引用:HW与Epoch的讨论
HW存在的意义:(为了保持副本间可消费数据一致的标记)
保证多个副本之间的数据一致,否则因为同步的延迟的问题会出现多个副本间数据不一致的问题。
如果Leader重新选举,对于消费者来说还会出现跳跃消费数据,丢失数据的情况
保证当出现Leader切换后,能够消费的数据一致
HW存在的基础:
LEO 日志末端位移,表示日志末端下一条数据的位移,如果它的值为10那么分区中存在0~9 10条数据,下一条的位移量是10
怎么样更新HW
简单的说:取LEO的最小值,就是保证所有的副本的可消费数据一致
- Leader端:取Leader端和Follower端的Leo的集合的最小值
- Follower端:取Leader端返回给Follower端的HW的
HW 在消息写入过程中的变化
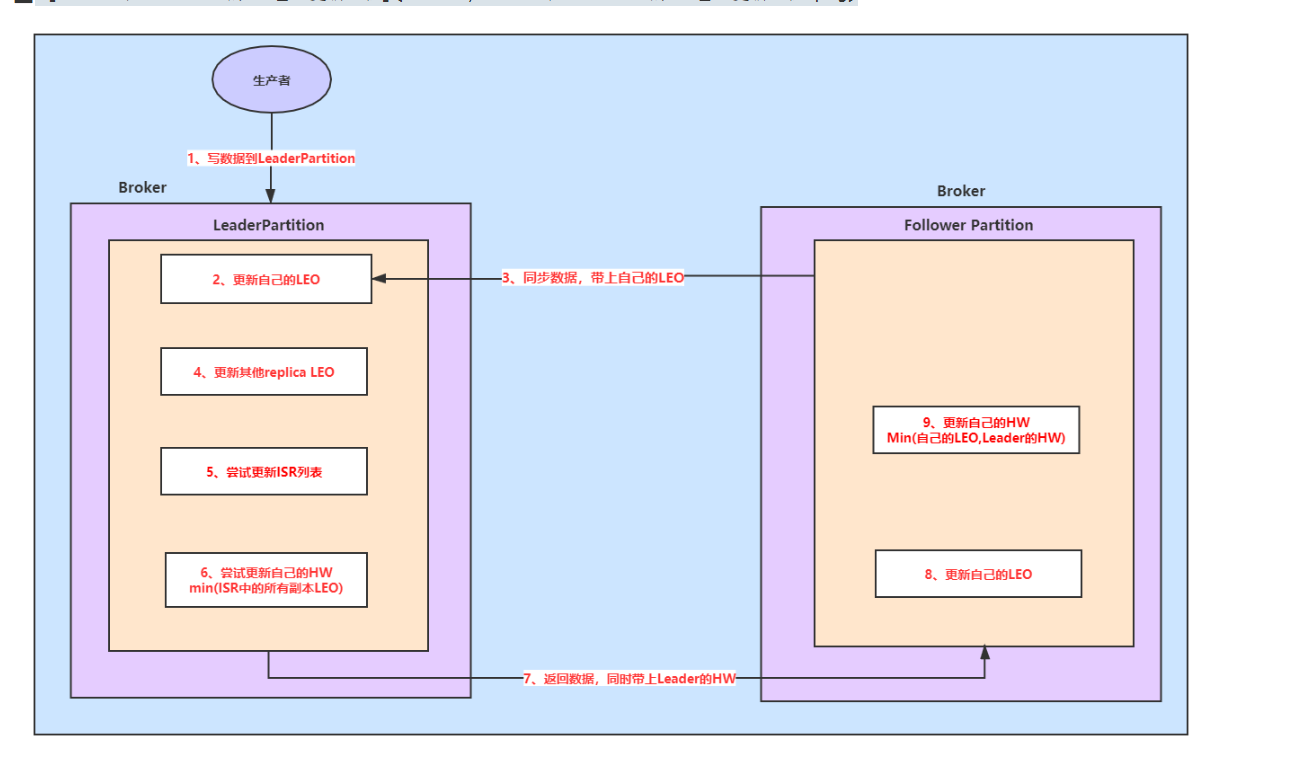
1.首先数据写入Leader
2.然后更新Leader的LEO
3.Follower向Leader同步数据,fetch 请求携带Follower的Offset
4.Leader更新Follower的LEO
5.尝试更新ISR
6.尝试更新自己的HW,min(ISR的所有LEO,包含自己的)
7.返回数据给Follower并带上Leader的HW
8.Follower更新自己的LEO
9.将Leader的HW和自己的LEO取最小值作为自己的HW
以上重要概念
Follower的Leo是存了两份的一份在Leader上,一份在自己的副本这里
何时更新Follower 的LEO
- Leader上的Follower上的LEO在Follower拉取数据请求发送给Leader后,这时数据还没有给Follower
- Follower自己的LEO,在拉取数据成功写入后
何时更新Leader的LEO
- Leader写入数据的时候
何时尝试更新Leader的HW
