北京大学 苏勋斌

编者按:
基于FPGA的图处理加速器目前一般是使用多条流水线来对图计算进行硬件加速。然而,由于不同流水线间访问BRAM的读/写冲突,带来了极大的开销,导致了显著的性能下降。本文通过关注基于SpMV(矩阵乘法)的图处理过程,提出了一个无冲突调度器WaveScheduler,它可以将图的邻接矩阵分片,然后通过一种对角线主顺序的调度,将不同的子矩阵块分配到同一组的多条流水线中,从而不会产生任何的读/写冲突。除此之外,本文还介绍了两个为WaveScheduler定制的优化:用于改善负载均衡的“degree-aware vertex index renaming”(度感知顶点索引重命名)和用于支持片外内存连续访问的”data reorganization”(数据重组)。
今天介绍的工作是A Conflict-free Scheduler for High-performance Graph Processing on Multi-pipeline FPGAs,作者:Qinggang Wang,Long Zheng,Jieshan Zhao,Xiaofei Liao,Hai Jin,Jingling Xue,收录于ACM Transactions on Architecture and Code Optimization期刊(2020年)。

论文地址:
https://dl.acm.org/doi/pdf/10.1145/3390523
(或点击文末“阅读原文”跳转)
1 背景介绍
如今,图被广泛地应用于各类现实场景中,例如:万维网、社交网络、道路交通网络、生物信息网络等等。而随着图的数据关联关系越来越复杂,对大规模图的处理和分析就越来越具有挑战性。
目前,对于开发软件层面上的图处理系统已经有了大量的研究。首先是经常用到的内存图处理系统,它们通常有着不错的性能表现,因为它们可以把整张图放入内存进行处理,但也正是因为这一点,它们受限于图的规模。而为了处理大规模的图,一种做法是分布式图处理系统,它们会把一张大规模图分成多个小规模的子图,并将其分配给不同的计算节点,不同节点间可以并行计算。而分布式图处理系统的问题是:其一,由于频繁的数据通信,分布式图处理系统有着不小的通信开销;其二,计算节点间的负载均衡也是要考虑的一个问题。而另一种做法则是核外图处理系统,将大规模图数据存储于硬盘中,这带来的问题是大量的访存开销,因此这类图处理系统受限于底层硬件架构。
当然,也有许多关于硬件加速器的研究,GPU按下不表,本文主要是针对FPGA的。FPGA可以为图处理过程设计专门的多阶段流水线,这在之前的一些工作中被证明是有效的,如Graphicionado等。而对于图计算来说,一般一条流水线消耗FPGA片上的资源大约是2%-5%,这使得可以多条流水并行处理,极大地提高处理效率。然而,FPGA的多流水线的效率会受到片上BRAM上的数据读/写冲突的极大影响。当多条流水线同时读或写BRAM上的某个数据,其实访问是会被序列化的,这增大了流水线的开销。因此,本文的目的旨在完全消除基于多流水FPGA的图处理过程中的数据冲突问题。
