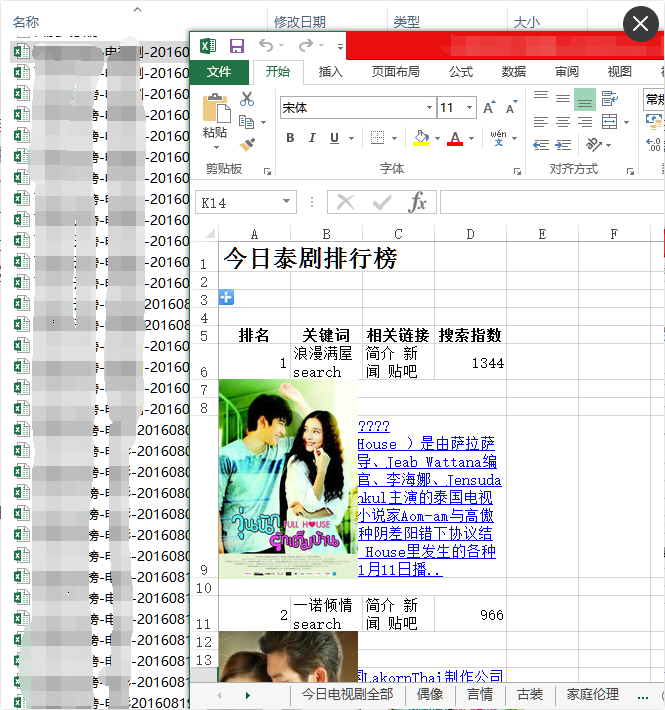
处理前示例
R程序
在安装xlsx包之前,需要先安装rJava包,rJava包的成功安装需要配置java环境,网上有很多资料。
library("rJava")
install.packages("xlsx")
library(xlsx)
library(stringr)#字符处理
file1<-"F://分类别"#上一级文件路径
works<-list.files(file1)#获取指定路径下的所有文件,这里我的全部是待处理的excel,若夹杂其他的,下面处理时需设定条件
for(m in 1:length(works)){
file<-paste(file1,"//",works[m],sep="")#拼接单个excel文件路径
#result<-data.frame()
wb<-loadWorkbook(file)
sheets<-length(getSheets(wb))#获取sheet数量
indexs<-attributes(getSheets(wb))#获取excel文件的sheet属性
for(i in 1:sheets){
content<-read.xlsx(file,i,encoding="UTF-8")#获取单个sheet内容
rows=nrow(content)#获取行数
for(j in 2:rows){
rank<-as.numeric(gsub("([tnr search])","",content[j,1]))#将目标字段转化为数值,非数字形式的方便下步过滤
if(is.na(rank)==TRUE){
#过滤非数值形式的数据,即干扰数据
}else{
ipname=gsub("([tnr search])","",content[j,2])#去除字符串中的各种空格、符号等
index=gsub("([tnr search])","",content[j,4])
time_str<-str_extract_all(file,"[0-9]+[0-9]")[[1]][2]#取文件名称中数字(时间)
updatetime=paste(substr(time_str,1,4),"/",substr(time_str,5,6),"/",substr(time_str,7,8),sep="")#调整时间格式
Encoding(indexs$names[i])<- "UTF-8"
type<-iconv(indexs$names[i], "UTF-8", "UTF-8")#获取到的文件sheet名称有编码问题,转化为utf-8格式,正常显示数据
ip<-data.frame(rank,ipname,index,type,updatetime,works[m])
#result<-rbind(result,ip)
write.table(ip,"F://分类别//totals.csv",append=TRUE,col.names=FALSE,row.names = FALSE,sep=",")#边处理边将处理好后的数据写出到外部文件,避免了内存溢出的问题
}
}
}
}处理后示例
一下就把几十个excel统一处理了,结构如下:

看来用R用多了,发现网上可参考的资料还是很少的,学会看说明文档很重要,现在看起比以前顺畅多了。
最后
以上就是执着台灯最近收集整理的关于文件夹下批处理excel-R语言的全部内容,更多相关文件夹下批处理excel-R语言内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复