在Leader收到Follower的同步数据请求后,并更新Follower的LEO后,在发送数据给Follower之前
何时更新Follower的HW
Follower写入数据,更新LEO后
在Leader端更新HW过程中,选取副本LEO条件(满足之一即可)
- 处于ISR中
- 消息同步延迟replica.lag.time.max.ms参数值(默认是10s)
看似这两是一个条件实则不然,如果一台机器首先是追赶上Leader,这时候它宕机了,然后在10s内Leader写入数据,如果只判断第一条。那么这台宕机的副本的LEO将不会选中,那么当这台机器回来后分区HW就越过了这个副本的LEO。
此时之前的Leader挂了,回来的Follower还没有同步数据。如果这台机器成为了Leader就会造成数据丢失的问题。
以上这套机制存在什么问题
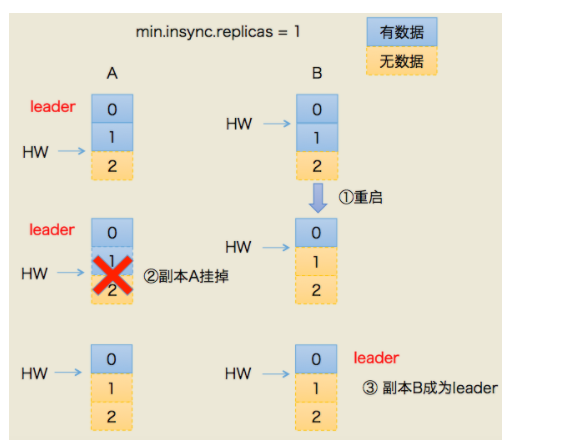
以下情况均建立在Kafka的最小Leader选举ISR数为1的情况
min.insync.replicas=1
副本超过一个,再加上Leader本身,总共有三个副本,那么是不太会出现以下情况。
-
还是存在数据丢失的可能
由于消息的的同步是延迟一轮的,所以有可能会出现以下场景:
1.Follower还没有更新HW,挂掉了
2.重启后,Leader也挂掉了,原来的Follower成为了新的Leader,它自己保持原来的HW,并且自动将LEO的值拉回了HW的值,这里很重要涉及到后面的解决方案
2.当原来的Leader加入变成Follower后,发现自己的HW比现在的Leader的高,然后做了日志截断
-
数据不一致
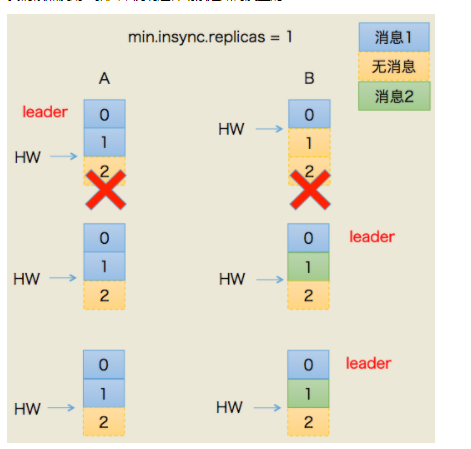
HW虽然一致,但是实际两个副本间的数据实际内容不一致了
1.首先Follower的同步此时延迟Leader一轮
2.两台机器都挂了,重启后由于网络的原因原来的Follower的先在Zookeeper建立了节点成为了新的Leader.