本文的贡献:其一是从矩阵乘法的角度调研了基于FPGA多流水的图处理过程中的数据冲突问题;其二是提出了一个无冲突的调度器WaveScheduler解决这种数据冲突问题;其三是针对WaveScheduler提出了两种优化策略:度感知顶点索引重命名和数据重组;最后是与两个先进的基于FPGA的图加速器HEGP和ForeGraph进行比较,展现了性能上的优势。
2 基础知识
图计算是一个重复计算给定图状态的递归过程,有两个基本的模型:以点为中心的模型和以边为中心的模型。前者通过将顶点数据传播到相邻节点,并从相邻节点累计更新来计算顶点数据,从而遍历顶点。后者通过以流的方式处理所有边,每次更新边的目的节点。本文使用的是后者,由于实际的图的边数要比顶点数多的多,通过将顶点数据存储于片上BRAM,边数据存储于片外存储DRAM,可以显著减少访存次数。其一是边数据有良好的局部性,其二是BRAM上的随机访问特性可以减少顶点数据的随机访问开销。
矩阵乘法可以抽象为下述模型:
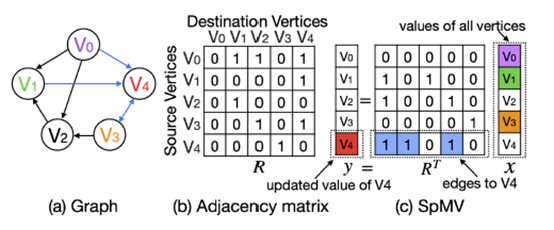
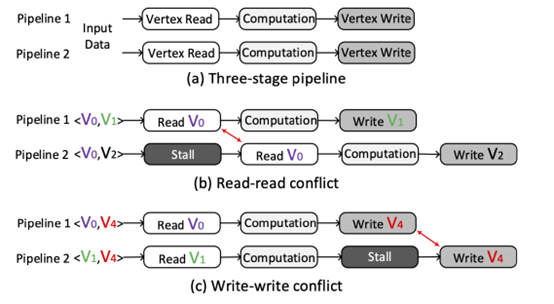
而对于FPGA流水线间的数据冲突,首先由于目前的FPGA卡的BRAM都是双端口的,一个是读端口,一个是写端口,并且BRAM可以设置读优先模式或写优先模式,所以读写冲突不考虑。本文主要考虑的读读冲突和写写冲突。可以把一条流水线大致分为三个阶段:读取源顶点数据,计算,更新目标顶点数据,如下图(a)所示。而当不同的流水线试图访问FPGA上BRAM中的相同位置的顶点数据时,就会发生数据冲突,如下图(b)和(c)所示。
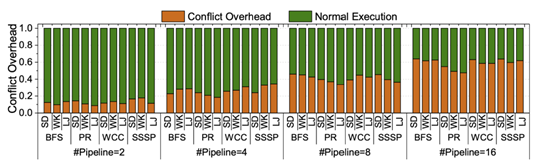
而数据冲突导致的流水线阻塞会显著影响性能,文章分别在BFS、PR(PageRank)、WCC(弱连通分量)、SSSP(单源最短路)四个算法上进行了测试。如下图所示,可以看到,随着并行流水线数目的增多,数据冲突带来的开销比重越来越大。
3 WaveScheduler
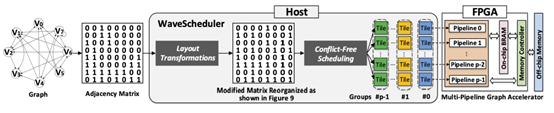
上图是WaveScheduler的大致工作流程。对于最左边这张图的邻接矩阵,水平地分块将产生源顶点集互斥的子矩阵,而垂直地分块将产生目标顶点集互斥的子矩阵,而为了同时消除读读冲突和写写冲突,本文的核心思想是同时应用水平分块和垂直分块,然后将得到的分片通过一种对角线主顺序的方式分配给多个流水线并行执行。WaveScheduler主要有两个组件:无冲突调度和布局转换。
1.无冲突调度

首先是如何在水平方向和垂直方向将邻接矩阵分片,以便所有的子矩阵片具有大致相同数量的非零元素。在水平方向上,会从第一行开始连续扫描邻接矩阵A,然后保证每一个切分的水平条带至多有#edges/p个非零元素,其中#edges是边的数目,p是流水线的数目,在垂直方向上也是同理。通过水平和垂直的切片,邻接矩阵就会被分成p×p个子矩阵片,对于一个稀疏图来说,可以确保每个子矩阵片包含大致相同数量的非零元素。当然,对于真实图来说,有可能会出现高度顶点聚集的情况,因此文章后面也提出了一种布局转化的策略。
