此事件非 kafka API调用报错
在实现自定义分区时,在 partition() 方法中实现分区均衡,均衡策略是根据 value 的 hashcode 值对主题分区个数做取余,这个均衡策略是很常用的,再利用 nginx 做负载均衡时,就会用到的一种策略。本身没有任何问题
在做如下测试前,请先启动 zookeeper 和 kafka,若你的kafka 的server 配置中指定新创建的主题默认为一个分区,请先创建并修改主题分区数,例如:
./kafka-topics.sh --zookeeper 192.168.0.117:2181 --create --topic yourTopic --replication-factor 1 --partitions 4代码
自定义一个分区器,在生产者中的参数设置 "partition.class" 为 该分区器完整路径
/**
* 自定义分区器
*/
public class SelfPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);//获取分区
int num = partitionInfos.size();//
int parId = value.hashCode() % num;//分区id 均衡
return parId;
}
public void close() {
System.out.println("自定义分区器 被关闭...");
}
public void configure(Map<String, ?> configs) {
System.out.println("自定义分区器 调用 configure...");
}/**
* 生产者测试代码
*/
public class SelfPartitionProducer {
private static KafkaProducer<String,String> producer = null;
public static void main(String[] args) {
/*消息生产者*/
Properties properties = new Properties();
// kafka 连接 必须参数
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.0.xxx:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,keySerializeClazz);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,valueSerializeClazz);
/*使用自定义的分区器*/
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,SelfPartitioner.class);
producer = new KafkaProducer<>(properties);
try {
for (int i = 0; i < 100; i++) {
/*待发送的消息实例*/
ProducerRecord<String, String> record;
try {
record = new ProducerRecord<>("yourTopic", "key-1", "value"+i);
//异步发送,三种发送方式都可以
producer.send(record,(recordMetadata,e)->{
if (null != e){
e.printStackTrace();
}
if (null != recordMetadata) {
System.out.println(String.format("偏移量:%s,分区:%s",
recordMetadata.offset(),
recordMetadata.partition()));
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
} finally {
producer.close();
}
}
}结果
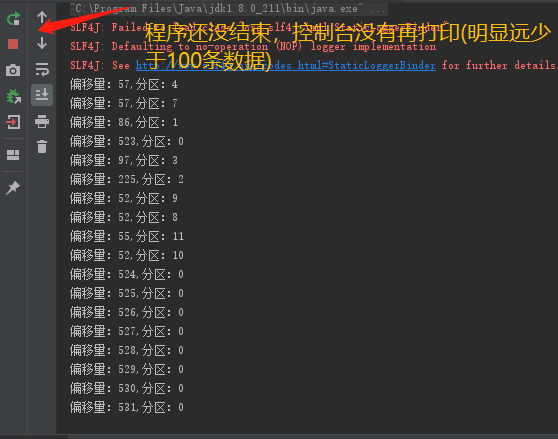
过了一定时间(重试超时时间)
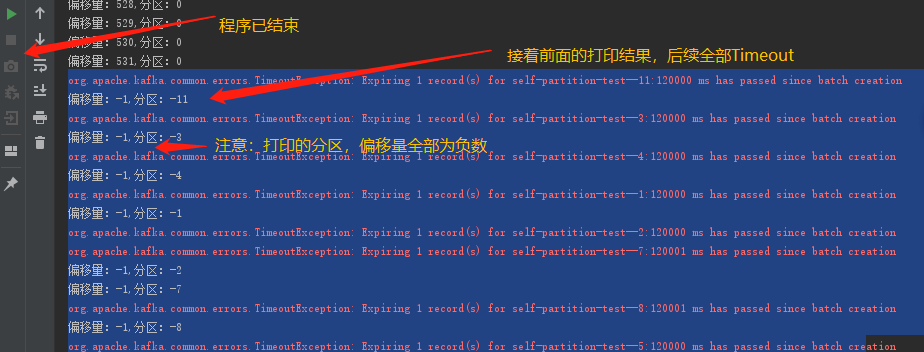
如果不适用自定义分区,完全没有这个问题,但是只往默认的一个分区发送消息
可以确定,是自定义分区方法报错
把自定义分区方法分解,debug
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);//获取分区
int num = partitionInfos.size();
// value 的 hashcode 值在某一个之后 全部变成了负数
int code = value.hashCode();
int parId = code % num;
return value.hashCode()%num;
}找到原因: value 为 Object 对象 hashcode 方法返回值在 某个 value 之后 开始为负数,导致计算返回的 partition 分区id 为负数,kafkaProducer 自然找不到 对应的分区,消息无限重试,最后超时
解决方法: 在取得hashcode值之后或者计算分区之后,做是否为负数的判断,再取反
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);//获取分区
int num = partitionInfos.size();//
// Object的hashcode方法在此使用会有极大的问题返回可以是负数,必须转化为正数,否则找不到分区
int code = value.hashCode();
/*if (code < 0){
code = - code;
}*/
int parId = code % num;
return parId < 0 ? -parId : parId;
}对nginx等类似做负载均衡策略配置的对比:
做nginx负载均衡配置时,若采用这种hashcode取余算法,没有符号,在java中有符号,且kafka中分区偏移量都为正数,需要做相应的取反操作
最后
以上就是明亮蜗牛最近收集整理的关于Java 调用 Kafka 原生API —— 自定分区使用报错的全部内容,更多相关Java内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。

![WARN [Producer clientId=console-producer] Connection to node -1 could not be established. Broker may](https://www.shuijiaxian.com/files_image/reation/bcimg27.png)






发表评论 取消回复