3.这时候新的Leader写入数据
4.然后原来的Leader重启后成为Follower,发现HW与新的Leader是一致,不需要变化
但其实这时候,两个副本HW是一致,但是最后一条数据实际内容是不一致的。
5.对于消费者来说,其实也是数据丢失了
Kafka是怎么规避上面的问题
在Leader端保存一条<epoch,offset>,表示《版本号,写入第一条消息的位移》,版本号只要重新选举一次就+1。
第一种情况:(数据同步了,HW未更新)
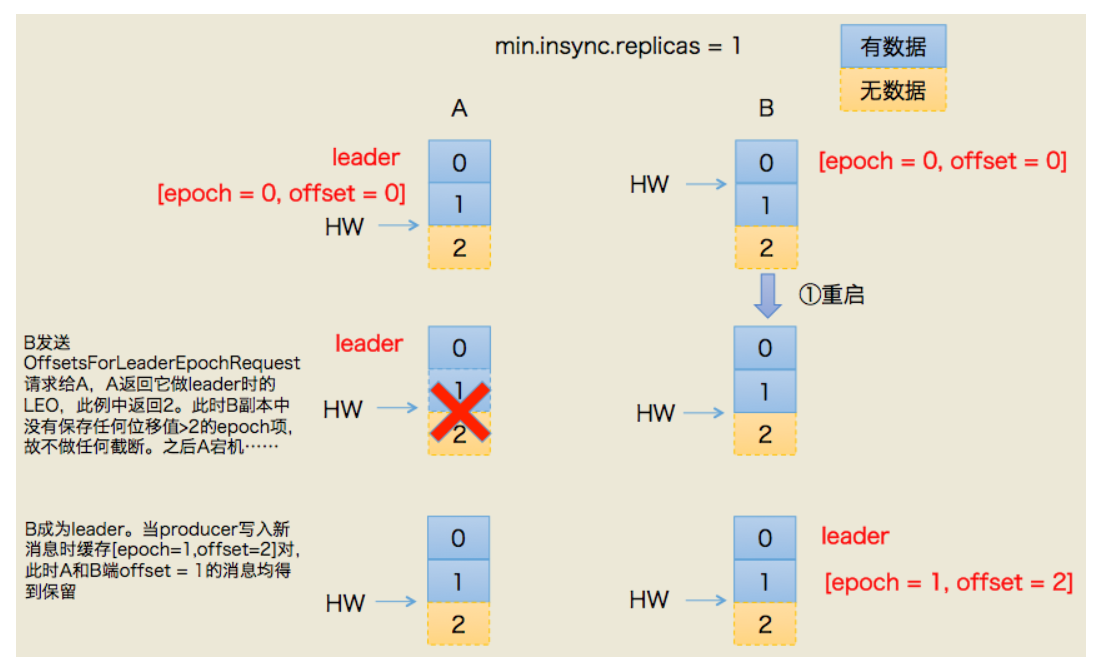
第二种情况:(数据还没有同步,HW未更新)
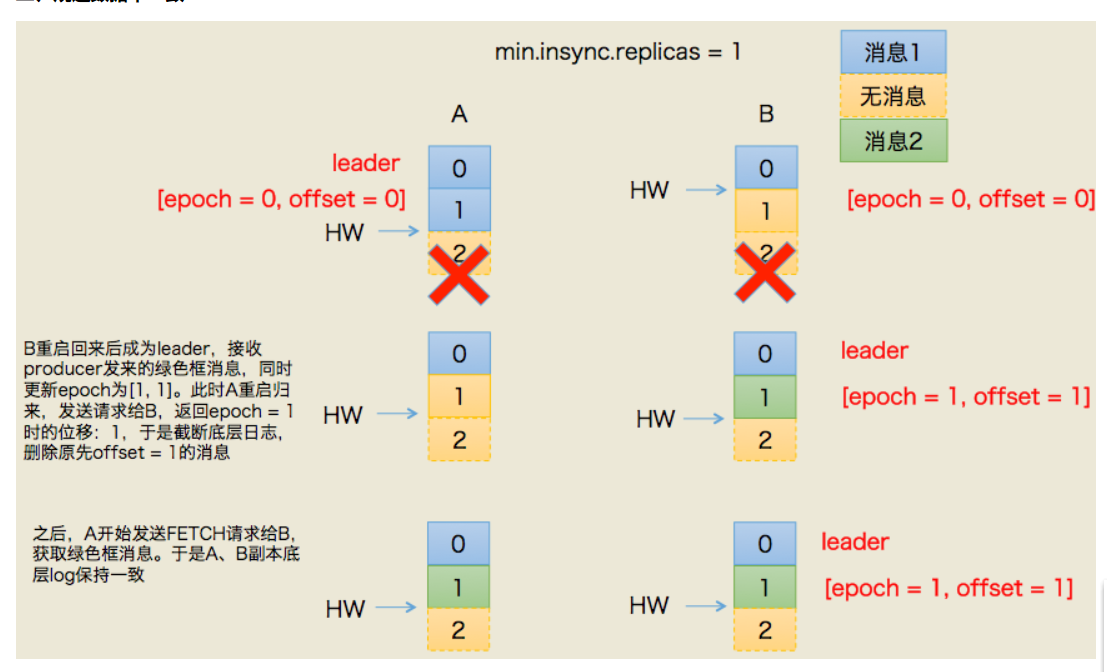
这样解决了数据的不一致问题,但其实我认为对于消费者来说还是丢失了数据的。
最后
以上就是勤奋皮卡丘最近收集整理的关于Kafka HW及Epoch的全部内容,更多相关Kafka内容请搜索靠谱客的其他文章。








发表评论 取消回复