在完成水平和垂直切片后,需要将这些子矩阵片调度到所有可用的流水线上。为了消除所有的数据冲突,不同流水线执行的两个子矩阵都不能有相同的行索引(这会导致读读冲突)或相同的列索引(这会导致写写冲突)。而满足这一条件的子矩阵片通常是对角的,因此本文以一种对角线主顺序的方式对所有子矩阵片进行索引编号,如算法1所示。

现在所有的子矩阵片都是对角索引,最后一步就是按照索引的递增顺序,循环分配到p个流水线中进行执行,共有p组执行。本文采用批量同步并行的模型(BSP),每组执行间都有一个barrier,只有当一组的所有子矩阵片都已处理,才会执行下一组的处理,如算法2所示。由于同一组内没有数据冲突,因此到达barrier后,不同块的更新也不需要合并。而阻塞的最简单方式,就是给非零元素少的片添加Null边,让同一组保持同步。因此当负载均衡时,可以实现良好的性能。
2.布局转换
但是,真实世界的图常常涉及不规则的度数分布,高度顶点往往占据连续的索引,直接在现实图上应用之前的分片技术可能会导致大量的关联边落入几个子矩阵片,产生负载不均衡的问题。而另一个问题是由于使用了对角线主顺序的方式,使得如果继续采用CSC或CSR的数据存储方式,可能会导致大量的片外存储器的随机访存。因此,本文提出了两种布局转换策略,“度感知顶点索引重命名”和“图数据重组”用于解决上述两个问题。
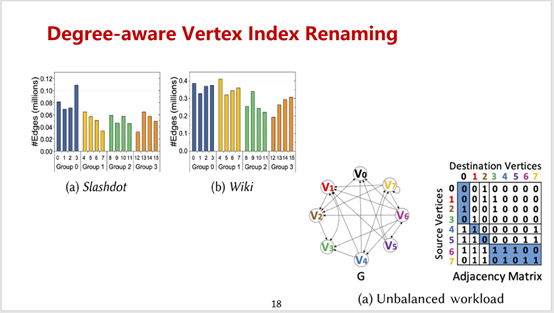
(1). 首先本文在两个数据集Slashdot和Wiki上使用了之前的无冲突调度策略,可以看到Slashdot数据集的子矩阵片1和3,Wiki数据集的子矩阵片12和15之间都存在着很大的负载不均衡。而产生这种负载不均衡的原因,主要是因为高度的顶点占据了连续的索引。所以一种自然的想法就是越相邻的顶点索引越应该被打散,这是度感知顶点索引重命名的核心思路。
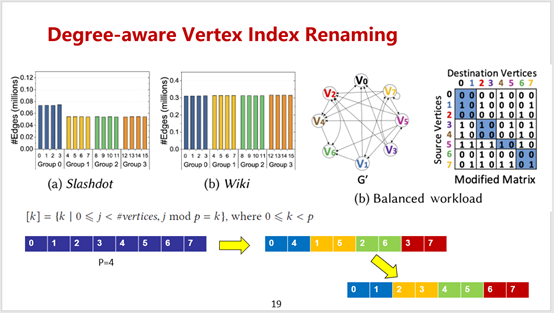
具体的做法是将所有顶点索引模p之后分为p个剩余类,然后按照余数大小排列每个剩余类,每个剩余类内部按照原始索引的递增顺序排列,最后对所有顶点进行索引重命名。通过实验表明,在使用度感知顶点索引重命名之后,对于上述两个数据集,每个子矩阵片上的负载被大大的平衡了。
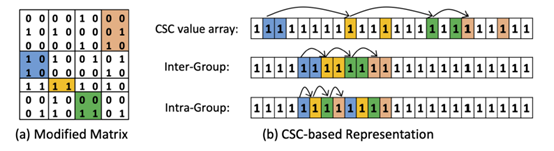
(2). 稀疏矩阵有很多存储格式,比如CSC和CSR,压缩稀疏行和压缩稀疏列。然而由于Wavescheduler使用的是对角线主顺序的调度,因此这种以行或列为主顺序的存储方式是不适合的,它们会带来大量的片外随机访存。因此本文提出了一种基于片索引的数据重组方式,以保证无冲突调度框架下对图边的连续访问。如图,给定一个邻接矩阵,它有p×p个分片,一共有p组执行,每组有p个子矩阵片。第一步,在组间阶段,按照片索引递增顺序存储。第二步,在组内阶段,p条连续存储的边属于同一组内的p个不同的子矩阵片,即片上的边以p为因子循环存储。
4 实验
本文使用的是Xilinx的U250 FPGA卡配备4块16GB的DDR4作为片外存储。host端是一台服务器,配备两个Intel 14-core Xeon E5-2680 2.40GHz处理器,256G内存和2TB HDD。在如下七个数据集上进行了实验,对标了两个目前先进的基于FPGA的图处理系统HEGP和ForeGraph。
1.性能比较
