**Centos7 Hadoop集群搭建**
https://www-us.apache.org/dist/hadoop/common/hadoop-2.8.5/
一.在node-1的主机上执行下面的命令:
ssh localhost – 无.ssh目录,则执行该命令生成
cd ~/.ssh/ 没有该目录,先执行上面的命令生成该目录
ssh-keygen -t rsa # 生成秘钥文件,会有提示输入秘钥文件信息,都按回车键即可
cat ./id_rsa.pub >> ./authorized_keys # 将秘钥内容加入到授权文件中
二.在node-2主机上执行上面一相关命令
将生成的公钥文件复制到node-1节点的相同目录,且重命名为id_rsa.pub.node-2
scp ~/.ssh/id_rsa.pub hadoop@node-1:~/.ssh/id_rsa.pub.node-2
三.在node-3主机上执行上面步骤一相关的命令:
将生成的公钥文件复制到node-1节点的相同目录,且重命名为id_rsa.pub.node-3
scp ~/.ssh/id_rsa.pub hadoop@node-1:~/.ssh/id_rsa.pub.node-3
在node-1节点,将node-2和node-3节点的秘钥文件信息都加入到授权文件中,相关命令如下:
cat ./id_rsa.pub.node-2 >> ./authorized_keys
cat ./id_rsa.pub.node-3 >> ./authorized_keys
在node-2和node-3节点分别执行下面的命令
chmod 700 ~/.ssh/
chmod 600 ~/.ssh/authorized_keys
在节点一上执行: ssh node-2 验证是否授权成功, exit 退出系统,回到原系统
解压hadoop 到 /usr/local/目录下面
tar -zxvf hadoop-2.8.5.tar.gz -C /usr/local/
cd /usr/local/hadoop-2.8.5/
pwd
/usr/local/hadoop-2.8.5
vi /etc/profile
hadoop config
export HADOOP_HOME=/usr/local/hadoop-2.8.5
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行下面命令,刷新profile文件,使修改生效
source /etc/profile
执行hadoop命令,如能输出下面的内容,说明hadoop系统变量配置成功
四 配置hadoop的环境变量
Hadoop所有的配置文件都存在于安装目录下的 etc/hadoop中,进入该目录进行以下配置
cd /usr/local/hadoop-2.8.5/etc/hadoop
依次修改:
hadoop-env.sh
mapred-env.sh
yarn-env.sh
三个文件分别加上JAVA_HOME环境变量: 如下
export JAVA_HOME=/usr/local/java/jdk1.8.0_192
把hadoop所有的文件及子目录所属组及用户调整为hadoop组与hadoop用户
chown -R hadoop:hadoop hadoop-2.8.5/
echo $JAVA_HOME
/usr/local/java/jdk1.8.0_192
vi hadoop-env.sh 同时其他两个文件也加入下面的环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_192
vi slaves
node-1
node-2
node-3
这是namenode感知其他节点存在的配置文件(不配置该文件,其他datanode节点不能启动,jps查询不到对应的进程号)
五 配置HDFS系统文件
(1) vi core-site.xml
<name>fs.defaultFS</name>
<value>hdfs://node-1:9000</value>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.8.5/tmp</value>
配置属性说明:
fs.defaultFS: HDFS的默认访问路径,也是NameNode的访问地址
hadoop.tmp.dir hadoop的数据文件的存放目录,该参数如果不配置,默认执行/tmp目录,
该目录在系统重启后会自动清空,从而导致hadoop的文件系统数据丢失.