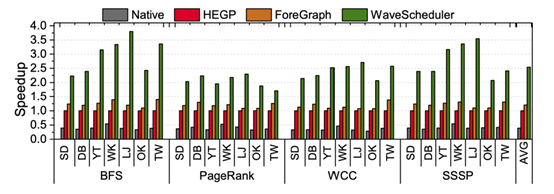
上图是图处理的性能比较:其中,Native是一个baseline的实现,没有无冲突调度。实验表明,平均情况下,WaveScheduler与Native相比有6.48x的加速比,与HEGP相比有2.53x的加速比,对ForeGraph相比有2.11x的加速比。
2.性能比较(含预处理开销)
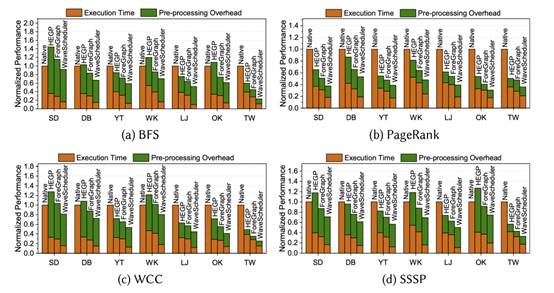
上图是加上了对图进行预处理的开销之后的性能比较:其中,Native无需对图进行预处理,而WaveScheduler对图的预处理包括分片、索引重命名和数据重组。实验表明,平均情况下,即使加上预处理的开销,WaveScheduler依然快于其余三个。
3.各个优化的收益比较
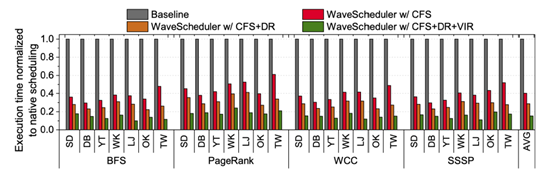
上图是将三个优化分别进行收益比较:其中,CFS是无冲突调度,DR是数据重组,VIR是度感知顶点索引重命名。实验表明,平均情况下,CFS贡献了70.70%的性能提升,DR贡献了13.51%的性能提升,VIR贡献了15.79%的性能提升。
4.扩展性测试
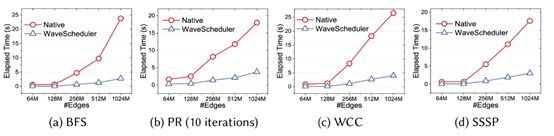
本文还进行了扩展性的测试,上图是随着数据图规模的增大,Native和WaveScheduler的时间开销曲线。实验表明,随着数据图规模的增大,虽然WaveScheduler的时间开销也在增大,但相比于Native的快速增长,WaveScheduler的时间开销增长是可以接收的。
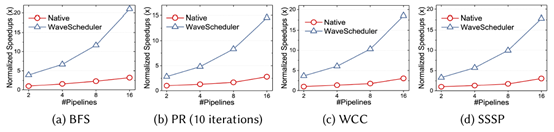
除此之外,本文还对流水线数目的扩展性做了测试。上图是随着流水线数目的增多,Native和WaveScheduler的加速效果。实验表明,随着流水线数目的增多,Native由于流水线间的数据冲突代价,导致了缓慢的性能增长,而WaveScheduler由于使用了无冲突的调度,所以性能可以有成倍的提高。
5.与基于CPU的图处理系统比较
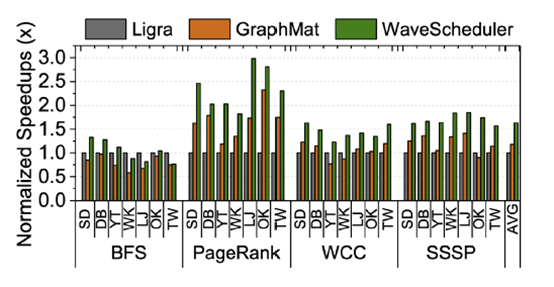
出于比较的目的,本文还与两个基于CPU的图处理系统Ligra和GraphMat进行了比较,也表现出了性能上的优势。
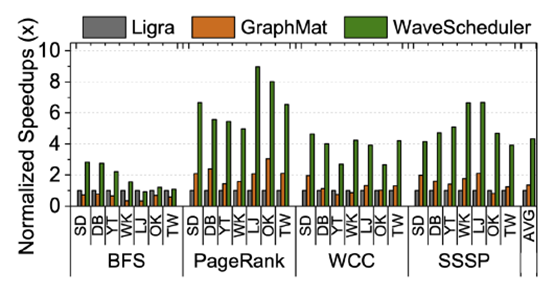
而在能耗比上,WaveScheduler的优势更加明显,如上图所示,这也是FPGA的优势所在。
6.与基于GPU的图处理系统比较


欢迎关注同名微信公众号。
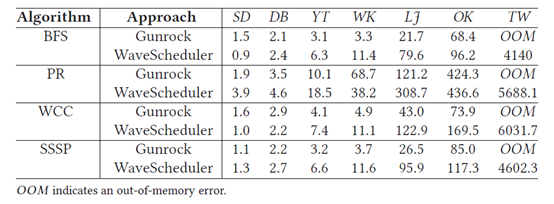
最后,本文还与基于GPU的Gunrock进行了比较,表现出了在部分数据集上可比的性能。虽然比不上GPU的性能,但FPGA优势主要是功耗少,对于上述的实验,Gunrock平均要消耗250瓦特,而WaveScheduler只需要消耗18瓦特。
最后
以上就是落后嚓茶最近收集整理的关于论文导读 | 基于多流水线FPGA的高性能图处理的无冲突调度器的全部内容,更多相关论文导读内容请搜索靠谱客的其他文章。








发表评论 取消回复