(2)vi hdfs-site.xml
<name>dfs.replication</name>
<value>2</value>
<name>dfs.permissions.enabled</name>
<value>false</value>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.8.5/tmp/dfs/name</value>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.8.5/tmp/dfs/data</value>
配置説明:
dfs.replication: 配置文件在HDFS系统中的副本数
dir.namenode.name.dir: NameNode节点数据在本地文件系统的存放位置
dfs.datanode.data.dir: DataNode节点数据在本地文件系统的存放位置
(3)修改slaves文件,配置DataNode节点。slaves文件原本无任何内容,需要将所有的DataNode节点的主机名都添加进去,每个主机名占一整行(注意不要有空格)
配置信息如下:
node-1
node-2
node-3
六 配置YARN
重新命名mapred-site.xml.template 文件为mapred-site.xml,修改mapred-site.xml文件,添加以下内容,指定任务执行框架为YARN。
(1)vi mapred-site.xml
<name>mapreduce.framework.name</name>
<value>yarn</value>
(2)vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node-1:8032</value>
</property>
配置属性解析如下:
yarn.nodemanager.aux-services: NodeManager 上运行的附属服务,需配置成mapreduce_shuffle 才可以运行MapReduce程序,YARN提供了该配置项目于在NodeManager上扩展自定义服务,MapReduce的Shuffle功能正是一种扩展服务
scp -r hadoop-2.8.5/ hadoop@node-2:/usr/local/
scp -r hadoop-2.8.5/ hadoop@node-3:/usr/local/
scp: /usr/local//hadoop-2.8.5: Permission denied 小插曲
拷贝hadoop节点至其他机器节点时报错: 在其他机器节点执行:
root账号执行
chmod -R a+w /usr/local
(三台集群上分别执行 开放防火墙端口)
firewall-cmd --zone=public --add-port=9000/tcp --permanent
firewall-cmd --zone=public --add-port=8032/tcp --permanent
firewall-cmd --zone=public --add-port=50070/tcp --permanent
firewall-cmd --zone=public --add-port=50010/tcp --permanent
firewall-cmd --zone=public --add-port=8088/tcp --permanent
firewall-cmd --reload
该命令只在node-1节点上执行,格式化hdfs
hadoop namenode -format
start-all.sh 启动hadoop集群
stop-all.sh 停止hadoop集群
(启动正常看到的结果如下:)
Starting namenodes on [node-1]
node-1: starting namenode, logging to /usr/local/hadoop-2.8.5/logs/hadoop-hadoop-namenode-node-1.out
node-3: starting datanode, logging to /usr/local/hadoop-2.8.5/logs/hadoop-hadoop-datanode-node-3.out
node-1: starting datanode, logging to /usr/local/hadoop-2.8.5/logs/hadoop-hadoop-datanode-node-1.out
node-2: starting datanode, logging to /usr/local/hadoop-2.8.5/logs/hadoop-hadoop-datanode-node-2.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.8.5/logs/hadoop-hadoop-secondarynamenode-node-1.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.8.5/logs/yarn-hadoop-resourcemanager-node-1.out
node-3: starting nodemanager, logging to /usr/local/hadoop-2.8.5/logs/yarn-hadoop-nodemanager-node-3.out
node-1: starting nodemanager, logging to /usr/local/hadoop-2.8.5/logs/yarn-hadoop-nodemanager-node-1.out
node-2: starting nodemanager, logging to /usr/local/hadoop-2.8.5/logs/yarn-hadoop-nodemanager-node-2.out
在node-1节点执行
jps
29523 ResourceManager
29099 DataNode
28940 NameNode
30062 Jps
29295 SecondaryNameNode
29647 NodeManager
在node-2节点执行
jps
45889 NodeManager
45622 DataNode
46410 Jps
在node-3节点执行
jps
45889 NodeManager
45622 DataNode
46410 Jps
=开机启动脚本制作==
vi /usr/lib/systemd/system/hadoop.service
#文件内容
[Unit]
Description=Hadoop Server
After=network.target
[Service]
Type=forking
Environment=JAVA_HOME=/usr/local/java/jdk1.8.0_192/
ExecStart=/usr/local/hadoop-2.8.5/sbin/start-all.sh
ExecStop=/usr/local/hadoop-2.8.5/sbin/stop-all.sh
Restart=always
User=hadoop
Group=hadoop
[Install]
WantedBy=multi-user.target
执行systemctl daemon-reload
systemctl start | stop | hadoop
======================================================================
http://node-1:50070 访问namenode节点 看到web 界面
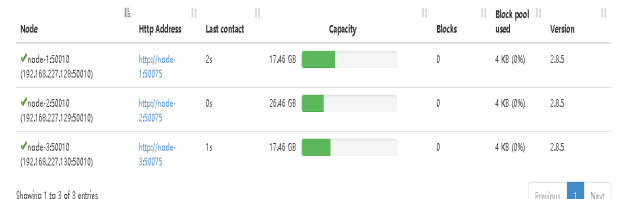
执行项目命令,在hadoop根目录下创建文件夹input
hadoop fs -mkdir /input
在本地创建一个文本文件words.txt,向其写入一些单词内容
Hello world
Hello hadoop
Bye hadoop
执行下面的命令,将words.txt上传到HDFS的/input目录中:
hadoop fs -put words.txt /input
进入cd /usr/local/hadoop2.8.5目录执行
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount
/input /output
统计完成后:
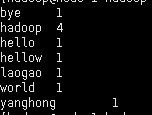
hdfs dfs -cat /output/* 执行该命令查看输出统计单词的结果
http://node-1:8088 可以查看程序的运行状态
程序运行的结果以文件的形式存放在HDFS的/output目录中,执行以下命令,查看目录/output中的内容
hadoop fs -ls /output
Found 2 items
-rw-r–r-- 2 hadoop supergroup 0 2019-11-07 17:32 /output/_SUCCESS
-rw-r–r-- 2 hadoop supergroup 60 2019-11-07 17:32 /output/part-r-00000
_SUCCESS执行状态文件,part-r-00000则存储实际的存储结果.
hadoop fs -cat /output/* —执行该命令查看结果文件中的数据
最后
以上就是个性大雁最近收集整理的关于Centos7 Hadoop集群架构hadoop config的全部内容,更多相关Centos7内容请搜索靠谱客的其他文章。








发表评论 取消回复